This article is the first in a series that explains Kubernetes storage on a high level. In the series, I provide information for a programmer or software architect to decide which types of storage meet the requirements for their applications running on Kubernetes. This series provides links to help you go deeper into your chosen technologies but does not dig into YAML syntax or Kubernetes APIs. Whether a novice or experienced with Kubernetes, this overview can guide you toward a storage architecture that is right for your application.
Follow the series:
I explain the concepts of persistent volumes and storage provisioners and how they enable system administrators to manage storage for a Kubernetes cluster.
I define the unique needs of containerized applications. I also describe how CSI drivers enable advanced storage features necessary for production environments and why they are useful for CI/CD pipelines.
In this article, I explain why storage is important, even for developers who plan to develop "stateless" applications based on microservices architectures. I will also explain the role of Kubernetes in managing and providing storage volumes for applications running as pods.
Why storage should matter to developers
I have heard more than once from fellow developers, "I do not care about storage." That might be acceptable for some applications and at some moments of development. As long as they have a place to store their data, they do not care where it is or which technology it uses.
As your applications move into production, you learn that not all storage is made equal, especially in shops that adopt DevOps. Different types of storage can significantly impact your applications' cost, performance, and reliability. For example, Azure offers five types of disks for cloud instances usage. There's more than an order of magnitude of difference between the throughput and IOPS performance of these types.
The concerns go beyond performance. Sometimes selecting the wrong storage type affects your application's reliability. In the worst-case scenario, a poor choice can lead to data loss or unreliable data consistency. For example, some applications do not work well over network file systems and should instead use SAN block storage.
Usually, more than one type of storage is available for a given Kubernetes cluster. Configuration—whether through application manifests, Helm charts, or custom resources—should be flexible to allow an application to connect to a storage type that matches its requirements. Developers should allow operations personnel to configure production deployments with the best storage for each environment while using the same set of manifests for development and testing environments.
Few cloud-native applications are stateless
According to the twelve-factor application design principles, aren't cloud-native applications supposedly stateless? If so, why would any developer working on greenfield applications care about storage? Would that be a concern only for developers using legacy technology stacks?
In truth, very few real-world applications are completely stateless. Most applications need to store data about users, customers, transactions, game state, recommendations, etc. The twelve-factor principles advocate storing that state in a more persistent location than application memory.
The preferred approach delegates complex data storage requirements to specialized middleware such as databases, messaging systems, and caching servers. Traditional applications use a relational database (shown in Figure 1) and also maintain some data in application memory.

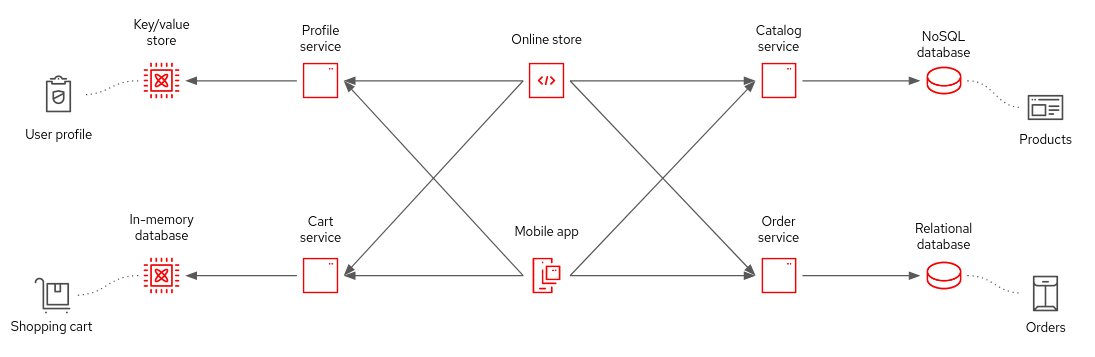
Modern, containerized applications are more likely to use a variety of storage mechanisms appropriate to different needs (shown in Figure 2). If the data storage requirements are simple, then saving and loading data in files should be fine.
There are arguments that state "cloud-native applications are stateless" or "storage-intensive applications must run outside of Kubernetes.” To counter these arguments, a Red Hat study found that the three most common production workloads on Kubernetes are databases, data analytics, and logging or monitoring systems. All of these workloads need to store persistent data as files.
If you are skeptical about a study from Red Hat, a storage vendor, then search the internet, and you will find corroborating data from many sources. For example, a study by the application monitoring vendor Data Dog lists the ten most deployed container images, eight of which require persistent storage. Among them are developer infrastructure tools such as PostgreSQL, Elasticsearch, Kafka Jenkins, and GitLab.
The importance of stateful workloads for developers using Kubernetes is not big news. A study by the Cloud Native Computing Foundation (CNCF) showed that 55% of respondents were running stateful workloads in production, while only 22% were running stateless workloads.
The bottom line is you may not be writing code that reads and saves data, but your code almost certainly depends on something else that does.
Later in this series of articles, we will return to stateless and stateful application concepts and how Kubernetes resource controllers deal with them.
OS-based file and block storage vs. object storage
Most programmers first learn how to manage storage as files, folders, and disks that programs read and write through the operating system (Figure 3). Under the hood, various specialized middleware (ie. databases) uses OS operations to deal with storage.
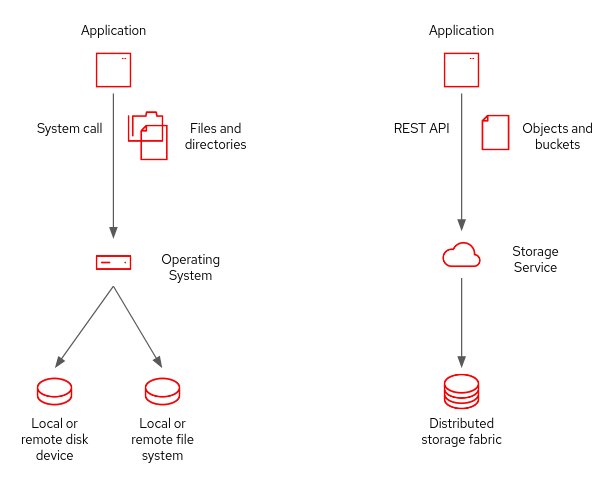
Nowadays, many developers prefer object storage services based on S3 API. Cloud providers support object storage, and on-premises data centers can get similar capabilities from open source software such as Ceph and MinIO.
A future article will focus on a software development perspective of how object storage differs from file-based and block-based storage. For now, it is sufficient to say that Kubernetes standard storage primitives deal only with file and block-based storage. But Kubernetes does not get in the way if your application uses object storage.
The role of Kubernetes in storage management
Before Kubernetes, managing storage was a labor-intensive task performed by system administrators. They handled the preliminary work to support applications at either the NAS/SAN level or the server enclosure. Once the organization had some disks connected to a server or virtual machine (VM), someone had to perform various tasks, such as formatting volumes, mounting them at the correct file system path, assigning file and group ownership, and granting directory and file access permissions. These tasks were unseen by most developers, who complained that IT took too long to provision the VM instances they needed to run their applications.
The good news is that Kubernetes takes care of all that, automating the process of making storage available to your pods. As with computing capacity and network connectivity, providing storage capacity becomes effortless with Kubernetes.
If your pods are destroyed for any reason (including the normal process of scaling up and down), or their replacement pods land in a different cluster node from the original pods, Kubernetes will disconnect storage volumes from the old nodes and connect them to the new nodes, ensuring that your applications maintain access to their data.
This automation makes storage seem "invisible" to developers using Kubernetes and provides truly self-service environments where developers and CI/CD pipelines can deploy applications and test them at will without waiting for IT to configure and provision environments.
Storage is integral to Kubernetes
Since few applications are truly stateless, Kubernetes performs an essential role in ensuring that the storage resources required by these applications are available in the cluster nodes where they run. Kubernetes enables developer agility by eliminating the need to manually configure storage resources in each individual server, and by moving storage around as application pods are rescheduled.
Read the next article in this series, A developer’s guide to the functions of Kubernetes storage, to learn the essential primitives of Kubernetes storage such as volumes, claims, and storage classes. You will also discover how these mechanisms enable developers to collaborate with system administrators to ensure that applications connect to their required storage services in different environments.
Thanks a lot to Andy Arnold and Greg Deffenbau for their reviews of this article.
Last updated: September 19, 2023