What is Kafka?
Apache Kafka is a distributed, open source messaging technology. It's all the rage these days, and with good reason: It's used to accept, record, and publish messages at a very large scale, in excess of a million messages per second. Kafka is fast, it's big, and it's highly reliable. You can think of Kafka as a giant logging mechanism on steroids.
What is Kafka used for?
Kafka is used to collect big data, conduct real-time analysis, and process real-time streams of data—and it has the power to do all three at the same time. It can feed events to complex event streaming systems or IFTTT and IoT systems or be used in accordance with in-memory microservices for added durability. It's distributed, which means it's highly scalable; adding new nodes to a Kafka cluster is all it takes.
Using Java and other programming languages with Kafka
Apache Kafka itself is written in Java and Scala, and, as you'll see later in this article, it runs on JVMs. Kafka's native API was written in Java as well. But you can write application code that interacts with Kafka in a number of other programming languages, such as Go, Python, or C#.
One of the nice things about Kafka from a developer's point of view is that getting it up and running and then doing hands-on experimentation is a fairly easy undertaking. Of course, there's a lot more work that goes into implementing Kafka clusters at the enterprise level. For enterprise installations, many companies will use a scalable platform such as Red Hat OpenShift or a service provider. Using a Kafka service provider abstracts away the work and maintenance that goes with supporting large-scale Kafka implementations. All that developers need to concern themselves with when using a service provider is producing messages into and consuming messages out of Kafka. The service provider takes care of the rest.
Yet, no matter what, at the most essential level a developer needs to understand how Kafka works in terms of accepting, storing, and emitting messages. In this piece, I'll cover these essentials. In addition, I'll provide instructions about how to get Kafka up and running on a local machine. I'll also demonstrate how to produce and consume messages using the Kafka Command Line Interface (CLI) tool. In subsequent articles, I'll cover some more advanced topics, such as how to write Kafka producers and consumers in a specific programming language.
We'll start with a brief look at the benefits that using the Java client provides. After that, we'll move on to an examination of Kafka's underlying architecture before eventually diving in to the hands-on experimentation.
What are the benefits of using a Java client?
As mentioned above, there are a number of language-specific clients available for writing programs that interact with a Kafka broker. One of the more popular is the Java client. Essentially, the Java client makes programming against a Kafka client a lot easier. Developers do not have to write a lot of low-level code to create useful applications that interact with Kafka. The ease of use that the Kafka client provides is the essential value proposition, but there's more, as the following sections describe.
Real-time data processing
When developers use the Java client to consume messages from a Kafka broker, they're getting real data in real time. Kafka is designed to emit hundreds of thousands—if not millions—of messages a second. Having access to enormous amounts of data in real time adds a new dimension to data processing. Working with a traditional database just doesn't provide this type of ongoing, real-time data access. Kafka gives you all the data you want all the time.
Decouple data pipelines
Flexibility is built into the Java client. For example, it's quite possible to use the Java client to create producers and consumers that send and retrieve data from a number of topics published by a Kafka installation. (As we'll discuss in more detail below, producers and consumers are the creators and recipients of messages within the Kafka ecosystem, and a topic is a mechanism for organizing those messages.) Switching among producers and consumers of message topics is just a matter of implementing a few lines of code. This means that the Kafka client is not dedicated to a particular stream of data. It can access different pipelines according to the need at hand.
Data integration
Kafka is by nature an event-driven programming paradigm. Events are represented by messages that are emitted from a Kafka broker. (You'll read more about this in sections to come.) Messages coming from Kafka are structured in an agnostic format. A message can contain a simple string of data, a JSON object, or packets of binary data that can be deserialized into a language-specific object.
This versatility means that any message can be used and integrated for a variety of targets. For example, you could set things up so that the content of a message is transformed into a database query that stores the data in a PostgreSQL database. Or that data could be passed on to a microservice for further processing. The agnostic nature of messages coming out of Kafka makes it possible to integrate that data with any kind of data storage or processing endpoint.
Scalability and automation
The Java client is designed with isolation and scalability in mind. Thus, it's quite possible to scale up clients within a Java application by spawning more threads using automation logic that is internal to the application.
However, there are times when running a large number of threads in a single application can be a burden to the host system. As an alternative, developers can scale up Java applications and components that implement Kafka clients using a distributed application framework such as Kubernetes. Using Kubernetes allows Java applications and components to be replicated among many physical or virtual machines. Developers can use automation scripts to provision new computers and then use the built-in replication mechanisms of Kubernetes to distribute the Java code in a load-balanced manner. The design of the Java client makes this all possible.
Kafka architecture
The Kafka messaging architecture is made up of three components: producers, the Kafka broker, and consumers, as illustrated in Figure 1. We'll discuss these in more detail in the following sections.

Brokers and clusters
Kafka runs using the Java Virtual Machine (JVM). An individual Kafka server is known as a broker, and a broker could be a physical or virtual server. A Kafka cluster is composed of one or more brokers, each of which is running a JVM. The Kafka cluster is central to the architecture, as Figure 1 illustrates.
ZooKeeper
In most Kafka implementations today, keeping all the cluster machines and their metadata in sync is coordinated by ZooKeeper. ZooKeeper is another Apache project, and Apache describes it as "a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services."
While Kafka uses ZooKeeper by default to coordinate server activity and store metadata about the cluster, as of version 2.8.0 Kafka can run without it by enabling Kafka Raft Metadata (KRaft) mode. When KRaft is enabled, Kafka uses internal mechanisms to coordinate a cluster's metadata. However, as of this writing, some companies with extensive experience using Kafka recommend that you avoid KRaft mode in production.
Producers and consumers
Producers create messages that are sent to the Kafka cluster. The cluster accepts and stores the messages, which are then retrieved by a consumer.
There are two basic ways to produce and consume messages to and from a Kafka cluster. One way is to use the CLI tool, which is appropriate for development and experimental purposes, and that's what we'll use to illustrate Kafka concepts later on in this article.
Remember, though, that Kafka is designed to emit millions of messages in a very short span of time. Consuming messages at this rate goes far behind the capabilities of using the CLI tool in the real world. And in a production situation, once a message is consumed, it most likely will either be processed by the consumer or forwarded onto another target for processing and subsequent storage. Again, this type of computing is well beyond the capabilities of the CLI tool. A fast, robust programming environment is required, and so for production purposes, the preferred technique is to write application code that acts as a producer or a consumer of these messages. This too is illustrated in Figure 1.
Events
Typically, messages sent to and from Kafka describe events. For example, an event can be a TV viewer's selection of a show from a streaming service, which is one of the use cases supported by the video streaming company Hulu. Another type of event could describe the workflow status of content creation at a daily newspaper, which is one of the New York Times' use cases.
Schema
A schema defines the way that data in a Kafka message is structured. You can think of a schema as a contract between a producer and a consumer about how a data entity is described in terms of attributes and the data type associated with each attribute. Using a consistent data schema is essential for message decoupling in Kafka.
For example, at the conceptual level, you can imagine a schema that defines a person data entity like so:
firstName (string)
lastName (string)
age (number)
This schema defines the data structure that a producer is to use when emitting a message to a particular topic that we'll call Topic_A. (Topics will be described in detail in the following section.) The schema also describes what the consumer expects to retrieve from Topic_A.
Now, imagine another producer comes along and emits a message to Topic_A with this schema:
fname (string)
lname (string)
dob (date)
In this case, the consumer wouldn't know what to do. Code within the consumer would log an error and move on. In order for an event-driven system to work, all parties need to be using the same data schema for a particular topic.
Topics and partitions
The organizational unit by which Kafka organizes a stream of messages is called a topic. You can think of a topic as something like an email inbox folder. A key feature of Kafka is that it stores all messages that are submitted to a topic. When you first set Kafka up, it will save those messages for seven days by default; if you'd like, you can change this retention period by altering settings in the config/server.properties file.
Under Kafka, a message is sent or retrieved according to its topic, and, as you can see in Figure 2, a Kafka cluster can have many topics.
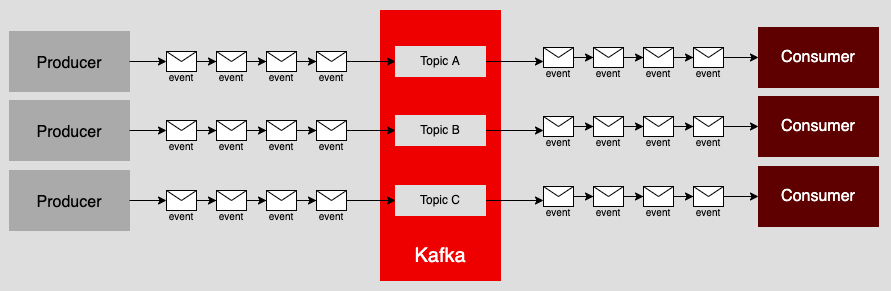
Topics are a useful way to organize messages for production and consumption according to specific types of events. For example, imagine a video streaming company that wants to keep track of when a customer logs into its service. The same company wants to keep track of when a user starts, pauses, and completes movies from its catalog. Instead of sending all those messages to a single consumer, a developer can program the set-top box or smart television application to send login events to one topic and movie start/pause/complete events to another, as shown in Figure 3.

There are a few benefits to using topics. First, producers and consumers dedicated to a specific topic are easier to maintain, because you can update code in one producer without affecting others. The same is true for consumers. When all events are created by one producer and sent to only a single consumer, even making a subtle change in the consumer or producer means that the entire code base will need to be replaced. This is not a trivial matter.
Secondly, separating events among topics can optimize overall application performance. Remember, Kafka is typically used in applications where logic is distributed among a variety of machines. Thus, you can configure the Kafka cluster as well as producers and consumers to meet the burdens at hand.
For example, a consumer that's bound to a topic that emits hundreds of thousands of messages a second will need a lot more computing power than a consumer bound to a topic that's expected to generate only a few hundred messages in the same timespan. Logic dictates that you put the consumer requiring more computing power on a machine configured to meet that demand. The less taxing consumer can be put on a less powerful machine. You'll save in terms of resource utilization, but also in terms of dollars and cents, particularly if the producers and consumers are running on a third-party cloud.
Partitions distribute data across Kafka nodes. All topics are divided into partitions, and partitions can be placed on separate brokers. This facilitates the horizontal scaling of single topics across multiple servers in order to deliver superior performance and fault-tolerance far beyond the capabilities of a single server.
Message streams in Kafka
Topics provide a lot of versatility and independence for working with messages. While it's possible that a one-to-one relationship between producer, Kafka cluster, and consumer will suffice in many situations, there are times when a producer will need to send messages to more than one topic and a consumer will need to consume messages from more than a single topic. Kafka can accommodate complex one-to-many and many-to-many producer-to-consumer situations with no problem.
Figure 4 illustrates a single consumer retrieving messages from many topics, in which each topic has a dedicated producer.
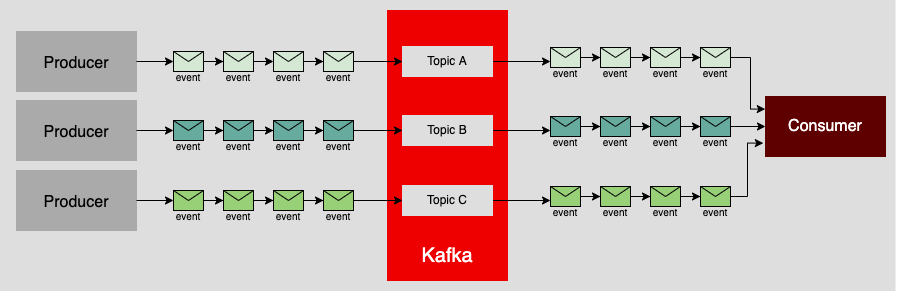
Figure 5 shows a single producer creating messages that are sent to many topics. Notice that each topic has a dedicated consumer that will retrieve its messages.

Figure 6 shows a situation in which the middle producer in the illustration is sending messages to two topics, and the consumer in the right-middle of the illustration is retrieving messages from all three topics.
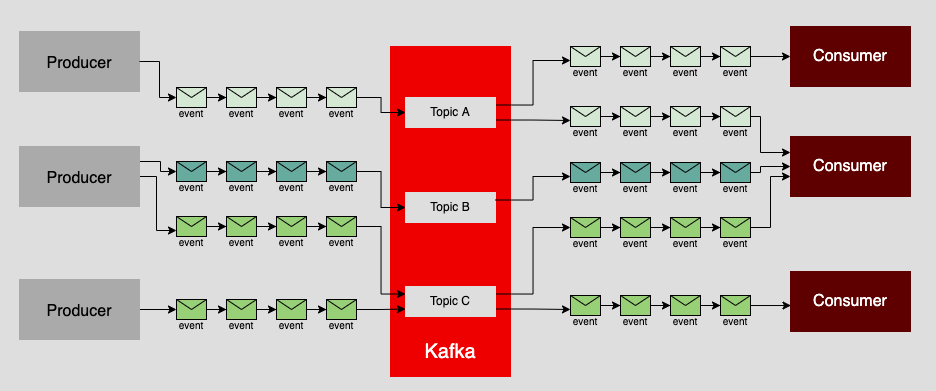
The thing to remember about mixing and matching producers and consumers in one-to-one, one-to-many, or many-to-many patterns is that the real work at hand is not so much about the Kafka cluster itself, but more about the logic driving the producers and consumers. For better or worse, while there is very complex work being done internally within Kafka, it's pretty dumb in terms of message management. The scope of Kafka's concern is making sure that a message destined for a topic gets to that topic, and that consumers can get messages from a topic of interest. The actual logic that drives a message's destination is programmed in the producer. The same is true for determining topics of interest for a consumer. There is no magic in play. The content of the messages, their target topics, and how they are produced and consumed is work that is done by the programmer.
Batches
One of the reasons Kafka is so efficient is because events are written in batches. A batch is a collection of events produced to the same partition and topic. Batches can be enormous, with streams of events happening at once. The larger the batches, the longer individual events take to propagate.
What setup do you need to get started?
Now that you have a basic understanding of what Kafka is and how it uses topics to organize message streams, you're ready to walk through the steps of actually setting up a Kafka cluster. Once you've done that, you'll use the Kafka CLI tool to create a topic and send messages to that topic. Finally, you'll use the CLI tool to retrieve messages from the beginning of the topic's message stream.
The step-by-step guide provided in the sections below assumes that you will be running Kafka under the Linux or macOS operating systems. If you're running Windows, the easiest way to get Kafka up and running is to use Windows Subsystem for Linux (WSL). Running terminals under WSL is nearly identical to running them on Linux.
To begin, you need to confirm the Java runtime is installed on your system, and install it if it isn't. In a terminal window, execute the following command:
java -version
You will see output similar to the following:
openjdk version "11.0.13" 2021-10-19
OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
If not, you'll need to install the Java runtime. This is how you'd do it on Linux:
sudo apt update -y && sudo apt install default-jre -y
If you're using Red Hat Enterprise Linux, Fedora, or CentOS, execute the following command to install Java:
sudo dnf update -y && sudo dnf install java-11-openjdk-devel -y
On macOS, if you have Homebrew installed, you can install Java using these two commands:
$ brew tap caskroom/cask
$ brew cask install java
Next, you need to install Kafka. The following commands will download the Kafka.tgz file and expand it into a directory within the HOME directory.
cd ~/
wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz
tar -xzf kafka_2.13-3.1.0.tgz
Now you need to get ZooKeeper up and running. In a separate terminal window, execute the following commands:
cd ~/kafka_2.13-3.1.0
bin/kafka-server-start.sh config/server.properties
You'll see Zookeeper start up in the terminal and continuously send log information to stdout.
Finally, you're ready to get Kafka itself up and running. Go back to the first terminal window (the one where you downloaded Kafka) and execute the following commands:
cd ~/kafka_2.13-3.1.0
bin/kafka-server-start.sh config/server.properties
You'll see Kafka start up in the terminal. It too will continuously send log information to stdout. That means your Kafka instance is now ready for experimentation!
Running Kafka in a Linux container
Kafka can be hosted in a standalone manner directly on a host computer, but it can also be run as a Linux container. The following sections describe how to run Kafka on a host computer that has either Docker or Podman installed.
How to start Kafka in Docker
Kafka can be run as a Docker container. Before you can do so, Docker must be installed on the computer you plan to use.
To see if your system has Docker installed, type the following in a terminal window:
which docker
If Docker is installed you'll see output that looks something like this:
/usr/local/bin/docker
Should this call result in no return value, Docker is not installed, and you should install it. Docker's documentation describes how to install Docker on your computer.
Once Docker is installed, execute the following command to run Kafka as a Linux container:
docker run -it --name kafka-zkless -p 9092:9092 -e LOG_DIR=/tmp/logs quay.io/strimzi/kafka:latest-kafka-2.8.1-amd64 /bin/sh -c 'export CLUSTER_ID=$(bin/kafka-storage.sh random-uuid) && bin/kafka-storage.sh format -t $CLUSTER_ID -c config/kraft/server.properties && bin/kafka-server-start.sh config/kraft/server.properties'
How to start Kafka with Podman
Podman is a container engine you can use as an alternative to Docker. To see if your system has Podman installed, type the following in a terminal window:
which podman
If Podman is installed, you'll see output similar to the following:
/usr/bin/podman
Should this call result in no return value, Podman is not installed. Podman's documentation walks you through the installation process. Once Podman is installed, execute the following command to run Kafka as a Linux container using Podman:
podman run -it --name kafka-zkless -p 9092:9092 -e LOG_DIR=/tmp/logs quay.io/strimzi/kafka:latest-kafka-2.8.1-amd64 /bin/sh -c 'export CLUSTER_ID=$(bin/kafka-storage.sh random-uuid) && bin/kafka-storage.sh format -t $CLUSTER_ID -c config/kraft/server.properties && bin/kafka-server-start.sh config/kraft/server.properties'
Producing Kafka messages
You now should have Kafka installed in your environment and you're ready to put it through its paces. In the following steps, you'll create a topic named test_topic and send messages to that topic.
Step 1: Create a topic
Open a new terminal window, separate from any of the ones you opened previously to install Kafka, and execute the following command to create a topic named test_topic.
cd ~/kafka_2.13-3.1.0
bin/kafka-topics.sh --create --topic test_topic --bootstrap-server localhost:9092
Step 2: Produce some messages
In the terminal window where you created the topic, execute the following command:
bin/kafka-console-producer.sh --topic test_topic --bootstrap-server localhost:9092
At this point, you should see a prompt symbol (>). This indicates that you are at the command prompt for the Kafka CLI tool for producing messages. Enter the following message:
This is my first event message, which is cool!
Press the Enter key and then enter another message at the same prompt:
This is my second event message, which is even cooler!!
To exit the Kafka CLI tool, press CTRL+C.
Consuming Kafka messages
In the open Kafka CLI terminal window in which you've been producing messages, execute the following command to consume the messages from the topic named test_topic from the beginning of the message stream:
$ bin/kafka-console-consumer.sh --topic test_topic --from-beginning --bootstrap-server localhost:9092
You'll have to wait a few seconds for the consumer to bind to the Kafka server. Once it's done, you'll see the following output:
This is my first event, which is cool!
This is my second event, which is even cooler!
You've consumed all the messages in the topic named test_topic from the beginning of the message stream.
Putting it all together, and a look ahead
This article has covered the very basics of Kafka. You learned about the concepts behind message streams, topics, and producers and consumers. Also, you learned about message retention and how to retrieve past messages sent to a topic. Finally, you got some hands-on experience installing and using Kafka on a computer running Linux.
Having a solid understanding of the fundamentals of Kafka is important. But please be advised that there is a lot more to know, particularly about the mechanisms that Kafka uses to support distributed messaging over a cluster made up of many computers.
Kafka is powerful. Using it to its full potential can become a very complex undertaking. Still, the basics discussed in this article will provide a good starting point for working with the technology in a fundamental way.
The next article in this series will show you how to write code that uses the KafkaProducer, which is part of the Java Kafka client, to emit messages to a Kafka broker continuously. Then you'll use the KafkaConsumer to continuously retrieve and process all the messages emitted.
Want to learn more about Kafka in the meantime? Check out the Red Hat OpenShift Streams for Apache Kafka learning paths from Red Hat Developer.
Last updated: April 6, 2022