Red Hat OpenShift AI combines the scalability and flexibility of containerization with the capabilities of machine learning and data analytics. With Red Hat OpenShift AI, data scientists and developers can efficiently collaborate, deploy, and manage their models and applications in a secure and streamlined environment. Snorkel is an open source Python library for programmatically building training datasets without manual labeling. It was created in 2017 to support reproducibility of early research papers on programmatic labeling and weak supervision.
In this tutorial, you will learn how to create an OpenShift AI environment and walk through 2 Snorkel tutorials provided by the Snorkel open source library, one for data labeling and for information extraction. This tutorial uses the Snorkel open source Python library. This is different from—though related to—Snorkel AI. The team that developed the Snorkel open source project founded Snorkel AI to continue building on their core ideas. They have since built the Snorkel Flow AI data development platform, which is neither free nor open source. For information on the Snorkel project, visit snorkel.org. For information on Snorkel AI the company, visit snorkel.ai.
Prerequisites
For this tutorial you will need Red Hat OpenShift 4.14 with OpenShift AI and access to the open source Snorkel library.
Install OpenShift AI
OpenShift AI can be installed from the OpenShift web console. Navigate to the Operators tab and select OperatorHub. In the text box, type red hat openshift data science, select the Red Hat OpenShift Data Science operator, and click Install (Figure 1).
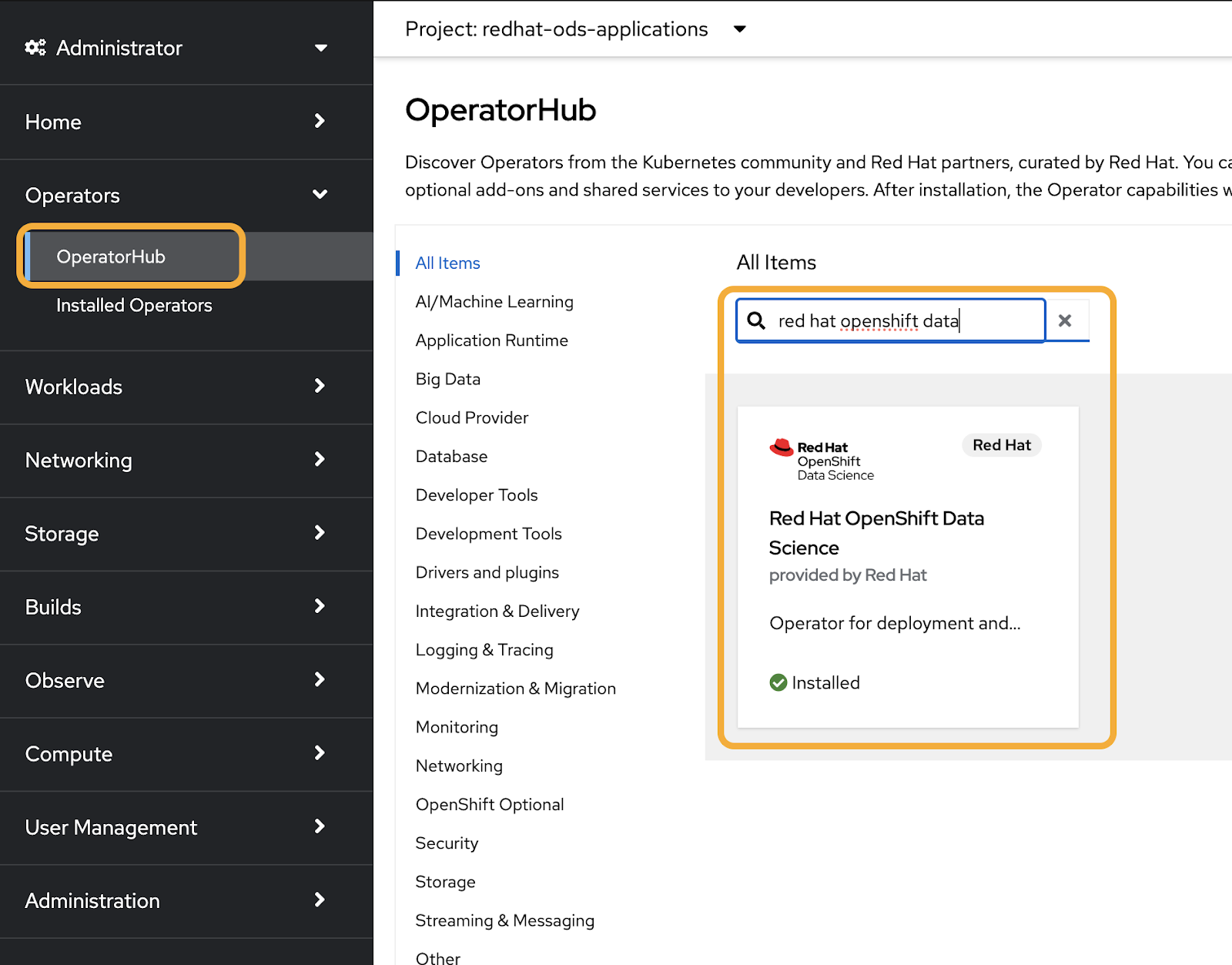
To start the installation, click the blue Install button again. You can check to see if our operator successfully deployed under the Operators tab and select Installed Operators (Figure 2).
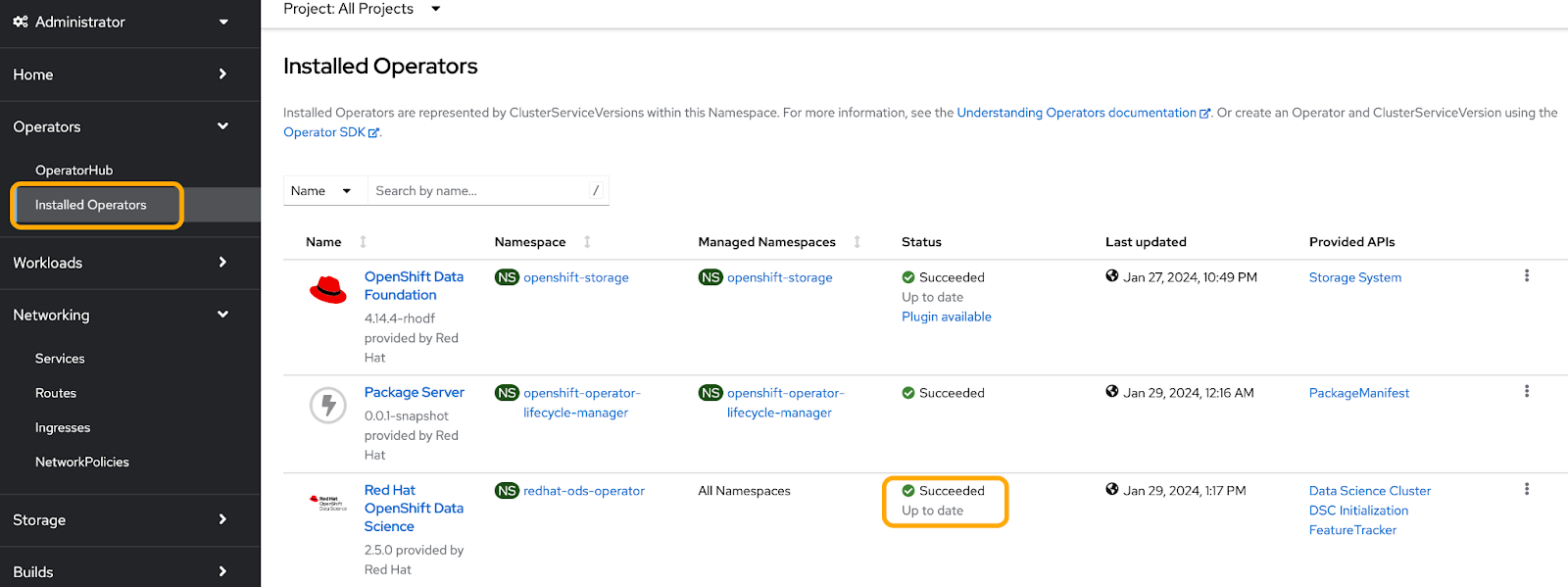
Now that our operator has successfully deployed, click it and create a new Data Science Cluster instance (Figure 3).
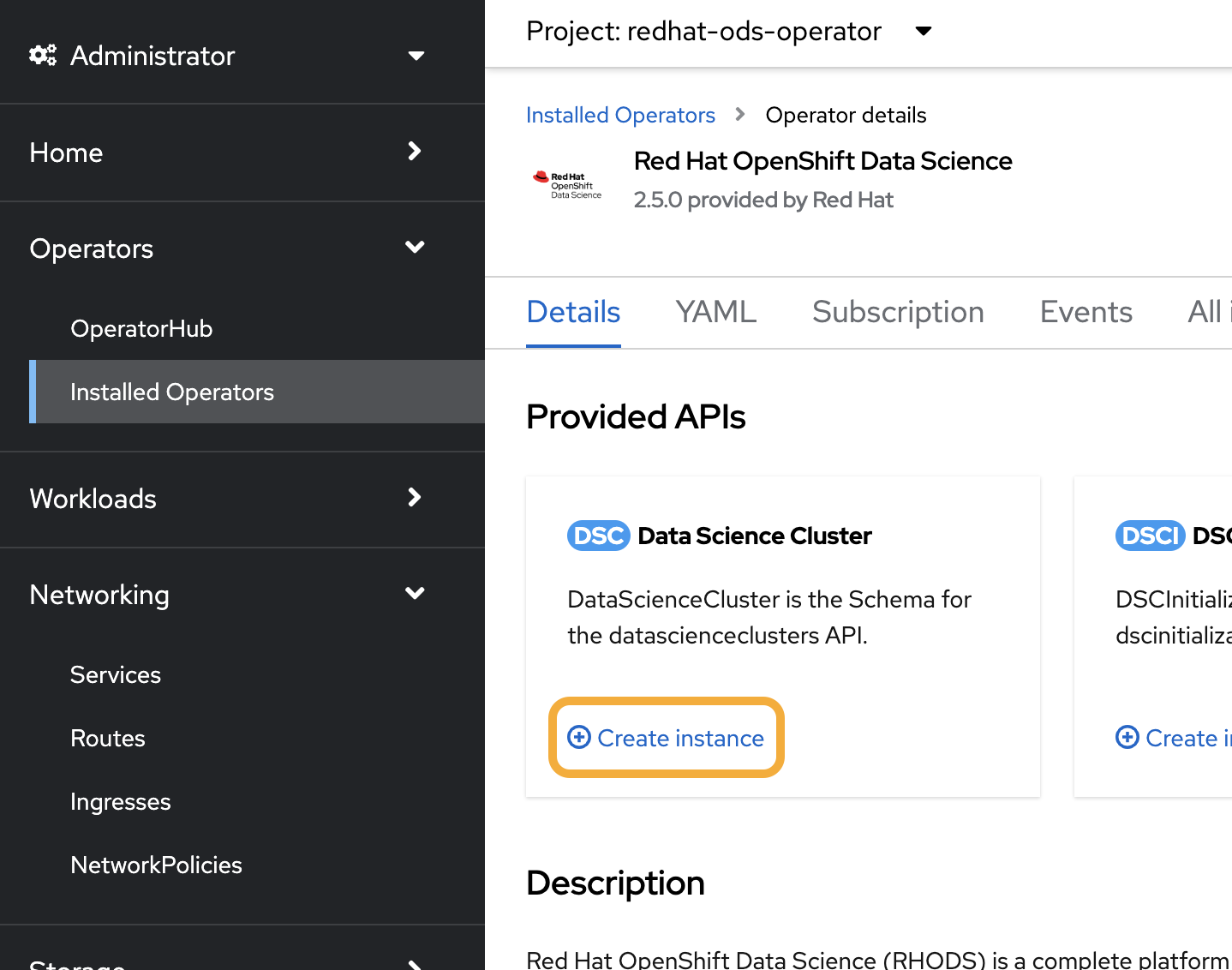
We don't need to make any changes to the default settings, so we'll just click Create. If you would like to use an accelerator, it’s recommended to prepare that before accessing the OpenShift AI dashboard (Figure 4).
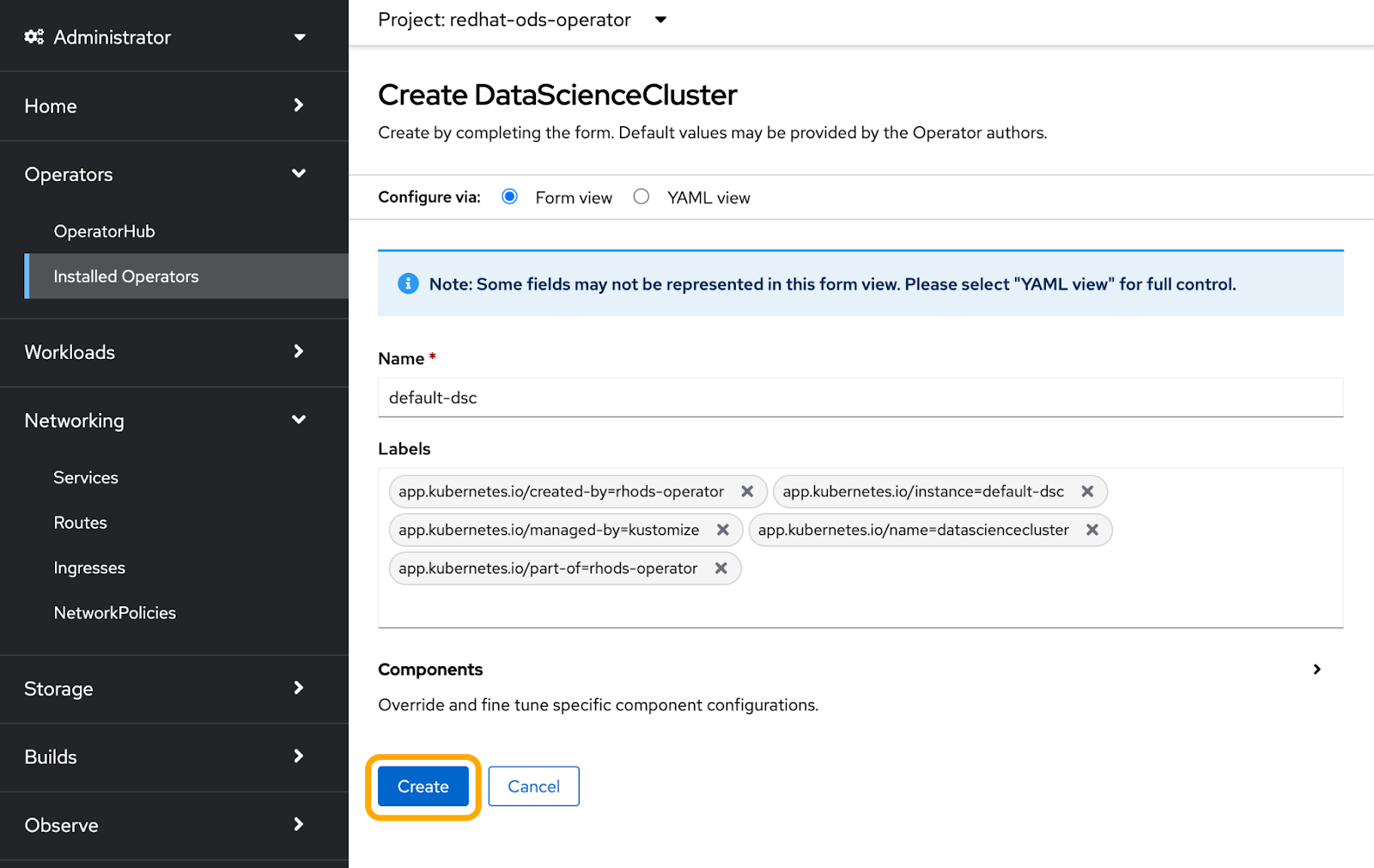
Once this has successfully deployed, we'll now access our OpenShift AI dashboard. On the administrator menu, head to Networking and click Routes. In Routes, we're going to change the project to redhat-ods-application, which is where we can access the address to our OpenShift AI application (Figure 5).
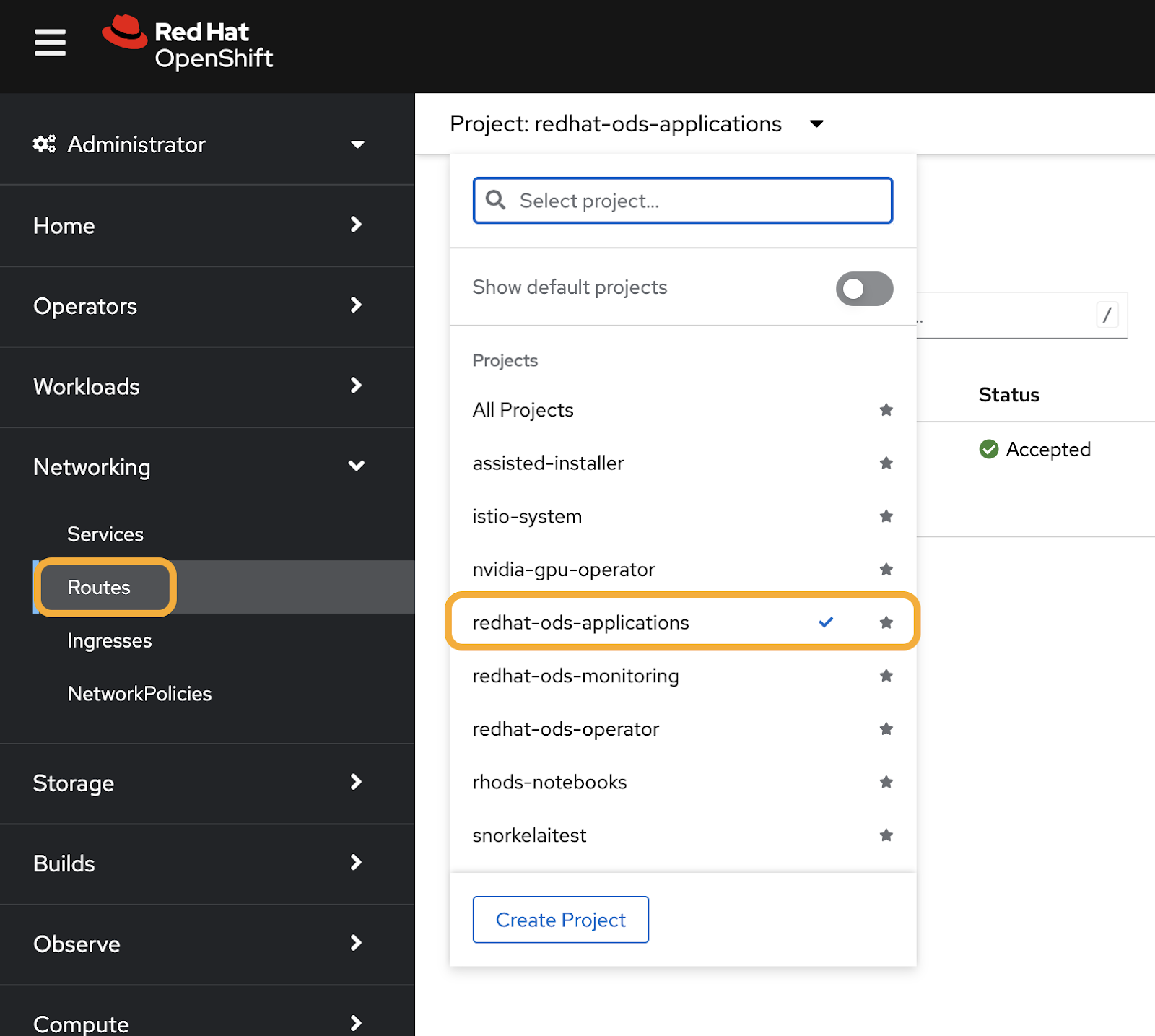
There should only be one route available, so go ahead and click the address to take you to the OpenShift AI dashboard (Figure 6).
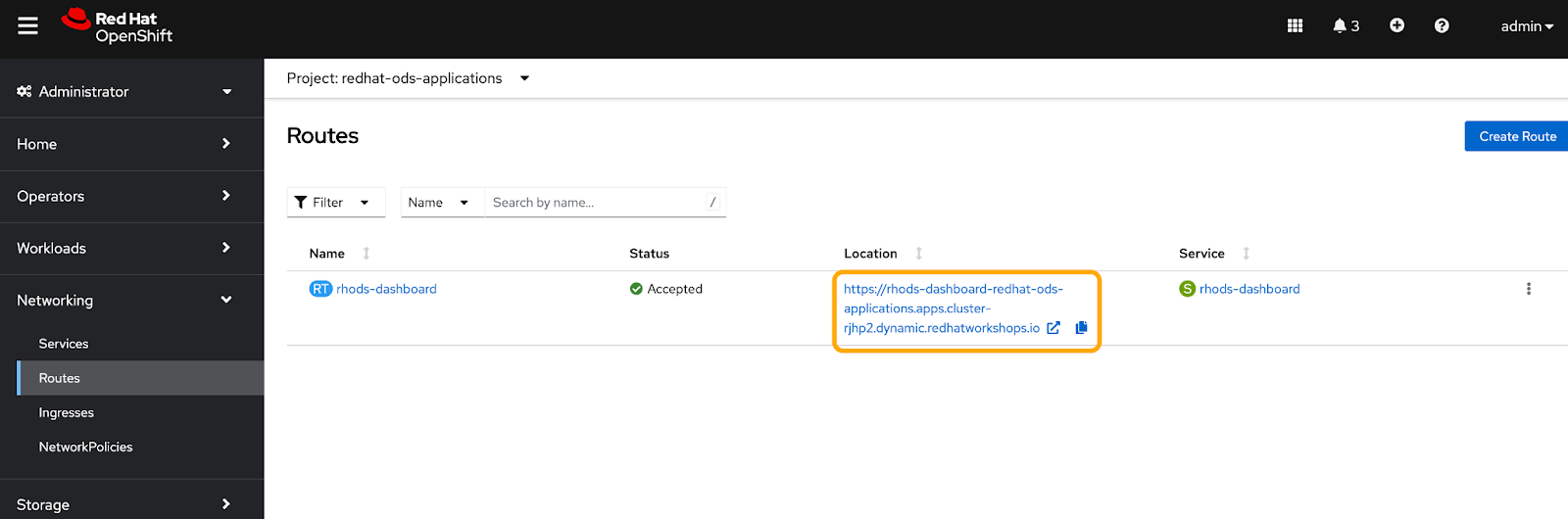
Create a new data science project
Now we're going to set up our Jupyter environment so we can run the Snorkel tutorials by creating a new data science project. In the left side menu, navigate to the Data Science Projects tab (Figure 7).
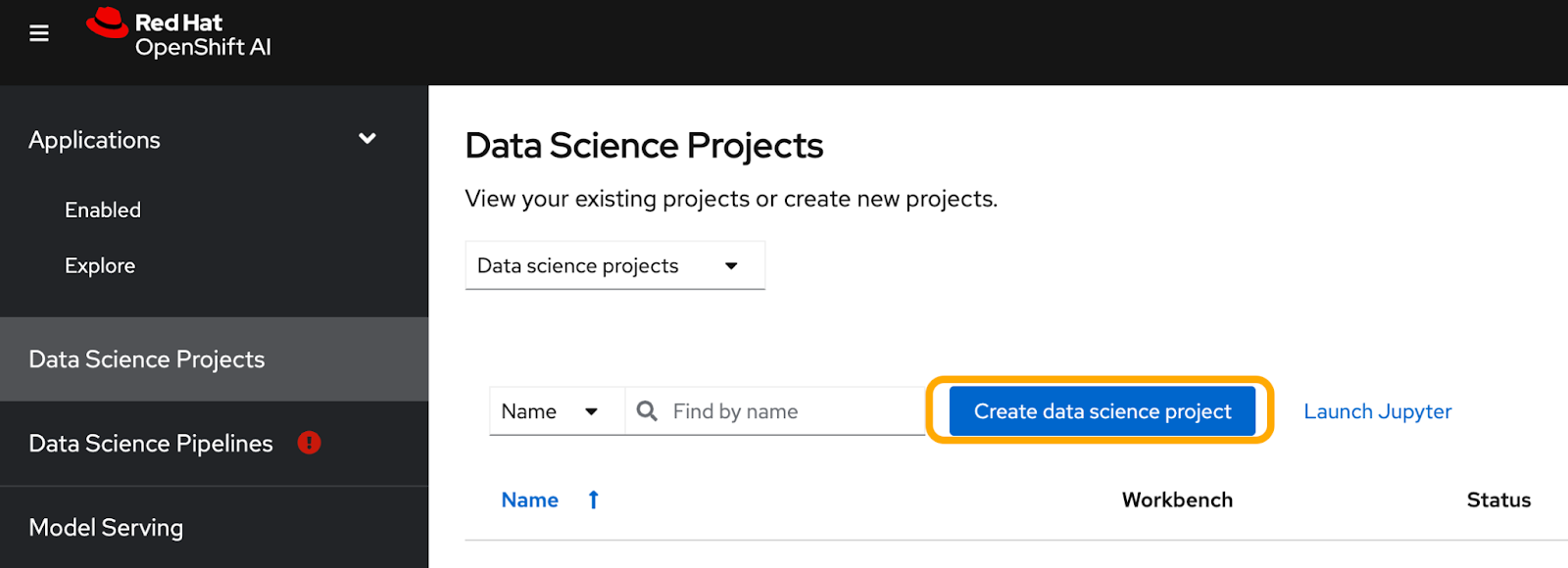
Next, click Create data science project. Type your preferred project name (in our case, snorkel) and click Create. This is the namespace where all the resources tailored to this demo will be deployed (Figure 8).
Create workbench
Inside our project, select Create workbench. This will guide us to the workbench configuration page. Complete the fields to match the following:
- Name: snorkel (or insert your preferred name)
- Image selection: PyTorch
- Version selection: 2023.1
- Container size: Small
- Check the Create new persistent storage box.
- Name: snorkel (or insert your preferred name)
- Persistent storage size: 20 GiB
Once you've completed the form, click Create workbench. You should be taken to the project home page. Once the workbench has finished provisioning, click Open to access the workbench. Log in with your OpenShift credentials and allow the selected permissions (Figure 9).
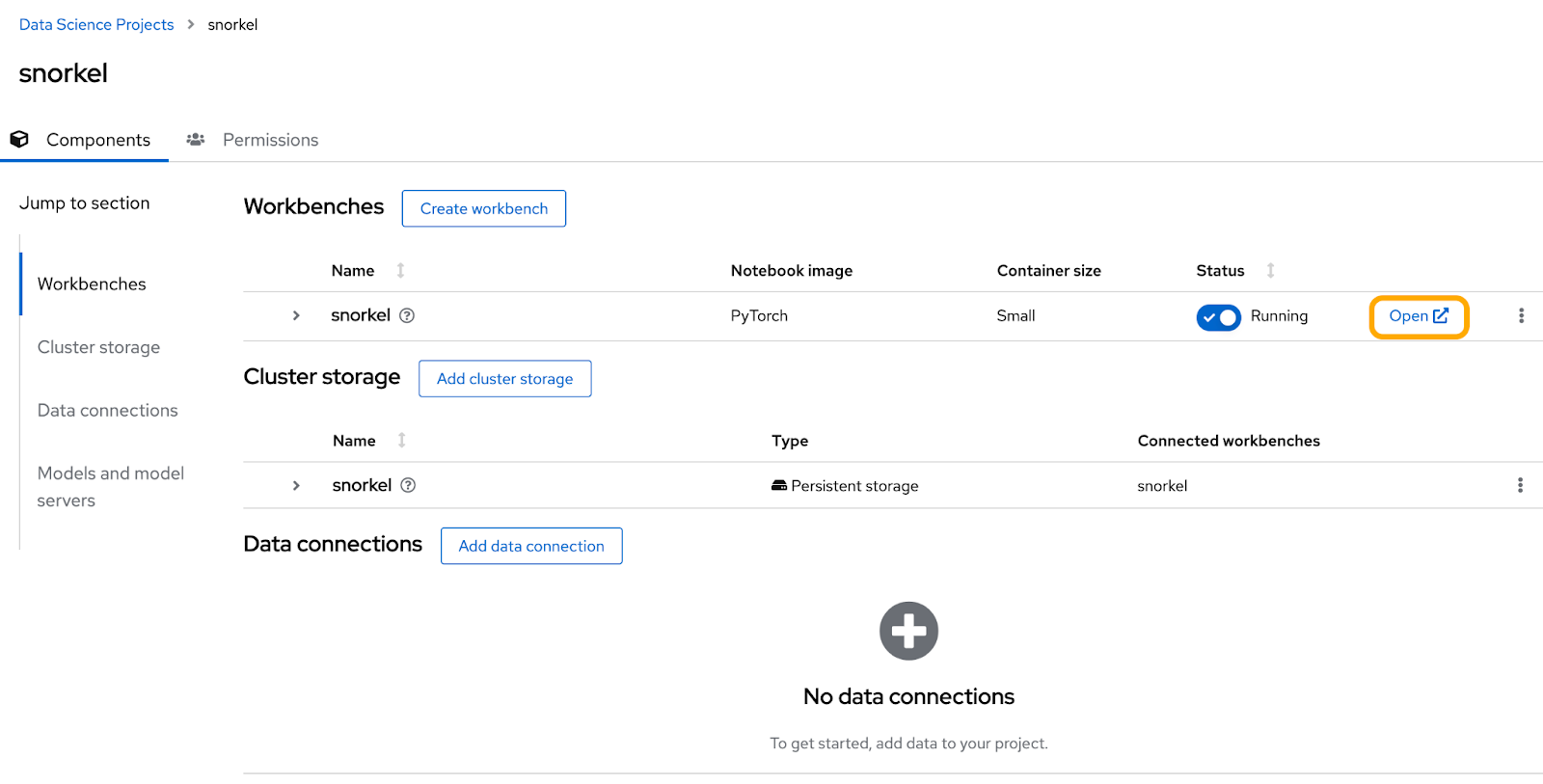
Snorkel open source tutorials
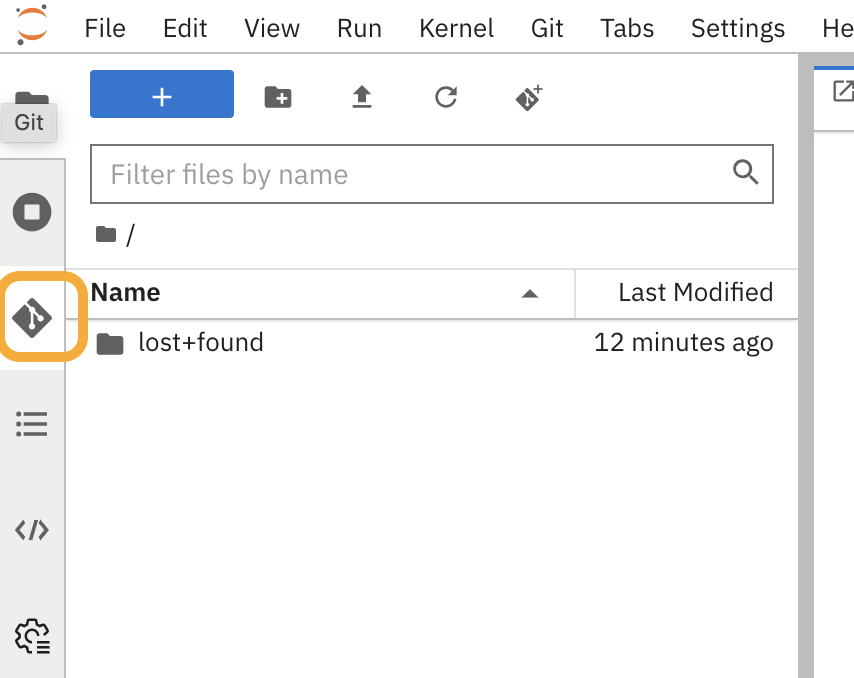
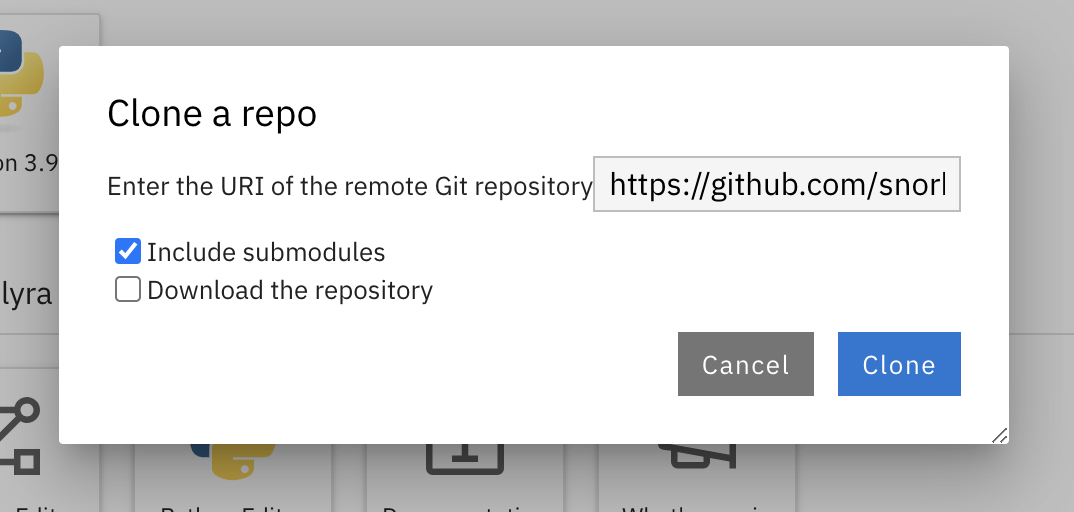
Now that we're in our Jupyter environment, let's clone the Snorkel repository. On the left, select the Git logo and click Clone a repository and paste the repository URL:
https://github.com/snorkel-team/snorkel-tutorials.gitSee Figure 10 for the Git logo icon and Figure 11 for the field to input the repository URL.
Now that we've cloned the repository, we're going to try out the spam and spouse tutorials (which you can find in the directories with the corresponding name). Both notebooks are incredibly detailed, as they walk you through and explain at length each step. These tutorials can serve as a reference point when using Snorkel API in the future.
The spam tutorial is a data labeling exercise that shows you how to build a training set for classifying YouTube comments as spam or not spam. To access it, enter the spam directory and begin with 01_spam_tutorial.ipynb. This is the first of 3 notebook files to walk through data labeling, augmentation, and slicing. It's an introductory tutorial and it is one avenue you could perform data labeling within OpenShift AI utilizing Snorkel.
The spouse tutorial is a little more complex, it walks through how to utilize Snorkel for information extraction by using keywords and distant supervision. In this tutorial, you will learn how to identify and classify someone's spouse utilizing labeling functions and models to do so. To begin this tutorial, enter the spouse directory and open spouse_demo.ipynb. This exercise is to demonstrate how simple it is to integrate Snorkel's libraries and tools with your OpenShift AI environment.
Conclusion
Now that you’ve walked through the tutorial, the Snorkel open source library is now available on your OpenShift AI environment. For more information on Snorkel, you can visit their websites to learn more about the Snorkel project and their AI services.
If you would like to try out OpenShift, you can with our Developer Sandbox using a no-cost trial. Learn more about OpenShift and our AI initiatives.
Last updated: July 22, 2026