Tiered storage is a new early access feature available as of Apache Kafka 3.6.0 that allows you to scale compute and storage resources independently, provides better client isolation, and allows faster maintenance of your Kafka cluster. Let's dive into this new feature to see the motivations, design, and implementation details. In this post, we will focus on Tiered storage implementation, so it is assumed a good understanding of the Kafka architecture and main components. If you are looking for a tutorial or example, we recommend reading Getting started with tiered storage in Apache Kafka.
Tiering
The idea of tiering is not new in the software industry. The three-tier is a well-established software application architecture that organizes applications into three logical and physical computing tiers: the presentation tier, or user interface, the application tier, where data is processed, and the data tier, where data associated with the application is stored and managed.
Info alert:Layer is often used interchangeably with tier, but they aren't the same. In this post, we'll use the term "layer" as a functional division of the software, and "tier" as a functional division of the software that runs on separate infrastructure. For example, the contacts app on your phone is a three-layer application, but a single-tier application, because all three layers run on your phone.
Tiered storage refers to a storage architecture that uses different classes or tiers of storage to efficiently manage and store data based on its access patterns, performance requirements, and cost considerations. This ensures that the most critical and frequently accessed data lives in high-performance "hot" storage (local), while less critical or infrequently accessed data is moved to lower-cost, lower-performance "warm" storage (remote). We may also define "cold" storage as a periodic backup system, but this is usually a separate process. The three tiers are shown below in Figure 1.
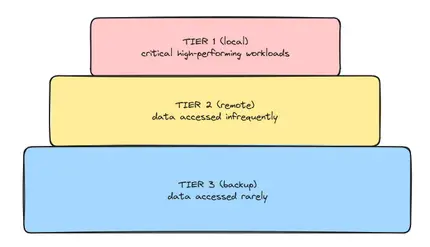
With tiered storage, data resides on one media type at any time, and moves between media as the data access patterns change. Data is not copied, but moved to a different storage medium, selecting the location that best balances availability, performance and the cost of the storage media. This way, storage hardware can be better utilized, while still maximizing performance for mission-critical applications. Some data might still be cached, but only for performance reasons.
The need for remote storage
Apache Kafka is designed to ingest large volumes of data from thousands of clients. Until now, a replica of a topic partition has been made of multiple segment files, which were entirely hosted on a single disk of a Kafka broker, so there has been a limit on how much data you can store.
What if you want to keep historical data? This is where the need for remote storage arises. Historical data of regular topics need to be stored somewhere. Event sourcing and change data capture are two architectural patterns that may require historical data. We may need them for disaster recovery, to initialize a new application, to rebuild the application state after fixing an issue with the business logic, to retrain a machine learning model.
There are basically two approaches for keeping historical data outside Kafka:
- Use an additional process to read all ingested data out of Kafka and copy them to the remote storage. This comes with the drawback of data consumers having to build different versions of applications to consume the data from different systems depending on the age of the data. Sometimes this is done using Kafka Connect to export and import back data as needed.
- Use a custom program running on the Kafka machine, which checks for inactive segments and moves them to the remote storage. These are segments that reached the maximum size, as defined by
segment.bytes, and have been closed and reopened as read-only. The advantage of this solution is that there is no cost in feeding back to Kafka for reprocessing, but it is another program you have to maintain.
Tiered storage in Kafka
The custom program solution is similar to the new tiered storage feature (KIP-405) released as early access in Kafka 3.6.0. This new feature offers a standardized built-in mechanism for automatically moving inactive segments from local storage (e.g., SSD/NVMe) to remote storage (e.g. S3/HDFS) based on your retention configuration, and reading back data from remote storage when a client asks for them. Various external storage systems can be supported via plugins, which are not part of the Kafka project.
Tiered storage must be enabled at the cluster level with remote.log.storage.system.enable, and at the topic level with remote.storage.enable. There are two retention periods that can be configured at the topic level: local.log.retention.ms for local storage, and log.retention.ms for remote storage (size based retention is also available).
The Kafka broker moves data to the remote storage as soon as possible, but certain conditions, such as high ingestion rate or connectivity issues, may cause more data to be stored on the local storage than the specified local retention policy. Any data exceeding the local retention threshold will not be purged until successfully uploaded to remote storage. Only the leader's inactive log segments are uploaded to the remote storage, not followers, but you can still fetch from followers.
When consumers request records (messages) that aren't already available locally, but within the available offset range, the broker fetches them from the remote storage, and caches index files locally. So it is recommended to reserve disk space for that (1 GiB by default, which is configurable with remote.log.index.file.cache.total.size.bytes).
There are various benefits that come with tiered storage:
- Elasticity: The separation of compute and storage resources that can now be scaled independently, and certain cluster operations become faster due to less local data.
- Isolation: Latency sensitive data can be served from the local tier as usual, while historical data can be served from the remote tier using a different code path and threads without changes to the Kafka clients.
- Cost efficiency: Remote object storage systems are less expensive than fast local disks. Kafka storage becomes cheaper and virtually unlimited.
There are also some limitations, that will be addressed in future releases:
- No support for multiple log directories (JBOD) and compacted topics (this includes compacted topics converted to regular topics).
- To disable tiering on a topic, you should first transfer the data to another topic or external storage, and then delete the topic.
An important feature, which is still under development, is the possibility to dynamically set broker level quotas to limit the rate at which we are uploading and downloading segments (KIP-956). This is useful to avoid over-utilising broker resources, and remote storage degradation. For example, this can happen when you enable tiered storage for the first time on existing topics.
There are several metrics for remote storage operations that you can use to monitor and create alerts about degradation of the remote storage service (e.g., Slow Remote Upload/Download Rate, High Remote Upload/Download Error Rate, Busy Upload/Download Thread Pool).
In Kafka 3.7.0 there are new metrics that report the segment or byte copy and deletion lag for each topic:
kafka.server:type=BrokerTopicMetrics,name=RemoteCopyLagSegments,topic=([-.w]+)kafka.server:type=BrokerTopicMetrics,name=RemoteCopyLagBytes,topic=([-.w]+)kafka.server:type=BrokerTopicMetrics,name=RemoteDeleteLagBytes,topic=([-.w]+)kafka.server:type=BrokerTopicMetrics,name=RemoteDeleteLagSegments,topic=([-.w]+)
Kafka internals
We will now deep dive into the internals of Apache Kafka to see how messages are produced and consumed. Then, we will see how tiered storage integrates with that, and how all components fit together. If you are already familiar with Kafka storage internals, you can directly jump to the How tiered storage works section.
How records are stored
Let's first see how records are stored on disk. In Kafka, we have two main subsystems: the "data plane", which is made of components dealing with user data, and the "control plane", which is made of components dealing with cluster metadata (Controller election, topic configuration and clustering). This is depicted in Figure 2.

Info alert: By default, when a new batch of records arrives, it is firstly written into the Operating System's page cache, and only flushed to disk asynchronously. If the Kafka JVM crashes for whatever reason, recent messages are still in the page cache, and will be flushed by the Operating System. However, this doesn't protect from data loss when the machine crashes. This is why enabling topic replication is important: having multiple replicas means data loss is only possible if multiple brokers can crash simultaneously. To further improve fault tolerance, a rack-aware Kafka cluster can be used to distribute topic replicas evenly across data centers in the same geographic region.
When you call producer.send() in your application, the producer determines the destination broker. The record may not be sent immediately, but accumulated and sent in a batch based on time or size configuration properties. The ProduceRequest is received by the broker on one of its network threads. The network thread converts that request into a ProduceRequest and passes it to an IO thread. This thread validates the request, before appending the data to the partition's segment (log and index files). See Figure 3.

By default, a broker only acknowledges a produce request once it has been replicated on other brokers. This happens without blocking the IO thread. Once replicated, the broker generates a ProduceResponse. Finally, the network thread sends this response to the producer.
The Kafka consumer sends Fetch requests specifying the desired topic, partition and offset to consume from. The broker's network thread passes requests to the IO thread, which compares the offset with the corresponding entry in the segment's index file. This step determines the exact number of bytes to be read from the log file.
How tiered storage works
A log segment consists of record data, and associated metadata, covering a contiguous range of offsets in a replica of a partition. On a broker's disk these data are stored in a number of files, the log itself holds the record batches, index files support efficient access to the log, and so on. Tiered storage feature involves moving these files to and from a remote object store.
In order to append data to the log, the IO thread notifies the ReplicaManager, which is where tiered storage is plugged in. The main components are the RemoteLogManager (RLM), the RemoteStorageManager (RSM), and the RemoteLogMetadataManager (RLMM). RSM and RLMM are both pluggable interfaces and so can support different kinds of remote storage systems. This is shown in Figure 4.

Two caches are used for performance reasons. An in-memory RemoteLogMetadataCache maintained by the TopicBasedRemoteLogMetadataManager (default RLMM implementation), which contains metadata for all the remote segments that were not deleted. A file-based RemoteIndexCache maintained by the RemoteLogManager and stored in the remote-log-index-cache folder, which is helpful to avoid re-fetching the index files like offset, time indexes from the remote storage for every fetch call.
RemoteStorageManager
The RemoteStorageManager provides the lifecycle of remote log segments that includes copying, fetching, and deleting from remote storage.
The log segment metadata provided in RemoteStorageManager is the RemoteLogSegmentMetadata instance, which describes a log segment that’s been uploaded to the remote storage. It contains a universally unique RemoteLogSegmentId, which is the identifier for segment data that's been externalized to the remote storage. The RemoteLogSegmentId is composed by topic name, topic ID, partition number and UUID. There is also the LogSegmentData that contains the actual data and indexes of a specific log segment that needs to be stored in the remote storage.
This is how a remote segment with indexes and auxiliary state looks like on remote storage:
test-0-00000000000000000000-knnxbs3FSRyKdPcSAOQC-w.index
test-0-00000000000000000000-knnxbs3FSRyKdPcSAOQC-w.snapshot
test-0-00000000000000000000-knnxbs3FSRyKdPcSAOQC-w.leader_epoch_checkpoint
test-0-00000000000000000000-knnxbs3FSRyKdPcSAOQC-w.timeindex
test-0-00000000000000000000-knnxbs3FSRyKdPcSAOQC-w.log
test-0-00000000000000001005-SpGkL2YWRMC5DIw5TJP_EA.index
test-0-00000000000000001005-SpGkL2YWRMC5DIw5TJP_EA.leader_epoch_checkpoint
test-0-00000000000000001005-SpGkL2YWRMC5DIw5TJP_EA.log
test-0-00000000000000001005-SpGkL2YWRMC5DIw5TJP_EA.snapshot
test-0-00000000000000001005-SpGkL2YWRMC5DIw5TJP_EA.timeindex
The file name doesn't have to be in this format, it is defined by the RemoteStorageManager plug-in, but basically, it usually contains some of these information to distinguish between each other:
- Topic name
- Partition ID
- Log segment base offset
- Remote segment UUID
- FILE_TYPE
The FILE_TYPE could be one of these types:
- The
leader-epoch-checkpointfile that contains the metadata ofleader_epochtostart_offsetmapping for that partition. - The offset index file that contains the offset index for the log segment.
- The times index file that contains the time index for the log segment.
- The producer snapshot file contains the producer ID mapping to some metadata like sequence number and epoch for the log segment.
- The optional transaction index file contains the aborted transaction for the log segment. This is an optional file and only exists if a transactional producer is enabled.
Please note that although the spec in KIP-405 doesn't enforce the file name format stored in the remote storage, when fetching from remote storage, any missing file, except the optional transaction index, will cause an exception and the fetch will fail.
RemoteLogMetadataManager
The RemoteLogMetadataManager is used to store RemoteLogSegmentMetadata about uploaded segments, and requires a storage system that supports strong consistency, while some of them only support eventual consistency. This is why Kafka provides the TopicBasedRemoteLogMetadataManager, which uses an internal non-compacted topic called __remote_log_metadata to store metadata records. Each metadata operation has an associated record type defined in storage/src/main/resources/message.
RemoteLogManager
When tiered storage is enabled, the broker starts the RemoteLogManager, which is the component that maintains a list of topic-partitions that have remote log segments. It is responsible for initializing the RemoteStorageManager and RemoteLogMetadataManager, handling events about leader/follower changes and partition stops, providing operations to other broker-side components to fetch indexes and metadata about remote log segments.
After all components are started, the ReplicaManager waits for a replica to take leadership for any partition. When this happens, the ReplicaManager notifies the RemoteLogManager. At this point, an RLMTask is created for each managed topic-partition and scheduled to run every remote.log.manager.task.interval.ms using the RLMScheduledThreadPool.
On each run, the RLMTask executes two subtasks:
- Copy log segments to remote storage.
- Delete log segments from remote storage.
LogSegment copy
To identify which LogSegments are qualified to be copied to remote storage, the RLMTask compares two offsets:
- The last stable offset (LSO), which is the high watermark with non-transactional records, and the last committed offset with transactional records.
- The last remote offset (LRO), which is the last offset stored in remote storage and retrieved using the
RemoteLogMetadataManager.
If LSO > LRO, the RLMTask checks if there are any inactive segments within this offset range, which means they are qualified to be copied to the remote storage. See Figure 5 for an illustration of this.

LogSegment deletion
Remote log retention is similar to local log retention, the difference is that segments are located in remote storage, that is, deleting old log segments based on retention.bytes or retention.ms. The RLMTask heavily relies on the metadata stored in RemoteLogMetadataManager to identify the candidate log segments to delete. Note that the retention.bytes calculation is the total size of local segments plus remote segments.
Consumer fetch
The consumer Fetch request behavior has some changes on a tiered topic. When handling the request, the ReplicaManager gets an OffsetOutOfRangeException if the required offset has moved to the remote storage. At this point, the ReplicaManager adds the request into the RemoteFetchPurgatory, and delegates to the RemoteLogManager by submitting a RemoteLogReader task to the RemoteStorageThreadPool's queue.
Each RemoteLogReader processes one remote Fetch request at a time. When the remote fetch sits in RemoteFetchPurgatory, we use fetch.max.wait.ms as the delay timeout. This is not ideal because the original purpose of this config is to wait for the given amount of time when there is no local data available to serve the Fetch request. In KIP-1018, it will be improved by introducing a new config for remote fetch delay timeout. Figure 6 depicts this.

Follower fetch
The Follower replication also has some changes on a tiered topic. When the follower partition replica gets OffsetMovedToTieredStorageException while fetching from the leader, it means that the fetch offset is no longer available in the leader's local storage, and the follower needs to build the auxiliary state from remote segment metadata.
The partition's auxiliary state includes the leader-epoch checkpoint, which is used by the log replication protocol to maintain log consistency across brokers, and the producer-id snapshot, which is used by the transaction subsystem.
The follower invokes the ListsOffsets API with EarliestLocalTimestamp parameter to know up to which offset it needs to rebuild this state. After the auxiliary state is built, the follower truncates local log, resets the fetch offset to the end offset of the remote log plus one, and resumes fetching from the leader's local storage.
Conclusion
We've delved into the necessity for remote storage in Kafka, particularly for retaining historical data critical for various use cases like disaster recovery, data analytics, and machine learning. The introduction of Kafka tiered storage presents a standardized, built-in solution. By leveraging different storage tiers based on data access patterns, performance needs, and cost considerations, tiered storage optimizes resource utilization while ensuring efficient data management.
We've also provided insight into the technical architecture underpinning the remote log subsystem, elucidating the roles of components like the RemoteLogManager, RemoteStorageManager, and RemoteLogMetadataManager. Tiered storage represents a significant advancement in data management within Kafka ecosystems, offering a robust solution for efficient data storage and retrieval in modern distributed architectures.