In this article, we will demonstrate a few use cases for Network Observability CLI. We will also explain how to capture and identify traffic, check connectivity between two endpoints, determine the User Defined Networks involved, and display packets payload.
If you haven't read it yet, take a look at our Network Observability CLI 1.8 update article, to discover seven new features introduced in release 1.8.
Use cases for Network Observability CLI
For each of the following use cases, you must have the netobserv CLI installed and must be connected to your cluster using the following command:
oc login <CLUSTER_API_URL> --username <CLUSTER_ADMIN> --password <PASSWORD>To observe what the command line interface (CLI) deploys on your cluster, you can run the oc events -n netobserv-cli -w command to watch all the events happening in the netobserv-cli namespace.
The result looks like this:
LAST SEEN TYPE REASON OBJECT MESSAGE
0s Normal SuccessfulCreate DaemonSet/netobserv-cli Created pod: netobserv-cli-t2vlr
0s Normal Scheduled Pod/netobserv-cli-t2vlr Successfully assigned netobserv-cli/netobserv-cli-t2vlr to ip-10-0-1-202.ec2.internal
0s Normal SuccessfulCreate DaemonSet/netobserv-cli Created pod: netobserv-cli-hlmxx
0s Normal Scheduled Pod/netobserv-cli-hlmxx Successfully assigned netobserv-cli/netobserv-cli-hlmxx to ip-10-0-1-220.ec2.internal
0s Normal Pulling Pod/netobserv-cli-t2vlr Pulling image "quay.io/netobserv/netobserv-ebpf-agent:main"
0s Normal Pulling Pod/netobserv-cli-hlmxx Pulling image "quay.io/netobserv/netobserv-ebpf-agent:main"
0s Normal Pulled Pod/netobserv-cli-hlmxx Successfully pulled image "quay.io/netobserv/netobserv-ebpf-agent:main" in 2.049s (2.049s including waiting)
0s Normal Created Pod/netobserv-cli-hlmxx Created container netobserv-cli
0s Normal Started Pod/netobserv-cli-hlmxx Started container netobserv-cli
0s Normal Pulled Pod/netobserv-cli-t2vlr Successfully pulled image "quay.io/netobserv/netobserv-ebpf-agent:main" in 5.376s (5.376s including waiting)
0s Normal Created Pod/netobserv-cli-t2vlr Created container netobserv-cli
0s Normal Started Pod/netobserv-cli-t2vlr Started container netobserv-cli
0s Normal Scheduled Pod/collector Successfully assigned netobserv-cli/collector to ip-10-0-1-220.ec2.internal
0s Normal AddedInterface Pod/collector Add eth0 [10.129.0.35/23] from ovn-kubernetes
0s Normal Pulling Pod/collector Pulling image "quay.io/netobserv/network-observability-cli:main"
0s Normal Pulled Pod/collector Successfully pulled image "quay.io/netobserv/network-observability-cli:main" in 1.724s (1.724s including waiting)
0s Normal Created Pod/collector Created container collector
0s Normal Started Pod/collector Started container collectorCapturing traffic
The CLI is able to read configurations from cluster-config-v1 and network to identify Machine, Pods, and Services subnets using the --get-subnets option. This automatically adds SrcSubnetLabel and DstSubnetLabel to your flows.
You can see the configuration of subnets during the creation of the agents as follows:
creating flow-capture agents:
opt: get_subnets, value: true
Found subnets:
Services: "172.30.0.0/16"
Pods: "10.128.0.0/14"
Machines: "10.0.0.0/16"Once it's running, you can cycle to different views using the left/right arrow keys and change the displayed enrichment columns using the page up/down keys. Also, to adapt to your screen height, you can increase/decrease the number of displayed flows using the up/down arrow keys, as shown here:
Running network-observability-cli as Flow Capture
Log level: info Duration: 34s Capture size: 32.348
Options: get-subnets
Showing last: 35 Use Up / Down keyboard arrows to increase / decrease limit
Display: Standard Use Left / Right keyboard arrows to cycle views
Enrichment: Subnet Label Use Page Up / Page Down keyboard keys to cycle enrichment scopes
End Time Src Subnet Label Dst Subnet Label Interfaces
10:54:14.432000 Machines Machines etho,br-ex
10:54:14.432000 n/a Pods genev_sys_6081,62514f803736b1f,eth0
...
Type anything to filter incoming flows in viewYou can live-filter this capture by typing a keyword (e.g., Machines, Pods, or Services) to see only what you look for here.
However, if you only want to capture a subset of these flows, you can use the regexes filter on top, as in the following example:
oc netobserv flows --get-subnets --regexes=SrcSubnetLabel~Pods,DstSubnetLabel~ServicesWarning:
Running regexes filters means that all the flows are captured and enriched before applying this filter stage in the pipeline. To avoid performance impact on your cluster, use eBPF filters such as IPs, Ports and Protocol as much as possible.
Connectivity check(s) between two endpoints
Let's start with a simple case where you have a pod unable to reach an endpoint. We will use a simple Node.js sample app deployed in connectivity-scenario namespace for this demo (Figure 1).

This could be related to many issues such as:
- DNS issue
- Policy or kernel drops
- Configuration issue (such as UDN)
- Timeouts
Since we don't know what to look for yet, we should enable all the features using this option:
--enable_allBy clicking the pod name, we can see that our current pod IP is 10.129.0.48. To capture all the traffic going in and out of the pod, we use the following command to filter:
--peer_ip=10.129.0.48Alternatively, you could also use the service port:
--port=3001Finally, you can add a node selector label on top as follows:
--node-selector=kubernetes.io/hostname:my-nodeWarning:
Running the capture without filtering is also an option, but it is not recommended because it collects all the flows of the cluster. Depending on the size of your cluster, this could be too much and make the collector pod crash.
The following command runs flow capture with all the features on our pod IP:
oc netobserv flows --enable_all --peer_ip=10.131.0.19This script connects to your cluster and starts deploying eBPF agents and collector pod:
Checking dependencies...
'yq' is up to date (version v4.43.1).
'bash' is up to date (version v5.2.26).
Setting up...
cluster-admin
creating netobserv-cli namespace
namespace/netobserv-cli created
creating service account
serviceaccount/netobserv-cli created
clusterrole.rbac.authorization.k8s.io/netobserv-cli unchanged
clusterrolebinding.rbac.authorization.k8s.io/netobserv-cli unchanged
creating collector service
service/collector created
creating flow-capture agents:
opt: pkt_drop_enable, value: true
opt: dns_enable, value: true
opt: rtt_enable, value: true
opt: network_events_enable, value: true
opt: udn_enable, value: true
opt: pkt_xlat_enable, value: true
opt: filter_peer_ip, value: 10.129.0.19
daemonset.apps/netobserv-cli created
Waiting for daemon set "netobserv-cli" rollout to finish: 0 of 2 updated pods are available...
Waiting for daemon set "netobserv-cli" rollout to finish: 1 of 2 updated pods are available...
daemon set "netobserv-cli" successfully rolled out
Running network-observability-cli get-flows...
pod/collector created
pod/collector condition metOnce that is done, it connects to the collector and displays this output:
------------------------------------------------------------------------
_ _ _ _ ___ _ ___
| \| |___| |_ ___| |__ ___ ___ _ ___ __ / __| | |_ _|
| .' / -_) _/ _ \ '_ (_-</ -_) '_\ V / | (__| |__ | |
|_|\_\___|\__\___/_.__/__/\___|_| \_/ \___|____|___|
------------------------------------------------------------------------
INFO[0000] Log level: info
Option(s): enable_all|peer_ip=10.129.0.19
INFO[0000] Kernel version: 5.14.0-427.50.1.el9_4.x86_64
INFO[0000] Starting Flow Capture...
INFO[0000] Creating database...
INFO[0000] flows.db created
INFO[0000] Create flows table...
INFO[0000] flows table created At this stage, the collector waits for incoming data. If nothing shows up yet, it means that no traffic has been captured. Try to open the route of your application or update the filters of the capture.
If you are using a standard cluster, cycle to the packet drops view. In this output, we see that the traffic is dropped by OVS:
Dropped Bytes Dropped Packets Drop State Drop Cause Drop Flags
74B 1 TCP_SYN_SENT OVS_DROP_EXPLICIT 2
74B 1 TCP_SYN_SENT OVS_DROP_EXPLICIT 2You will need to investigate to get to the root cause. But it's probably a configuration, such as a network policy.
If you are using the TechPreview feature, cycle to the network events view. In the following output, we see that the traffic is blocked by a network policy:
Network Events
Dropped by network policies isolation in namespace connectivity-scenario, direction IngressEdit your network policies and give it another try.
Behind the scenes of our scenario, we used to have a deny all on the pod label:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: deny-nodejs
namespace: connectivity-scenario
spec:
podSelector:
matchLabels:
app: nodejs-basic
policyTypes:
- Ingress
- EgressOnce you've updated your policies, you can try to reach your route until you fix the issue. The network event disappears and your route should open correctly now. You can also ensure that the round trip time (RTT) is correct. If you are still experiencing issues with the route, you may update/get rid of the filter(s) and play with live filtering.
While running a capture, you can place additional live filters to the view by simply typing keywords, such as nodejs:
Live table filter: [nodejs] Press enter to match multiple regexes at onceAnd add as many keywords as you want by pressing enter:
Live table filter: [nodejs ip-10-0-1-220.ec2.internal genev_sys FlowDirection:1] Press enter to match multiple regexes at onceIf your deployment involves some DNS resolution, you can switch to the DNS display to show latencies and errors. Once you've updated your policies, you can try again to open your route url until you fix the issue:
Time SrcHostName DstHostName DnsId DnsLatency DnsRCode
10:59:42.459000 n/a ip-10-0-1-202.ec2.internal 20291 2ms NXDomain
10:59:42.459000 n/a ip-10-0-1-202.ec2.internal 64890 2ms NoError
10:59:42.459000 n/a ip-10-0-1-202.ec2.internal 52733 2ms NoErrorThose NxDomain errors could be from a misconfiguration in your app deployment trying to reach the wrong domain.
To check which network is involved, you can switch to Network Name enrichment and UDN display. This will show you which network name, interfaces, direction, and User Defined Network name are involved:
End Time Src Network Name Dst Network Name Interfaces Interface Dirs UDN labels
10:18:05.776000 ovn-kubernetes ovn-kubernetes ens5 Ingress None
10:18:05.776000 ovn-kubernetes ovn-kubernetes 74090695c33f2d4,ens5 Egress,Ingress None, NoneOnce you are done, simply press CTRL + C to exit. Your capture is copied to your local machine for post mortem analysis.
That's the end of the first scenario for connectivity checks.
User Defined Network (developer preview)
In the developer preview, you can enrich flows to get User Defined Network (UDN) information by using the --enable_udn_mapping option.
To configure your UDNs, refer to the official documentation.
Our primary UDN in this example is defined as follows:
apiVersion: k8s.ovn.org/v1
kind: UserDefinedNetwork
metadata:
name: primary-udn
namespace: user-defined-network
spec:
layer2:
role: Primary
subnets:
- 10.0.0.0/24
topology: Layer2Once everything is configured, you can inspect your pod's YAML and look for the k8s.v1.cni.cncf.io/network-status annotation:
kind: Pod
apiVersion: v1
metadata:
name: pod-a
namespace: user-defined-network
...
annotations:
...
k8s.v1.cni.cncf.io/network-status: |-
[{
"name": "ovn-kubernetes",
"interface": "eth0",
"ips": [
"10.131.0.35"
],
"mac": "0a:58:0a:83:00:23",
"dns": {}
},{
"name": "ovn-kubernetes",
"interface": "ovn-udn1",
"ips": [
"10.0.0.4"
],
"mac": "0a:58:0a:00:00:04",
"default": true,
"dns": {}
}]
...Note that eth0 is the default pod network, and ovn-udn1is the User Defined Network. We will filter on its IP: 10.0.0.4. Since this IP is not unique across the cluster, we can add a filter on the port 8080 (used in this example) and the node annotation kubernetes.io/hostname=ci-ln-cfqkhfb-72292-6l8l5-worker-c-lrr4q matching the node running this pod.
Putting it all together, the command is as follows:
oc netobserv flows --enable_udn_mapping --peer_ip=10.0.0.4 --port=8080 --node-selector=kubernetes.io/hostname:ci-ln-cfqkhfb-72292-6l8l5-worker-c-lrr4qWhen you run the command, it waits for the flows to come. In this scenario, we simply run a curl command between two pods under the same UDN.
Once you get your flows, you can cycle to the UDN mapping display to see which UDN is involved:
UDN labels
user-defined-network/primary-udn, user-defined-network/prinary-udnThen retrieve the namespace user-defined-network and the name primary-udn from the UDN labels column.
Identifying unknown traffic content
In this next scenario, we will dig into unknown packets using unencrypted traffic on the TCP protocol on port 80. We usually avoid such usage on a production cluster, but would like to understand who's involved.
For demo purposes, we will again use a Node.js basic deployment, exposing unencrypted traffic on port 80 in the packet-capture-scenario namespace.
Let's start a packet capture using the following command:
oc netobserv packets --protocol=TCP --port=80Similar to the previous scenario, the script connects to your cluster and starts deploying the eBPF agents and collector pod, but capturing full packet content this time.
Once the first packet is captured, you'll see the following table showing the amount of packets and bytes:
Running network-observability-cli as Packet Capture
Log level: info Duration: 1m52s Capture size: 36KB
Options: port=80
Showing last: 35 Use Up / Down keyboard arrows to increase / decrease limit
Display: Standard Use Left / Right keyboard arrows to cycle views
Enrichment: None Use Page Up / Page Down keyboard keys to cycle enrichment scopes
End Time Src IP Src Port Dst IP Dst Port Interfaces
02:47:55.180000 172.30.68.174 80 (http) 10.128.0.16 43236 n/a
02:47:55.180000 10.128.0.16 43236 172.30.68.174 80 (http) n/a
02:47:55.180000 10.128.0.16 43236 172.30.68.174 80 (http) n/a
...
Live table filter: [10.] Press enter to match multiple regexes at onceYou can cycle between the views to see IPs and ports instead of resources.
Let the capture run long enough to get several packets and press CTRL + C to exit. Open the generated pcap file using Wireshark and look for your IP as source, as shown in Figure 2.
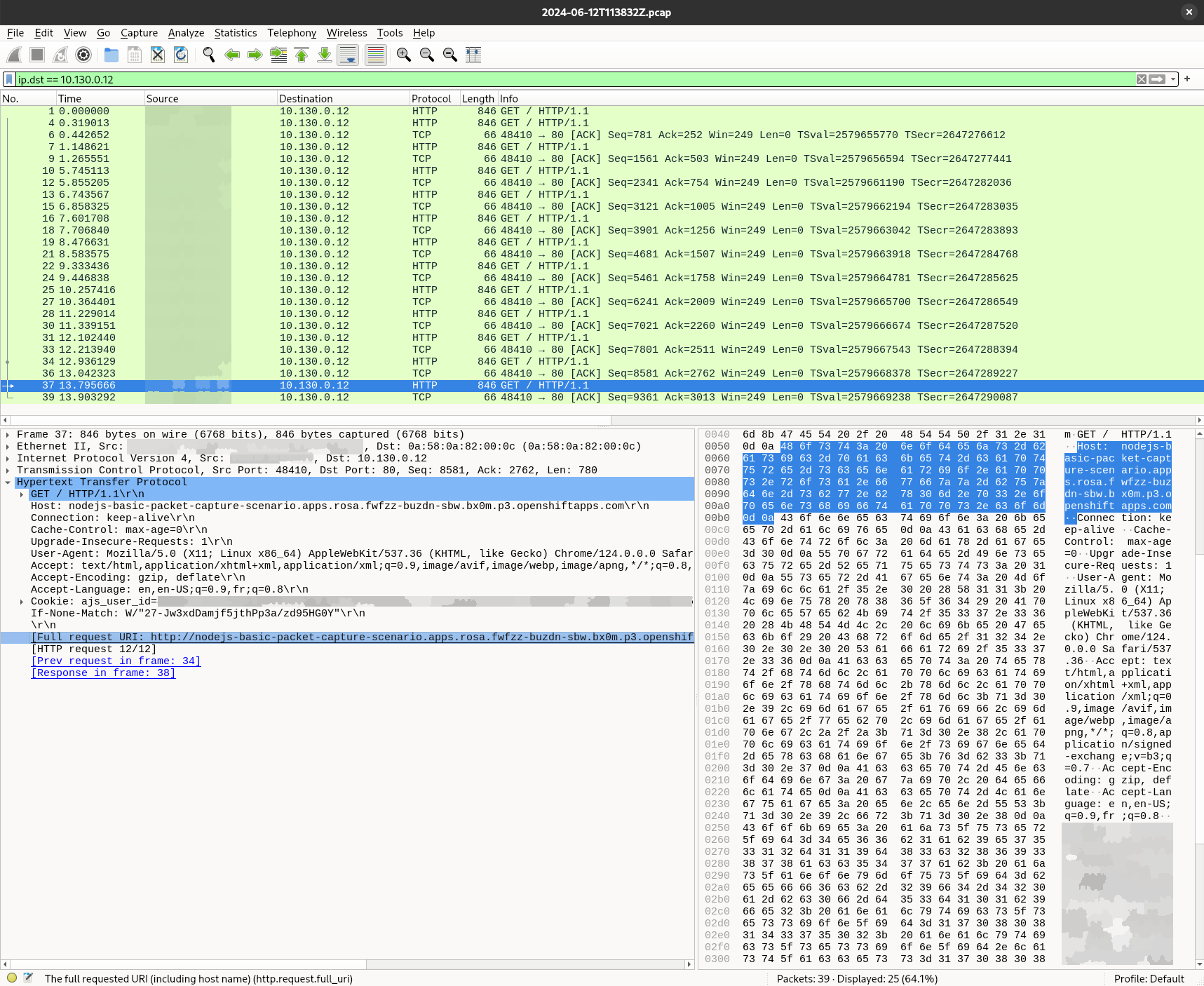
This time we can see the HTTP content including the request URL and response. Since we have the entire payload, we can check for any authentication header, cookie, encoding, etc. that may be wrong. This is useful to identify traffic content and debug a deployment that may be misconfigured or requesting unexpected content on unencrypted connections.
What about encrypted traffic?
Most of the time, your traffic should be secured, and you do not have access to the data it holds. Wireshark can decrypt the content if you provide the proper secrets. However, getting these secrets may be tricky depending on where the encryption happens and may require some juggling.
If you are looking for the traffic between your browser and the cluster, you can simply run the following command to capture the pre-master-secret keylog file:
SSLKEYLOGFILE="keylog.txt" chromium-browser &The generated file contains each client and server traffic secrets to decode your packets.
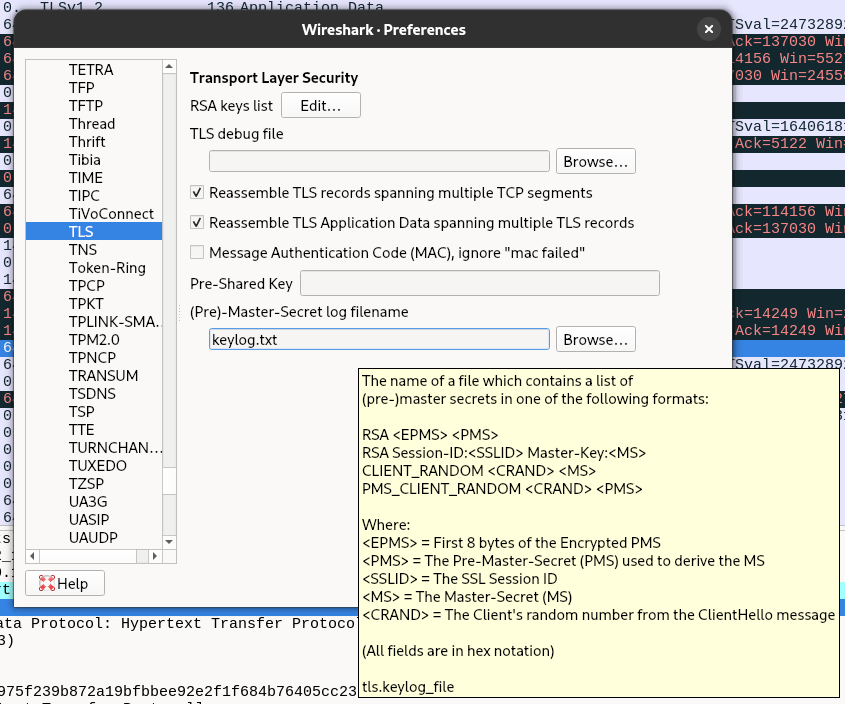
In Wireshark, specify the file path in Edit→Preferences→Protocols→TLS→(Pre)-Master-Secret log filename.
A single file can hold keys for multiple TLS connections, as shown in Figure 3.
You should now have access to decrypted packets.
What about a secure connection between two pods? In this case, you need to have a good understanding of what's involved behind the scenes. If your application relies on OpenSSL, GnuTLS or NSS TLS library, you should be able to set the SSLKEYLOGFILE environment variable and extract the result.
For our Node.js example, you need to either use the CLI option --tls-keylog or modify the code and subscribe on the keylog event. When multiple teams are involved, this may take a while.
Another alternative is a man-in-the-middle (MitM) approach using a proxy with kubetap.
Run the following command to install it using krew:
oc krew install tapThen run the following command to port forward the traffic of your service to the proxy:
oc tap on -n packet-capture-scenario -p 3001 --https nodejs-basic --port-forwardThe output should look like this:
Establishing port-forward tunnels to Service...
Port-Forwards:
mitmproxy - http://127.0.0.1:2244
nodejs-basic - http://127.0.0.1:4000Open the mitm proxy URL and generate a query to your route. You will see queries listed in the proxy web UI with the content displayed, as depicted in Figure 4.
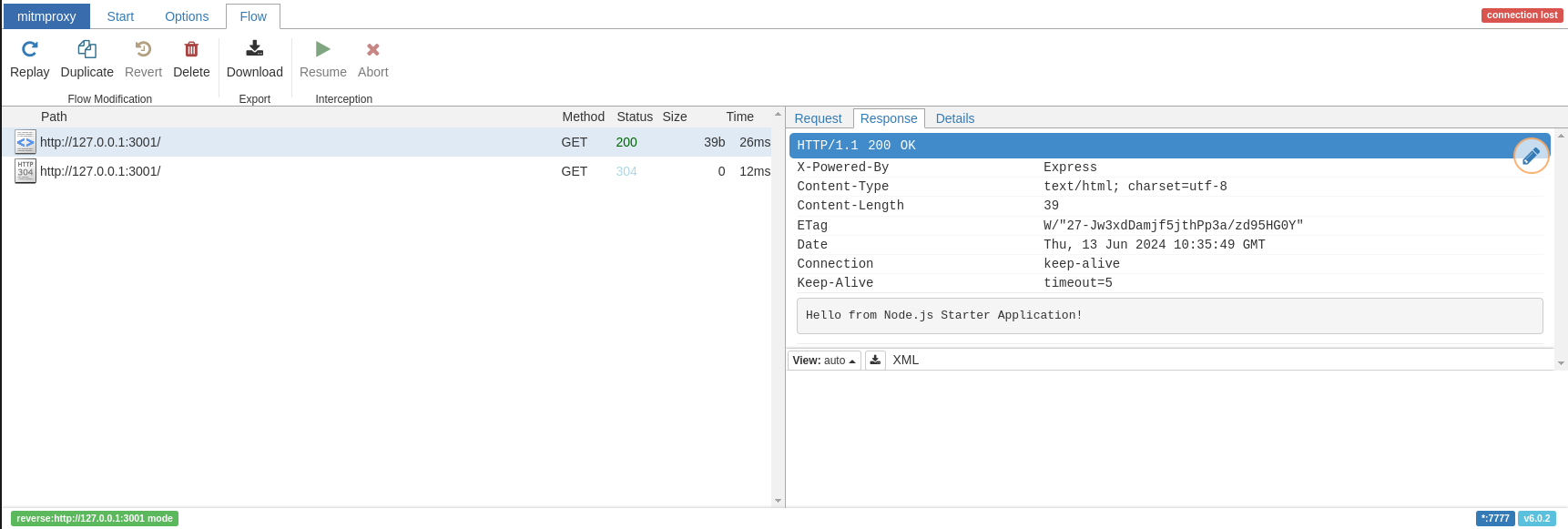
We welcome your feedback
We hope you enjoyed this article. We demonstrated concrete examples of CLI usage for Network Observability. You learned how to capture and identify traffic, check connectivity between two endpoints, determine the User Defined Networks involved and display packets payload. Be sure to check out the new features in the Network Observability CLI 1.8.
NetObserv is an open source project available on GitHub. Feel free to share your ideas and use cases or ask the community for help.
Thanks to Mohamed Mahmoud, Joël Takvorian, Sara Thomas, and Amogh Rameshappa Devapura for reviewing this article.