Note: The following is an excerpt from our The Path to GitOps e-book, which outlines Git best practices for GitOps deployment. Explore more best practices in Workflows for GitOps deployments.
When adopting GitOps, organizations must plan carefully to divide tasks and configuration files appropriately between repositories and directories in each repository. Standard practices have long existed for using Git-based workflows for infrastructure and software delivery. But with the dawn of cloud-native architectures and Kubernetes, you can now automate a wide range of deployments based on declarations stored in a Git repository.
The question of best practices comes up a lot when creating repositories for GitOps. There is no magic bullet, but several common patterns exist to match the various ways the organization interacts internally.
Conway's Law and GitOps
The overarching consideration when choosing a GitOps directory structure seems to fall under Conway's Law, which states:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.
— Melvin E. Conway
Applying Conway's law to GitOps, we can expect each team of developers to create its own branches and directories within a repository. Furthermore, the structure will be dictated by organizational boundaries (which can also be called “points of demarcation”), such as security, operations, regulatory concerns, etc.
In the following sections, we will discuss some best practices when structuring Git repositories and how you might arrange them based on experiences from different types of organizations.
One final note before diving in: These examples are designed to be a starting point, not a reflection of how your final repository will be represented.
Structuring your Git repositories
The following are general best practices when it comes to structuring your Git repositories for GitOps. They are designed to be generic to all GitOps implementations and are not tied to a particular toolset or technology.
DRY (Don't repeat yourself)
The acronym “DRY” stands for “Don't Repeat Yourself.” We can adapt it to a GitOps model by rewording it as “Don't Repeat YAML.” The idea is simple here; as described in the Templating chapter, storing everything in Git can sometimes lead to copying the same YAML over and over again in different places. Use the strategies described in that chapter to avoid duplication of YAML. Specifically, use Kustomize to keep the base configuration of your deployment and then store the deltas as patched overlays.
Parameterize where you need to
There are certain situations where patching isn't the best solution. Patching existing YAML is great when you already know the configurations and deltas beforehand. An example of this is the Ingress Object in Kubernetes. This configuration has a host field in the YAML manifest that is supposed to be filled in with the fully qualified domain name (FQDN) of the application being deployed. When you are deploying onto many clusters, the FQDNs of each one may not be known beforehand. Parameterizing your configurations makes sense in this scenario. This is where Helm shines, specifically when you use the lookup feature.
In the end, you will use a combination of tools to get your desired results, as I explained in the Templating chapter. Keep in mind that there is no “absolutely right” method to do things, and a lot will depend on your environment and communication structure. The main point of this is not to copy the same YAML everywhere.
Repository considerations
Before we go deeper into how your directory can be structured, there's another important consideration to keep in mind: How many repositories are you going to have?
As mentioned previously, this really all depends on how your enterprise is structured and where the boundaries lie. Also, the GitOps tool being used might have some limitations on handling repository structures that require other considerations that are out of scope for this discussion. But taking a high-level look at things, two patterns arise when considering the structure of repositories: monorepo and polyrepo.
Monorepo
In a monorepo environment, all the manifests for the entire environment, including end-user applications, cluster configuration, and cluster bootstrapping, are stored in a single Git repository. This pattern applies not just to one cluster: every potential cluster in your environment is represented in this single repository. Yes, dev and production would live in the same repo. Figure 1 shows the monorepo solution.
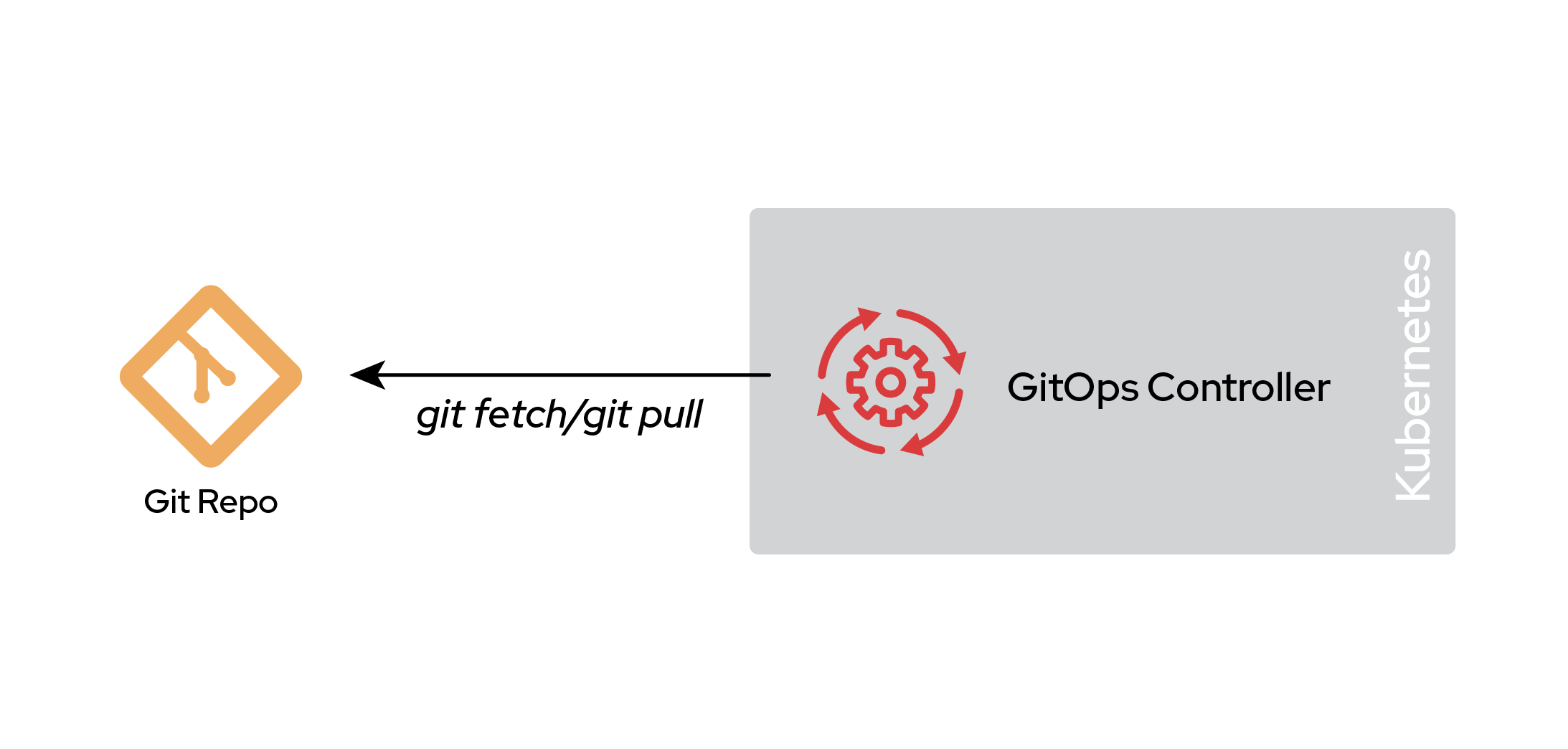
The clear advantage of a monorepo is that it provides a central location for configuration changes. This simplicity enables straightforward Git workflows that will be centrally visible to the entire organization, making for a smoother and clearer approval process and merging.
There are several disadvantages, however. The first is scalability. As your organization grows, your environment also needs to grow with it, increasing the overall complexity of each deployment. This can make a monorepo difficult (even impossible) to manage.
There are also performance issues, especially if you use Argo CD. As the monorepo grows and changes become more and more frequent, the GitOps controller (for example, Argo CD) takes considerably more time to fetch the changes from the Git repository. This can slow down the reconciliation process and might slow down the correction of deviations from your desired state.
In short, although a monorepo is a valid choice, it can be quickly outgrown by the evolving requirements of the organization's operational needs. It can work if the team managing the environment is small enough and the repository manages only a handful of applications, environments, and clusters. Usually, startups and organizations just starting out with GitOps prefer this approach, which is perfectly valid. Another possible use case is when operating in a lab or another environment with a very limited domain for action.
Polyrepo
A polyrepo environment contains multiple repositories, possibly to support many clusters or deployment environments. The basic idea is that a single cluster can have multiple repositories configured as a source of truth. Figure 2 illustrates how multiple repositories can manage a single cluster.
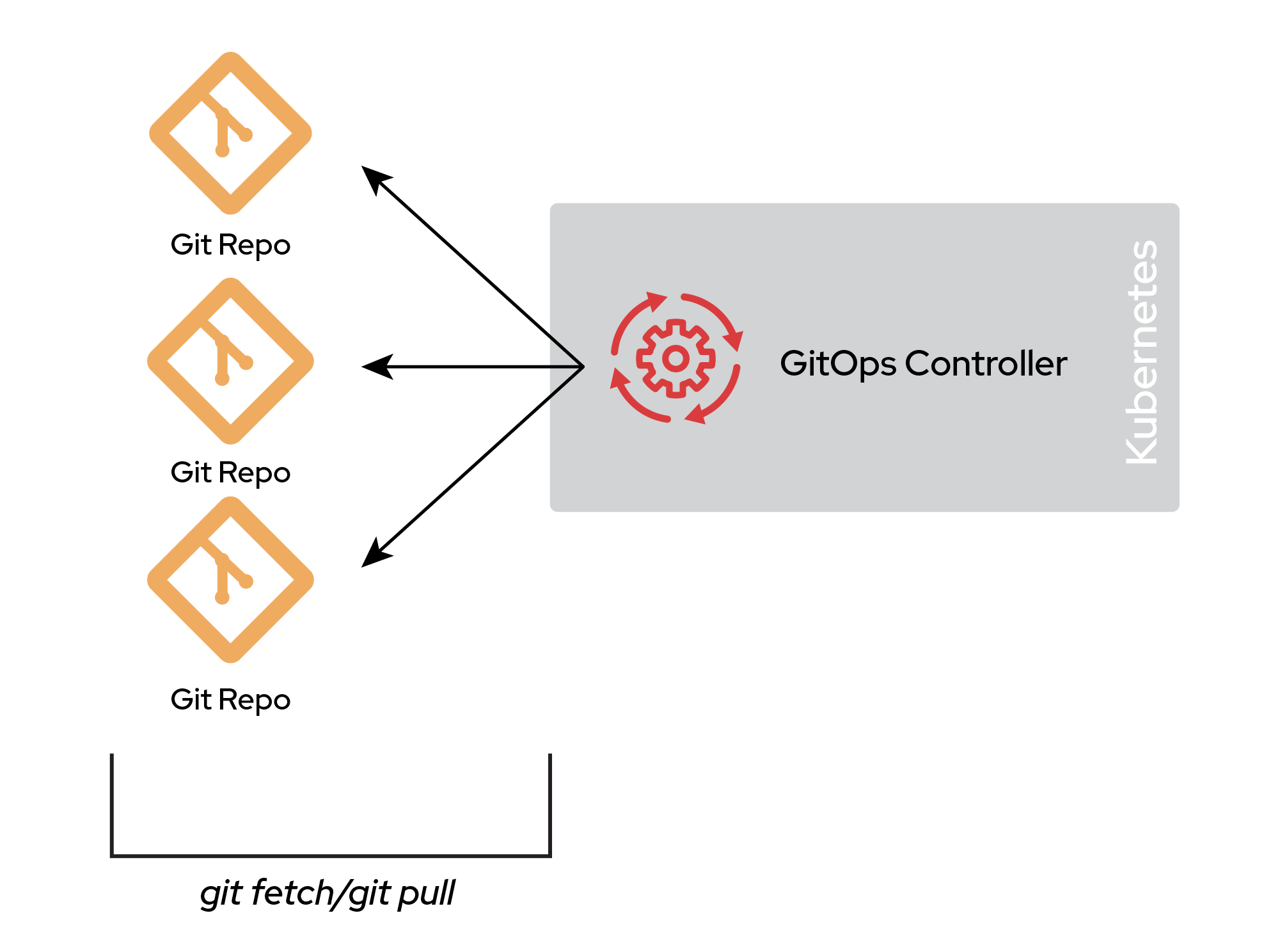
The differences between these Git repositories depend on several factors. A common example is separating concerns between different departments of an organization: a repository for the security team, a repository for the operations team, and one or more repositories for application teams. Another example involves multitenancy, where you have one repository per application.
You could run multiple GitOps controllers within a single cluster, or a GitOps controller can operate in a hub-and-spoke model, as shown in Figure 3.
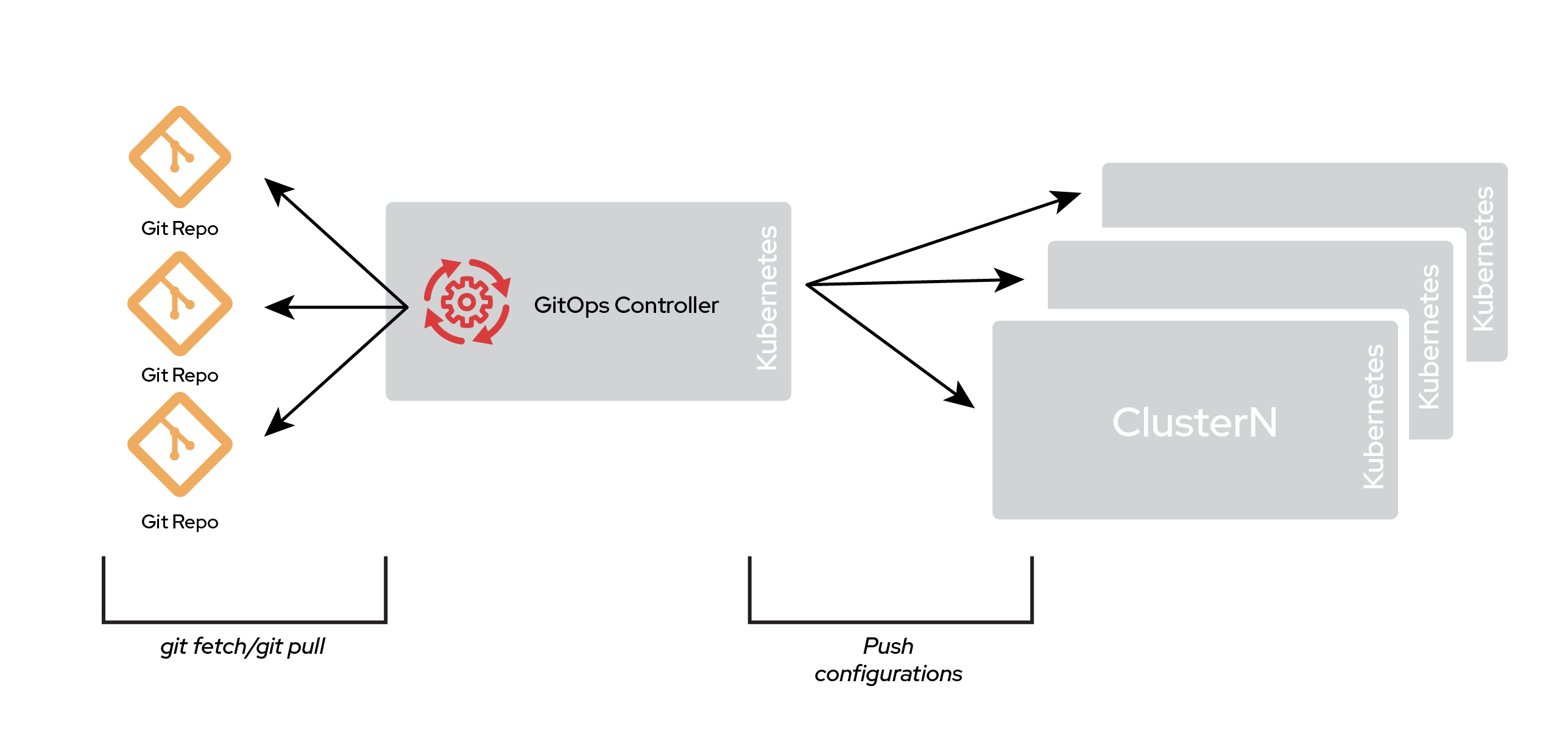
A polyrepo, therefore, permits many possible designs.
The primary characteristic of a polyrepo is that not everything is contained within a single repository and that you'll have a sort of catalog of what needs to go into an environment or cluster. The contents of these repositories are the topic of the next section.
One common polyrepo design is many-to-many, meaning that each repository points to a single cluster. This is a typical structure in a siloed organization where each team takes care of deploying its own infrastructure.
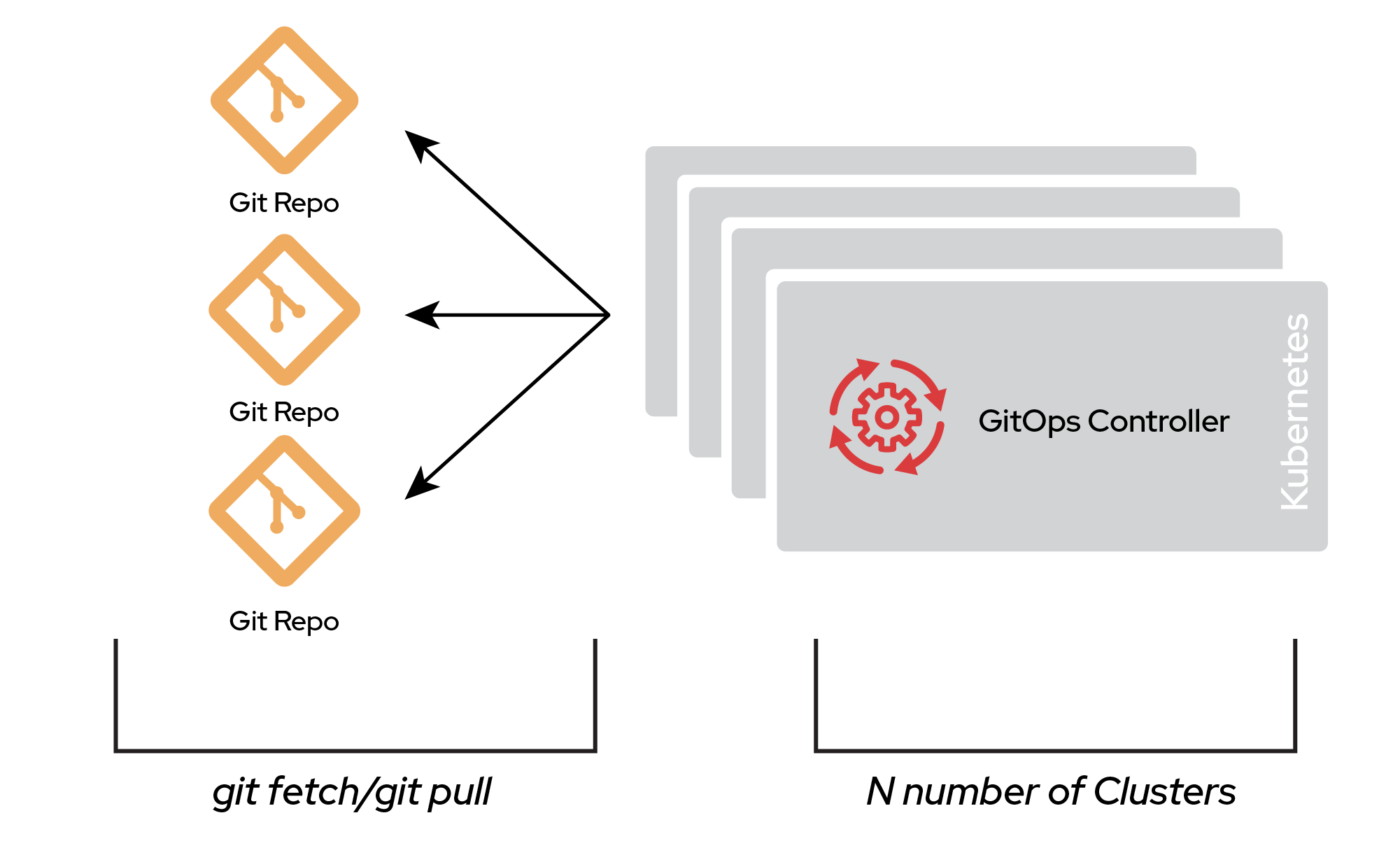
The drawback of a polyrepo is that it creates a large number of Git repositories to manage. The number of Git repositories depends on how your organization is laid out and how changes are managed. It's not unheard of for each repository to have its own associated Git workflow. This method can become hard to manage, but it scales incredibly well and is flexible enough to fit almost any organization.
Directory structures
As explained in the previous section, your Git repository structure will depend heavily on how your organization is laid out. The repositories reflect how your organization communicates with each other and how your current deployment workflow is represented. The different organizations with different workflows are often referred to as silos, but more accurately, they are boundaries. For example, developers won't modify platform configurations, whereas operators who work on platform configurations won't go in to change developers' code.
Within each repository, there are many different ways to organize directories. In this section, we'll focus on two use cases, showing both a monorepo and a polyrepo implementation. The polyrepo example shows how organizational boundaries influence the repositories. The monorepo example shows what a repository might look like for a specific cluster.
Repositories reflecting an organizational boundary
This example presents a simple use case with a single organizational boundary between the Kubernetes platform administrator and the Kubernetes application developer. This division between administrators and developers is standard.
Kubernetes platform administrator
The repository for the Kubernetes administrator is typically focused on getting the Kubernetes cluster bootstrapped (installed) and configured with the necessary components to run applications. The following is a sample of what the directory structure might look like:
├── bootstrap
│ ├── base
│ └── overlays
│ └── default
├── cluster-config
│ ├── gitops-controller
│ ├── identity-provider
│ └── image-scanner
└── components
├── applicationsets
├── applications
└── argocdproj
Note: The name of the directories are not important; you can change them to suit your needs/preferences. What's important is the layout and what the directories represent. The resources listed at the end of this article explain how to use other controllers, such as Flux, instead of Argo CD.
Here is a short explanation of the directories and files in this repository:
-
bootstrap: This stores bootstrapping configurations. These are items that get the cluster configured with the GitOps controller. The base directory contains YAML installation configuration, while overlays contain GitOps controller configurations. There is only one overlay, here calleddefault, because this is the only overlay in our simple example.The
defaultdirectory contains akustomization.yamlfile that hascomponents/applicationsets/andcomponents/argocdproj/as a part of its bases configuration. It will look something like the following:apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization bases: - ../../base - ../../../components/applicationsets - ../../../components/argocdproj
-
cluster-config: This is where YAML for the cluster's configuration manifest lives. The manifest determines the behavior of the cluster.The files under
gitops-controlleruse Argo CD to manage themselves. Thekustomization.yamlfile refers tobootstrap/overlays/defaultin its bases configuration. This directory gets deployed as an ApplicationSet incomponents/applicationsets/cluster-config-appset.yaml. components: This configures the GitOps controller (in this case, Argo CD).applicationsetscontains YAML for the ApplicationSets andargocdprojcontains YAML for the Argo AppProject.
The Application configured in the components directory can point to other Git repositories. The administrator uses the directory as a "point of entry" to onboard applications.
An administrator bootstraps a cluster by running:
$ kubectl apply -k bootstrap/overlays/default
This command loads in all the configurations and deploys the cluster-specific configurations onto the Kubernetes cluster.
Kubernetes application developer
The repository for the Kubernetes application developer is actually pretty straightforward. It’s one of the last components that lands on a cluster, so it lets you be very terse and make assumptions about what previous configurations have already done. Most of the groundwork has already been implemented on the clusters by other personas. A typical directory structure is:
└── deploy
├── base
└── overlays
├── dev
├── prod
└── stage
The bulk of the configuration is in the base directory, and only the deltas are stored in overlays. This example shows environments such as dev and prod, but can also be other configurations (such as clusters). This layout does make a lot of assumptions, but the idea is that the cluster will already come configured.
The YAML files stored in this layout won’t state a namespace in their metadata sections. This is because the creation and management of namespaces are typically controlled by the Kubernetes administrator. This may change from organization to organization, so it is not a hard and fast rule, but it’s something to keep in mind and communicate about.
Although the GitOps tool deploys the application, an example deployment into the dev environment would look like this:
$ kubectl apply -k deploy/overlays/dev
The dev overlay consumes all the YAML in base and overlay the deltas. Since most GitOps tools support Kustomize, the combination allows a flexible deployment. For example, if one cluster is administered through Flux and another through Argo CD, this structure would work for both clusters.
Other boundaries
The previous section showed a simple use case to illustrate how the division of responsibilities can dictate the contents and structure of the repositories. Best practices are similar when an organization has more than just two boundaries. Other common roles that define boundaries are Kubernetes service site reliability engineer (SRE), Kubernetes security team, and application release manager.
GitOps repo example
This example shows how a repository can be laid out using the DRY principle and keep the structure generic enough to deploy to many clusters. This example also assumes "full DevOps," where the entire organization (both Kubernetes administrators and Kubernetes developers) is taking part, working together in the release process.
This example, like the previous one, is based on using Argo CD as the GitOps controller:
├── bootstrap
│ ├── base
│ └── overlays
│ └── default
├── components
│ ├── applicationsets
│ └── argocdproj
├── core
│ ├── gitops-controller
│ └── sample-admin-workload
└── apps
├── bgd-blue
│ ├── base
│ └── overlays
│ ├── dev
│ ├── prod
│ └── stage
└── myapp
├── base
└── overlays
├── dev
├── prod
└── stage
The basic components of the structure are:
bootstrap: This plays the same role as thebootstrapdirectory in the previous example.components: This plays the same role as the components directory in the previous example. Manifests that can live here include role-based access control (RBAC), Git repository secrets, and configuration files specific to the Git controller, Argo CD. Each configuration has its own directory.-
core: This contains YAML for the core functionality of the cluster. The Kubernetes administrator places resources here that are necessary for the functionality of the cluster, such as cluster configurations and cluster workloads.The files under
gitops-controlleruse Argo CD to manage themselves. Thekustomization.yamlfile refers tobootstrap/overlays/defaultin its bases configuration. This directory gets deployed as an ApplicationSet incomponents/applicationsets/core-components-appset.yaml.To add a new "core functionality" workload, the administrator adds a directory with YAML content in the core directory.
-
apps: This is where the workloads for this cluster live. Similar tocore, this directory gets loaded as part of an ApplicationSet undercomponents/applicationsets/tenants-appset.yaml.The
appsdirectory is where developers and release engineers work. They just need to commit a directory with some YAML, and the ApplicationSet takes care of creating the workload.The
bgd-blue/kustomization.yamlfile can point to another Git repository. Thus Kustomize helps you with your YAML in many repositories, if this is convenient. Thebgd-bluedirectory can also be a Git submodule.
Summary
In this article, we discussed best practices for creating GitOps repository and directory structures. Although there are generic examples that you can follow, there is no one answer. Your directory structure is going to be driven by your organizational structure and possibly regulatory considerations as well. However, following these basic best practices can help lead you in the right direction.
To get you started working with GitOps directory structures, I provide several starting points in the following repositories:
Next steps
Download The Path to GitOps to explore how GitOps fits in your CI/CD (continuous integration/continuous delivery) pipelines and the various ways to implement it. Discover popular tools like Argo CD and Flux and learn how Kustomize, Helm, and Kubernetes Operators make it easier to deal with lengthy configuration files.
Find even more GitOps resources from Red Hat Developer:
- Getting GitOps: A practical platform with OpenShift, Argo CD, and Tekton helps you put it all together by walking through a common use case from beginning to end.
- Get a preview of GitOps Cookbook, a collection of useful recipes to follow GitOps practices on Kubernetes.