Note: The following is an excerpt from Kafka Connect: Build and Run Data Pipelines by Mickael Maison and Kate Stanley (O'Reilly Media, September 2023). Download the e-book for practical advice to help you quickly adopt Kafka and build modern data pipelines.
Systems to handle data have existed since the early days of computers. However, the amount of data being generated and collected is growing at an exponential rate. In 2018, an estimated 2.5 quintillion bytes of data were being created each day, and the International Data Corporation (IDC) expects that the total size of all existing data will double between 2022 and 2025.
For organizations to handle these large volumes of data, now called “big data,” new classes of systems have been designed. There are now hundreds of different databases, data stores, and processing tools to cater to every conceivable big data use case. Today, a typical organization runs several of these systems. This may be because different systems have been inherited through acquisition, optimized for specific use cases, or managed by different teams. Or it could be that the preferred tools have changed over time and old applications have not been updated.
For most organizations, simply collecting and storing raw data is not enough to gain a competitive advantage or provide novel services. In order to extract insights, data must be refined by analyzing and combining it from multiple sources. For example, data from the marketing team can be used alongside data from sales to identify which campaigns perform the best. Sales and customer profile data can be combined to build personalized reward programs. The combination of tools that is used for data collection and aggregation is called a data pipeline.
Over the past ten years, Apache Kafka has emerged as the de facto standard for ingesting and processing large amounts of data in real time. Kafka is an open source data streaming platform and is designed to serve as the data backbone for organizations. It is now a key component in many data deployments, as it's used by over 80% of the Fortune 100. Many new applications are developed to work with Kafka so that their data is immediately highly available and can be easily reused and processed efficiently to drive real-time knowledge.
Most organizations already have a lot of data in existing systems. It may seem relatively easy at first sight to write an application to aggregate data from these systems because most of them have APIs. However, as the number of external systems you use increases, doing so can quickly become a large and costly burden in terms of maintenance and developer time. Systems have their own unique formats and APIs, and are often managed by different teams or departments. If you then add considerations around security and data privacy, such as the European Union'’s General Data Protection Regulation (GDPR), writing an application can quickly turn into a challenging task.
To address these issues, a number of integration systems have been developed. An integration system is designed to connect to various systems and access data.
Kafka Connect is one of these integration systems. It is part of Apache Kafka and specializes in integrating other systems with Kafka so that data can be easily moved, reused, combined, or processed. For example, Kafka Connect can be used to stream changes out of a database and into Kafka, enabling other services to easily react in real time. Similarly, once data has been fully processed in Kafka, Kafka Connect can move it to a data store, where it can be kept for long durations.
Kafka Connect Features
Kafka Connect provides a runtime and framework to build and run robust data pipelines that include Kafka. It was first introduced in Kafka 0.10.0.0 in 2016 via KIP-26. Kafka Connect is battle-tested and known to be resilient under load and at huge scale. The Kafka Connect runtime also provides a single control plane to manage all your pipelines, and it often allows building pipelines without writing any code so that engineers can focus on their use cases instead of moving the data.
Kafka Connect distinguishes between source pipelines, where data is coming from an external system to Kafka, and sink pipelines, where data flows from Kafka to an external system. With Kafka Connect, one side of the pipeline has to be Kafka, so you can'’t directly connect two external systems together. That said, it is very common for data imported into Kafka via a source pipeline to end up in another external system via a sink pipeline once it has been processed.
For example, Figure 1-1 shows a source pipeline that imports data from a database into Kafka.

Let'’s take a closer look at the unique set of features and characteristics that make Kafka Connect a very popular platform for building data pipelines and integrating systems:
- Pluggable architecture
- Scalable and reliable
- Declarative pipeline definition
- Part of Apache Kafka
Pluggable Architecture
Kafka Connect provides common logic and clear APIs to get data into and out of Kafka in a resilient way. It uses plug-ins to encapsulate the logic specific to external systems. The Kafka community has created hundreds of plug-ins to interact with databases, storage systems, and various common protocols. This makes it quick and easy to get started with even complex data pipelines. If you have custom systems or none of the existing plug-ins satisfy your needs, Kafka Connect provides APIs so that you can implement your own.
Kafka Connect allows you to build complex data pipelines by combining plug-ins. The plug-ins used to define pipelines are called connector plug-ins. There are multiple types of connector plug-ins:
- Source connectors, which import data from an external system into Kafka
- Sink connectors, which export data from Kafka to an external system
- Converters, which convert data between Kafka Connect and external systems
- Transformations, which transform data as it flows through Kafka Connect
- Predicates, which conditionally apply transformations
A pipeline is composed of a single connector and a converter, and includes optional transformations and predicates. Kafka Connect supports both Extract-Load- Transform (ELT) and Extract-Transform-Load (ETL) pipelines. In ELT pipelines, Kafka Connect performs the extract and load steps, enabling you to use another system to perform transformations once the data reaches the target system. In ETL pipelines, Kafka Connect transformations update the data as it flows through Kafka Connect.
Figure 1-2 shows a simple ETL pipeline composed of a source connector, one transformation (a record filter), and a converter.

Alongside connector plug-ins, there'’s another group of plug-ins that are used to customize Kafka Connect itself. These are called worker plug-ins:
- REST extensions customize the REST API.
- Configuration providers dynamically retrieve configurations at runtime.
- Connector client override policies police what configurations users can set for the Kafka clients used by connectors.
Scalability and Reliability
Kafka Connect runs independently from Kafka brokers and can either be deployed on a single host as a standalone application or on multiple hosts to form a distributed cluster. A host running Kafka Connect is named a worker.
These two deployment options allow Kafka Connect to handle a large spectrum of workloads. You can have workloads that scale from a single pipeline flowing just a few events to dozens of workers handling millions of events per second. You can also add workers to and remove workers from a Kafka Connect cluster at runtime, which allows you to adjust the capacity to match the required throughput.
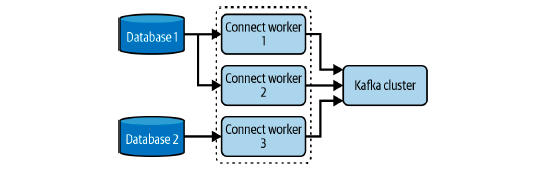
When deployed as a cluster, workers cooperate and each one handles a share of the workload. This makes Kafka Connect very reliable and resilient to failures because if a worker crashes, the others can take over its workload.
Figure 1-3 shows a Kafka Connect cluster handling two data pipelines (from Database 1 to Kafka, and from Database 2 to Kafka), and the workload is distributed across the available workers.
Declarative Pipeline Definition
Kafka Connect allows you to declaratively define your pipelines. This means that by combining connector plug-ins, you can build powerful data pipelines without writing any code. Pipelines are defined using JSON (or properties files, in standalone configuration) that describes the plug-ins to use and their configurations. This allows data engineers to focus on their use cases and abstract the intricacies of the systems they are interacting with.
To define and operate pipelines, Kafka Connect exposes a REST API. This means you can easily start, stop, configure, and track the health and status of all your data pipelines.
Once a pipeline is created via the REST API, Kafka Connect automatically instantiates the necessary plug-ins on the available workers in the Connect cluster.
Part of Apache Kafka
Kafka Connect is part of the Apache Kafka project and is tailor-made to work with Kafka. Apache Kafka is an open source project, which means Kafka Connect benefits from a large and active community. As mentioned, there are hundreds of available plug-ins for Kafka Connect that have been created by the community. Kafka Connect receives improvements and new features with each Kafka release. These changes range from usability updates to alterations that allow Kafka Connect to take advantage of the latest Kafka features.
For developers and administrators who already use and know Kafka, Kafka Connect provides an integration option that doesn'’t require a new system and reuses many of the Kafka concepts and practices. Internally, Kafka Connect uses regular Kafka clients, so it has a lot of similar configuration settings and operation procedures.
Although it'’s recommended to always run the latest version of Kafka and Kafka Connect, you aren'’t required to do so. The Kafka community works hard to make sure that older clients are supported for as long as possible. This means you are always able to upgrade your Kafka and Kafka Connect clusters independently. Similarly, the Kafka Connect APIs are developed with backward compatibility in mind. This means you can use plug-ins that were developed against an older or newer version of the Kafka Connect API than the one you are running.
When Kafka Connect is run in distributed mode, it needs somewhere to store its configuration and status. Rather than requiring a separate storage system, Kafka Connect stores everything it needs in Kafka.
Now that you understand what Kafka Connect is, let'’s go over some of the use cases where it excels.
Use Cases
Kafka Connect can be used for a wide range of use cases that involve getting data into or out of Kafka. In this section we explore Kafka Connect'’s most common use cases and explain the benefits they provide for managing and processing data.
The use cases are:
- Capturing database changes
- Mirroring Kafka clusters
- Building data lakes
- Aggregating logs
- Modernizing legacy systems
Capturing database changes
A common requirement for data pipelines is for applications to track changes in a database in real time. This use case is called change data capture (CDC).
There are a number of connectors for Kafka Connect that can stream changes out of databases in real time. This means that instead of having many applications querying the database, you only have one; Kafka Connect. This reduces the load on the database and makes it much easier to evolve the schema of your tables over time. Kafka Connect can also transform the data by imposing a schema, validating data, or removing sensitive data before it is sent to Kafka. This gives you better control over other applications'’ views of the data.
There is a subset of connector plug-ins that remove the need to query the database at all. Instead of querying the database, they access the change log file that keeps a record of updates, which is a more reliable and less resource-intensive way to track changes.
The Debezium project provides connector plug-ins for many popular databases that use the change log file to generate events. In Chapter 5, we demonstrate two different ways to capture changes from a MySQL database: using a Debezium connector, and using a JDBC connector that performs query-based CDC.
Mirroring Kafka Clusters
Another popular use case of Kafka Connect is to copy data from one Kafka cluster to another. This is called mirroring and is a key requirement in many scenarios, such as building disaster recovery environments, migrating clusters, or doing geo-replication.
Although Kafka has built-in resiliency, in production-critical deployments it can be necessary to have a recovery plan in case your infrastructure is affected by a major outage. Mirroring allows you to synchronize multiple clusters to minimize the impact of failures.
You might also want your data available in different clusters for other reasons. For example, you might want to make it available to applications running in a different data center or region, or to have a copy with the sensitive information removed.
The Kafka project provides MirrorMaker to mirror data and metadata between clusters. MirrorMaker is a set of connectors that can be used in various combinations to fulfill your mirroring requirements. We cover how to correctly deploy and manage these in Chapter 6.
Building Data Lakes
You can use Kafka Connect to copy data into a purpose-built data lake or archive it to cost-effective storage like Amazon Simple Storage Service (Amazon S3). This is especially interesting if you need to keep large amounts of data or keep data for a long time (e.g., for auditing purposes). If the data is needed again in the future you can always import it back with Kafka Connect.
The Kafka community is currently adding support for tiered storage to Kafka. This means that in a future version, you will be able to configure Kafka to store some of its data in longer-term storage system without affecting connected applications. However, creating a complete copy of the data will still require a tool like Kafka Connect.
Copying your event data from Kafka into a dedicated storage system can also be useful for machine learning (ML) and artificial intelligence (AI), both of which commonly use training data. The more realistic the training data, the better your system becomes. Rather than creating mock data, you can use Kafka Connect to copy your real events to a location that can be accessed by your ML or AI system.
In Chapter 5, we demonstrate how to use a connector to export data from Kafka topics to a bucket in Amazon S3.
Aggregating Logs
It is often useful to store and aggregate data such as logs, metrics, and events from all of your applications. It is much easier to analyze the data once it is in a single location. Also, with the rise of the cloud, containers, and Kubernetes, you must expect the infrastructure to completely remove your workloads and recreate them from scratch if it observes an error. This means it'’s essential to store data such as logs in a central place, rather than with the application, in order to avoid losing them. Kafka is a great fit for data aggregation, as it'’s able to handle large volumes of data with very low latency.
Kafka can be configured as an appender by logging libraries like Apache Log4j2 to send logs directly from applications to Kafka instead of writing them to log files on storage. However, this only works for applications that can use this kind of library. Without Kafka Connect, you would likely need to add Kafka clients to many applications and systems as well as skill up all of your teams to understand how to write, deploy, and run those clients. Once you overcome this initial hurdle, you then have multiple different places to update if you change your mind about the shape of the data being collected or where it should be sent.
Adding Kafka Connect to these sorts of use cases reduces the overhead for collecting the data. You can have a single team deploy and manage the Kafka Connect cluster, and—given the sheer number of connectors already out there—they can often do so without writing any code. Since the connectors and their configuration are all handled through Kafka Connect, you can change data formats and target topics in one place.
Modernizing Legacy Systems
Modern architectures have trended toward deploying many small applications rather than a singular monolith. This can cause problems for existing systems that weren'’t designed to handle the workload of communicating with so many applications. They are also often unable to support real-time processing. Since Kafka is a publish/subscribe messaging system, it creates a separation between the applications sending data to it and those reading data from it. This makes it a very useful tool to have as an intermediary buffer between different systems. You can use Kafka Connect to make the legacy data available in Kafka, then have your new applications connect to Kafka instead. Kafka applications don'’t need to be connected all the time or read the data in real time. This allows legacy applications to process data in batches, avoiding the need to rewrite them.
Alternatives to Kafka Connect
Since there are many different data systems, it'’s no surprise that there are many different integration systems too. Kafka Connect is not the only tool designed for building data pipelines, and many other tools also support Kafka. We won'’t go into detail about all of the alternatives to Kafka Connect, but we will list a few popular ones. Each tool has its own specificities and you should pick one based on your requirements, current expertise, and tools. Many of the alternatives available provide integration with Kafka. The Kafka project supports multiple client versions, so your chosen tool does not necessarily use the latest Kafka client. However, if you use these tools, you may not be able to take advantage of new Kafka features as quickly as you could if you were using Kafka Connect.
Here are some open source alternatives you might consider:
- Apache Camel: An integration framework. It can be deployed standalone or embedded as part of an application server. Apache Camel includes a Kafka component that can get data into and out of Kafka.
- Apache NiFi: A system to process and distribute data that can be deployed in a cluster. Apache NiFi provides processors for sending data to and from Kafka.
- Apache Flume: A system to collect, aggregate, and move large amounts of log data from applications to a central location.
- LinkedIn Hoptimator: An SQL-based control plane for complex data pipelines. Hoptimator includes an adapter for Kafka.
Summary
A number of vendors offer support or custom distributions for the open source systems listed earlier. Many companies have also developed proprietary integration systems and platforms to target specific use cases or industries.
This first chapter introduced the current data landscape and the problems many organizations are facing with handling their data. Data is often spread across many different systems, which can make it hard for organizations to use it to gain insights and provide innovative services to their customers. Integration systems such as Kafka Connect are designed to solve these issues by providing easy, scalable, and reliable mechanisms to build data pipelines between various systems.
Kafka Connect has some key features that make it popular. It has a pluggable architecture that makes it easy to build complex pipelines with no code. It is scalable and reliable, with a useful REST management API that can be used to automate operations. Finally, it is part of the open source Apache Kafka project and benefits from the thriving Kafka community.
Download Kafka Connect
Ready to learn more about working with Kafka Connect? Download the full e-book from Red Hat Developer.