Usually, we think about IoT applications as something very special made for low power devices that have limited capabilities. For this reason, we tend to use completely different technologies for IoT application development than the technology we use for creating a datacenter's services.
This article is part 1 of a two-part series. In it, we'll explore some techniques that may give you a chance to use containers as a medium for application builds—techniques that enable the portability of containers across different environments. Through these techniques, you may be able to use the same language, framework, or tool used in your datacenter straight to the "edge," even with different CPU architectures!
We usually use "edge" to refer to the geographic distribution of computing nodes in a network of IoT devices that are at the "edge" of an enterprise. The "edge" could be a remote datacenter or maybe multiple geo-distributed factories, ships, oil plants, and so on.
In this article, we'll address a very common theme—the creation and distribution of containers—but our target environment will be an x86_64 edge gateway.
As you know, OpenShift is a great platform for application development. It's shipped with a Kubernetes orchestrator enriched with a fully integrated and containerized Jenkins, native “build” resources, and a very powerful web interface.
Consider the following real use case scenario, in which a customer asked for a way to create and test containers in a Platform as a Service (PaaS) environment for deployment at the edge.
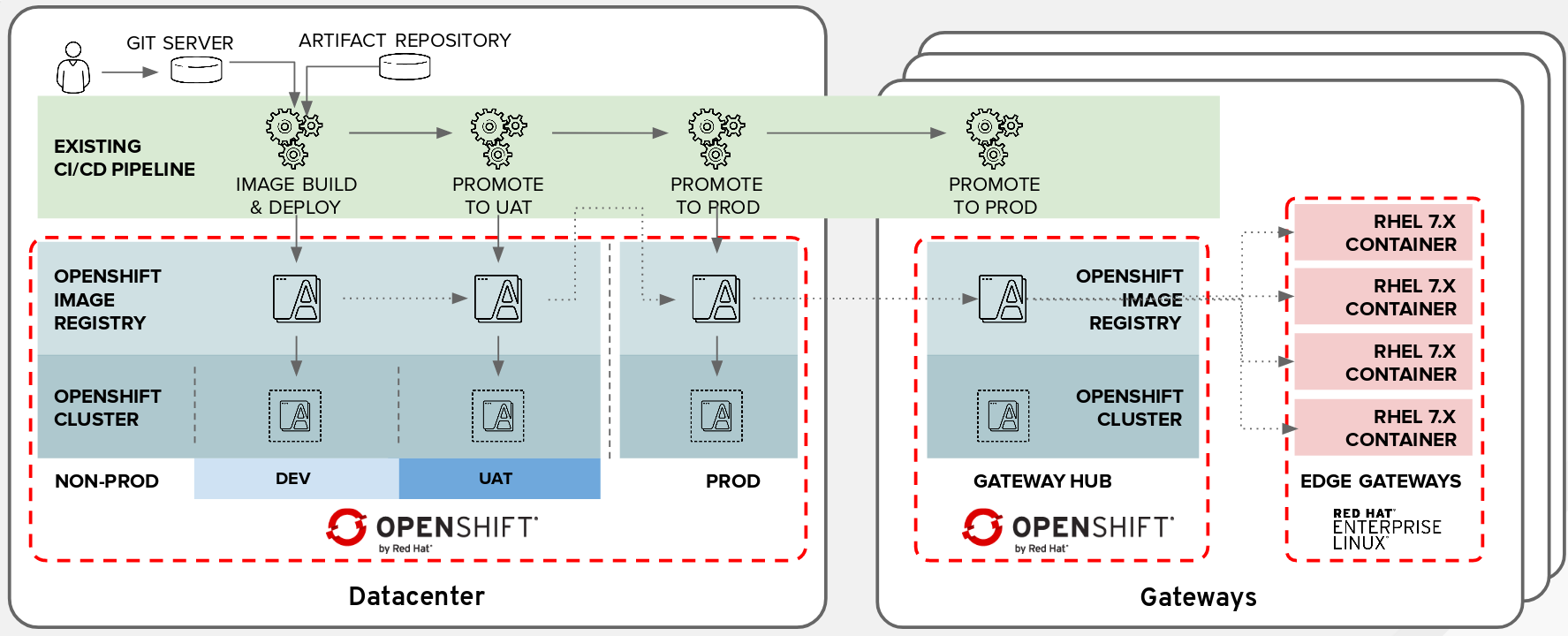
We used an existing standalone IoT demo application, splitting it into different projects to create truly independent containers.
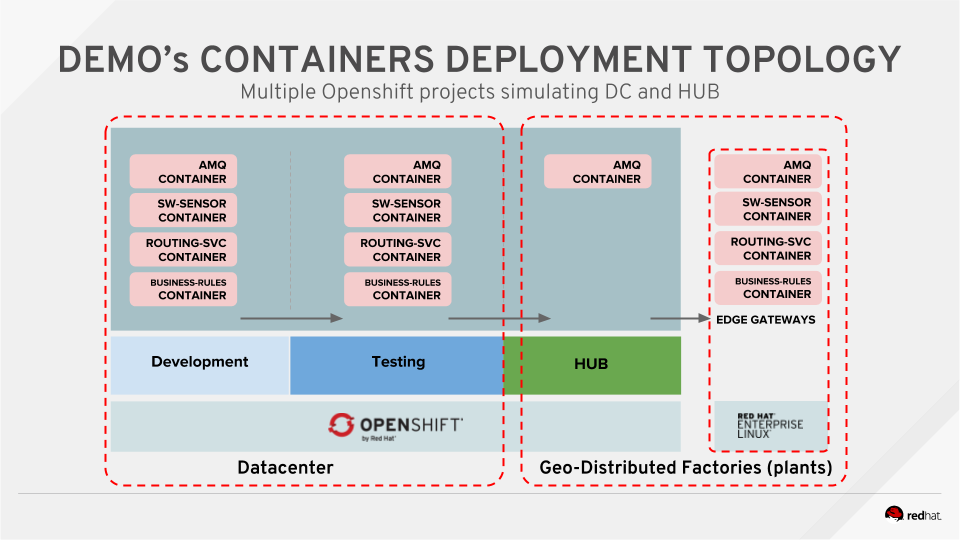
You'll find the initial demo project here and the main placeholder container project here.
The main project page also contains instructions for re-creating the demo environment on your platform.
As you'll see from the project's pages, the containerization process was not difficult, thanks to the usage of Red Hat AMQ queues for messaging.
We created three containers, one for each software brick of our standalone application demo, and then we created respective Jenkins pipelines in OpenShift, as shown in the following screenshot. Thanks to this containerization, every software piece may inherit a full, independent development environment and have independent testing activities.
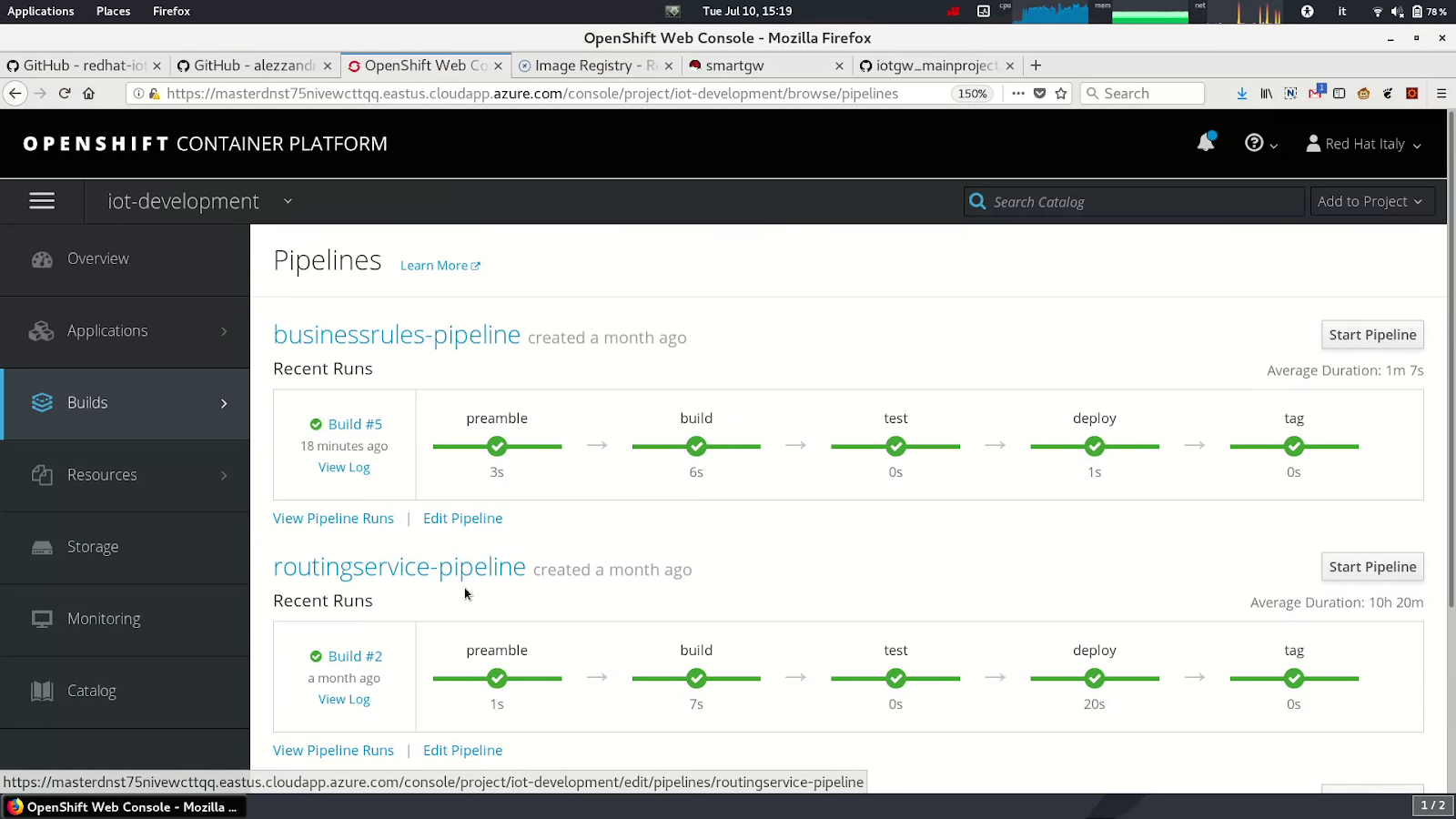
A benefit of the created pipelines and the independent project is that we can also leverage the OpenShift/Kubernetes features of project isolation and replication for testing our brand new containers in different environments.
Thanks to the containers' portability, the last step would be to push the containers onto a gateway hub, which is a secondary Red Hat OpenShift Container Platform setup in a remote factory, for deploying the developed applications onto the edge gateway.
I bet you’re guessing about the final deployment at the edge, right?
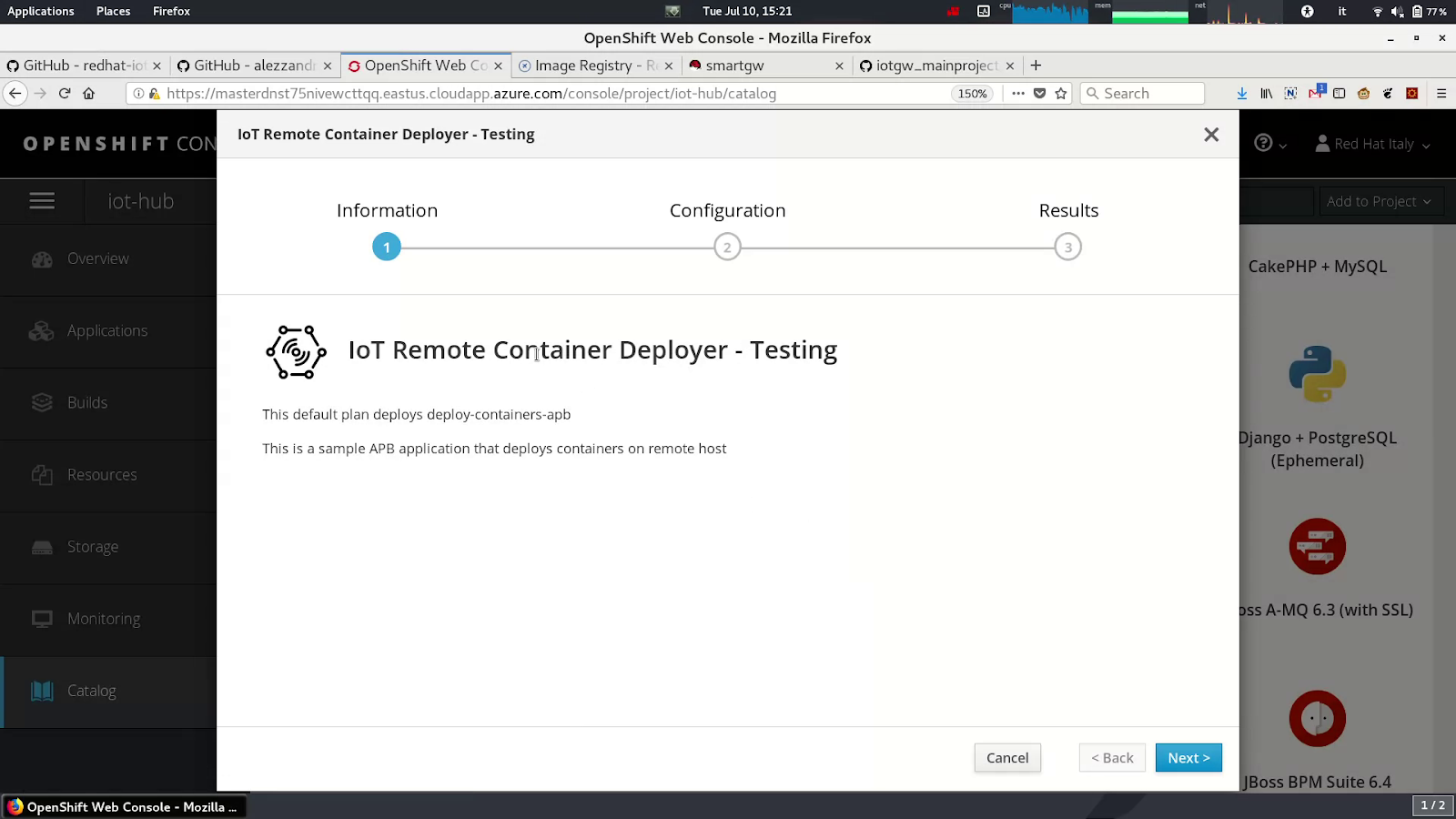
The final deployment will be handled by the central OpenShift platform or through the remote one (on an IoT hub, the "remote factory"), thanks to the Red Hat Ansible Automation suite.
OpenShift has a special feature included called OpenShift Ansible Service Broker. It follows the Open Service Broker API and let you use a common Ansible Playbook for invoking an internal service (a Kubernetes/OpenShift one) or an external service, for example, a virtual machine or just a remote gateway.
For this reason, we can leverage this feature to invoke a custom Ansible Playbook created for deploying the standalone containers on a remote system to test them.
Once we tested one or multiple deployments, we can then scale out the container distribution through Red Hat Ansible Tower using the same Ansible Playbook we developed and tested through OpenShift Ansible Service Broker.
The first version of our Ansible Playbook for remote container deployment leveraged the Docker daemon for their execution. We then enhanced it by replacing the daemon (a single point of failure) with standalone container execution, thanks to Podman and its systemd integration. (Read more about Podman in Red Hat Enterprise Linux and managing containerized system services.)
The main objective of this example is to show the powerful capabilities of a complete PaaS environment created on top of Kubernetes—the best and de facto container orchestrator—that is used for creating and testing containers for your IoT edge applications.
Are you curious to see a live demo? Take a look at this OpenShift Common Briefings recording, in which I presented live the solution:
https://www.youtube.com/watch?v=bNipu5OA1o4
Of course, this is just an example and every use case could be different, for example, introducing the need for a container architecture other than x86_64.
In the second and last part of this series, we’ll go over the creation, execution, and testing of multi-architecture containers on Red Hat OpenShift Container Platform. Stay tuned!
Additional resources
- Podman: Managing pods and containers in a local container runtime
- Managing containerized system services with Podman
- Containers without daemons: Podman and Buildah available in RHEL 7.6 and RHEL 8 Beta
- Podman – The next generation of Linux container tools
- Intro to Podman (New in Red Hat Enterprise Linux 7.6)
- Customizing an OpenShift Ansible Playbook Bundle
About Alessandro

