Microservices today are often deployed on a platform such as Kubernetes, which orchestrates the deployment and management of containerized applications. Microservices, however, don't exist in a vacuum. They typically communicate with other services, such as databases, message brokers, or other microservices. Therefore, an application usually consists of multiple services that form a complete solution.
But, as a developer, how do you develop and test an individual microservice that is part of a larger system? This article examines some common inner-loop development cycle challenges and shows how Quarkus and other technologies help solve some of these challenges.
What is the inner loop?
Almost all software development is iterative. The inner loop contains everything that happens on a developer's machine before committing code into version control. The inner loop is where a developer writes code, builds and tests it, and perhaps runs the code locally. In today's world, the inner loop could also include multiple commits to a Git pull request, where a developer may commit multiple times against a specific feature until that feature is deemed complete.
Note: The word local is also up for debate in industry today as more and more remote development environments, such as Red Hat OpenShift Dev Spaces, Gitpod, and GitHub Codespaces are available. This article does not differentiate between a developer machine and any of these kinds of environments. They are all viewed as local in this article.
Inner loop shifts to outer loop when code reaches a point in source control where it needs to be built, tested, scanned, and ultimately deployed by automated continuous integration and deployment (CI/CD) processes. Figure 1 illustrates a simple inner loop and outer loop.
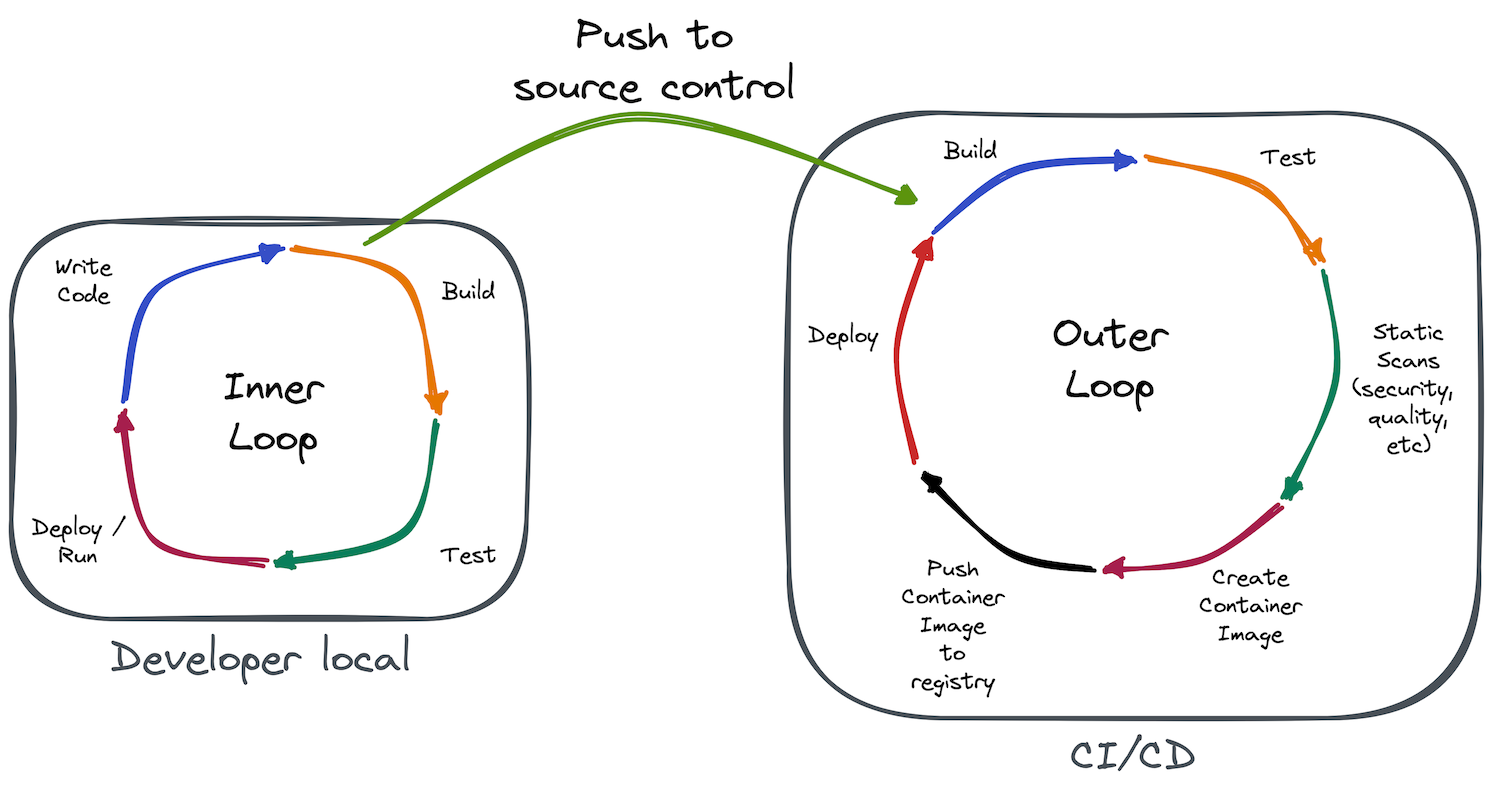
Challenges of inner loop development
Developing a single microservice in isolation is challenging enough without worrying about additional downstream services. How do you run a microservice in isolation on your local machine if it depends on other services for it to function properly?
Using various mocking techniques, you can to some extent get around the absence of required services when writing and running tests. Mocking techniques generally work great for testing. You can also use in-memory replacements for required services, such as an H2 database instead of a separate database instance. Beyond that, if you want or need to run the application locally, you need a better solution.
Of course, you could try to reproduce your application's entire environment on your development machine. But even if you could, would you really want to? Do you think a developer at Twitter or Netflix could reproduce their environment on their development machine? Figure 2 shows the complexity of their architectures. Lyft also tried this approach and found it wasn't feasible or scalable.

Container-based inner loop solutions
Using containers can help speed up and improve the inner loop development lifecycle. Containers can help isolate and provide a local instance of a dependent service. We'll look at a few popular tools and technologies for the inner loop.
Docker Compose
One common pattern is to use Docker Compose to run some of your microservice's dependent services (databases, message brokers, etc.) locally while you run, debug, and test your microservice. With Docker Compose, you define a set of containerized services that provide the capabilities required by your microservice. You can easily start, stop, and view logs from these containerized services.
However, there are a few downsides to using Docker Compose. First, you must maintain your Docker Compose configuration independently of your application's code. You must remember to make changes to the Docker Compose configuration as your application evolves, sometimes duplicating configuration between your application and your Docker Compose configuration.
Second, you are locked into using the Docker binary. For Windows and macOS users, Docker Desktop is no longer free for many non-individual users. You are also prevented from using other container runtimes, such as Podman. Podman does support Docker Compose, but it doesn't support everything you can do with Docker Compose, especially on non-Linux machines.
Testcontainers
Testcontainers is an excellent library for creating and managing container instances for various services when applications run tests. It provides lightweight, throwaway instances of common databases, message brokers, or anything else that can run in a container.
But Testcontainers is only a library. That means an application must incorporate it and do something with it to realize its benefits. Generally speaking, applications that use Testcontainers do so when executing unit or integration tests, but not in production. A developer generally won't include the library in the application's dependencies because Testcontainers doesn't belong as a dependency when the application is deployed into a real environment with real services.
Quarkus
Quarkus is a Kubernetes-native Java application framework focusing on more than just feature sets. In addition to enabling fast startup times and low memory footprints compared to traditional Java applications, Quarkus ensures that every feature works well, with little to no configuration, in a highly intuitive way. The framework aims to make it trivial to develop simple things and easy to develop more complex ones. Beyond simply working well, Quarkus aims to bring Developer Joy, specifically targeting the inner loop development lifecycle.
Dev mode
The first part of the Quarkus Developer Joy story, live coding via Quarkus dev mode, improves and expedites the inner loop development process. When Quarkus dev mode starts, Quarkus automatically reflects code changes within the running application. Therefore, Quarkus combines the Write Code, Build, and Deploy/Run steps of Figure 1's inner loop into a single step. Simply write code, interact with your application, and see your changes running with little to no delay.
Dev Services
A second part of the Quarkus Developer Joy story, Quarkus Dev Services, automatically provisions and configures supporting services, such as databases, message brokers, and more. When you run Quarkus in dev mode or execute tests, Quarkus examines all the extensions present. Quarkus then automatically starts any unconfigured and relevant service and configures the application to use that service.
Quarkus Dev Services uses Testcontainers, which we've already discussed, but in a manner completely transparent to the developer. The developer does not need to add the Testcontainers libraries, perform any integration or configuration, or write any code. Furthermore, Dev Services does not affect the application when it is deployed into a real environment with real services.
Additionally, if you have multiple Quarkus applications on your local machine and run them in dev mode, by default, Dev Services attempts to share the services between the applications. Sharing services is beneficial if you work on more than one application that uses the same service, such as a message broker.
Let's use the Quarkus Superheroes sample application as an example. The application consists of several microservices that together form an extensive system. Some microservices communicate synchronously via REST. Others are event-driven, producing and consuming events to and from Apache Kafka. Some microservices are reactive, whereas others are traditional. All the microservices produce metrics consumed by Prometheus and export tracing information to OpenTelemetry.
The source code for the application is on GitHub under an Apache 2.0 license. The system's architecture is shown in Figure 3.

In the Quarkus Superheroes sample application, you could start both the rest-fights and event-statistics services locally in dev mode. The rest-fights dev mode starts a MongoDB container instance, an Apicurio Registry container instance, and an Apache Kafka container instance. The event-statistics service also requires an Apicurio Registry instance and an Apache Kafka instance, so the instance started by the rest-fights dev mode will be discovered and used by the event-statistics service.
Continuous testing
A third part of the Quarkus Developer Joy story, continuous testing, provides instant feedback on code changes by immediately executing affected tests in the background. Quarkus detects which tests cover which code and reruns only the tests relevant to that code as you change it. Quarkus continuous testing combines testing with dev mode and Dev Services into a powerful inner loop productivity feature, shrinking all of Figure 1's inner loop lifecycle steps into a single step.
Other inner loop solutions
The solutions we've outlined thus far are extremely helpful with local inner loop development, especially if your microservice requires only a small set of other services, such as a database, or a database and message broker.
But when there are lots of dependent services, trying to replicate them all on a local machine probably won't work well, if at all.
So what do you do? How do you get the speed and agility of inner loop development for an application when it depends on other services that you either can't or don't want to run locally?
One solution could be to manage an environment of shared services. Each developer would then configure those services in their local setup, careful not to commit the configuration into source control.
Another solution could be to use Kubernetes, giving each developer a namespace where they can deploy what they need. The developer could then deploy the services and configure their local application to use them.
Both of these solutions could work, but in reality, they usually end up with a problem: The microservice the developer is working on is somewhere in the graph of services of an overall system. How does a developer trigger the microservice they care about to get called as part of a larger request or flow?
Wouldn't a better solution be to run the application locally, but make the larger system think the application is actually deployed somewhere?
This kind of remote + local development model is becoming known as remocal. It is an extremely powerful way to get immediate feedback during your inner loop development cycle while ensuring your application behaves properly in an environment that is close to or matches production.
Quarkus remote development
Another part of the Quarkus Developer Joy story, remote development, enables a developer to deploy an application into a remote environment and run Quarkus dev mode in that environment while doing live coding locally. Quarkus immediately synchronizes code changes to the remotely deployed instance.
Quarkus remote development allows a developer to develop the application in the same environment it will run in while having access to the same services it will have access to. Additionally, this capability greatly reduces the inner feedback loop while alleviating the "works on my machine" problem. Remote development also allows for quick and easy prototyping of new features and capabilities. Figure 4 illustrates how the remote development mode works.
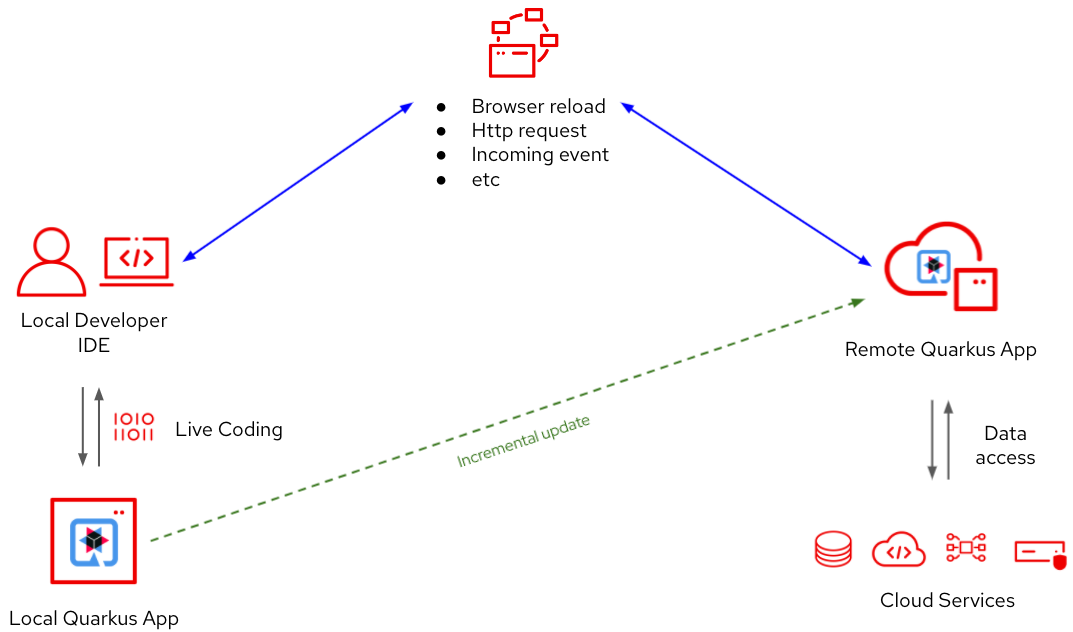
First, the application is deployed to Kubernetes, a virtual machine, a container, or just some Java virtual machine (JVM) somewhere. Once running, the developer runs the remote development mode on their local machine, connecting their local machine to the remote instance.
From there, development is just like live coding in Quarkus dev mode. As the developer makes code changes, Quarkus automatically compiles and pushes the changes to the remote instance.
Let's continue with the Quarkus Superheroes example from before. Let's assume the entire system is deployed into a Kubernetes cluster. Let's also assume you want to make changes to the rest-fights microservice.
As shown in Figure 5, you start the rest-fights microservice in remote dev mode on your local machine. The rest-fights application running on the cluster connects to the MongoDB, Apicurio Registry, and Apache Kafka instances on the Kubernetes cluster.
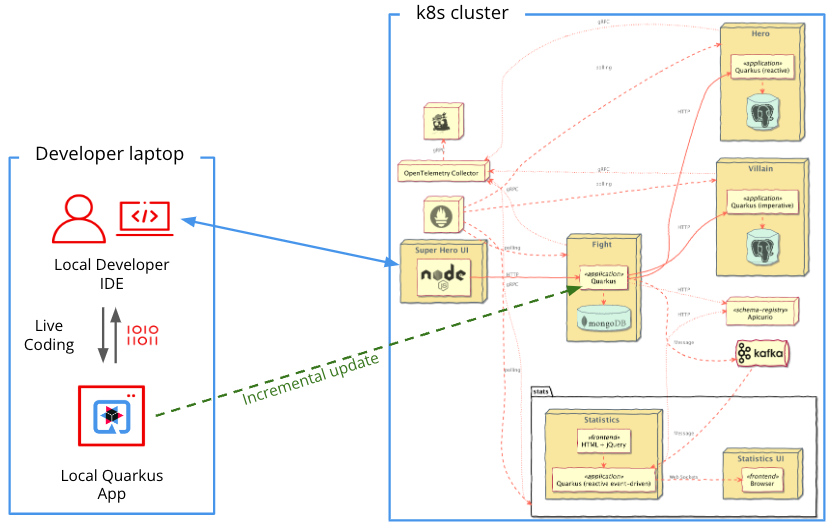
You can then interact with the system through its user interface. Quarkus incrementally synchronizes the changes with the remote instance on the Kubernetes cluster as you make changes to the rest-fights microservice. If you want, you could even use breakpoints within your IDE on your local machine to assist with debugging.
Skupper
Skupper is a layer 7 service interconnect that enables secure communication across Kubernetes clusters without VPNs or special firewall rules. Using Skupper, an application can span multiple cloud providers, data centers, and regions. Figure 6 shows a high-level view of Skupper.

With Skupper, you can create a distributed application comprised of microservices running in different namespaces within different Kubernetes clusters. Services exposed to Skupper are subsequently exposed to each namespace as if they existed in the namespace. Skupper creates proxy endpoints to make a service available within each of the namespaces where it is installed. Figure 7 shows a logical view of this architecture.

Why do we mention Skupper in an article about Kubernetes native inner loop development? Because in addition to bridging applications across Kubernetes clusters, a Skupper proxy can run on any machine, enabling bidirectional communication between the machine and the other Kubernetes clusters.
Logically, this is like a local machine inserted into the middle of a set of Kubernetes clusters. Services exposed to Skupper on the clusters can discover services exposed to the Skupper proxy on the local machine and vice versa.
Skupper can make our Quarkus Superheroes example even more interesting, taking it further from the remote development scenario we described earlier.
With Skupper, rather than continuously synchronizing changes to the rest-fights service from a local instance to a remote instance, you could completely replace the remote rest-fights instance with a local instance running Quarkus dev mode and continuous testing.
Skupper would then redirect traffic on the Kubernetes cluster into the rest-fights service running on your local machine. Any outgoing requests made by the rest-fights service, such as connections to the MongoDB, Apicurio registry, and Apache Kafka instances, and even the rest-heroes and rest-villains services, would then be redirected back to the Kubernetes cluster. Figure 8 shows a logical view of what this architecture might look like.

You could even use Quarkus dev services to allow the rest-fights microservice to provide its own local MongoDB instance rather than using the instance on the cluster, yet continue to let traffic to Kafka flow onto the cluster. This setup would enable other Kafka consumers listening on the same topic to continue functioning.
In this scenario, Quarkus continuously runs the tests of the rest-fights microservice while a developer makes live code changes, all while traffic is continually flowing through the whole system on the Kubernetes cluster. The services could even be spread out to other Kubernetes clusters on different cloud providers in other regions of the world while traffic continues to flow through a developer's local machine.
A better developer experience, whether local or distributed
Parts two and three of the previously mentioned article series at Lyft show Lyft's approach to solving this problem, albeit using different technologies. As more and more services came to life, Lyft saw that what they were doing wasn't scaling and that they therefore needed a kind of "remocal" environment.
Quarkus was designed with many of these Developer Joy characteristics in mind. Quarkus helps developers iterate faster and contains built-in capabilities that alleviate many of these challenges and shorten the development lifecycles. Developers can focus on writing code.
Last updated: February 11, 2024