Page
Launch JupyterHub

Launch JupyterHub
Red Hat OpenShift AI makes extensive use of JupyterHub, a project that enables users to quickly and easily launch Jupyter notebooks to conduct data and feature engineering, experimentation, model development, training, and testing.
Because JupyterHub has already been enabled in your OpenShift AI dashboard, you can directly launch JupyterHub by clicking the Launch hyperlink (Figure 9).
Selecting Launch takes you to the JupyterHub home dashboard, where you will select options for your notebook server.
Select options for your notebook server
When you first get access to JupyterHub, you see a configuration screen (Figure 10) that gives you the opportunity to select a notebook image and configure the deployment size and environment variables for your data science project.
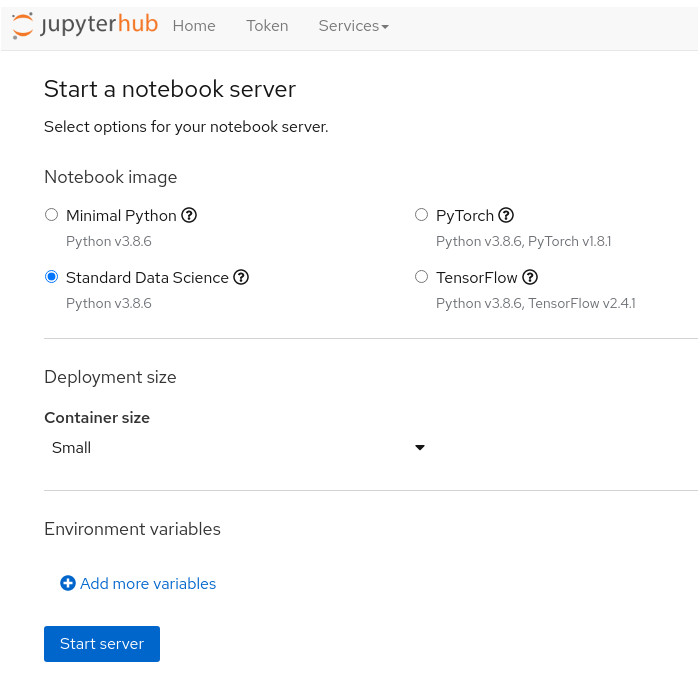
You can customize the following options:
- Notebook image
- Deployment size
- Environment variables
The following subsections cover each of these topics.
Notebook image
There are a number of predefined images that you can choose from. When you choose a predefined image, your JupyterLab instance has the associated libraries and packages that you need to do your work.
Available notebook images include:
- Minimal Python
- PyTorch
- Standard Data Science
- Tensorflow
These images are coded in Python. You can determine which libraries and packages the images contain by clicking the ? (question mark) icon listed by each image name.
Info alert: If there is a library or package that you need, and it is not listed, you can always install the library or package using pip install in your Jupyter notebook.
For this learning path, choose the Standard Data Science notebook image. For all other learning paths, choose the notebook image listed in the prerequisites section.
Deployment size
You can choose different Deployment sizes (resource settings) based on the type of data analysis and machine learning code you're working on. Each deployment size is pre-configured with specific CPU, and Memory resources.
For this learning path, select the Small deployment size. For all other learning paths, choose the deployment size listed in the prerequisites section.
Environment variables
The environment variables section is useful for injecting dynamic information that you don't want to save in your notebook. For example, if you are reading or writing to S3-compatible storage, you can inject your credentials here.
This learning path does not use any environmental variables. For all other learning paths, enter the environment variables listed in the prerequisites section.
If you are satisfied with your notebook server selections, click the Start Server button to start the notebook server. Once the new notebook server starts, you will be in JupyterLab and ready to experiment with your new notebook image.
