Our team recently created an application called Beer Horoscope, which we used to illustrate the extensive possibilities for modern software development and deployment with Red Hat OpenShift and community-built free software tools. The application's front end collects user preferences and makes beer recommendations. The back end performs machine learning on users and products (beers) to make appropriate recommendations. Figure 1 shows how we combined an event-driven architecture with machine learning models that are applicable to numerous real-world scenarios.
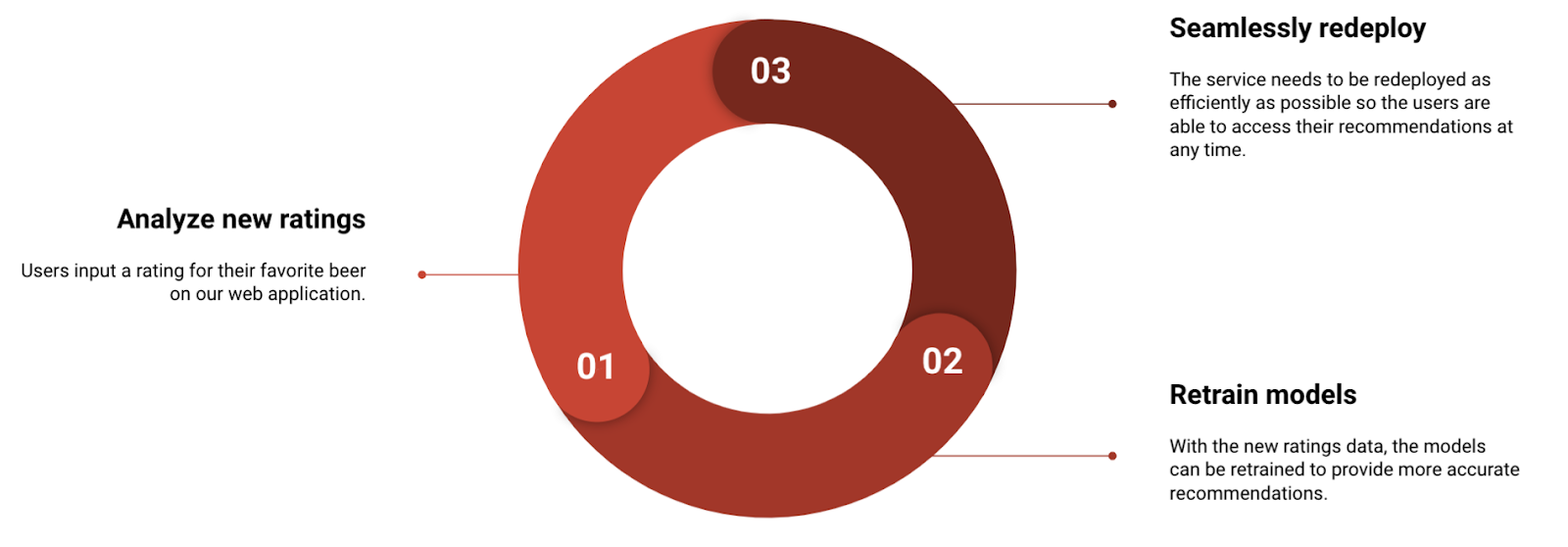
This article summarizes our talk at the 2021 Red Hat Summit break-out session titled Modern Fortune Teller: Your Beer Horoscope with AI/ML. We'll discuss how we used GitOps on OpenShift, along with ArgoCD, to continuously deploy our application as we were developing it. We'll also explain how we used Open Data Hub as a one-stop machine learning environment to create and test our algorithms on OpenShift. See our GitHub repository for application source code and additional documentation.
What is GitOps?
GitOps is a way of implementing continuous deployment (CD) for cloud-native applications. GitOps extends CD from development to cloud deployment using tools developers are already familiar with, including Git.
The core idea of GitOps is to create a Git repository that contains declarative descriptions of the infrastructure. These are updated so they always indicate the images currently desired in the production environment, as shown in Figure 2.

GitOps's advantages in practice include:
- Faster and more frequent application deployments
- Easier and faster error recovery
- Simplified credential management
- Self-documenting deployments
- Shared knowledge throughout the team
Red Hat's GitOps Operator
Red Hat OpenShift is a Kubernetes platform meeting the declarative principles that allow administrators to configure and manage deployments using GitOps. Working within a Kubernetes-based infrastructure and applications, you can apply consistency across clusters and development life cycles.
Red Hat collaborates with open source projects such as Argo CD and Tekton Pipeline to implement a framework for GitOps.
For this application, we leveraged Red Hat's GitOps Operator for application deployment. This operator allows for continuous updates and delivery via ArgoCD and Git, thus implementing GitOps.
ArgoCD pulls the deployment instructions from our Git repository and installs Red Hat AMQ Streams. AMQ Streams is based on the Apache Kafka streaming tool. The AMQ Streams Operator allows developers to use Kafka and various components, such as Kafka Connectors, to support complex event processing. For this project, we use AMQ Streams in high availability mode.
The Open Data Hub Operator
We used Open Data Hub as a one-stop environment for machine learning and artificial intelligence (AI/ML) services and tools on OpenShift. Open Data Hub provides tools at every stage of the AI/ML workflow, and for multiple user personas including data scientists, DevOps engineers, and software engineers. The Open Data Hub Operator (Figure 3) lets developers use a best-of-breed machine learning toolset and focus on building the application.
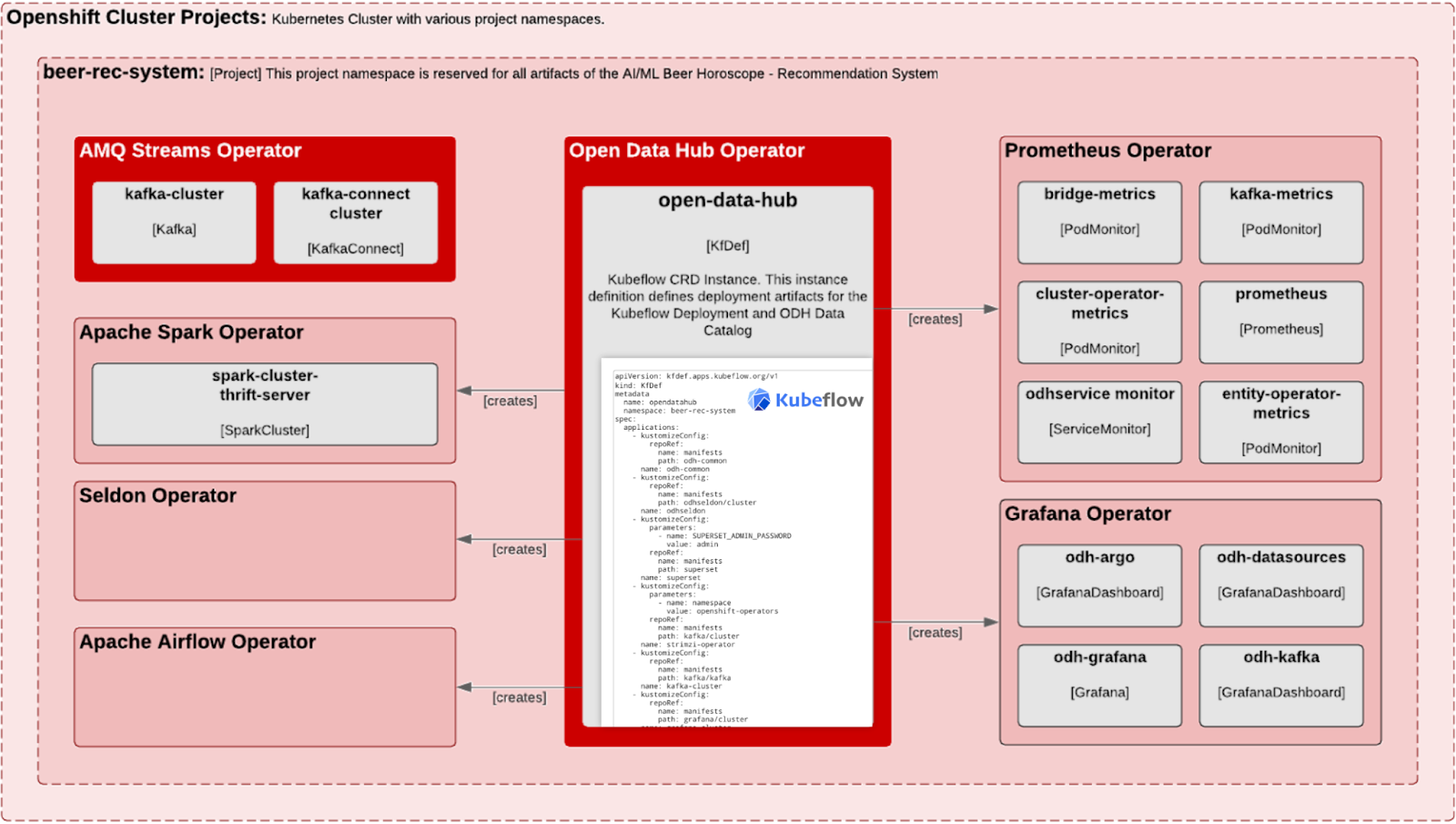
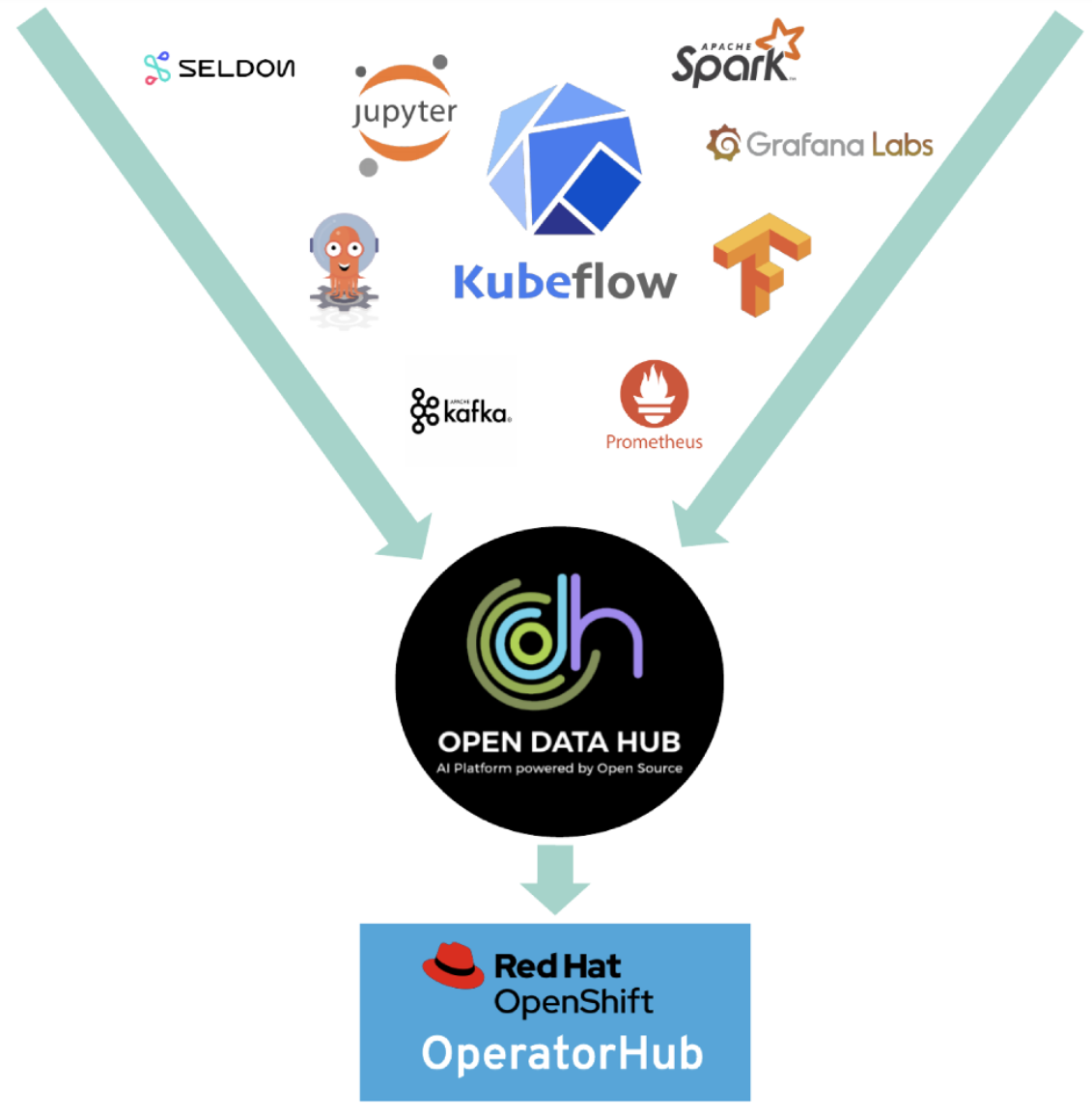
Figure 4 shows the platform components, such as Jupyter Notebook, Apache Spark, and others, that Open Data Hub makes available for data scientists via Kubeflow.

Developing the recommendation system
To develop the algorithms for the Beer Horoscope project, we needed a recommendation system. To choose the correct algorithms for the system, we first had to determine the relationships involved when users get a beer recommendation. Three main types of relationships occur in this scenario:
- User-product: What kind of beer does this user like to drink?
- Product-product: What beers are similar to each other?
- User-user: Which users have similar taste in beer?
Two of these relationships can be established by two very popular algorithms used in recommendation systems:
- Collaborative filtering: Used to establish user-user relationships. If one user rates Beer A very highly, and another user also rates Beer A very highly, we can assume these users have similar taste in beer. We can then start recommending to each user the beers that are highly rated by the other user.
- Content-based filtering: Used to establish product-product relationships. If a user likes Beer A, it's safe to recommend beers similar to Beer A to the user.
We developed models using these two algorithms on JupyterHub through Open Data Hub. We had access there to all of the components that made up the development environment, including environment variables, databases, configurations settings, and so on.
Once we created our models, our application deployment life cycle became very similar to the software development life cycle.
Next, we'll take a look at how cloud-native development utilizes containers, DevOps, continuous delivery, and microservices to automate these formerly time-consuming steps.
How we built the Beer Horoscope
Up to this point, we've covered how we automated the infrastructure that our application runs on, from the perspective of a DevOps engineer, by leveraging GitOps. We then discussed how we trained and created the data models from the perspective of a data engineer and data scientist.
Here, we turn to the viewpoint of an application developer. We'll go over how an application interacts with trained data models and how to leverage the OpenShift infrastructure and platform to make these interfaces possible.
The AMQ Streams Operator, GitOps Operator, and Open Data Hub Operator, discussed earlier, were all available from the OperatorHub, shown in Figure 5.
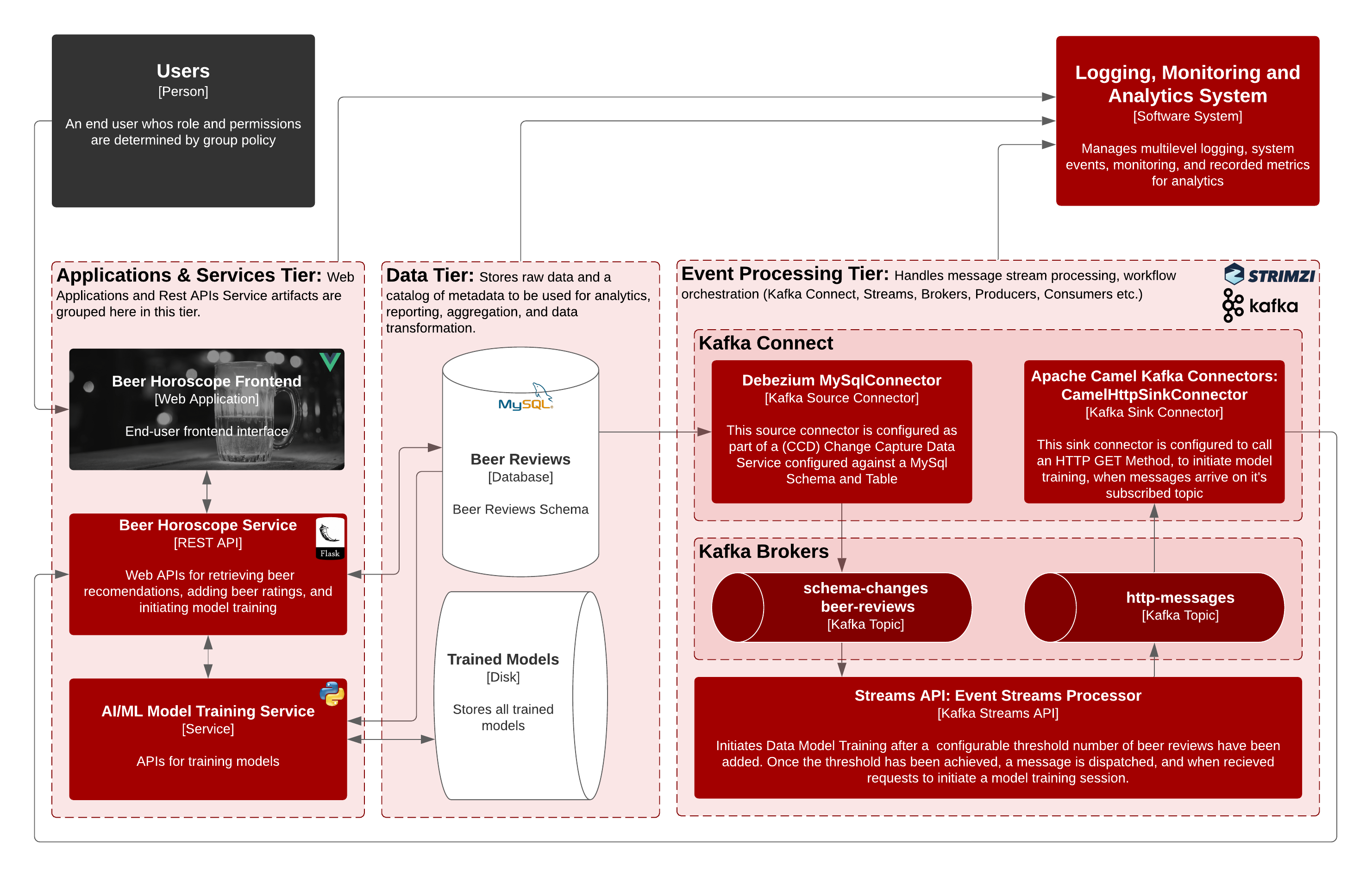
Application architecture
Figure 6 lists the systems involved in this architecture and roughly indicates how they relate to each other. The application components are:
- Users: These are evaluated for their preferences and are served by the project.
- Applications and services tier: This collection typically houses artifacts such as web applications, REST services, and internal services. Much of the APIs and underlying business logic were extrapolated from Jupyter notebooks developed by data engineers. The front-end component was written using Vue.js. The API services are built on Python and Flask.
- Data tier: This tier stores both raw and structured data, as well as trained data models. This data is used by the consuming tiers. The Beer Horoscope application uses both the MySQL relational database and file storage to store data.
- Event-processing tier: In this tier, we orchestrate how we process any new data introduced into our ecosystem. We create data streams to handle complex event processing scenarios and business rules. For this tier, we used Kafka Connectors and Streams for complex event processing.
- Logging, monitoring, and analytics: This tier provides functions for logging and monitoring, so that we can analyze what's going on in real time and keep historical records. This tier used the Grafana and Prometheus Operators.
- Container registry: To facilitate the versioning, storage, and retrieval of container image artifacts in our OpenShift cluster, we stored all application image artifacts within a container registry. The Beer Horoscope uses Quay.io to host these artifacts.
Conclusion
In this article, we explored the tools and methods we used to operationalize our machine learning models, and how we then brought algorithms written on a Jupyter notebook into production through a user-friendly web application.
Before starting a full-stack project, you need an environment that supports continuous delivery. We used Red Hat's GitOps Operator on OpenShift, along with ArgoCD, to continuously deploy our application as we were developing it.
Then, we used OpenShift's Open Data Hub Operator as a one-stop machine learning environment to create and test our algorithms. The MySQL databases and file system store our large datasets and trained data models, respectively.
Finally, we created an application that interacts with our models. Our full-stack application includes the front-end user interface, API services written in Flask that talk to our machine-learning model training services written in Python, the data tier, and the event-processing tier that uses Kakfa Streams through AMQ Streams.
By closely examining and optimizing the software development cycle, we were able to collaborate and deploy into production an intelligent application—one that's telling you to go grab a cold beer right now!
Last updated: September 19, 2023