In this article, I will demonstrate how to speed up your compilation times by distributing compilation load using a distcc server container. Specifically, I'll show how to set up and use containers running a distcc server to distribute the compilation load over a heterogeneous cluster of nodes (development laptop, old desktop PC, and a Mac). To improve the speed of recompilation, I will use ccache.
What to expect
Today, you can find a lot articles about Kubernetes or OpenShift. This is not such an article. I started using containers, especially Docker, back in 2013, and in the beginning, I mainly used them to isolate things and have reproducible builds. The same is true here; we'll build a container, push it to DockerHub for distribution, and download it on other machines on the fly when running docker run ... so don’t expect crazy things to happen here.
In fact, even if you don’t have any prior knowledge of Docker, you should still be able to follow along. Getting and installing the Docker Engine in the Community Version (on Linux) or the Docker Desktop (on macOS and Windows) is completely enough.
In terms of C++, I don’t expect anything code-wise except that your project uses CMake and compiles with GCC or Clang.
Introduction
I recently started a new job at Red Hat where I get the chance to work on the LLDB project. The first thing I noticed, after not having worked with C++ for quite a while, was the slowness of compilation. I worked with Go for a couple of years, and compilation performance isn’t an issue there at all. It simply vanishes from the picture.
Slow compilation
When I say that compilation was slow for LLDB, I mean that compiling the lldb target (git tag: llvmorg-7.1.0) in release mode takes close to two hours. Release builds are already the fastest to build and given that I need to build a total of 7 or more variants of LLDB (clang/gcc, debug/release, asan/no asan, assert/no assert, …) this makes compilation time take up a whole working day.
My normal developer system consists of a three-year-old Lenovo Thinkpad T460s laptop, on which I run Fedora 29 and the following tools:
- gcc (GCC) 8.2.1 20180801 (Red Hat 8.2.1–2)
- clang version 7.0.1 (Fedora 7.0.1–6.fc29)
- ccache version 3.4.2
- distcc 3.2rc1 x86_64-redhat-linux-gnu
When I compile LLDB on my development laptop using make and four compile jobs ( -j 4 ), the time command reports this:
real 72m24,439s user 224m32,731s sys 12m2,094s
This means that I have to wait approximately two hours for a one-time compilation.
Speeding up
When I compile LLDB on my cluster (laptop, desktop, iMac) using ninja and 10 compile jobs (as determined by distcc -j ) the time command reports this:
real 22m29,130s user 49m16,726s sys 4m27,407s
That means compiling with ninja and my distcc cluster is
- 3.22 times faster in real time.
- 4.56 times faster in total number of CPU seconds that the process spent in user mode.
- 2.7 times faster in number of CPU-seconds that the process spent in kernel mode.
I hope this motivates you to continue reading.

Tip #1: Distributing compilation load
I have experimented before with ways to speed up compilation using distcc, which lets you distribute your compile jobs onto other machines. It requires you to have the exact same compilers installed on the worker machines (the servers) as on the developer machine (the client).
So I installed a spare machine with Fedora 29 running on it to make it part of my compilation cluster. I installed all the right compilers in the right versions to match the ones I have running on my local machine.
But then I realized that this would be a nightmare to maintain. I didn’t want to trade slowness for complexity. Not to mention all the things I would have to do when I upgrade my developer system to Fedora 30. Do I really have to upgrade all my worker machines in the cluster?
Also, I had an iMac sitting on another desk that doesn’t do much when we’re not doing video or photo editing or music recording with it. Could it be used for compilation? After all, macOS doesn’t have the exact same compilers that I have on my developer machine. This is what I meant by heterogeneous cluster of nodes in the introduction.
To spare you the details of how to set up a distcc server, or how to bring CMake to use it, we’ll jump into Tip #2 right away.

Tip #2: Using a distcc server container
I’ve mentioned before that I have an iMac, which does nothing when I work on my laptop. Wouldn’t it be nice if I could run a container (e.g., with Docker) on it that serves distcc with all the necessary tooling already set up?
To better explain what I'm trying to achieve, here’s a diagram of my compiler cluster architecture.
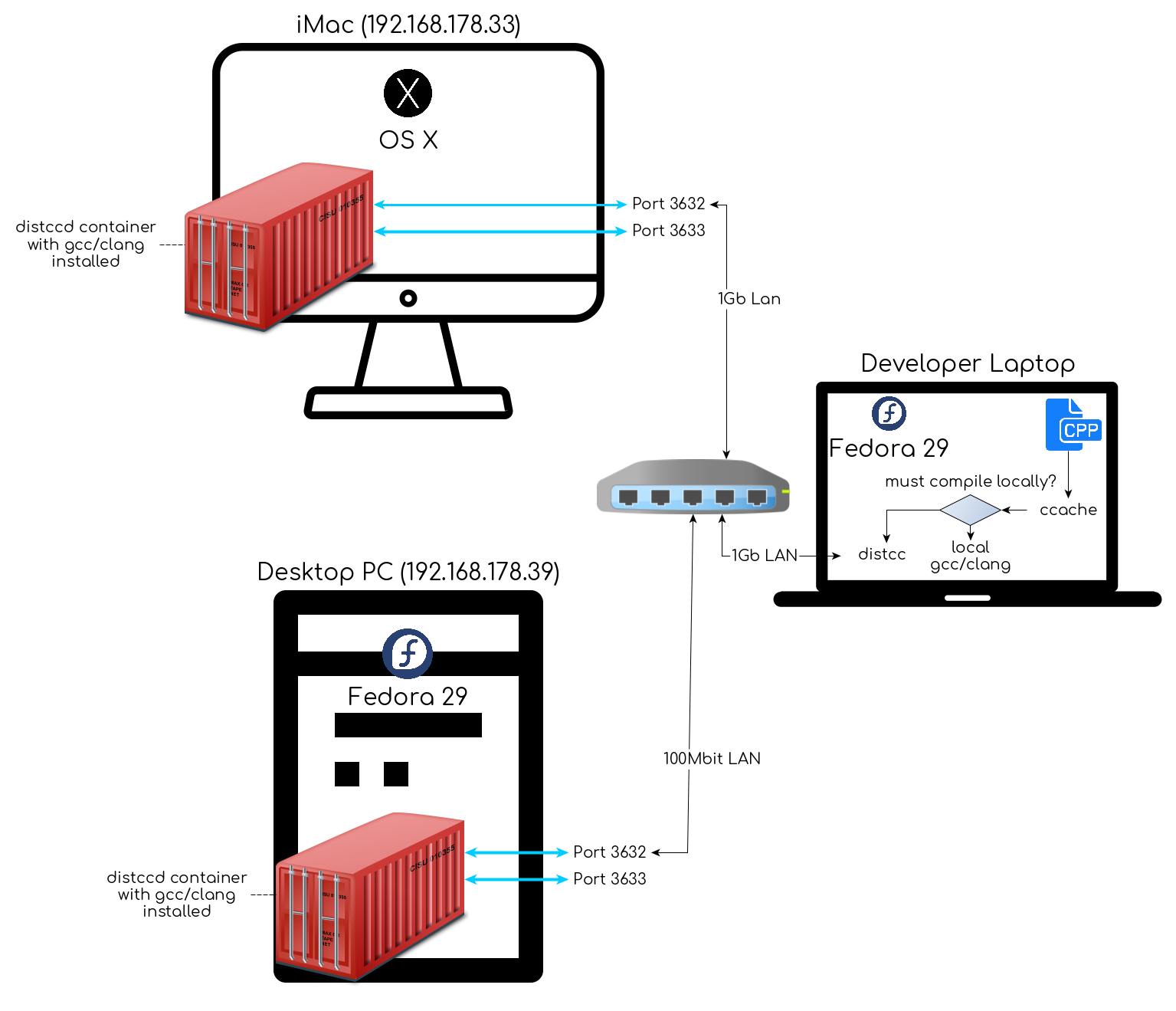
Diagram of my compiler cluster architecture.">
It turns out, you can (almost) completely abstract away from the underlying operating system as long as you can run a docker run command in a terminal.
If you’re not familiar with Docker, don’t worry; it is easy. Think of this rough analogy:
- A Docker image is like a program in Linux.
- A container is like a process of a program in Linux, a.k.a. an instance of the program.
Obviously, the image must exist before the container can exist. To create an image, you write what’s called a Dockerfile that describes the base image (think operating system here, even though it is not correct) you want to begin with. In my case, I want to be as close to my developer machine as possible, so I use the fedora:29 image.
FROM fedora:29
Then, you install tools that your image ships with (installing tools):
RUN dnf install -y \ clang \ distcc \ distcc-server \ doxygen \ gcc \ graphviz \ htop \ libasan \ libasan-static \ libedit-devel \ libxml2-devel \ make \ ncurses-devel \ net-tools \ python-devel \ swig \ && yum clean all
NOTE: All of the above packages are not necessarily needed. I literally installed in my Docker image whatever I had installed on my developer laptop. This, of course, is not needed because distcc only sees pre-processed compilation units. That means it does not need to have all the include files available itself, but instead they will be pushed to the distcc server from my developer laptop.
In a Docker container, there can only be one top-level process that is the heart of the container. In our case, that is distcc. We configure it using a so-called entrypoint and pass along all the flags that we want to keep independent of the machine that runs the container:
ENTRYPOINT [\ "distccd", \ "--daemon", \ "--no-detach", \ "--user", "distcc", \ "--port", "3632", \ "--stats", \ "--stats-port", "3633", \ "--log-stderr", \ "--listen", "0.0.0.0"\ ]
If you don’t understand any of the flags above, you can look them up with man distccd.
Then, there are the flags for which we provide defaults but that you also can change:
# By default the distcc server will accept clients from everywhere. # Feel free to run the docker image with different values for the # following params. CMD [\ "--allow", "0.0.0.0/0", \ "--nice", "5", \ "--jobs", "5" \ ]
That is essentially it. You can find the latest version of my Dockerfile here.
How to build the Docker image out of the Dockerfile
Please note, that I’ve configured a repository on DockerHub to automatically build the latest version of my Dockerfile image. Instead of building the image yourself, you could just issue the following command to get the latest version:
$ docker pull konradkleine/distcc:fedora29
If you plan to experiment and tinker with it, you can build the image like so:
$ git clone git@github.com:kwk/distcc-docker-images.git $ cd distcc-docker-images $ docker build -t konradkleine/distcc:fedora29 -f Dockerfile.fedora29 .
How to run the Docker image
To make a Linux, MacOS or Windows-based computer part of your cluster, make sure you have installed and properly configured Docker on that machine. Then head over to a terminal and run the following command:
$ docker run \ -p 3632:3632 \ -p 3633:3633 \ -d \ konradkleine/distcc:fedora29
This will download (a.k.a. pull) my latest distcc Docker image (if not already pulled) and run it in daemon mode ( -d ). It will expose distcc’s main port ( 3632 ) and distcc’s HTTP statistics port ( 3633 ) under the same numbers on the host machine.
How to test the Docker image
The beauty of Docker to me is that you can always use your developer machine to try out stuff. For example, to run the distcc container on your localhost, you can run the same command from before but give the container a name this time so you can refer to it in subsequent Docker commands:
$ docker run \ -p 3632:3632 \ -p 3633:3633 \ -d \ --name localdistcc \ konradkleine/distcc:fedora29
Then I suggest running htopinside the newly created container to see what’s going on:
$ docker exec -it localdistcc htop
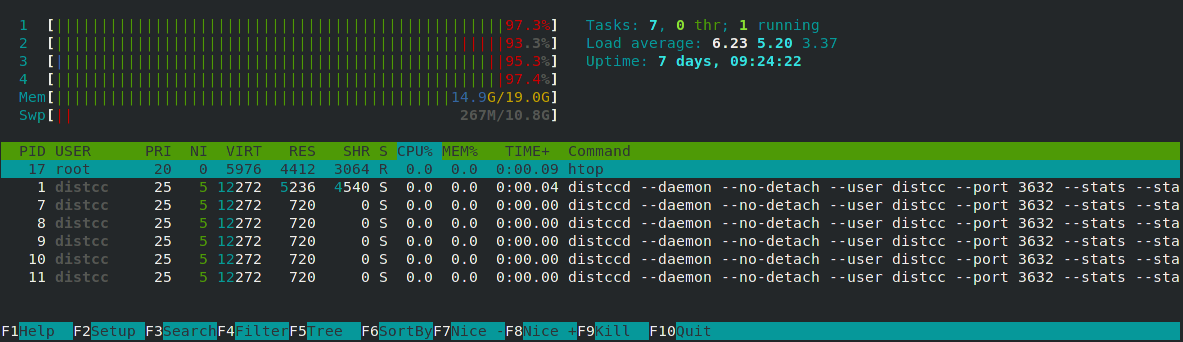
Running htop inside the localdistcc container shows that your container only runs distccd.">
Let’s compile some code and distribute it to our localdistcc node. Here I’m going to compile LLDB with adjustments:
$ git clone https://github.com/llvm/llvm-project.git ~/dev/llvm-project
# Get the IP address of the localdistcc container
$ export LOCAL_DISTCC_IP=$(docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' localdistcc)
$ export DISTCC_HOSTS="$LOCAL_DISTCC_IP/7 localhost"
$ mkdir -p ~/dev/llvm-builds/release-gcc-distcc
$ cd ~/dev/llvm-builds/release-gcc-distcc
$ cmake ~/dev/llvm-project/llvm \ -G Ninja \ -DCMAKE_BUILD_TYPE=Release \ -DLLVM_USE_LINKER=gold \ -DLLVM_ENABLE_PROJECTS="lldb;clang;lld" \ -DCMAKE_C_COMPILER=/usr/bin/gcc \ -DCMAKE_CXX_COMPILER=/usr/bin/g++ \ -DCMAKE_EXPORT_COMPILE_COMMANDS=1 \ -DCMAKE_C_COMPILER_LAUNCHER="ccache;distcc" \ -DCMAKE_CXX_COMPILER_LAUNCHER="ccache;distcc"
$ ninja lldb -j $(distcc -j)
I’ve marked the sections in bold that are worth looking at. Things to notice are:
Get the IP address of the container running the distcc container using docker inspect .
When exporting DISTCC_HOSTS, I suggest that you take a look at the /7 because that tells distcc to distribute seven jobs to this machine. My machine has eight cores, and I don’t want it to run out of power. By default, only four jobs are sent (see man distcc):
/LIMIT A decimal limit can be added to any host specification to restrict the number of jobs that this client will send to the machine. The limit defaults to four per host (two for local‐host), but may be further restricted by the server. You should only need to increase this for servers with more than two processors.
Generate a build system for ninja using -G Ninja.
We use fully qualified paths to the compilers we want to use by specifying CMAKE_C_COMPILER=/usr/bin/gcc and CMAKE_CXX_COMPILER=/usr/bin/g++ . See the next section about masquerading to understand why we do this.
Use CMake’s CMAKE_<LANG>_COMPILER_LAUNCHER in order to call ccache distcc /usr/bin/gcc instead of just /usr/bin/gcc. This is a nice mechanism to avoid masquerading gcc or g++ .
Masquerading is a technique where you create file named gcc and make it available on your PATH to intercept calls to gcc. Oddly enough, Fedora 29 does this when you install ccache . That package creates /usr/lib64/ccache/gcc that points to /usr/bin/ccache . This effectively masquerades your local gcc binary with ccache . As a matter of fact, ccache will masquerade a whole armada of compilers including but not limited to gcc, g++, clang, clang++ (see rpm -ql ccache for the complete list). This is why we use fully qualified paths to the compiler /usr/bin/gcc .
We let discc figure out how many build jobs to run in parallel by looking at the available hosts: -j $(distcc -j) .
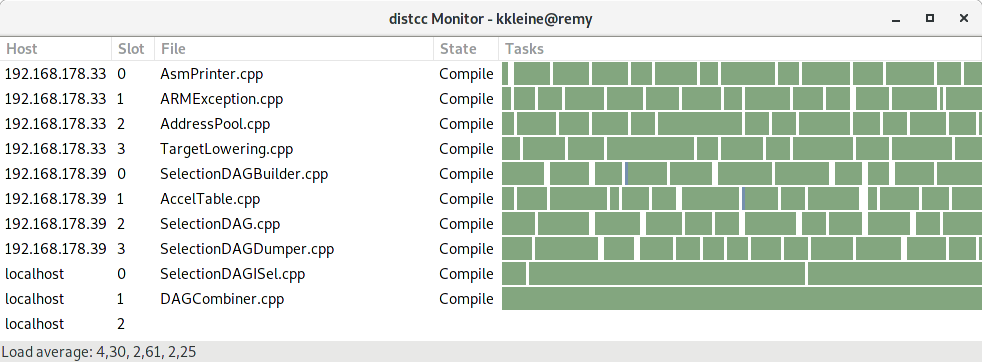
While ninja builds, take a look at the distccmon-gnome output (see the "Troubleshooting" section). It should show something like this:
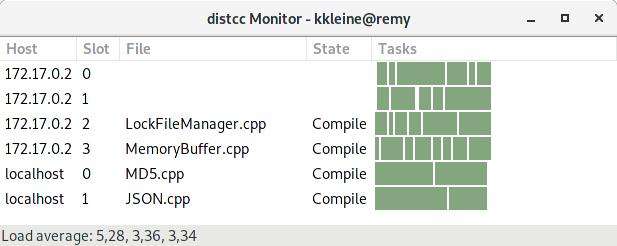
distccmon-gnome output when compiling locally using a distcc container.">
NOTE: distcc -j assumes that all your hosts listed in DISTCC_HOSTS are distinct machines. But the container runs on your localhost and thereby consumes resources from it. This could impact the performance of your developer machine. If things get slow, just abort the compilation; this is just for testing anyway.
Troubleshooting
How can I visualize the distribution of the compilation?
On Fedora 29, I use distccmon-gnome or distccmon-text (see screenshots below). To install them, run sudo dnf distcc-gnome distcc .
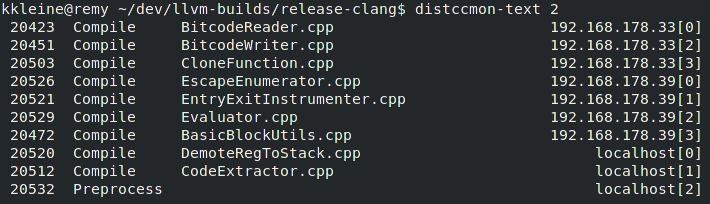
How do I test that all my hosts are serving distcc?
Test that all your nodes are serving distcc with netcat (nc). In the following command, replace 192.168.178.33 192.168.178.39 with the IPs of your hosts. NOTE: I’m often on a VPN, so I use fixed IP addresses to mitigate issues with resolving host names.
$ for i in 192.168.178.33 192.168.178.39; do nc -zv $i 3632; done
Ncat: Version 7.70 ( https://nmap.org/ncat ) Ncat: Connected to 192.168.178.33:3632. Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds. Ncat: Version 7.70 ( https://nmap.org/ncat ) Ncat: Connected to 192.168.178.39:3632. Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.
Alternatively, you can use the much slower nmap:
$ nmap -A 192.168.178.33/32 -p 3632 -Pn Starting Nmap 7.70 ( https://nmap.org ) at 2019-04-23 14:05 CEST Nmap scan report for MyServer (192.168.178.33) Host is up (0.00069s latency).
PORT STATE SERVICE VERSION 3632/tcp open distccd distccd v1 ((GNU) 8.3.1 20190223 (Red Hat 8.3.1-2))
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 6.68 seconds
For better security, how can I specify who is allowed to use my distcc container?
Please note, that the CMD section in the Dockerfile defines a default of --allow 0.0.0.0/0 to allow connections from everywhere. I suggest that you adjust this parameter when running the distcc container:
$ docker run \ -p 3632:3632 \ -p 3633:3633 \ -d \ konradkleine/distcc:fedora29 \ --allow <YOUR_HOST>
Do I have to use ccache or can I just use distcc?
You can absolutely only use one or the other, just adjust the CMAKE_C_COMPILER_LAUNCHER and CMAKE_CXX_COMPILER_LAUNCHER variables when configuring/generating your project with CMake.
# To use ccache and distcc -DCMAKE_C_COMPILER_LAUNCHER="ccache;distcc" \ -DCMAKE_CXX_COMPILER_LAUNCHER="ccache;distcc"
# To use ccache alone (please note, that no distribution will # happen if you choose this option.) -DCMAKE_C_COMPILER_LAUNCHER="ccache" \ -DCMAKE_CXX_COMPILER_LAUNCHER="ccache"
# To use distcc alone -DCMAKE_C_COMPILER_LAUNCHER="distcc" \ -DCMAKE_CXX_COMPILER_LAUNCHER="distcc"
How do I send more than 4 jobs to a machine?
In your DISTCC_HOSTS environment variable, you need to adjust the limit, which defaults to 4. It is specified with a /<LIMIT>after the hostname:
export DISTCC_HOSTS="fasthost/8 slowhost/2 localhost"
How can I see if ccache works for me?
I suggest that you take a look at the output of ccache --show-stats and inspect the cache hit rate. For example, the following hit rate is at 15.61%, which is better than nothing, I’d say.
$ ccache --show-stats cache directory /home/kkleine/.ccache primary config /home/kkleine/.ccache/ccache.conf secondary config (readonly) /etc/ccache.conf stats zero time Wed Apr 17 18:44:31 2019 cache hit (direct) 1787 cache hit (preprocessed) 21 cache miss 9774 cache hit rate 15.61 % called for link 584 called for preprocessing 35 compile failed 12 preprocessor error 116 unsupported code directive 4 no input file 19 cleanups performed 0 files in cache 25218 cache size 1.2 GB max cache size 5.0 GB
I hope you liked reading this article and got some value out of it. Check out the accompanying video, too.
