To say that DevOps is an illusion is a controversial statement to start this article. What I mean is that I often see DevOps passing by, but I have the feeling that they forgot the “and.” Development and operations are often two separated silos, not looking at each other, not looking at each other’s principles, even in cloud development. One of the best examples of looking for best practices in other silos is (in my opinion) agile software development, which originated from the Japanese car manufacturer, Toyota.
As hybrid and/or multi-cloud is often positioned from an infrastructure point of view, I believe that it can bring added value to tell the story about it, seeing through “application development glasses" instead of “infrastructure glasses." Hence, we wrote this article.
This is part one of two articles in a series about clean architecture. Part two covers transitioning to a clean architecture platform.
Knowing versus understanding
Everybody knows mathematics, but not everybody understands integrals or knows how to apply volume calculations. Everybody knows that the surface of a triangle is ((b x h) / 2), but not everybody knows how to come to this formula. Some developers know the concept of clean architecture but don’t understand the internal details or principles enough to apply it to other domains (e.g., cloud infrastructure and cloud platform setup).
We often look at Red Hat OpenShift with infrastructure glasses, but development-oriented people care less about security, ease to set up the cluster(s). Next to that, infrastructure-oriented people are less interested in application development best practices, while there can be or should be a synergy between the two worlds.
How to handle data
Consider the concepts of DRY vs. WRYMSIU (i.e., while repeating yourself, make sure it’s useful). Don’t repeat yourself. Personally, I think this statement is outdated and should be replaced with WRYMSIU (I apologize, I’m not the best inventor of acronyms). This means that you can repeat yourself (e.g., data), but only if the duplication of data brings added value (like we will see later).
An example of this is an analytics engine that runs in another environment than where your result-showing application is living. If application performance is a priority, then it can bring added value to copy the result-data from the environment of the analytics engine to the application environment. Nowadays, storage is not that expensive anymore, which leads to my opinion that DRY is outdated.
Java application setup
There are a lot of options in dependencies and languages, but in order to set up a project or application, you need to work in the scope or context of a programming language. This is the only choice that you should be or will be tied to.
- Dependencies: Libraries or frameworks that are provided by third parties and that offer some functionality (e.g., logging, connection to Oracle, MongoDB, MySQL, databases, framework to expose REST/GraphQL endpoints). They are linked to your code base and can then be included within your source code (see Image 1).
- SOA: Service-oriented architecture. Controller (i.e., entry point), service layer (i.e., business logic), repository layer (i.e., database layer and persistence layer). Issues with SOA include the concept of service is error-prone (i.e., updating the code base to introduce workflow x can break workflow y). In this analogy, serverless function, Kubernetes Jobs should be preferred over real applications, but out of scope for this presentation.
Focus lies on dependencies from now on, with the choice for Java as programming language.
Example 1: Pollution of data classes (i.e., domain entities)
The issue with this way of coding is the database layer is directly intertwined with the domain entity (Figure 1). This results in that you have to know which type of database you’ll be using at the time of writing your data classes, and that whenever you would like to change your database technology, you’ll need to change the application core (i.e., business logic and application behavior).
A third issue with such code is the fact that data validation is handled by the library, based upon annotations. When you would try a new database technology, and you forget that validation should be rewritten now, the entire data validation will be compromised. Quite a lot of risks to just try out or change a library or database layer.

Example 2: Dependencies in the core (i.e., service) layer
Source: Log4J shell POC
Issue with this way of coding: This simple business logic (Figure 2) is tightly coupled to the Apache log4j library. Whenever you now would like to use another logging framework/library, you’ll have to refactor/touch a lot of classes, and you’ll have to touch the business logic layer. Hence, you’ll have a risk of introducing bugs in your application’s behavior, just by changing a library. This should never be the case, and this is something what implementing clean architecture (properly) would prevent.

Both examples showed that depending on third-party libraries in your core/service/business logic layer can result in the following:
- Higher maintenance costs and cycles (i.e., hard to keep dependencies up-to-date).
- Higher risk when changing/upgrading dependencies.
- Less innovation: It takes some time to change dependencies, and it comes with risks. Not too much enthusiasm to play around with new technologies or dependencies.
This is something that implementing clean architecture properly would prevent. Clean architecture can still cause bugs during refactoring, but business logic should not break.
What is clean architecture?
One of the main principles of clean architecture is nothing more than keeping your options open by changing, adding, or removing dependencies as often as you want. We offer two analogies to illustrate this point.
Real world analogies
If you’re in the lead of a football team, you better not offer long term contracts to a new coach: (maybe this is an exaggeration) because in 90% of the cases, a coach doesn’t last for more than two years. Offering short term contracts, will allow the team to change trainers as often as we think is needed to achieve good results.
As a business analogy, companies that do not focus on software development (e.g., companies with a focus towards biochemistry) often rely on consultancy companies. Again, to keep options open. When they need more software developers, want to change software developers (e.g., mismatch with the atmosphere within the team) or just want to decrease the amount of developers (e.g., wrapping up of a project), then they are more flexible to do so when dealing with consultants than when they’d be dealing with internal employees.
Technical explanation of clean architecture
A good demo project can be found on GitHub by Mattia Battiston. I often start with this project to do my talks.
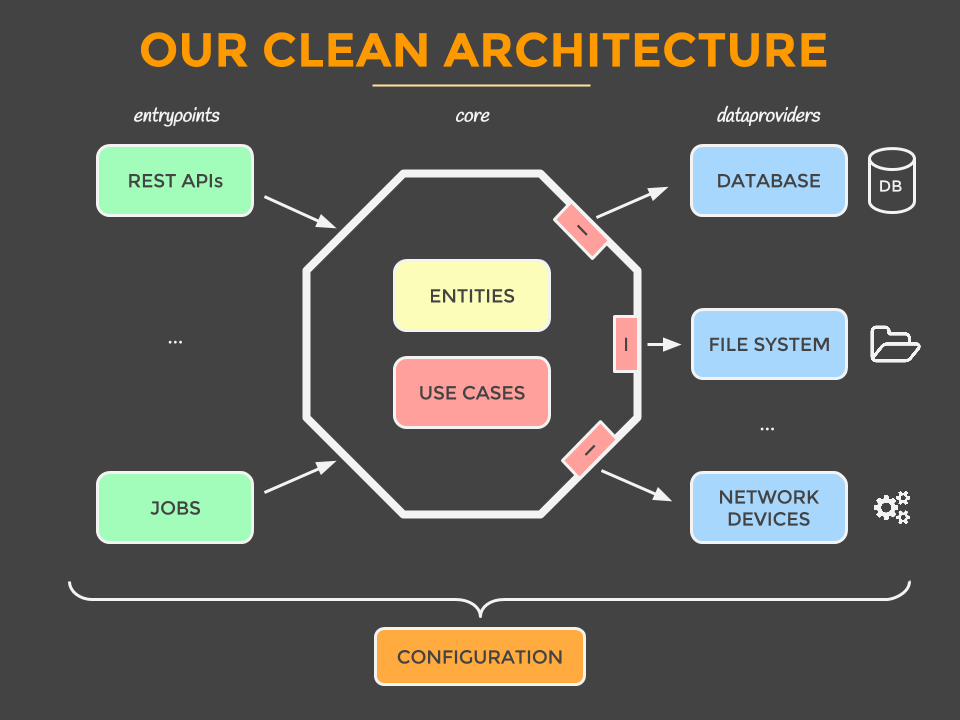
Clean architecture is about moving all your infrastructure and dependencies to the outer layer of your code base, leaving the business logic (domain entities and use cases, but these concepts are out of scope for this document/presentation) in the core (Figures 3 and 4). This has as an added value that it’s fairly cheap to change infrastructure, dependencies, or libraries as they are in the outer layer. Moving from Spring Boot to Quarkus, replacing Oracle with MySQL, ... will be easier to do. When trying something new is fairly cheap, then development teams can work around proof-of-concepts regarding modernizing their code base/application platform driving innovation (i.e., goes hand-in-hand with the values of Red Hat).
Last but not least, making it easy to change dependencies results in easier dependency upgrades without the risk of breaking the business logic. Hence, the core-layer (i.e., the business logic) is relatively easy to maintain and should be able to live for a longer period of time.
Infrastructure and dependencies often go hand-in-hand as every infrastructure component is managed by a third-party library. This is the case for REST/GraphQL APIs, databases, jobs, and file system access and network calls (although basic functionality to do so, is embedded in Java since Java 11).
As it’s not the focus of this article to do a deep dive about clean architecture, we’ll go for now with the concept of clean architecture is abstracting away business logic, the core of your business, from it’s (external, infrastructural) dependencies to avoid the marriage between infrastructure and dependencies.
As a side note (but beyond the scope of this article), going from SOA to use cases, makes you let go of DRY (for a valid reason in my opinion).

Learn more about clean architecture
In this article, I shared my opinions and advice about the benefits of building maintainable, clean architecture. If you want to learn more about clean architecture, feel free to reach out to me (but reserve some time because I’m passionate about it).
Be sure to check out the next article discussing the transition from functional microservices to a clean architecture platform. If you have any questions, please comment below. We welcome your feedback.
Last updated: September 19, 2023