This is part three in our series on running Node.js applications on the edge with Red Hat Enterprise Linux (RHEL)/Fedora, which includes:
- Running Node.js applications on the edge with RHEL/Fedora
- Containerizing your Node.js applications at the edge on RHEL/Fedora
- Advanced container management at the edge for Node.js applications (this post)
In the first part, we introduced you to the hardware and software for our Node.js-based edge example as well as some of the details on laying the foundation for deploying the application by building and installing the operating system using Fedora IoT.
In the second part we dug a bit deeper into the application itself, and how to build, bundle, deploy, and update the Node.js application using Podman and containers.
In this third and final part, we'll look at running the container on the device using Kubernetes and managing it remotely with Red Hat’s Advanced Cluster Management for Kubernetes.
A quick reminder of the example
The hardware/software outlined in the example in part 1 monitors the underground gas tank at a gas station showing the current temperature and the status of the tank lids. The hardware is based on a Raspberry Pi 4 with a temperature sensor and lid switches as shown in Figure 1. The application is a Next.js based application running on Fedora IoT, which displays the status of those sensors.

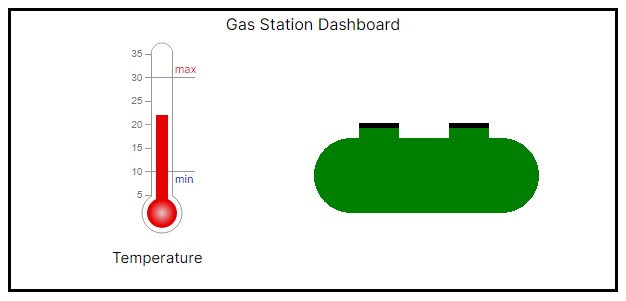
In part 2 we built the application using a Containerfile and pushed it to quay.io as a container named midawson/gas-station, as shown in Figure 3.
To deploy ,we then pulled and ran the container on the device using Podman. Podman Quadlet was used so that we could pull and start the container on boot of the device, and the application could be automatically updated on a timed interval.
While this approach is appropriate in many cases, some organizations will want to have more control over when and how the application is updated. In addition, as the number or complexity of applications deployed on an edge device increases, it may become necessary to manage a group of containers and more easily control the routes to those applications.
Kubernetes allows groups of containers to be managed, along with the internal and external routes for them. Building on that capability, Red Hat’s Advance Cluster Management for Kubernetes allows deployments to be controlled centrally, simplifying management of a larger fleet as well as providing control over how and when applications are updated.
Kubernetes at the edge: Hello MicroShift
With edge devices growing in terms of their CPU and memory (for example, 4 cores and 8G of memory for the Raspberry Pi 4 in our example) and Kubernetes distributions for constrained environments, it is possible to run a capable Kubernetes distribution at the edge. MicroShift is an example of one of these Kubernetes distributions for which the minimum requirements were only 2 CPU cores, 2-3GG of RAM and 10GB of storage at the time this article was published.
Note that MicroShift is not supported on Fedora IoT, and RHEL is not supported on the Raspberry Pi, so what we’ll experiment with in this article is not supported in any way. On the other hand, using a device that supports Red Hat Device Edge, installing MicroShift is as easy as adding a few packages in the blueprint we use to create the image for our device. The article Meet Red Hat Device Edge with MicroShift covers how to create that blueprint so we’ll not cover that here. Instead we’ll skip forward, assuming we have MicroShift running on our target device.
Deploying our Node.js application in Kubernetes
We can start by deploying the gas-station application to Kubernetes locally. To do that we need a Kubernetes Deployment to run the container and a Kubernetes service to allow the port exposed by the application to be reached. A basic example would be (https://github.com/mhdawson/gas-station/blob/main/deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: gas-station-deployment
labels:
app: gas-station
spec:
selector:
matchLabels:
app: gas-station
replicas: 1
template:
metadata:
labels:
app: gas-station
spec:
containers:
- name: gas-station
image: quay.io/midawson/gas-station:latest
ports:
- containerPort: 3000
resources:
limits:
memory: 128Mi
cpu: "500m"
requests:
memory: 128Mi
cpu: "250m"
---
apiVersion: v1
kind: Service
metadata:
name: gas-station
spec:
selector:
app: gas-station
ports:
- protocol: TCP
port: 3000
targetPort: 3000
nodePort: 30011
type: NodePortThis deploys the same container that we built in part 2—quay.io/midawson/gas-station:latest.
Unfortunately, as was the case when we first containerized the application and ran it with Podman, the GPIO switches are not available in the container and the tank will show green even if one of the caps is removed, as shown in Figures 4 and 5.
 |
|
Ok, so we’ll just use the equivalent to the Podman --device options, right? Well unfortunately, this does not exist as a simple option to add to our container specification. As in part 2, one of the interesting parts of running our application in the edge device is going to be enabling access to the hardware devices.
Getting access to the device in the container: Approach 1
Most of the available instructions/advice on the internet on how to get access to devices in a container running under Kubernetes suggest you make the container privileged by configuring the securityContext:
containers:
- name: gas-station
securityContext:
privileged: true
image: quay.io/midawson/gas-station:latest
ports:
- containerPort: 3000
resources:
limits:
memory: 128Mi
cpu: "500m"
requests:
memory: 128Mi
cpu: "250m"When a container is privileged it has broad access to the host, including all of the devices on the host. You can read more about configuring a securityContext in Configure a Security Context for a Pod or Container. This gives significant capabilities to the container. Therefore, by default, deployments that have containers configured this way will be rejected when you try to deploy them to MicroShift.
When we first tried to deploy the application we got this error:
Warning: would violate PodSecurity "restricted:v1.24": privileged (container "gas-station" must not set securityContext.privileged=true), allowPrivilegeEscalation != false (container "gas-station" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "gas-station" must set securityContext.capabilities.drop=["ALL"])
deployment.apps/michael-station-deployment createdThis is because of pod security admission policies which by default restrict what privileges containers may be given. You can read more about these policies in Pod Security Admission.
Unfortunately, if you follow the suggestions in the warning you will end up with a deployment where the container cannot access the device for the GPIO. Instead, we needed to modify the admission policy for the namespace we created so that it accepts privileged containers. We did that as follows:
oc label namespaces test pod-security.kubernetes.io/enforce=privileged --overwrite=trueAfter that we still got an error because by default a newly created namespace is not associated with a credential that has the right permissions. We saw this from the error reported by the replica set created by the deployment:
Warning FailedCreate 14s (x15 over 96s) replicaset-controller Error creating: pods "michael-station-deployment-5f96c65958-" is forbidden: unable to validate against any security context constraint: [provider "anyuid": Forbidden: not usable by user or serviceaccount, provider restricted-v2: .containers[0].privileged: Invalid value: true: Privileged containers are not allowed, provider "restricted": Forbidden: not usable by user or serviceaccount, provider "nonroot-v2": Forbidden: not usable by user or serviceaccount, provider "nonroot": Forbidden: not usable by user or serviceaccount, provider "hostmount-anyuid": Forbidden: not usable by user or serviceaccount, provider "hostnetwork-v2": Forbidden: not usable by user or serviceaccount, provider "hostnetwork": Forbidden: not usable by user or serviceaccount, provider "hostaccess": Forbidden: not usable by user or serviceaccount, provider "privileged": Forbidden: not usable by user or serviceaccount]We discovered through trial and error that the default namespace does have enough privileges that the containers can start. However, our understanding is that you don’t want to use the default namespace for application deployments as outlined in OpenShift Runtime Security Best Practices. Instead we would have needed to figure out how to create the appropriate credentials and associated them with the namespace.
Another lesson we learned is that you should be careful if you add other options beyond the "privileged: true" option to the securityContext. We believe that adding some of those suggested in the pod admission warning caused us some trouble in getting access to the devices.
The up side to the trouble we ran into is that along the way we also discovered an alternative way to make the device accessible in the container. Depending on what’s important in terms of security within your device, this alternate approach (covered in the next section) might make sense for you. It’s what we used for the rest of what we are sharing in this post.
Before we move on to describing the second approach, here is a list of the devices in the gas-station container when running privileged in the default namespace as shown in Figure 6.
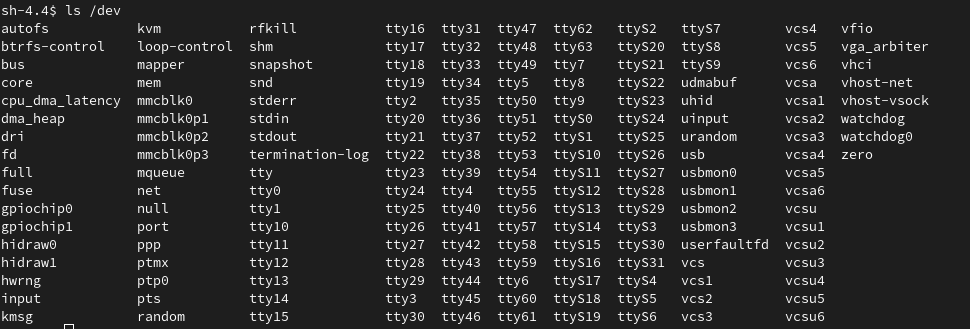
Since we can see /dev/gpiochip0, the GPIO switches can now be read and the application worked as expected.
Getting access to the device in the container: Approach 2
As we mentioned we had some trouble getting all of the devices to show up initially in the container using a privileged securityContext so we searched for other alternatives.
What we discovered is that there are configuration options in the container engine (CRI-O) used in MicroShift. The CRI-O configuration file is located in:
/etc/crio/crio.confIt has two sections that are of interest with respect to accessing devices:
# List of devices on the host that a
# user can specify with the "io.kubernetes.cri-o.Devices" allowed annotation.
allowed_devices = [
]
# List of additional devices. specified as
# "<device-on-host>:<device-on-container>:<permissions>", for example: "--device=/dev/sdc:/dev/xvdc:rwm".
# If it is empty or commented out, only the devices
# defined in the container json file by the user/kube will be added.
additional_devices = [
] The first section allows a set of devices to be configured so that they can be requested based on an annotation on the container being deployed. This should give a capability similar to using --device with Podman.
The second section lists additional devices that should be mapped into all containers. This is the option we used by configuring it as follows:
# List of additional devices. specified as
additional_devices = [
"/dev/gpiochip0:/dev/gpiochip0:rwm"
] After adding that configuration and then restarting CRI-O with:
systemctl restart crioThe /dev/gpiochip0 device showed up within our gas-station container without needing to be privileged!
The advantage of this approach is that the gas-station container does not need to be given broad access to the host. The downside is that the device is available to all containers. This is similar to kernel modules (for example, the one loaded for the temperature sensor) so may be appropriate for some deployments.
The tradeoff is between giving one container (the one which needs to access a device) broad access to the host, versus giving all containers access to the device. We think in some deployments (including our gas-station example) giving all containers access to the additional device is a lower risk than giving the container accessing the device broad access to the host. Using the additional_devices configuration along with an annotation would make this even better so only the containers we tag with the annotation can access the device.
Using the additional_devices configuration, this is the list of devices we see in the gas_station container, as shown in Figure 7,

This is without having to set a securityContext, without having to change the pod admission policy for the namespace and without having to associate a special credential with the namespace.
We now have a fully working application once again, as shown in Figures 8 and 9.
|
 |
External connectivity
In part 2 when running with Podman we could run our application container on the port of our choosing by adding the port to the Blueprint and running Podman with the -p command to specify the external port. Now that we are running under Kubernetes, it is more flexible, but also more complicated.
In our example we created a nodePort service:
---
apiVersion: v1
kind: Service
metadata:
name: gas-station
spec:
selector:
app: gas-station
ports:
- protocol: TCP
port: 3000
targetPort: 3000
nodePort: 30011
type: NodePortBy default the ports available for a nodePort service are between 30000-32767 so we cannot reuse port 3000 that way. Instead we can run on another port like 30011 and then use a port forward on the machine to achieve something similar by adding a firewall rule like:
firewall-cmd --add-rich-rule='rule family=ipv4 forward-port to-port=3000 protocol=tcp port=30011'Running under Kubernetes also brings the ability to have multiple instances of the container and load balancing across them. In that case we could configure a load balancer as outlined in howto_load_balancer from the MicroShift user guide.
The TLDR; is that we can keep it simple with a single container listening on port exposed for the edge device but also have a lot more of the flexibility that comes with Kubernetes.
Updating the application
In the previous sections we’ve covered deploying the application locally with Kubernetes. If we continue to control deployment locally this has not changed too much from using Podman/Quadlet unless we have a complex application with multiple running containers that need to be managed together. This might be enough to motivate using Kubernetes in some edge deployments.
Application updates would be quite similar to when using Podman with either a timed or custom built process for updating the deployment for the application. As before, carefully planning how you manage tags is important—see Docker Tagging: Best practices for tagging and versioning docker images.
The second advantage that running under Kubernetes unlocks is being able to remotely control the deployments through tools like Red Hat’s Advanced Cluster Management for Kubernetes (ACM). Even for a simple application with one running container, the ability to remotely monitor and manage deployments may be just what an organization is looking for.
Red Hat’s Advanced Cluster Management for Kubernetes allows a cluster to be enrolled. Once enrolled you can push deployments to the cluster. The general model would be as follows:
- Build the edge device so that the base image includes MicroShift but no deployment.
- Enroll the device to connect it with ACM.
- Use ACM to deploy and update applications.
In earlier sections we talked about building the base image to include MicroShift. Next, we’ll move on to steps 2 and 3.
Enrolling with Advanced Cluster Management for Kubernetes
Installation of Advanced Cluster Management for Kubernetes (ACM) is relatively simple by installing the operator provided through OperatorHub and following the instructions, as shown in Figure 10.

Once ACM is installed you can switch to the All Clusters view, as shown in Figure 11.
From there you have the option to import clusters, as shown in Figure 12.
When importing you have a number of options on how to import the cluster, as shown in Figure 13.
In our case we chose the Kubeconfig option, where you get the Kubeconfig for the device and paste it into the form.
Once imported, the cluster shows up in the all cluster view. We named the cluster running in the device gas-station-pi-4 as shown in Figure 14.

At this point we are able to deploy workloads to the cluster. In the case of a fleet of edge devices you would want to automate this. The article Bring your own fleet with Red Hat Advanced Cluster Management for Kubernetes auto-import and automation tools has some suggestions on how to do that.
Using ACM to deploy and update applications
Now we get to the good part. We can now deploy an application to our edge device remotely through ACM. We can do that through the Applications page. There are a number of options when creating the application, as shown in Figure 15.
We chose to use a subscription. A subscription has a few options, as illustrated in Figure 15.
We chose Git ,which pulls the application from a GitHub repository and specified that the application should be deployed to the gas-station namespace. We’ll use the same gas-station GitHub repository that we’ve been using throughout the series:
https://github.com/mhdawson/gas-station
We added the deployment file that we took you through earlier to that repository:
https://github.com/mhdawson/gas-station/blob/main/deployment.yaml
We can specify the repository when creating the Git subscription along with other options like a subdirectory, branch, or specific tag, but because our deployment.yaml is at the top level we can keep it simple, as shown in Figure 16.
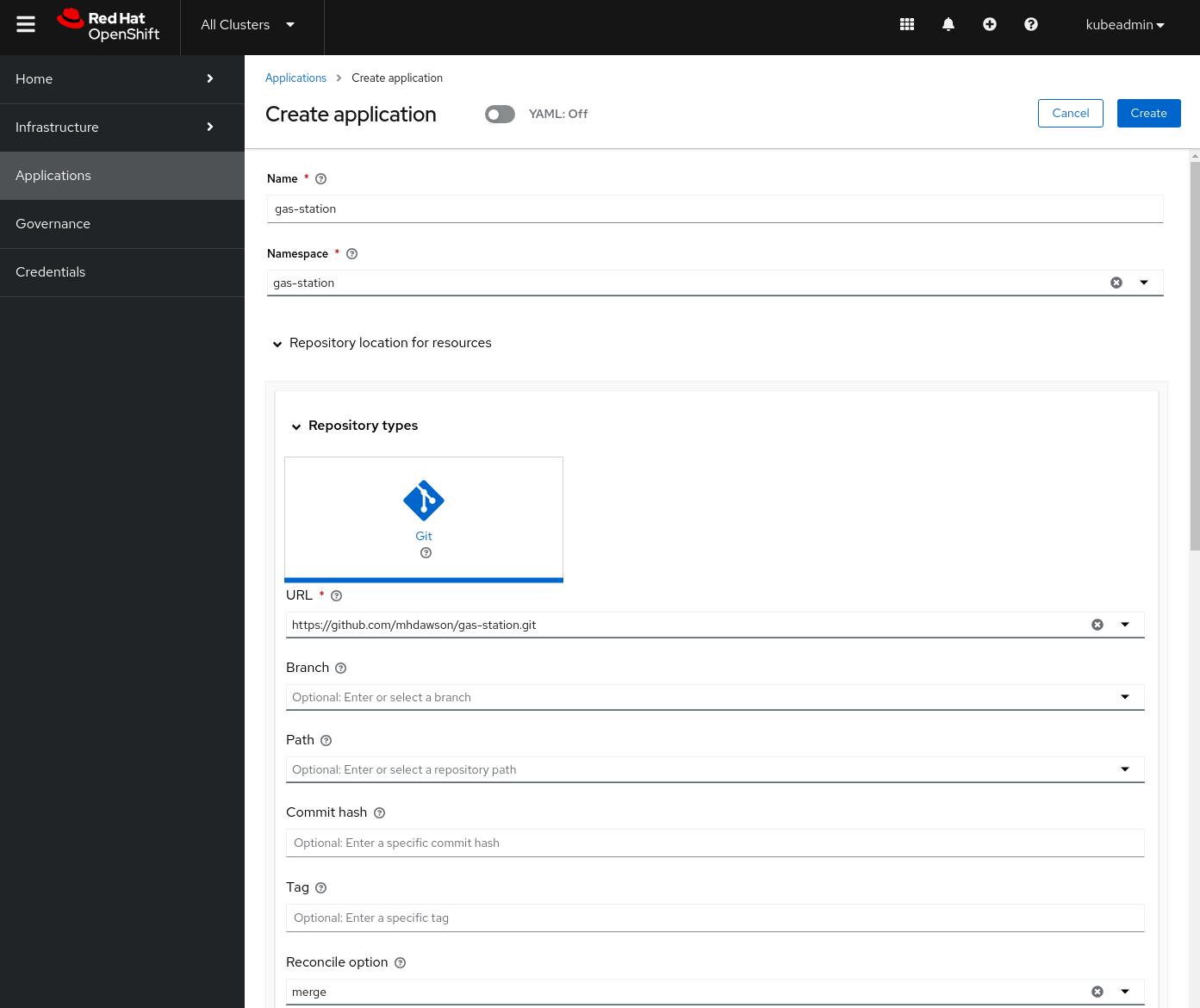
We can also select rules for which clusters the application will be deployed to, as shown in Figure 17. You can see how this could be used to deploy to a set of clusters that were labeled as being devices within different gas stations.
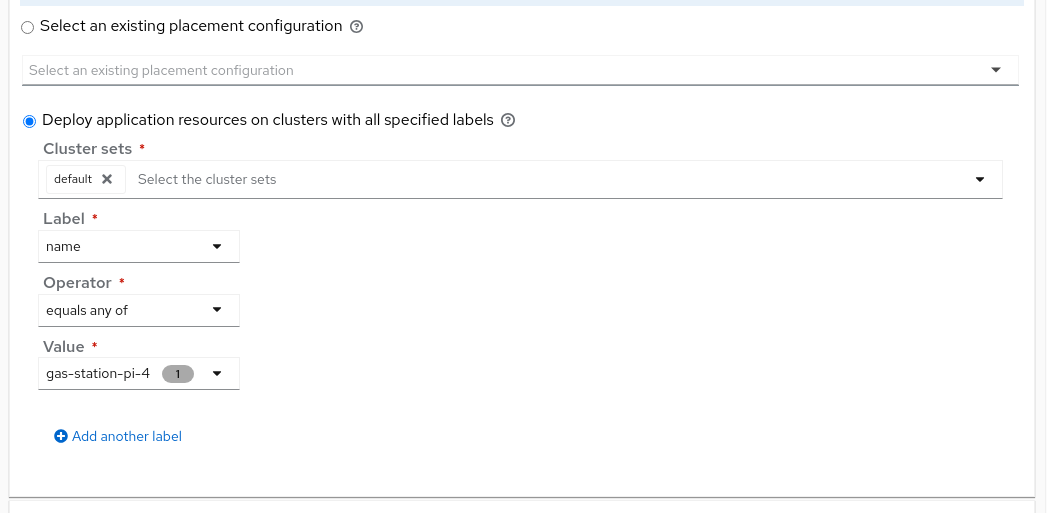
In our case we kept it simple and just specified a rule that matched the cluster running on our edge device.
Once we hit the Create button, the application is automatically deployed and will start running on the edge device. From the topology view we can see what was deployed, as shown in Figure 18.

Not only can see the deployed components, but we can look at logs and etc. for each of the components, as shown in Figures 19 and 20.
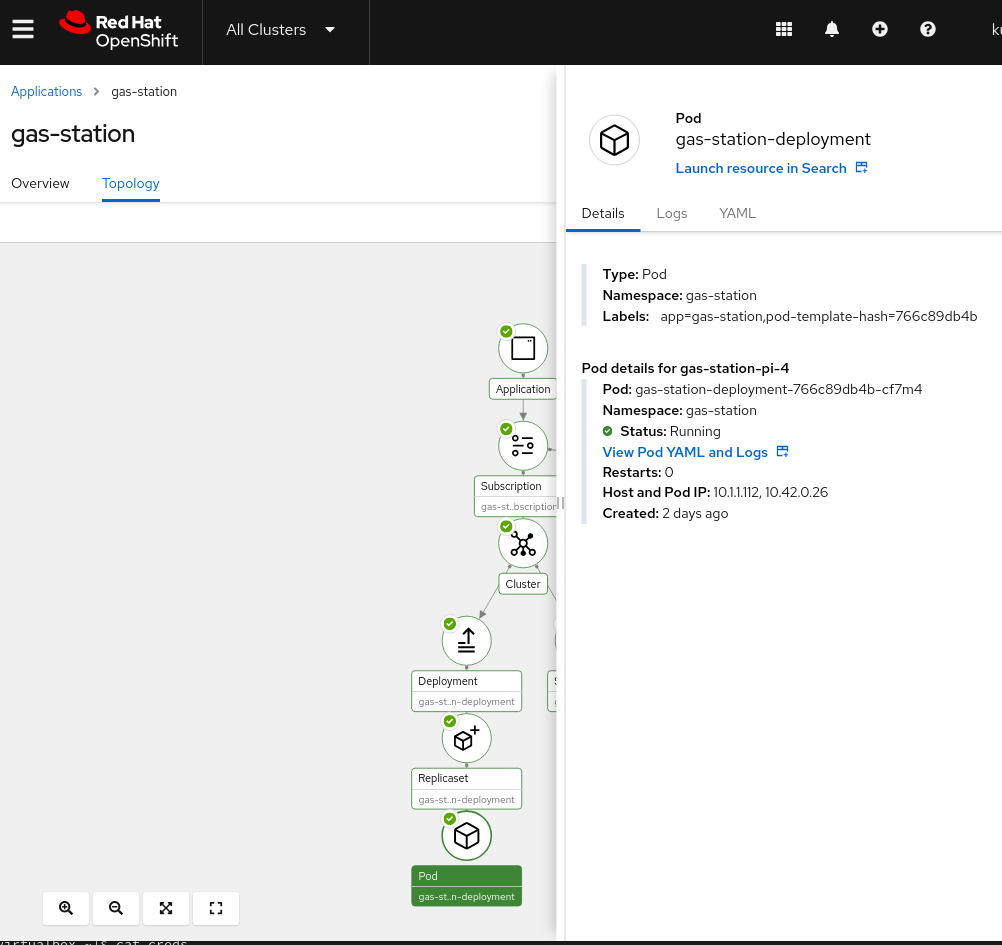

From those pages we can see that our Next.js application running on Node.js is up and running on the device.
We can also confirm that we can access the application by navigating to the port that was exposed (Figure 21):

If we want to expose the application on a different port (for example, 80 or 443) we could use a port forward as we did in the local deployment, or use use some of the other ingress options in Kubernetes.
To update the application, we can now:
- Push an updated version of the application to Quay.io and tag it appropriately.
- Update the deployment file in the GitHub repository for the application, for example move the tag from v0.1 to v0.2.
ACM checks the GitHub repository every minute by default and will update the deployed application when changes are detected. You can also ask for synchronization through the Sync option on the Overview page for the application as shown in Figure 22.
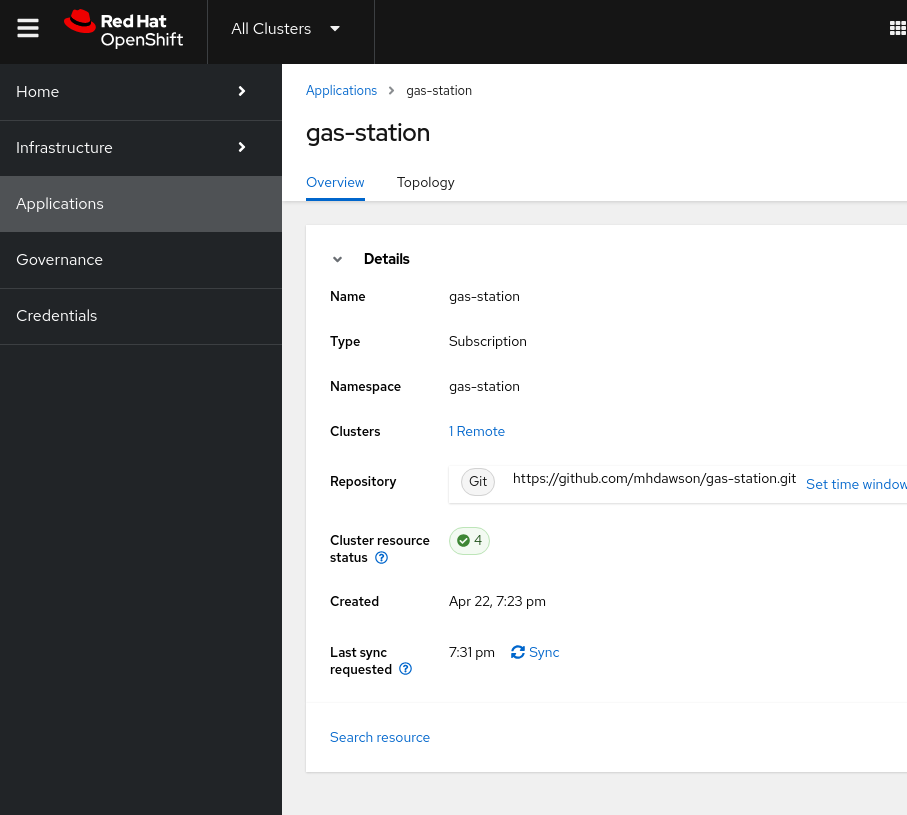
One of the key motivators for moving to Kubernetes was to get more control over when and how the application is updated. ACM provides a number of different options to control when an application will be updated after a change is detected in the GitHub repo. This can include specifying specific time windows, excluding time windows, and more. You can read about all of the options in the Scheduling a deployment section in the Managing applications section of the ACM documentation.
At this point we’ve achieved a high level of control over when and how the application is updated in the edge device and we’ve reached the end of our journey with remote management of the application as show in Figure 23:
Wrapping up
This three-part series on managing Node.js applications at the edge took you along the journey from manually building and installing a Node.js application on the edge device all the way to being able remotely deploy and update the application. Regardless of which endpoint along this journey makes sense to you, I hope this guide helped you learn about some of the considerations and options that are available, as well as how to navigate common the challenges along the way.
Node.js and JavaScript at the edge: The why, what, and how
You can watch the following video to learn more about building, deploying, and managing Node.js applications running on the edge.
If you would like to learn more about what the Red Hat Node.js team is up to, you can check out the Node.js product page, the Node.js topic page, and the Node.js Reference Architecture.