OpenShift Virtualization, a feature of Red Hat OpenShift, lets you run virtual machines (VMs) alongside containers on the same platform, simplifying management. It allows using VMs in containerized environments by running VMs the same way as any other pod, so that organizations with significant investment in virtualization or who desire the greater isolation provided by VMs with legacy workloads can use them in an orchestrated containerized environment.
While VMs offer important advantages in this regard, they do consume additional memory. There are several reasons why, but one of them is that while VMs can expand their memory use up to the limit of the defined size, but until now they cannot shrink their memory footprint. In this post, I will present a technology, Free Page Reporting (FPR), to mitigate this. FPR allows guests to report (release) unused memory back to the hypervisor, thereby increasing available host memory. FPR is a mature technology, having been present in the Linux kernel since 5.7, and is available in OpenShift Virtualization as a technology preview as of release 4.14.
In this article, I report performance and memory utilization results of using FPR versus not using FPR versus using containers without VMs.
Project goals
I set out to measure and analyze various performance and memory consumption implications of using FPR. In particular, I studied the following:
- Measure the memory savings available with FPR, including both maximum and average memory use.
- Measure the CPU overhead of FPR, particularly as seen from the host.
- Measure how long it takes to allocate and free guest memory, as seen from the host.
- Measure memory allocation time as seen from the guest:
- Without FPR, memory freed by a guest process stays in the guest VM, so subsequent allocations do not require a round trip to the host to acquire memory
- With FPR (assuming it functions correctly), subsequent allocations of previously-freed memory may require reallocation on both the host and guest, potentially resulting in longer allocation times.
- Determine impact on guest I/O due to interaction with guest buffer cache.
- Determine impact on host I/O due to any differences in memory use.
Using FPR
Enabling FPR for a cluster is very straightforward. There are two ways to do it from the command line:
Edit the hyperconverged object:
oc edit hyperconverged -n openshift-cnv kubevirt-hyperconverged Change spec.virtualMachineOptions.disableFreePageReporting from true to false: kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: [...] virtualMachineOptions: disableFreePageReporting: false [...]Patch the hyperconverged object:
oc patch --type=merge -n openshift-cnv hyperconverged/kubevirt-hyperconverged -p '{"spec":{"virtualMachineOptions":{"disableFreePageReporting":false}}}'
This will take effect for future VMs, but existing ones will not be affected. Note that FPR will always be disabled if a VM requests dedicated CPUs, real time behavior, or huge pages. It will also not be used if the guest OS does not support it (for Linux, kernel 5.7 or newer is required). Lastly, it is possible for a guest to opt out by adding the following annotation to individual VM definitions:
kubevirt.io/free-page-reporting-disabled: trueSummary of results
If you are someone who wants the summary right away, I will briefly discuss the high level results here before diving into the process of collecting and analyzing the data.
- Overall, FPR is very effective at saving host memory with very little overhead. It was effective in my tests at releasing memory back to the hypervisor, resulting in substantially less average and maximum RAM use with long-running VMs running dynamic memory-intensive workloads. FPR is a mature technology within the Linux kernel, and functions with OpenShift Virtualization transparently. The reduction in memory consumption can allow for better host-side I/O cache behavior in mixed environments and, depending upon your workload, less risk of out-of-memory process terminations.
- CPU overhead associated with reporting memory to the host was negligible. On a 40 core/80 thread node with very dynamic memory use by many VMs, the extra CPU load was on the order of 0.1 core. In general, I observed no performance degradation with one minor and specific exception I note below.
- There was no reproducible effect on guest I/O performance, and in particular, no evidence that the guest I/O cache was any less effective with FPR than without.
- There is one minor downside that may affect workloads that make heavy use of dynamic memory while also requiring fast response time: memory reallocation after the VM has reported memory back to the host takes as long as initial memory allocation within the VM. Without FPR, memory reallocation is faster as the memory is already assigned to the VM. The penalty should be very small for the large majority of workloads. If you do have one of the workloads where this does matter, you can disable FPR for that VM by means of one of the procedures described above (the VM needs to be restarted).
Running the tests
My test platform was a single worker node of a cluster running OpenShift and OpenShift Virtualization 4.14. The hardware consisted of 2x Intel Xeon Gold 6130 (Skylake) sockets with 192 GiB of RAM.
For VMs, I used quay.io/rkrawitz/clusterbuster-vm:latest for the containerdisk. This image is based on CentOS Stream9, containing additional tooling.
I used only synthetic workloads for this work. I wanted to run reproducible tests that do not depend on network, I/O, and other unpredictable factors.
I used two principal tests:
- Clusterbuster, a tool that I have developed to allow running workloads on OpenShift clusters. Clusterbuster is designed to run one or many instances of various workloads, in either pods or VMs, synchronizing workload steps if desired. It also orchestrates collection of metrics data. For these tests, I use two workloads: memory and fio.
- A simple ad hoc test, written in C, to measure the time required to allocate and deallocate memory as seen from the client. malloc(3) is not actually sufficient, as it only reserves the memory; it is necessary to write a non-zero byte to each page to actually force the kernel to reserve the memory.
Notes on each test:
- The Clusterbuster memory test can be run in a way that pseudo-randomly allocates and frees chunks of memory. It can run multiple independent processes within each pod or VM. As I wanted reproducible behavior, I arranged to use a separate seed for each process, based on the pod/VM name, container name, and process index (not process ID, which can vary from run to run). For VMs, which do not have containers, I use the same name as the first container in a pod would have. Examination of traces clearly shows the reproducible behavior. I used differing average load cycles (i. e., the amount of time that the memory was held after allocation versus the amount of time that the memory was released), and randomly started each process either with or without memory allocation based on the duty cycle, so all processes would not start with memory allocated and thereby immediately use a maximum amount of memory.
- For I/O on the guest, I used fio with Clusterbuster and arranged for the total file size to be about 15% less than the RAM allocated to the VM. I pre-created the work file in the VM and arranged for fio to not purge the buffer cache pre-run. VMs without FPR can keep all of that in RAM, but the question was whether VMs using FPR would treat the buffer cache as unused memory that it could report to the hypervisor.
- For I/O on the host, I again used fio and measured the total memory used with clusterbuster memory tests using a certain profile with and without FPR. I then used a file size that, when subtracted from the total RAM, would fit between the two memory sizes, with the intention of seeing whether the reduced memory load with FPR would result in more memory being available for caching. Again, I pre-created the work file.
- For the ad hoc test, I allocated and freed 60 GiB RAM, and measured the time between the malloc request and when all pages were touched. I kept the memory in use for 1 minute, then released it and waited another minute for FPR to return the RAM. I ran this test 11 times consecutively, measuring the time for the first run and computing the mean and standard deviation for the successive 10 runs.
I used Prometheus to collect data on CPU utilization, host memory use, and pod/VM memory with a 1 second sampling interval. This allowed me to collect fine-grained time series data to see detailed behavior of the host memory system. While the VM level data is still sampled at the default 30 second interval, the aggregate host data was sufficient to analyze the behavior of FPR.
Results
Memory savings
The first test case simply allocates 60 GiB RAM, holds onto it for 60 seconds, releases it, and repeats, as shown in Figure 1.
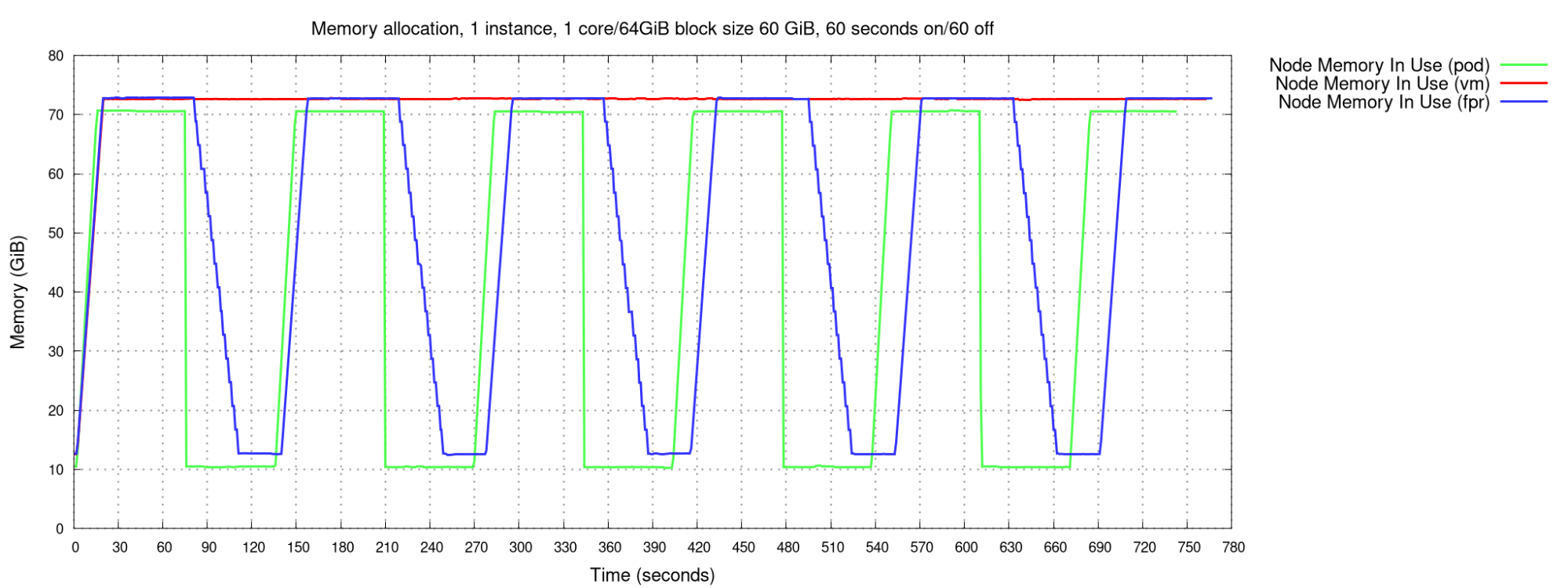
We observe the following:
- Without FPR (red line), the system memory in use does not decline when the memory inside the VM is freed, while with FPR (blue) it does, and closely tracks the memory used by a pod.
- Memory allocation takes slightly longer in a VM with FPR than in a pod (the slope of the upward green line is slightly steeper than the blue line).
- Releasing memory takes a significant amount of time with a VM with FPR (the slope of the downward blue line is significant), while with a pod, the memory is returned instantly.
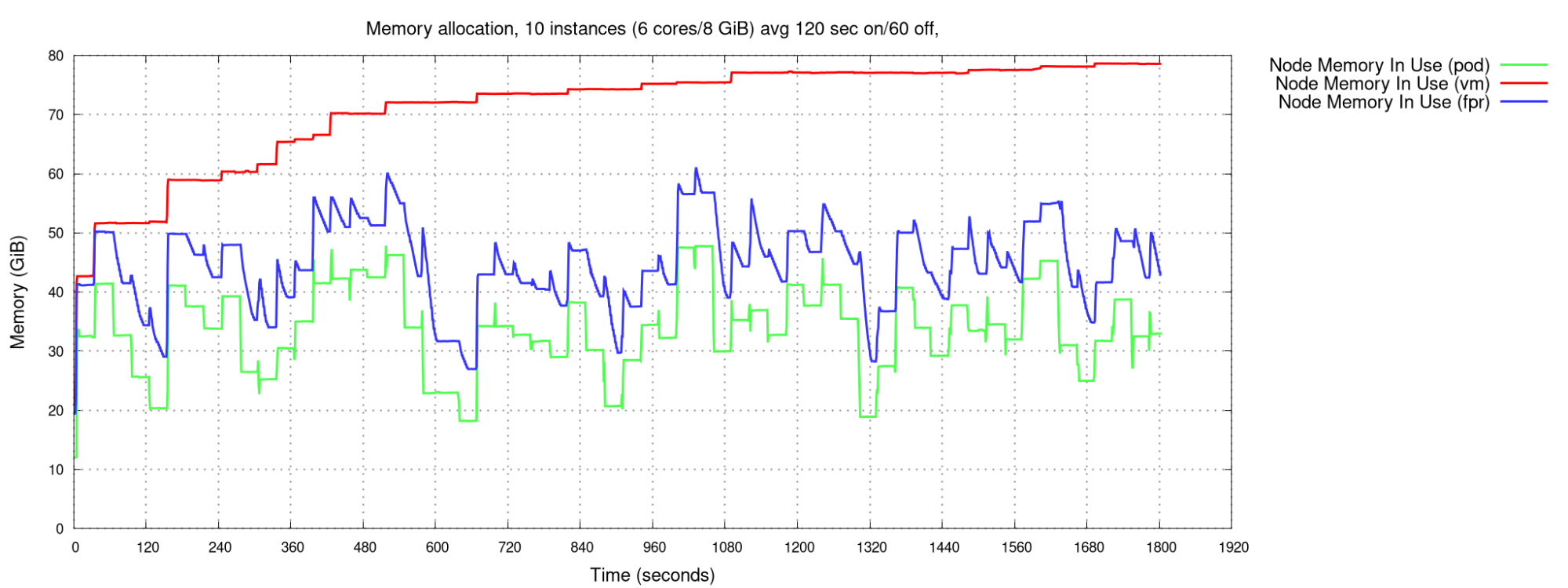
With a randomized pattern, averaging 120 seconds "on" and 60 "off", with 10 VMs, we see that the memory usage of pods and VMs with FPR track very closely, with about 8 GiB overhead for the VMs (0.8 GiB per VM). The non-FPR VMs result in monotonically but discontinuously increasing memory use, as VMs gradually exceed their previous high watermark. See Figure 2.
CPU overhead
Looking at CPU consumption, with a very fast rate of allocation and deallocation with 10 active VMs, we see in Figure 3 that VMs with FPR use very marginally more CPU than without.
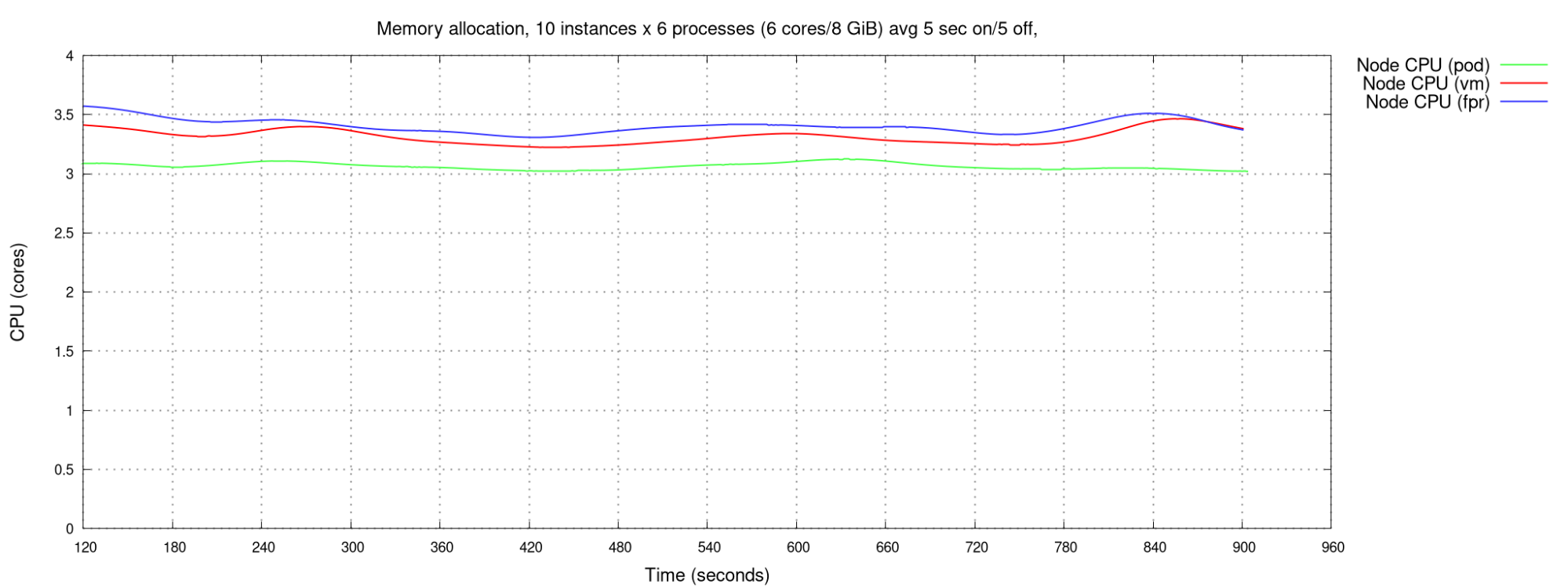
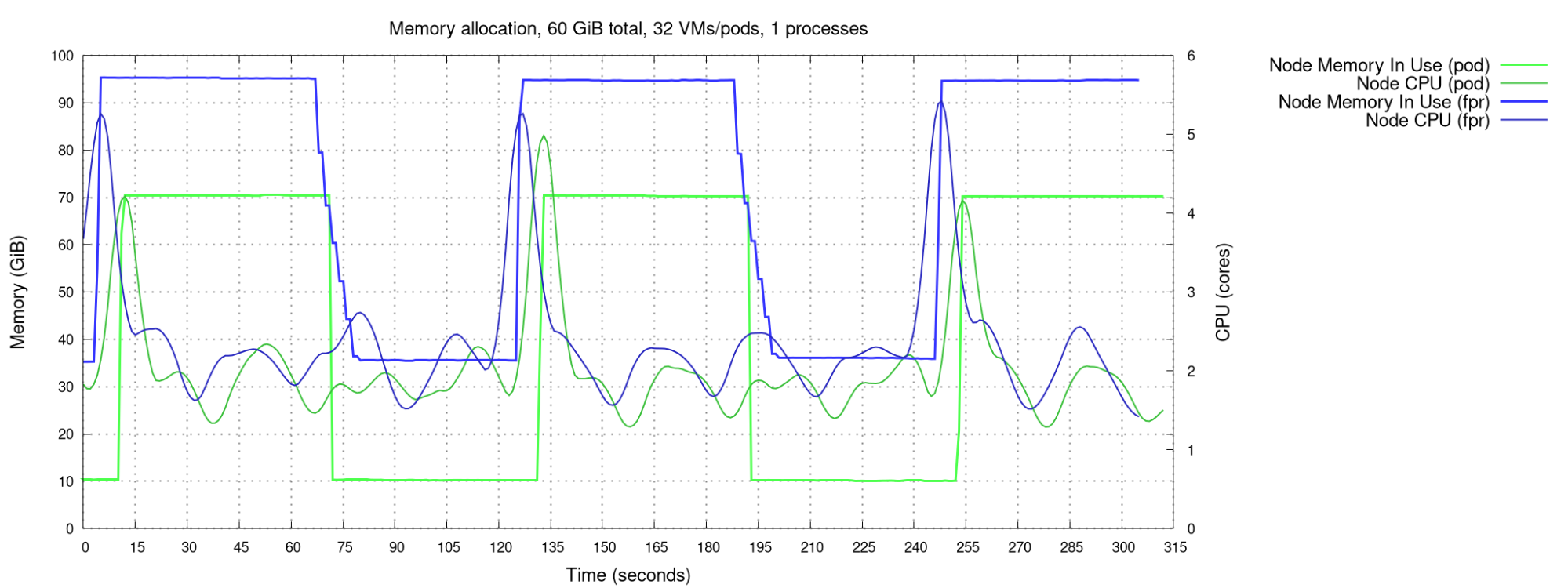
I next studied CPU utilization with 32 synchronized pods or FPR VMs. There is a strong peak during memory allocation—it actually peaked over 30 cores (as would be expected, given 32 pods concurrently attempting to allocate memory, which is CPU-intensive), but this graph in Figure 4 is smoothed for readability—but no overhead for deallocation.
Memory re-allocation time
For this test, I measured the time to allocate 60 GiB RAM with malloc and write one non-zero byte to each page, freed the memory, and waited for 60 seconds. I ran this in a loop, with the first iteration on a freshly-booted VM followed by 10 more iterations. I measured the allocation time and user/system CPU times for each iteration, and averaged the final 10 iterations. The standard deviation of the final 10 iterations was in all cases negligible. All times in the chart below are in seconds.
| Instance type | Alloc (first) | Alloc (rest) | SysCPU (first) | SysCPU (rest) | User CPU (first) | User CPU (rest) |
|---|---|---|---|---|---|---|
| Pod | 11.434 | 11.430 | 11.005 | 11.005 | 11.434 | 11.430 |
| VM w/o FPR | 14.916 | 11.433 | 14.846 | 11.375 | 0.139 | 0.143 |
| VM w/ FPR | 15.300 | 15.223 | 15.190 | 15.190 | 0.132 | 0.114 |
We can see the effect of FPR returning memory to the host, with the successive iterations having to make an additional round trip to the hypervisor to allocate memory, where without FPR the memory is retained in the guest, allowing successive iterations to be fast. The penalty of 30% or so may be significant in some cases, so if you have an application sporadically using a large amount of dynamically-allocated memory that requires minimal access time to freshly allocated memory, you may wish to consider not using FPR or disabling it for the VMs in question.
Guest I/O performance
These tests measure I/O performance and memory consumption with FPR versus non-FPR VMs, using both ext4 and xfs. I am including the ratio here rather than absolute numbers. I ran the test several times, and there was some variation between runs with I/O rate.
The cells that are in bold underline in Figure 5 reflect performance that is substantially faster than the underlying storage medium, i.e., was cached. I found no cases where the data was cached without FPR but not with FPR, indicating that guests were not reporting cache memory to the hypervisor. Of course, it is possible that different VM kernels may choose to do otherwise.
The first test is single stream, using a 28 GiB file on a 32 GiB VM. For memory, "in use" refers to overall memory on the node, while "WS" refers to the working set, defined as the size of the VM as reported by OpenShift. In this case, I was only interested in the ratio between FPR and non-FPR for both memory consumption and I/O throughput.
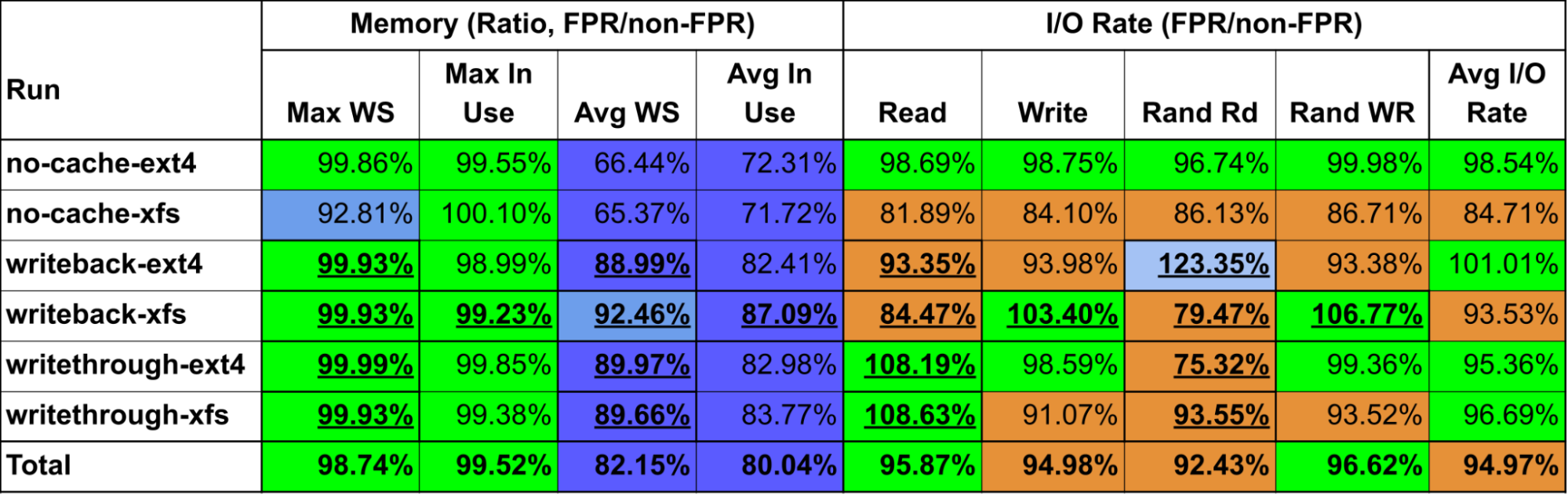
The specific I/O throughput differences did not reproduce on a rerun, and there was no clear overall pattern; on the whole, the I/O performance was very similar, perhaps very slightly slower with FPR. The maximum memory consumption was likewise very similar. The average memory consumption, however, was significantly lower; the rerun yielded very similar numbers. With multi-stream I/O (using 7 workers, each using a 4 GiB file), however, the memory savings was much smaller (4-5%). Again in this case, though, the I/O performance, while variable, showed a similar pattern where guest cache was not impaired.
Host I/O performance
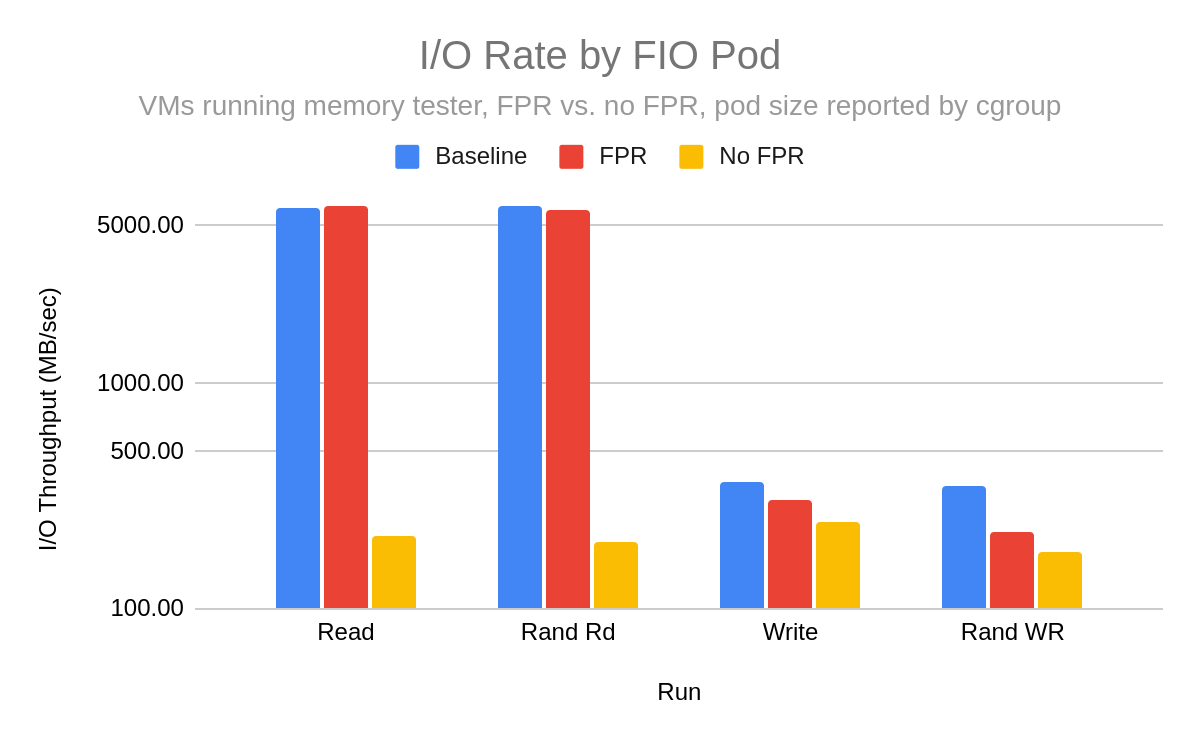
My final test was to measure host I/O performance in a pod with memory workers running concurrently, and a baseline run with no memory workers. I used a single fio pod with a 90 GiB file running against a SATA drive, with 17 memory worker VMs each running 8 processes using an average of 576 MiB each (total average working memory per VM 4.5 GiB) that were started 30 minutes before the fio job and left running throughout. The VMs were sized at 10 GiB but in practice never came close to that. Without FPR, the pseudo-random fluctuations resulted in monotonically increasing memory use, reaching about 115 GiB total prior to the fio job being started. With FPR, the memory fluctuated between about 60 and 75 GiB. Therefore, with FPR not in use, we could expect a memory demand including cache of 215 GiB or so, exceeding the 192 GiB RAM of the node, while without FPR we would expect a memory requirement peaking around 165 GiB, well under the node memory
The I/O throughput (Figure 6) clearly shows that caching was effective for read operations in both the baseline and FPR scenarios. With write operations, it was not fully effective, but I still saw some benefit compared to non-use of FPR. I plotted the data logarithmically because of the wide spread between cached and non-cached I/O performance.
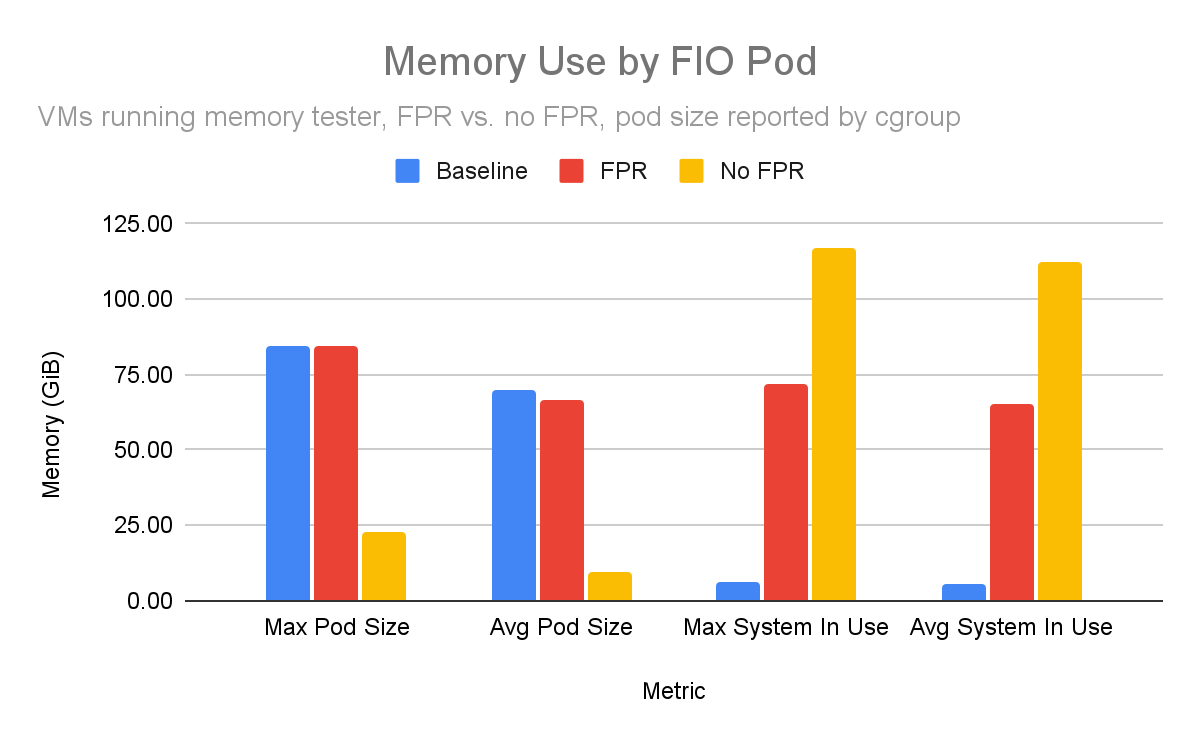
For memory use, we can clearly see in Figure 7 that the pod had more memory available to work with. Total system memory in use, defined as (total_memory - free - cache - buffers - reclaimable), was obviously very little in the baseline case, but with FPR in use for the memory workers we saw substantial savings.
Acknowledgements
As usual, this project could not have been completed without the assistance of numerous others, including:
- Fabian Deutsch of the OpenShift Virtualization team for collaboration of the experiment design.
- Federico Fossemo of the OpenShift Virtualization team for assistance throughout the project.
- Simon Pasquier of the OpenShift Monitoring team for assistance with collecting high frequency node metrics.
Conclusion
We clearly see that FPR is effective at reducing host memory consumption in a VM-based environment, if the workload inside the VM makes significant variable use of memory. This of course requires workloads that can release the memory back to the OS. This may allow greater density of pods or VMs without running out of memory and thereby being killed, but obviously there are no guarantees. There is very little CPU overhead directly incurred with the use of FPR.
However, there is still some overhead incurred by the dynamic memory allocation within the VM, as the memory has to be reacquired from the hypervisor. At least on my system, this overhead was about 30%, which was about 3 seconds for allocating 60 GiB of RAM. If you want to use FPR, and have very dynamic workloads, you need to consider (and preferably measure) whether this overhead is significant. The guest does not instantly report all freed memory back to the hypervisor, which may limit the savings for extremely dynamic memory patterns but also reduce thrashing.
So, should you try using FPR? If you are memory-strapped and have problems with pods or VMs being OOM killed, or run pod workloads with large I/O working sets alongside VMs making significant use of dynamic memory, you may find FPR to be beneficial. On the other hand, if you have VM-based workloads making heavy use of dynamic memory that need fast response time, you may find the additional overhead of reacquiring memory from the hypervisor to be detrimental.
I hope this analysis helps you decide whether or not you should experiment with Free Page Reporting for your VM-based workloads. Good luck!
Last updated: September 13, 2024