The race is about to start.
The driver is focusing on the track and his adrenaline is at its peak.
The engineers are already at their computers, ready to check that everything is working fine on the car.
The red lights will turn on one after the other, and when they all turn off together the challenge will begin.
One side must drive as fast as possible, choose the right line, and overtake the opponents.
The other side must analyze the telemetry, spotting potential anomalies and providing feedback to the driver.
Everyone has a single goal: to reach the checkered flag first.
The time has come! Five, four, three, two, one ... go!
A Formula 1 data-streaming infrastructure
The story we just told plays out on every race weekend in the Formula 1 season.
We are not lucky enough to be drivers, so let's see how the engineers on the team can exploit multiple software technologies to process telemetry data in a Java application in real time.
During the free practices, qualifying, and race, a huge amount of data is collected by the car's sensors and sent back to the team to be analyzed. The analysis improves the car's performance, spots anomalies, and provides feedback to the driver to help them shave a few milliseconds off of each lap.
In this article, you'll learn how to set up a complete open source stack for monitoring Formula 1 telemetry data—how to ingest the data, and how to set up dashboards that let you monitor it—with everything running in a cloud environment. Figure 1 shows Red Hat OpenShift Streams for Apache Kafka with some of the open source technologies used in this article.
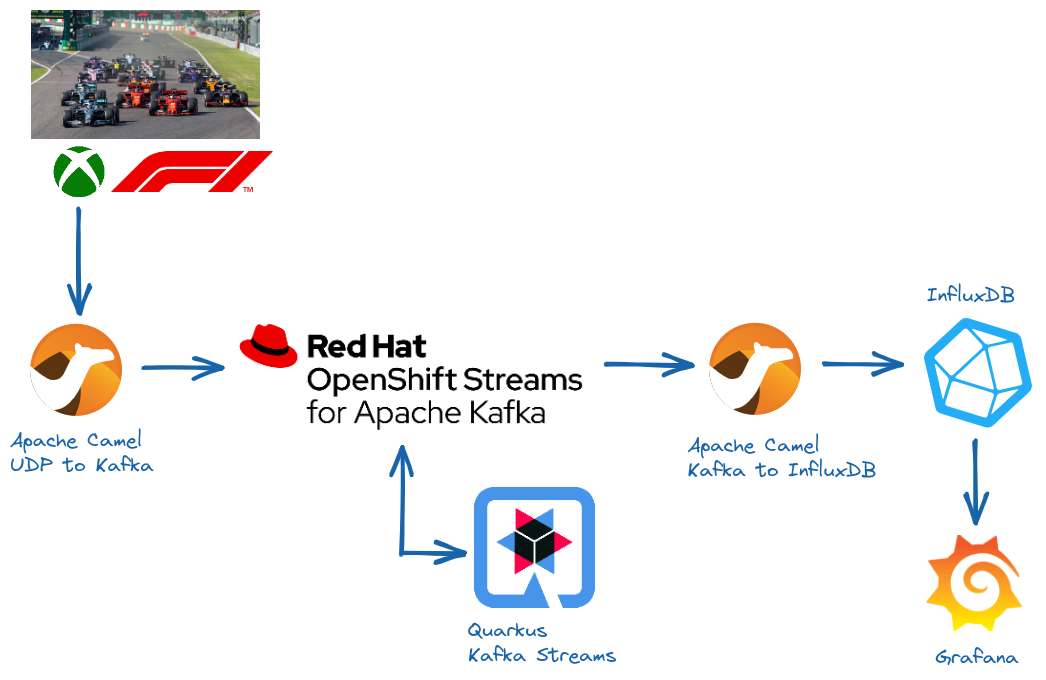
How to get telemetry data
Unfortunately, getting access to real Formula 1 telemetry data is not easy. But we can get some simulated data as the next best thing.
For this purpose, the F1 2021 game from Codemasters - Electronic Arts works really well. It provides telemetry data for all the cars in a race, sending that data over the UDP port (on a Microsoft Xbox, for example).
The packet specification is open and freely available, so we developed the Formula 1 - Telemetry decoding library in Java that decodes the raw bytes to provide high-level models of all the information: drivers, car status, lap times, and lots more.
An OpenShift-based ingestion platform
The first step is to find a way to ingest the telemetry data with low latency, high throughput, and durable storage. We cite these requirements because, in addition to real-time processing, the engineers could also be interested in replaying the data after the race for more advanced analysis.
A platform that can provide all these features out of the box is Apache Kafka. However, running Kafka in the cloud, particularly on Kubernetes, is not straightforward. It's better to have someone else handle the burden for you.
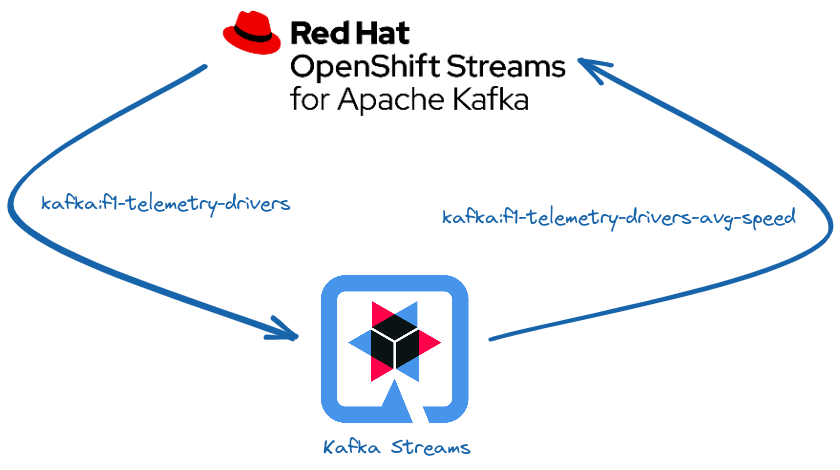
This is where OpenShift Streams for Apache Kafka comes into the picture. The service is based on the open source Strimzi project from the Cloud Native Computing Foundation (CNCF). Thanks to OpenShift Streams for Apache Kafka, you can spin up a Kafka cluster in a few minutes just by using the Web user interface on the Red Hat Cloud (Figure 2) or by using the rhoas command-line interface (CLI).
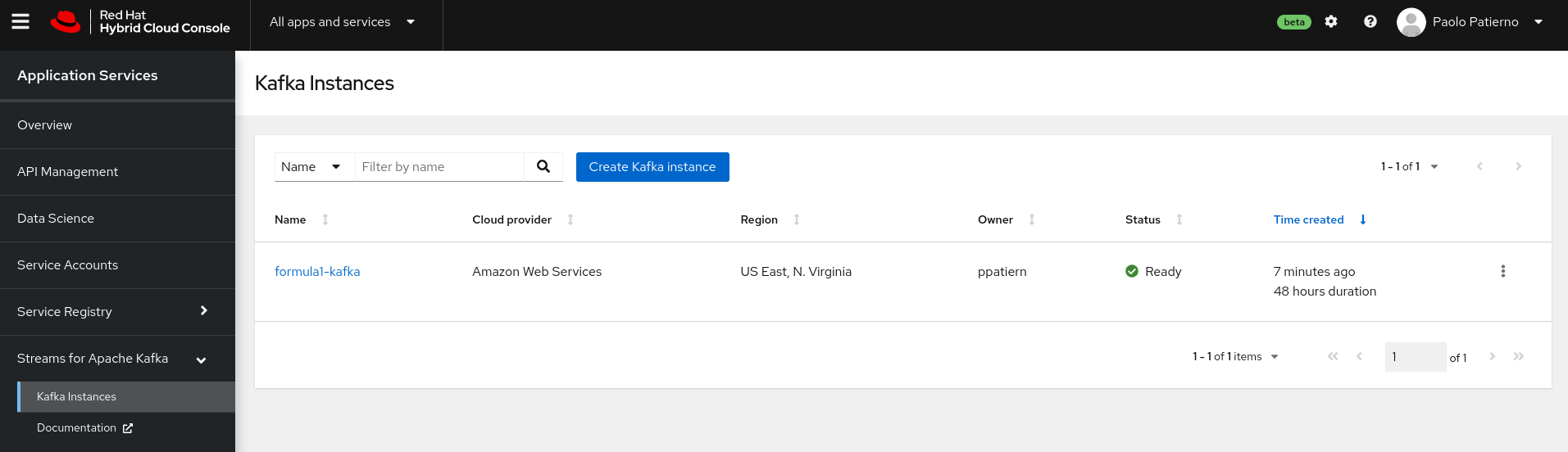
Red Hat handles all your concerns about having the service up and running 365/24/7, so you can focus on writing cloud-native applications that use a Kafka cluster for events and data streaming. OpenShift Streams for Apache Kafka simplifies basic Kafka tasks such as creating topics, defining the service accounts with the corresponding permissions to write to and read from the topics, and monitoring the status of your Kafka cluster in terms of used storage, throughput, client connections, and bytes in movement (Figure 3).
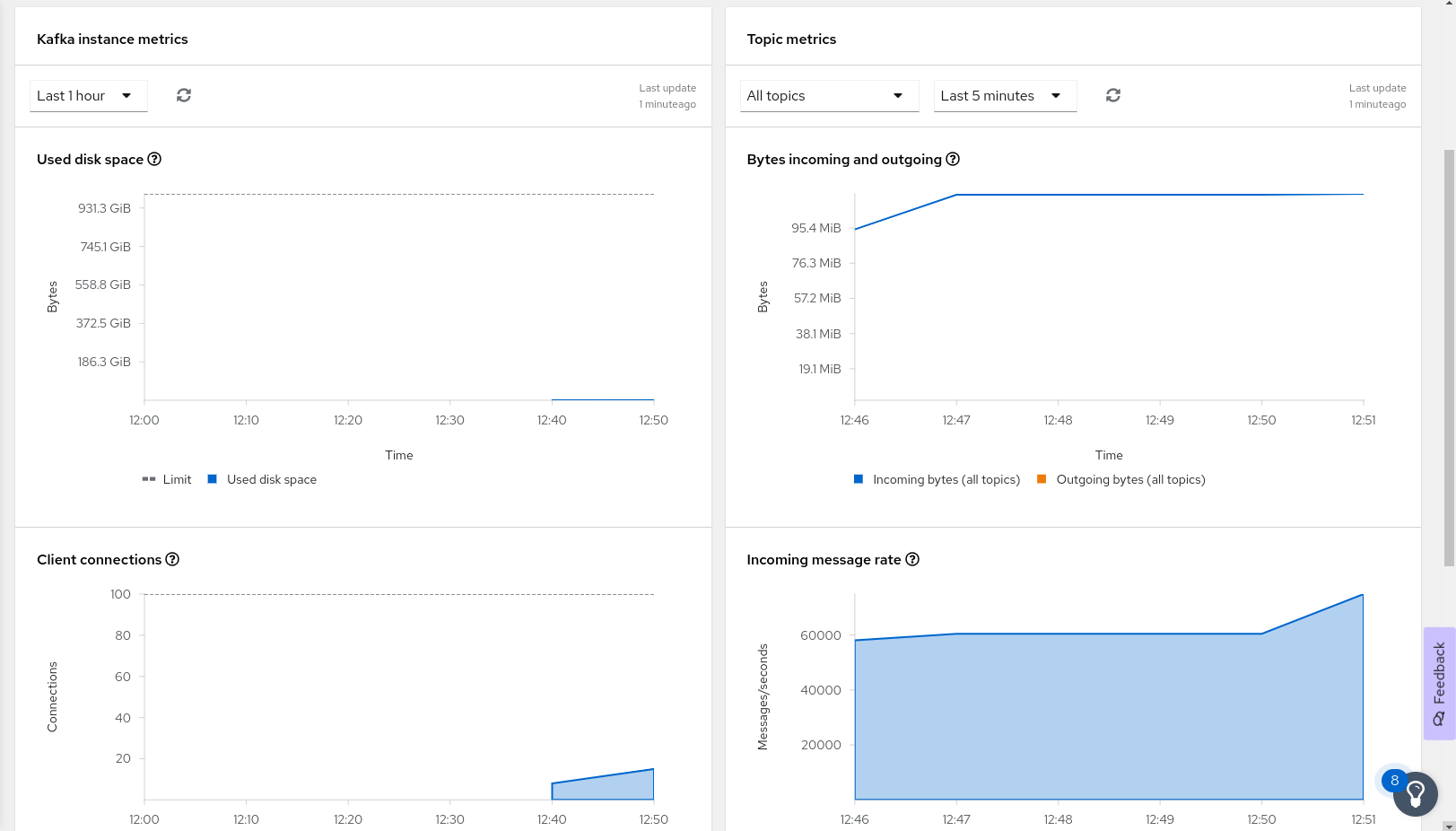
The Formula 1 telemetry on Red Hat OpenShift Streams for Apache Kafka GitHub repository contains all you need to automate the setup of a Kafka cluster in OpenShift Streams for Apache Kafka, together with the corresponding topics and service accounts needed for the Formula 1 applications. Just follow the steps and run some scripts. The required Kafka instance will be deployed for you.
From ingestion to monitoring
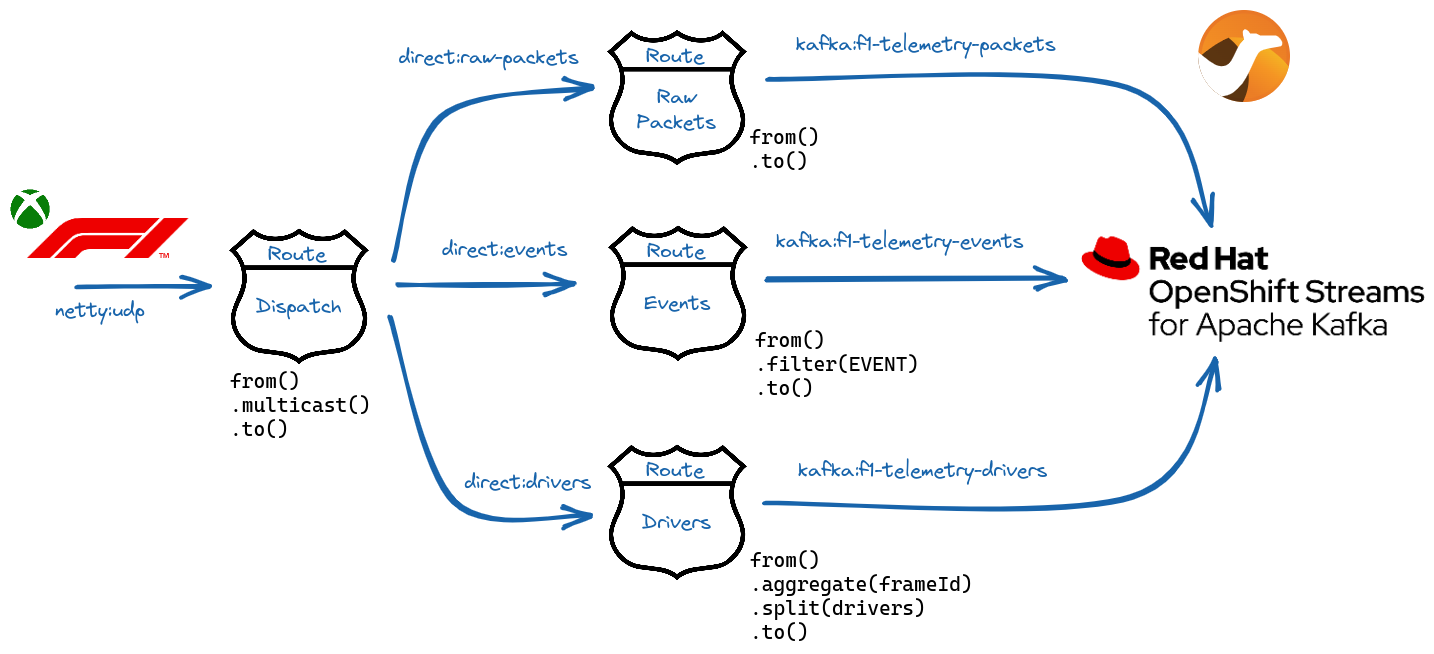
To complete the data ingestion part of your application, you need to move data from the UDP port, where it is coming from the Xbox, to the Kafka cluster. The Apache Camel integration framework makes this step really easy.
Through a simple application made up of different routes, it's possible to decode the packets and send them to multiple topics (Figure 4) containing:
- The raw packets as they come in
- Aggregated driver data together with all the information related to car status, telemetry, motion, and lap data
- Race events such as speed traps and best lap
Another application based on Apache Camel reads from these topics and writes the corresponding messages as data points into a time series database such as InfluxDB (Figure 5).

The database can be a data source for Grafana dashboards that help engineers monitor all the telemetry (Figure 6).
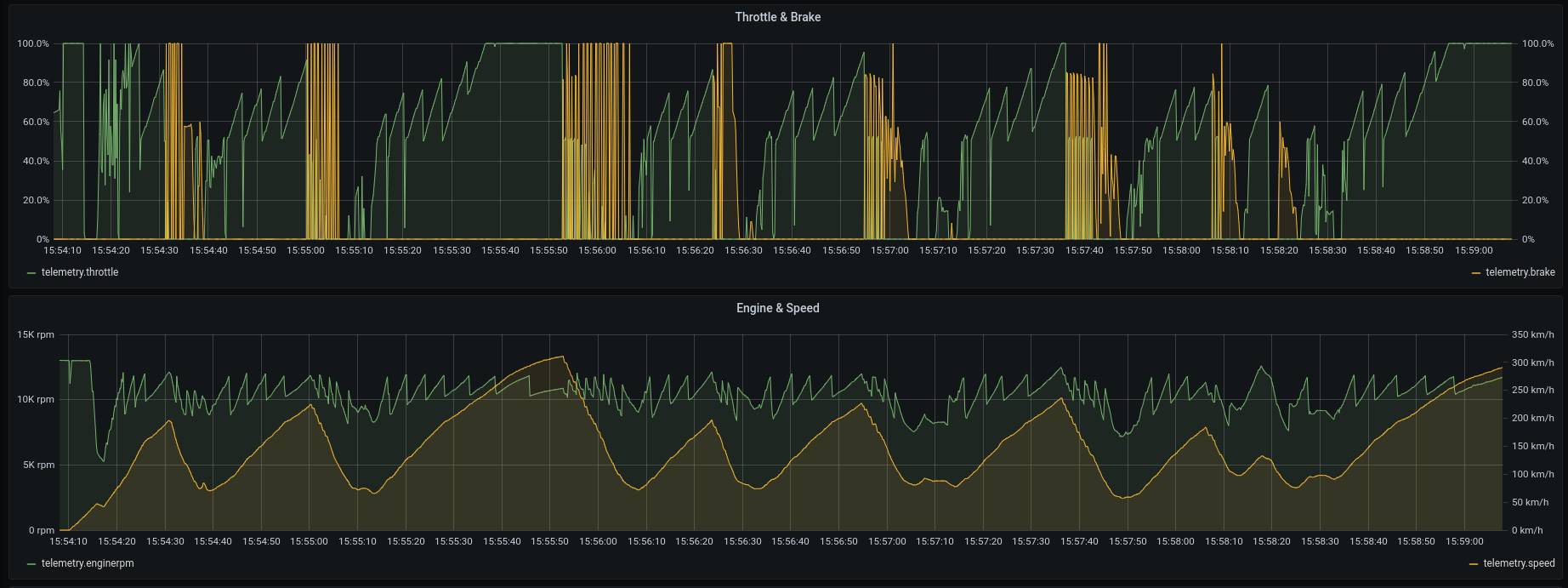
Real-time processing
A data-streaming platform can go way beyond ingesting data to show on dashboards. It's really valuable for real-time processing.
The Apache Kafka project comes with its own Kafka Streams API library that can process continuous flows of data, getting insights from it in real time and reacting accordingly.
You can build your own Kafka Streams API pipeline by designing a so-called topology from the source node to the sink node. The pipeline can pass through multiple processing nodes that run multiple operations such as mapping, filtering, grouping, and much more (Figure 7).
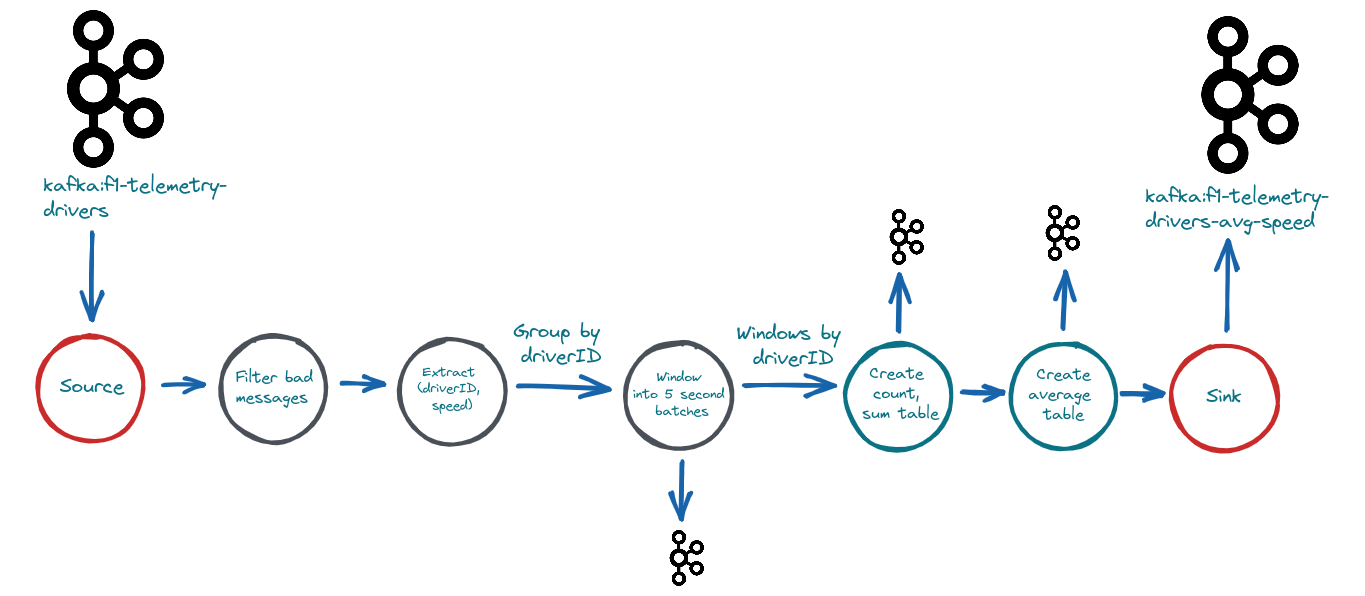
In this specific use case, the repository provides a couple of applications as examples of real-time processing in Formula 1 (Figure 8):
- Using the windowing feature to get the average speed of all cars in the most recent 5 seconds.
- Getting the best overall timings in each sector of the track during the lap.
But sometimes, writing an application based on the Kafka Streams API involves a lot of boilerplate code just for configuring and starting up the application. This is where the Quarkus framework comes in. Quarkus is a Kubernetes-native Java stack with support for best-of-breed Java libraries and standards. Quarkus supports the Kafka Streams API, allowing developers to focus on writing the topology of the application while the framework takes care of running it, hiding the boilerplate code.
To add to a developer's joy, Quarkus also provides a useful web UI showing your topology.
At the same time, thanks to native compilation with the GraalVM compiler, Quarkus makes it possible to get the best performance possible from your Java application.
Conclusion
Simulated Formula 1 telemetry data provides an example of how to build a very real-time analytics pipeline by using multiple technologies, all tied together and completely open source.
You can actually try out these applications by following the steps described in the Formula 1 - Telemetry with Apache Kafka repository, where you can find the entire codebase as well.
If you want to know more about these technologies, feel free to join us at the Red Hat Summit 2022 on May 10-11. It's virtual and free. We will lead a session on the process in this article, Formula 1 telemetry processing using Quarkus and OpenShift Streams for Apache Kafka, and go through the process in much more detail.
Looking forward to having you there.
Last updated: October 6, 2023