For the second entry in our series introducing Red Hat OpenShift Virtualization to VMware vSphere administrators, we are going to discuss storage. In our previous article, we compared OpenShift Virtualization network configurations to how networks are often laid out in most general deployments of VMware vSphere. With this article, we will focus on how a containerized virtualization solution presents an entirely new storage paradigm when compared to what traditional virtualization administrators are used to.
The traditional view of hypervisor storage
In traditional hypervisor storage paradigms, the anchorpoint is the shared datastore. A datastore is a single large volume presented to our hypervisor as either a block storage device (LUN) through a SAN protocol (iSCSI, FCP, FC-NVMe), or a remote file share through a NAS protocol (NFS/CIFS). This datastore is filled with image files that make up the storage devices for our virtual machines (VMs), as well as other support and configuration files for each individual machine.
Benefits of the shared datastore
There are a number of benefits to having the storage administrator create this single large volume that allows for a large number of VMs deployed in one virtual datacenter to share the datastore capacity.
For starters, having a large number of similar machines with similar storage resource needs stored in the same datastore allows administrators to apply storage quality of service (QoS) guarantees to groups of machines easily. This can result in a large amount of deduplication savings, savings for creating virtual guest snapshots, or a more rapid response when attempting to clone VM instances.
A second benefit is that once a datastore has been created by the storage system and mounted by the hypervisor, no further intervention is needed. This is easier for the admin to manage, as the virtual guest image files (VMDKs) are placed on the datastore when the guest is created, and as long as the datastore is mounted to each hypervisor in the vSphere deployment, those virtual guests can run on any node in the vCenter environment without the storage files needing to be moved. It is often a “set it and forget it” type of resource in the virtualization environment.
Disadvantages of the shared datastore
Along with the benefits of this paradigm, there are a number of disadvantages as well.
If the storage system or network experienced an issue, it could affect the availability of the datastore as a whole, which would have a negative effect on every VM hosted there. This could cause an entire virtual datacenter to go offline unexpectedly.
In addition to the entire datastore going offline, if one VM on the datastore experiences extremely high input/output (I/O), it can adversely affect other guests on the same datastore. In virtualization administration circles, this is often known as the “noisy neighbor” effect.
Other storage options for VMware vSphere
While the shared datastore is the most common method by which storage is consumed in VMware vSphere environments, there are additional popular methods with more specific use cases that are used to connect storage to virtual guests.
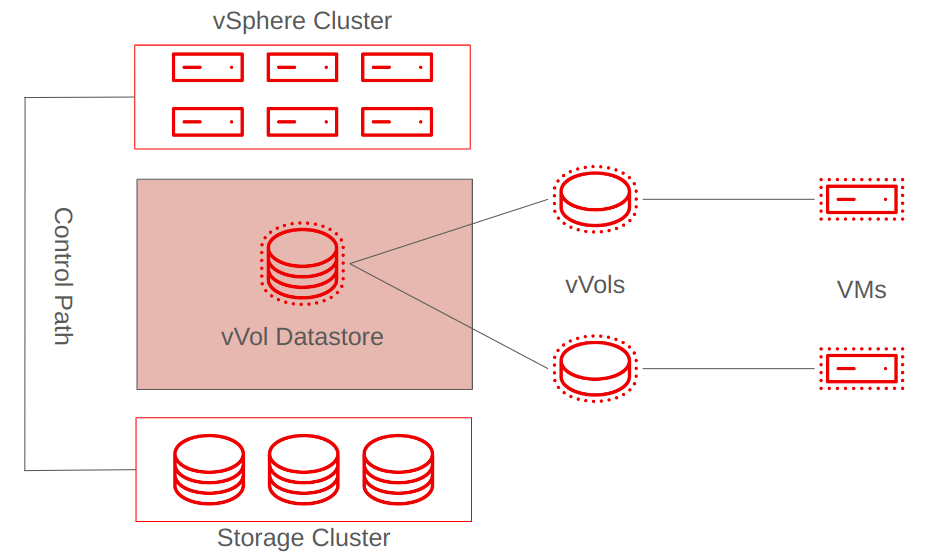
One of these methods involves vVols, where VMs use the virtual Small Computer System Interface (SCSI) stack. Raw Device Mappings (RDM) are another method, where VMs attach to volumes on a storage array with direct access.
vVols and RDMs act differently than VMDKs stored in a larger storage domain in that they each represent direct mappings to data volumes on the storage system backing the virtualization environment. That is, each VM has their own block storage device that is directly connected to the guest by a SAN protocol (see Figure 1).
By having direct access to this storage device at the operating system (OS) level, the VM can conduct more I/O-intensive tasks, and it can be ideal for supporting systems in need of enhanced performance, such as those that host Oracle databases or Microsoft Exchange servers.
The primary reason I bring up vVols and RDMs as different options for VM storage is because storage in OpenShift Virtualization works similarly, by direct mapping storage to virtual guests.
How storage works with OpenShift Virtualization
The mapping of a storage volume to an OpenShift Virtualization pod is handled in a 1:1 manner, very much like vVols and RDMs direct map storage to a virtual guest in VMware vSphere.
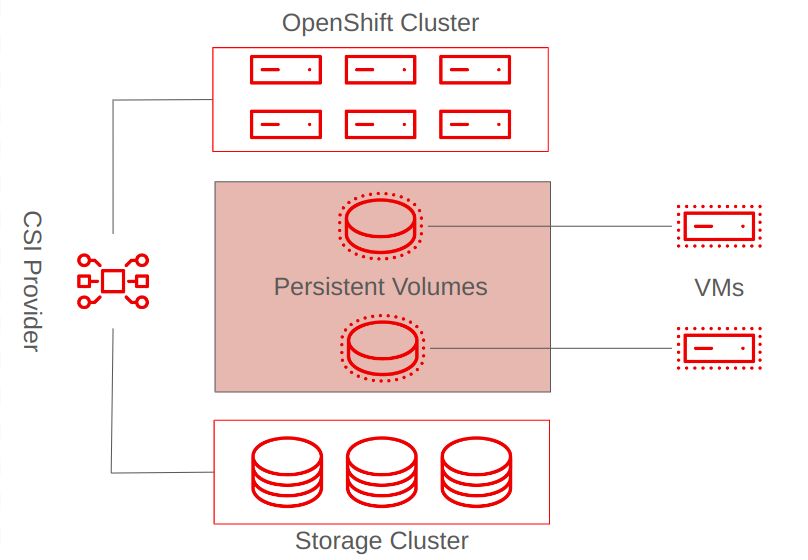
When a container needs access to storage for the workload that it is supporting, including VMs, it creates a Persistent Volume Claim (PVC). This PVC interacts with the installed container storage interface (CSI) driver to provision and attach a new Persistent Volume (PV) to the node and the pod that is hosting the virtual guest (see Figure 2).
One difference between traditional storage models and OpenShift Virtualization is that the process of attaching a volume through CSI is a dynamic process that easily scales on demand. This is similar to using vVols for the same process, but set apart from the behavior of attaching RDMs, which often requires rescanning the SCSI bus on the guest to make the new drive addressable.
Outside of this minor difference, the advanced storage system features that you expect to get from using vVols and RDMs directly with vSphere VMs are also available to each guest in OpenShift Virtualization, as those features are supported in the CSI driver provided by each storage vendor.
For example, while each PV is usually created as its own volume on a storage system, systems that are able to offer space-saving features like deduplication or global copy-on-write snapshots of data can still be taken advantage of. This helps to realize some of the benefits that were available in the classic datastore method with a large number of virtual disks sharing a single large storage volume on the array.
Benefits of OpenShift Virtualization’s storage paradigm
Having PVs available that can make use of storage array features through CSI drivers provided by the storage vendor can also provide virtual guests in OpenShift Virtualization with advanced features like rapid cloning. Rapid cloning benefits certain use cases like virtual desktop deployments, and are often a minimum expectation of administrators that deploy enterprise hypervisors.
Another feature I would like to highlight is live migration of virtual machines, popularly known as vMotion in the VMware ecosystem. This feature is also available in OpenShift Virtualization, and just like VMware vSphere, it only requires a shared datastore or storage system that is accessible from all of the nodes in the hypervisor cluster. This is so that both the source and destination nodes can connect to the storage device backing the virtual guest, should there be a need for migration.
OpenShift Virtualization achieves this well known feature by leveraging the ability for any node in the cluster to be able to mount and interact with PVs when requested. For those unfamiliar with the configuration of persistent volumes, there are a number of access modes that can be defined based on the type of storage being used to back the volume. Examples such as ReadWriteOnce (RWO) or ReadWriteMany(RWX) can be specified in the StorageClass used for each application, and the CSI driver then creates the volume on the storage system in that access mode.
For OpenShift Virtualization we look to have persistent volume types that can support the RWX access mode. This is a functional requirement for the live migration of virtual guests between worker nodes in an OpenShift cluster, because it allows multiple nodes read and write access to the persistent volume simultaneously. This is necessary so that both the worker node originally hosting the VM and the node it is reassigned to can interact with the supporting storage volume.
OpenShift Virtualization: A new storage paradigm with familiarity
In closing, I’d like to emphasize that even though the storage paradigm available in OpenShift Virtualization is very different from what users of VMware vSphere may be used to, there are still parts of it that can seem very familiar. It also allows OpenShift Virtualization to perform many of the common virtual guest actions that are expected in enterprise hypervisor environments. By understanding these common use cases, and how the storage provided for OpenShift Virtualization is consumed to support them, an admin can feel a sense of relative comfort when exposed to the new environment for the first time.
To learn more about how VMs interact with storage systems in OpenShift Virtualization, consider attending one of our upcoming live events, such as the Red Hat Summit Connect events, or a session of the OpenShift Virtualization Road Show, where we feature a product overview and hands-on lab dedicated to OpenShift Virtualization that can help familiarize you with this modern container and virtualization platform.
Finally, check out the Getting started with OpenShift Virtualization learning path to get some hands-on experience with OpenShift Virtualization at your own pace.
Next up: OpenShift Virtualization for VMware vSphere admins: Disaster and site recovery
Last updated: June 5, 2025