Apache Kafka is designed for performance and large volumes of data. Kafka's append-only log format, sequential I/O access, and zero copying support high throughput with low latency. Its partition-based data distribution allows it to scale horizontally to hundreds of thousands of partitions.
Because of these capabilities, it can be tempting to use a single monolithic Kafka cluster for all your eventing needs. Using one cluster reduces operational overhead and development complexities to a minimum. But is "a single Kafka cluster to rule them all" the ideal architecture, or is it better to split Kafka clusters?
Are you ready to experiment with Kafka? Get started in minutes with a no-cost Kafka service trial.
To answer that question, consider the segregation strategies for maximizing performance and optimizing cost while increasing Kafka adoption. We also must understand the impact of using Kafka as a service on a public cloud or managing it yourself on-premise. This article explores these questions and more, offering a structured way to decide whether or not to segregate Kafka clusters in your organization.
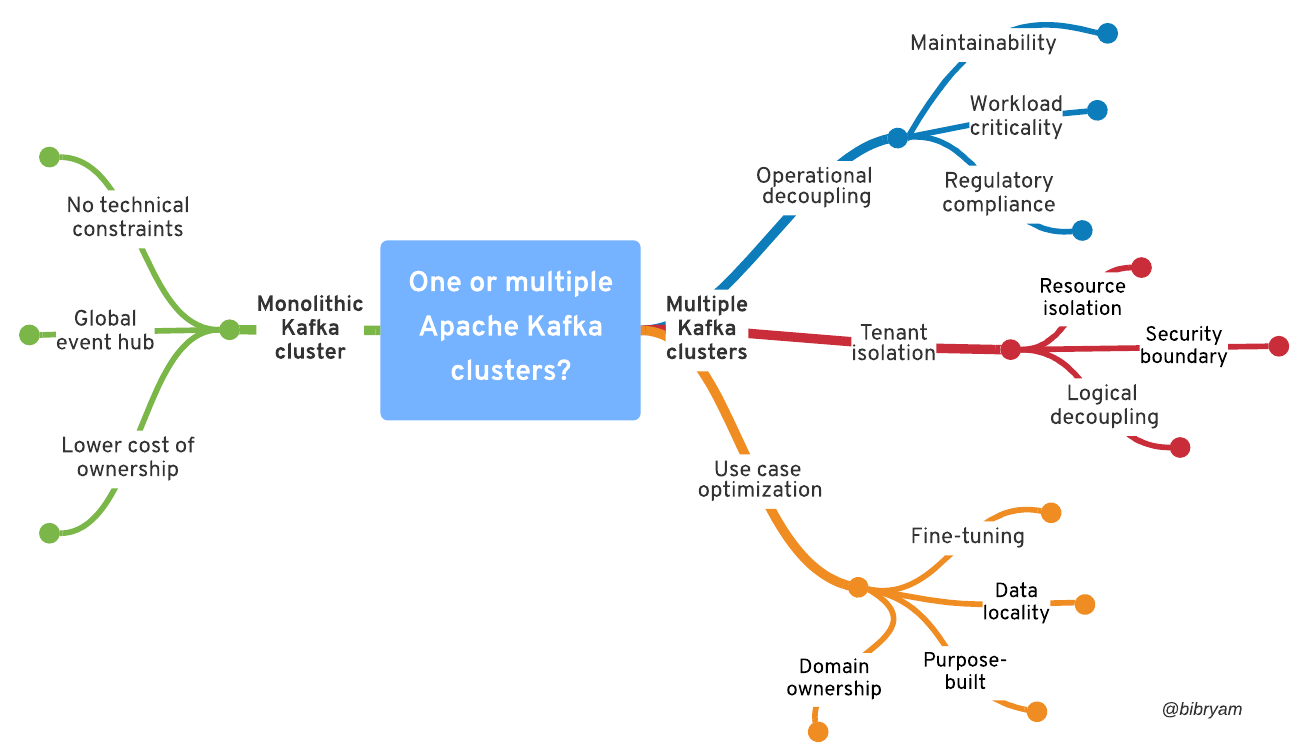
Figure #1 summarizes the questions explored in this article.
Three benefits of a monolithic Kafka cluster
To start, let's explore some of the benefits of using a single, monolithic Kafka cluster. Note that I don't mean literally a single Kafka cluster for all environments, but a single production Kafka cluster for the entire organization. The different environments would still typically be fully isolated with their respective Kafka clusters. A single production Kafka cluster is simpler to use and operate and is a no-brainer as a starting point.
1. A global event hub
Many companies are sold on the idea of having a single "Kafka backbone" and the value they can get from it. The possibility of combining data from different topics from across the company arbitrarily in response to future and yet unknown business needs is a huge motivation. As a result, some organizations end up using Kafka as a centralized enterprise service bus (ESB) where they put all their messages under a single cluster. The chain of streaming applications is deeply interconnected.
This approach can work for companies with a small number of applications and development teams, and with no hard departmental data boundaries that are enforced in large corporations by business and regulatory forces. (Note that this singleton Kafka environment expects no organizational boundaries.)
The monolithic setup reduces concerns about event boundaries, speeds up development, and works well (until an operational or a process limitation occurs).
2. No technical constraints
Certain technical features are available only within a single Kafka cluster. For example, a common pattern used by stream processing applications is to perform read-process-write operations in a sequence without any tolerances for errors that could lead to duplicates or loss of messages. To address that strict requirement, Kafka offers transactions that ensure that each message is consumed from the source topic and published to a target topic in exactly-once processing semantics. That guarantee is possible only when the source and target topics are within the same Kafka cluster.
A consumer group, such as a Kafka Streams-based application, can process data from a single Kafka cluster only. Therefore, multi-topic subscriptions or load balancing across the consumers in a consumer group are possible only within a single Kafka cluster. In a multi-Kafka setup, enabling such stream processing requires data replication across clusters.
Each Kafka cluster has a unique URL, a few authentication mechanisms, Kafka-wide authorization configurations, and other cluster-level settings. With a single cluster, all applications can make the same assumptions, use the same configurations, and send all events to the same location. These are all good technical reasons for sharing a single Kafka cluster whenever possible.
3. A single Kafka cluster is cheaper
I assume that you use Kafka because you have a huge volume of data, or you want to do low latency asynchronous interactions, or take advantage of both of these with added high availability—not because you have modest data needs and Kafka is a fashionable technology. Offering high-volume, low-latency Kafka processing in a production environment has a significant cost. Even a lightly used Kafka cluster deployed for production purposes requires three to six brokers and three to five ZooKeeper nodes. The components should be spread across multiple availability zones for redundancy.
Note: ZooKeeper will eventually be replaced, but its role will still have to be performed by the cluster.
You have to budget for base compute, networking, storage, and operating costs for every Kafka cluster. This cost applies whether you self-manage a Kafka cluster on-premises with something like Strimzi or consume Kafka as a service. There are attempts at "serverless" Kafka offerings that try to be more creative and hide the cost per cluster in other cost lines, but somebody still has to pay for resources.
Generally, running and operating multiple Kafka clusters costs more than a single larger cluster. There are exceptions to this rule, where you achieve local cost optimizations by running a cluster at the point where the data and processing happens or by avoiding replication of large volumes of non-critical data, and so on.
Benefits and challenges of multiple Kafka clusters
Although Kafka can scale beyond the needs of a single team, it is not designed for multi-tenancy. Sharing a single Kafka cluster across multiple teams and different use cases requires precise application and cluster configuration, a rigorous governance process, standard naming conventions, and best practices for preventing abuse of the shared resources. Using multiple Kafka clusters is an alternative approach to address these concerns. Let's explore a few of the reasons that you might choose to implement multiple Kafka clusters.
Operational concerns of decoupling
Kafka's sweet spot is real-time messaging and distributed data processing. Providing that at scale requires operational excellence. Here are a few manageability concerns that apply to operating Kafka.
-
Segregated workloads facilitate operational tasks
Not all Kafka clusters are equal. A batch processing Kafka cluster that can be populated from source again and again with derived data doesn't have to replicate data into multiple sites for higher availability. An ETL data pipeline can afford more downtime than a real-time messaging infrastructure for frontline applications. Segregating workloads by service availability and data criticality helps you pick the most suitable deployment architecture, optimize infrastructure costs, and direct the right level of operating attention to every workload.
-
Faster upgrades with separate Kafka clusters
The larger a cluster gets, the longer it can take to upgrade and expand the cluster due to rolling restarts, data replication, and rebalancing. In addition to the length of the change window, the time when the change is performed might also be important. A customer-facing application might have an upgrade window that differs from a customer service application. Using separate Kafka clusters allows faster upgrades and more control over the time and the sequence of rolling out a change.
-
Regulatory compliance issues
Regulations and certifications typically leave no room for compromise. You might have to host a Kafka cluster on a specific cloud provider or region. You might have to allow access only to support personnel from a specific country. All personally identifiable information (PII) data might have to be on a particular cluster with short retention, separate administrative access, and network segmentation. You might want to hold the data encryption keys for specific clusters. The larger your company is, the longer the requirements list gets.
The challenges of tenant isolation
The secret for happy application coexistence on a shared infrastructure relies on having good primitives for access, resource, and logical isolation. Unlike Kubernetes, Kafka has no concept like namespaces for enforcing quotas and access control or avoiding topic naming collisions. Let's explore some of the resulting challenges for isolating tenants.
-
Resource isolation
Although Kafka has mechanisms to control resource use, it doesn't prevent a bad tenant from monopolizing the cluster resources. Storage size can be controlled per topic through retention size, but cannot be limited for a group of topics corresponding to an application or tenant. Network utilization can be enforced through quotas, but it is applied at the client connection level. There is no means to prevent an application from creating an unlimited number of topics or partitions until the whole cluster gets to a halt.
All of that means you have to enforce these resource control mechanisms while operating at different granularity levels, and enforce additional conventions for the healthy coexistence of multiple teams on a single cluster. An alternative is to assign separate Kafka clusters to each functional area and use cluster-level resource isolation.
-
Security and access issues
Kafka's access control with the default authorization mechanism (ACLs) is more flexible than the quota mechanism and can apply to multiple resources at once through pattern matching. But you have to ensure good naming convention hygiene. The structure for topic name prefixes becomes part of your security policy.
ACLs control which users can perform certain actions on various resources, but a user with admin access to a Kafka instance has access to all the topics in that Kafka instance. With multiple clusters, each team can have admin rights only to their Kafka instance.
The alternative is to ask someone with admin rights to edit the ACLs and update topics rights. Nobody likes having to open a ticket to another team to get a project rolling.
-
Logical decoupling
A single cluster shared across multiple teams and applications with different needs can quickly get cluttered and difficult to navigate. You might have teams that need very few topics and others that generate hundreds of them. Some teams might even generate topics on the fly from existing data sources by turning microservices inside-out. You might need hundreds of granular ACLs for some applications that are less trusted, and coarse-grained ACLs for others. You might have a large number of producers and consumers. In the absence of namespaces, properties, and labels that can be used for logical segregation of resources, the only option left is to use naming conventions creatively.
Reasons for segregating Kafka clusters
So far we have looked at the manageability and multi-tenancy needs that apply to most shared platforms in common. Next, we will look at a few examples of Kafka cluster segregation for specific use cases. The goal of this section is to list the long tail of reasons for segregating Kafka clusters that varies for every organization and to demonstrate that there is no wrong reason for creating another Kafka cluster.
Data locales
Data has gravity, meaning that a useful dataset tends to attract related services and applications. The larger a dataset is, the harder it is to move around. Data can originate from a constrained or offline environment, preventing it from streaming into the cloud. Large volumes of data might reside in a specific region, making it economically unfeasible to replicate the data to other locations. Therefore, you might create separate Kafka clusters at regions, cloud providers, or even at the edge to benefit from data's gravitational characteristics.
Fine-tuning system parameters
Fine-tuning is the process of precisely adjusting the parameters of a system to fit certain objectives. In the Kafka world, the primary interactions that an application has with a cluster center on the concept of topics. And while every topic has separate and fine-tuning configurations, there are also cluster-wide settings that apply to all applications.
For instance, cluster-wide configurations such as redundancy factor (RF) and in-sync replicas (ISR) apply to all topics if not explicitly overridden per topic. In addition, some constraints apply to the whole cluster and all users, such as the authentication and authorization mechanisms, IP whitelists, the maximum message size, whether dynamic topic creation is allowed, and so on.
Therefore, you might create separate clusters for large messages, less-secure authentication mechanisms, and other oddities to localize and isolate the effect of such configurations from the rest of the tenants.
Domain ownership
Previous sections described examples of cluster segregation to address data and application concerns, but what about business domains? Aligning Kafka clusters by business domain can enforce ownership and give users more responsibilities. Domain-specific clusters can offer more freedom to the domain owners and reduce reliance on a central team. This division can also reduce cross-cluster data replication needs because most joins are likely to happen within the boundaries of a business domain.
Purpose-built clusters
Kafka clusters can be created and configured for a particular use case. Some clusters might be born while modernizing existing legacy applications and others created while implementing event-driven distributed transaction patterns. Some clusters might be created to handle unpredictable loads, whereas others might be optimized for stable and predictable processing.
For example, Wise Engineering uses separate Kafka clusters for stream processing with topic compaction enabled, separate clusters for service communication with short message retention, and a logging cluster for log aggregation. Netflix uses separate clusters for producers and consumers. The so-called fronting clusters are responsible for getting messages from all applications and buffering, while consumer clusters contain only a subset of the data needed for stream processing.
These decisions for classifying clusters are based on high-level criteria, but you might also have low-level criteria for separate clusters. For example, to benefit from page caching at the operating-system level, you might create a separate cluster for consumers that re-read topics from the beginning each time. The separate cluster would prevent any disruption of the page caches for real-time consumers that read data from the current head of each topic. You might also create a separate cluster for the odd use case of a single topic that uses the whole cluster. The reasons can be endless.
Summary
The argument for "one thing to rule them all" has been used for pretty much any technology: mainframes, databases, application servers, ESBs, Kubernetes, cloud providers, and so on. But generally, the principle falls apart. At some point, decentralizing and scaling with multiple instances offer more benefits than continuing with one centralized instance. Then a new threshold is reached, and the technology cycle starts to centralize again, which sparks the next phase of innovation. Kafka is following this historical pattern.
This article presented common motivations for growing a monolithic Kafka cluster and reasons for splitting it out. But not all points apply to all organizations in every circumstance. Every organization has different business goals and execution strategies, team structure, application architecture, and data processing needs. Every organization is at a different stage of its journey to the hybrid cloud, a cloud-based architecture, edge computing, data mesh—you name it.
You might run on-premises Kafka clusters for good reason and give more weight to the operational concerns you have to deal with. Software-as-a-Service (SaaS) offerings such as Red Hat OpenShift Streams for Apache Kafka can provision a Kafka cluster with a single click and remove the concerns for maintainability, workload criticality, and compliance. With such services, you might pay more attention to governance, logical isolation, and controlling data locality.
If you have a reasonably sized organization, you will have hybrid and multi-cloud Kafka deployments and a new set of concerns about optimizing and reusing Kafka skills, patterns, and best practices across the organization. These concerns are topics for another article, however.
I hope this article provided guidance for structuring your decision-making process for segregating Kafka clusters. Follow me at @bibryam to join my journey of learning Apache Kafka.
Last updated: October 18, 2023