Now that you have become an application development expert, it’s time to look at how clean architecture would look when we map it to the infrastructure side of an application platform. In case you're not familiar with clean architecture, read part one in this series, My advice for building maintainable, clean architecture.
Preferred application platform architecture
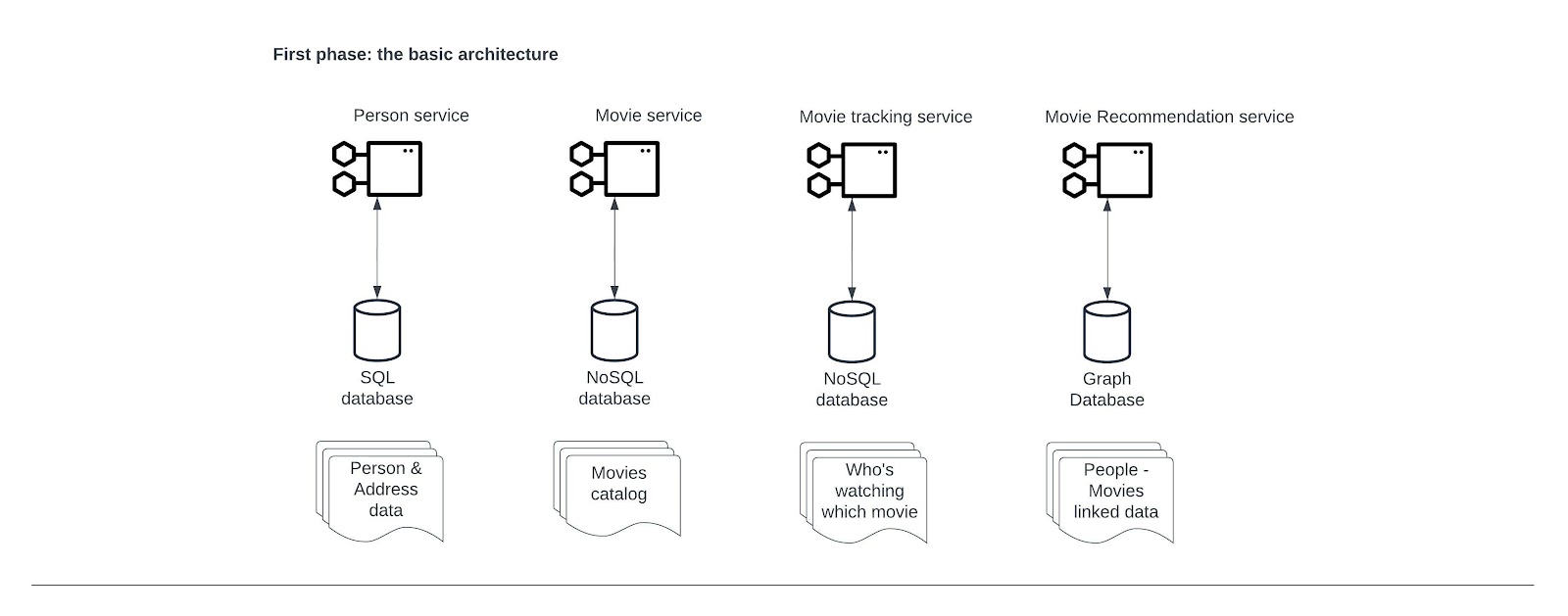
Before we get into the clean architecture mapping of our application platform, let’s describe how it should look (Figure 1).
We will have these four microservices:
- Personal data service: Capturing personal information (i.e., email, name, phone number, age, gender, and address). Since this kind of data is relational in nature, we would opt for a relational database for this service.
- Movies catalog service: A service to capture all movies from which we have collected data (i.e., name, director, actors, release date, and categories). We prefer to have this data stored in a NoSQL database.
- Movie tracking service: A service to store tracking information about who watched a movie. Data is very limited (i.e., person ID, movie ID, timestamp, and if the movie was completed). We prefer to have this data stored in a NoSQL database.
- Movie recommendation service: A service that consumes data from the previous three microservices to provide recommendations based on viewer habits, age, gender, and broad location). Since this is connected data, we prefer to have this data stored in a graph database. Here too, we let go of DRY - data copied to the graph.
Now that we have this outline, let's discuss how to implement it.
AWS single cloud vendor
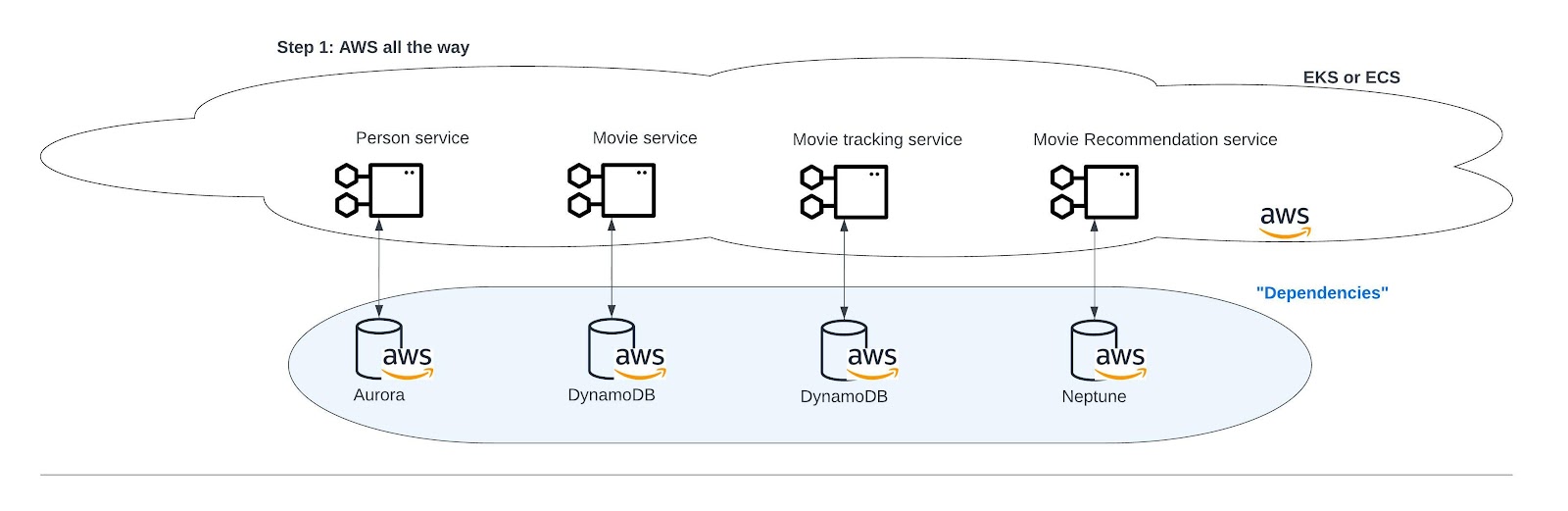
Within company XYZ, developers played with AWS in the past. The management and architects supported the choice for AWS, so the development team started the design of the application platform on AWS cloud. The list of requirements to design their cloud infrastructure is as follows:
- The requirement of the person microservice is that it should run on a SQL database. Within AWS, there are various options, but the development team chooses AWS Aurora.
- The requirement of the movie microservice is that it should run on a NoSQL database. AWS only offers DynamoDB off-the-shelf, so they choose DynamoDB.
- The movie-tracking microservice has the same requirements as the movie service; hence they choose DynamoDB.
- The requirement of the movie recommendation service is that it should run on a graph database. Since AWS only offers Neptune off-the-shelf (at the time of writing), they choose Neptune. If they need machine learning models, the development team can opt for AWS Athena or a machine learning model running on the graph database.
- The development team thinks that Red Hat OpenShift on AWS (ROSA) is too expensive, so they choose the DIY solution provided by EKS or ECS (both Kubernetes implementations of AWS), not thinking or knowing about the risks going along with this decision.
Now the development team has designed their cloud infrastructure for the cloud application platform (Figure 2).
In the next section, they will get back to the management team and the architects.
The evaluation of dependencies
In this section, we’ll look at the AWS services as if they were code dependencies. Instead of libraries referenced from the code (see our previous article), these dependencies will be cloud services referenced from the microservices. If we refer to clean architecture, the four microservices are the core-layer (i.e., the business logic that should stand the test of time) and the AWS services are the dependencies that should be easy to replace. We should not tightly couple (combine) with any specific AWS service (as interface layer, Camel can be used, but more on that in future articles). There is one exception. EKS or ECS is the hosting infrastructure and can be seen as the programming language within clean architecture.
The management team and the architects looked at the design of the application platform’s cloud architecture and had the following recommendations (Figure 3):
- Usage of AWS Aurora: That’s fine. It’s recommended by AWS. It’s a stable solution. This choice is accepted (acceptance rate: green).
- Usage of DynamoDB: This choice is not well received. The reason is that they bought or installed an on-premise bare-metal MongoDB cluster last year. In order to have some ROI, the management team and the architects prefer to use this cluster. If there is no other choice, DynamoDB can be accepted (acceptance rate: orange).
- Usage of Neptune: This is a no-go. Although it’s provided off-the-shelf by AWS, it’s not the best graph database on the market (at the time of writing). The management team and the architects would prefer Neo4J or TigerGraph (acceptance rate: red).
- Usage of EKS or ECS: Accepted by the management team and the architects, but this discussion is only won on the short-term pricing argument. They may have thought that OpenShift on AWS is too expensive, but they forgot the risks and the hidden costs that go along with a DIY solution.

Because not everything was accepted, the development team must go back to the drawing board.
Preferred dependencies
The development team, good listeners as they are, take the feedback from the management team and architects into account and start adapting their architecture. Their preferred dependencies are as follows (Figure 4):
- AWS Aurora was accepted. So AWS Aurora stays.
- Management was not too happy with the lack of ROI on their investment in the bare-metal MongoDB cluster. If they don’t want to have repercussions on future requested investments, it’s maybe a good idea to reuse that cluster, which is what they’ll do. AWS DynamoDB will be replaced by the on-premise bare-metal MongoDB cluster.
- Neptune was a no-go. The development team invests some time in reviewing graph databases. The winner in this exercise is Neo4J, off-the-shelf, offered by Google Cloud. AWS Neptune will be replaced by Google Cloud Neo4J.
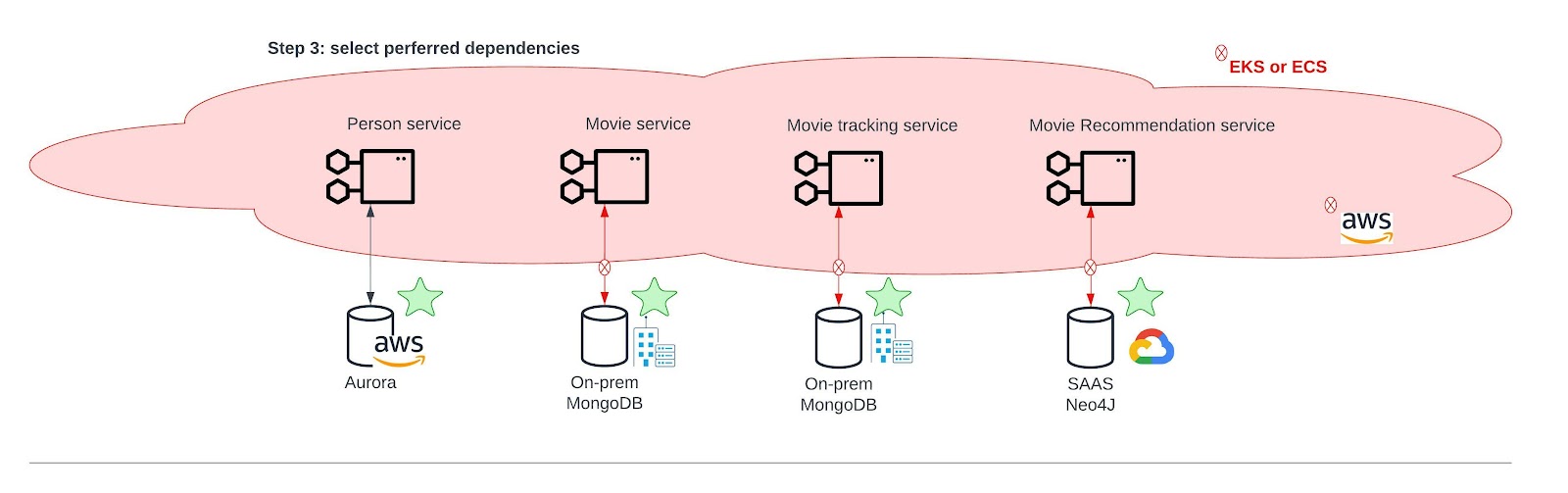
All of these changes should go relatively easy because the development team follows the principles of clean architecture. But it does not go easy. EKS or ECS has issues connecting to our on-premise MongoDB cluster and Google Cloud Neo4J (unless they spend quite some time and effort in fixing the network setup, which would even open the door for security flaws, as the development team is less trained in networking and operations).
The development team does not know how to fix the cloud (i.e., core layer) issue regarding the dependencies and asks the architects for input. This will be covered in the next section.
There is an analogy that can be made with Java and Python. Imagine that person service is a Java service and that the on-premise MongoDB is a Python library. If the programming language (like EKS or ECS) is Java, you won’t be able to access the Python libraries from within the person service. If you change the programming language to JVM and then to GraalVM, it would allow Java code to access Python scripts. It then would allow that the movie and movie tracking service are Python scripts (i.e., allow using these libraries) and that they can be called from within a Java service. Changing the programming language from Java to GraalVM, opened the options to a broader spectrum of third-party libraries.
Hybrid cloud and multicloud solutions to the rescue
The development team consults the architects with the issue: “We have isolated our dependencies (i.e., cloud services), but have issues with organizing our core layer (i.e., the third-party independent business logic, the microservices).” The architects look to see where the issue originated.
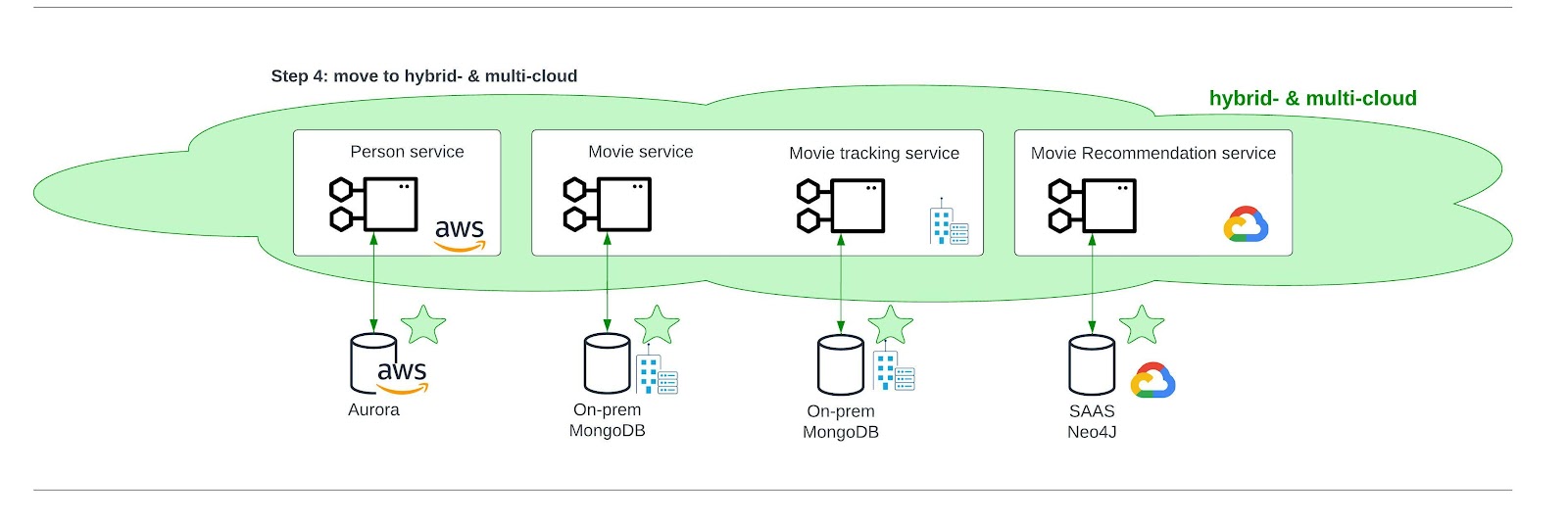
Clean architecture is about keeping your options open. The development team did this, but they narrowed the options too much by limiting their programming language (i.e., the microservice hosting platform) to AWS only. What they really need to make full use of the options available in the cloud and on-premise, is a hybrid cloud and multicloud. With a hybrid cloud, we mean the combination of a part of the cloud located at a vendor and a part of the cloud located on-premise. With a multicloud, we mean that the cloud is located over multiple vendors. When hybrid cloud and multicloud solutions are enabled as programming language, the development team will be able to use the preferred dependencies: AWS Aurora, on-premise MongoDB, and Google Cloud Neo4J.
This architecture will withstand the test of time as well. Whenever a new SaaS solution becomes available or a new cloud emerges, or new tooling is needed, it will be easy to plug it in the designed cloud architecture (Figure 5). This results in a more resilient platform that requires less maintenance and that fairly easily allows for future innovation.
But how can they implement a hybrid cloud and multicloud solution?
How to set up hybrid cloud and multicloud solutions
How do you set up hybrid cloud or multicloud solutions? Red Hat OpenShift Container Platform is the answer. It is a container platform that has the ability to easily start building hybrid cloud and/or multicloud solutions.
Although we used OpenShift as a solution for the issues that come along with EKS, OpenShift is more than just a Kubernetes installation or implementation. OpenShift Container Platform is a full application container platform. Check with the OpenShift specialists about how to bring the hybrid cloud and multi-cloud service to your company. Get started with a Red Hat OpenShift Service on AWS (ROSA) trial.
Last updated: September 19, 2023