Ollama recently announced tool support and like many popular libraries for using AI and large language models (LLMs) Ollama provides a JavaScript API along with its Python API.
If you've been following along with our journey into Node.js and Large Language Models (How to get started with large language models and Node.js, Diving Deeper with large language models and Node.js) you know that function calling/tool use is one of the things we took a look at earlier.
While our initial experience with function calling/tool use helped us understand how it worked, the results were mixed. This was not a surprise as it was early in the function call/tool use evolution and still a fast moving area for large language models. With the introduction of support into Ollama, we wanted to take another look to see what progress has been made.
In this blog post we'll expand our experiments with tool use and Node.js, continuing to use functions that return a person's favorite color, and adding one to get a person's favorite hockey team. For the experiments we don't really care what the functions being called are, just that we see them called when appropriate and that the information they return is used correctly.
In case you want to look ahead at any point while reading, all of the code and results are in the repository mhdawson/ai-tool-experimentation in the ollama subdirectory.
Interaction with the Large Language Model
While LLMs are often used in a chat with a person we want to be able to run the same sequence a nubmer of times with different models so typing responses manually would not be practical. Instead we have a fixed set of messages that the "person" chatting with the model will make regardless of the response from the LLM. Since responses from an LLM may be different each time it does mean that sometimes the next message from the person does not fully fit with the last resposne from the LLM. This turned out not to be a big problem as the sequence we use often works out well, and our evaluation of success takes into consideration that some of the "person" messages don't fit the flow.
The sequences of messages that we used were as follows (from : favorite-color.mjs) :
const questions = ['What is my favorite color?',
'My city is Ottawa',
'My country is Canada',
'I moved to Montreal. What is my favorite color now?',
'My city is Montreal and my country is Canada',
'My city is Ottawa and my country is Canada, what is my favorite color?',
'What is my favorite hockey team ?',
'My city is Montreal and my country is Canada',
];We send these messages to the LLM as follows:
// maintains chat history
const messages = [{type: 'system', content:
'only answer questions about a favorite color by using the response from the favoriteColorTool ' +
'when asked for a favorite color if you have not called the favoriteColorTool, call it ' +
'Never guess a favorite color ' +
'Do not be chatty ' +
'Give short answers when possible'
}];
console.log(`Iteration ${j} ------------------------------------------------------------`);
for (let i = 0; i< questions.length; i++) {
console.log('QUESTION: ' + questions[i]);
messages.push({ role: 'user', content: questions[i] });
const response = await ollama.chat({ model: model, messages: messages, tools: tools});
console.log(' RESPONSE:' + (await handleResponse(messages, response)).message.content);
} We'll explain the handleResponse function along with the tools passed into the chat call in the next section when we introduce the fuctions/tools that are made available.
In the ideal case the LLM would respond as follows:
'What is my favorite color?' -> I need your city and country
'My city is Ottawa' -> I need your Country
'My country is Canada' -> Your favorite color is black
'I moved to Montreal. What is my favorite color now?' -> Your favorite color is red
'My city is Montreal and my country is Canada' -> Your favorite color is red
'My city is Ottawa and my country is Canada, what is my favorite color?' -> your favorite color is black
'What is my favorite hockey team ?' -> your favorite hockey team is the Ottawa Senators
'My city is Montreal and my country is Canada' -> Your favorite hockey team is the Montreal CanadiansThe Functions/Tools
In the Ollama API tools are passed in as a JSON structure similar to other APIs, with the JSON describing the type of tool, the name, description and for functions the function parameters. In our example we defined two tools as follows:
/////////////////////////////
// TOOL info for the LLM
const tools = [{
type: 'function',
function: {
name: 'favoriteColorTool',
description: 'returns the favorite color for person given their City and Country',
parameters: {
type: 'object',
properties: {
city: {
type: 'string',
description: 'the city for the person',
},
country: {
type: 'string',
description: 'the country for the person',
},
},
required: ['city', 'country'],
},
},
},
{
type: 'function',
function: {
name: 'favoriteHockeyTeamTool',
description: 'returns the favorite hockey team for person given their City and Country',
parameters: {
type: 'object',
properties: {
city: {
type: 'string',
description: 'the city for the person',
},
country: {
type: 'string',
description: 'the country for the person',
},
},
required: ['city', 'country'],
},
},
}
];This is what was provided in the tools: tools parameter in the ollama.chat call, and provides the LLM with information about the tools/functions which are available when information outside of its knowledge based is required.
LLMs do not call the functions directly, instead the LLM uses the description provided to return a request to call a function with a set of parameters. The Ollama API's parse the response from the LLM and put tool requests into the response.message.tool_calls object. Using that object from a response we can figure out if there are any requests to call tools, and if so make the call to the tools.
For each tool we call on behalf of the LLM, the response from the tool is then added to the existing message history and we make a new chat request to the LLM. The LLM sees the responses for the tools requests that it made and can then request that additional tools be called or return a response to the user.
The work of calling functions when requested by the LLM, including handling the possibility recursive tool calls, is implemented in the handleRequest function:
async function handleResponse(messages, response) {
// push the models response to the chat
messages.push(response.message);
if (response.message.tool_calls && (response.message.tool_calls.length != 0)) {
for (const tool of response.message.tool_calls) {
// log the function calls so that we see when they are called
log(' FUNCTION CALLED WITH: ' + inspect(tool));
console.log(' CALLED:' + tool.function.name);
const func = funcs[tool.function.name];
if (func) {
const funcResponse = func(tool.function.arguments);
messages.push({ role: 'tool', content: funcResponse });
} else {
messages.push({ role: 'tool', content: 'invalid tool called' });
console.log(tool.function.name);
}
}
// call the model again so that it can process the data returned by the
// function calls
return ( handleResponse( messages,
await ollama.chat({ model: model, messages: messages, tools: tools})
));
} else {
// no function calls just return the response
return response;
}
}The implementation of the two functions are simple JavaScript functions where we have hard coded the favorite color and favorite hockey team for people in Ottawa, Canada and Montreal, Canada. You can easily imagine how this could be a database lookup, a call to a microservice or something else:
/////////////////////////////
// FUNCTION IMPLEMENTATIONS
const funcs = {
favoriteColorTool: getFavoriteColor,
favoriteHockeyTeamTool: getFavoriteHockeyTeam
};
function getFavoriteColor(args) {
const city = args.city;
const country = args.country;
if ((city === 'Ottawa') && (country === 'Canada')) {
return 'the favoriteColorTool returned that the favorite color for Ottawa Canada is black';
} else if ((city === 'Montreal') && (country === 'Canada')) {
return 'the favoriteColorTool returned that the favorite color for Montreal Canada is red';
} else {
return `the favoriteColorTool returned The city or country
was not valid, please ask the user for them`;
}
};
function getFavoriteHockeyTeam(args) {
const city = args.city;
const country = args.country;
if ((city === 'Ottawa') && (country === 'Canada')) {
return 'the favoriteColorTool returned that the favorite hockey team for Ottawa Canada is The Ottawa Senators';
} else if ((city === 'Montreal') && (country === 'Canada')) {
return 'the favoriteColorTool returned that the favorite hockey team for Montreal Canada is the Montreal Canadians';
} else {
return `the favoriteColorTool returned The city or country
was not valid, please ask the user for them`;
}
};Tools calling in Action
Ok so now we know how to use the Ollama API to:
- tell the model what functions are available
- call those functions when asked by the model, and
- how to return the answers to the model so that it can use them in answering the original question
but how well does it work ?
To check that out we ran the sequence of questions using a number of different models that are supported for tool calling by with Ollama. We started with mistral as we'd used that model in pervious explorations and expanded the list to:
- mistral
- mistral-nemo
- llama3.1-8B
- hermes3-8B
- llama3.1-70B
- firefunction-v2-70B
For each of these models we ran the question sequence 10 times with a fresh history and captured the output. This resulted in a lot of data and faced the prospect of going through the results manually to see how things went. This made us wonder if an LLM could help us avoid doing all of that work manually. To that end we put together a simple question that asked the LLM to rate the results of each run - rate.mjs. These are the key parts of that:
const messages = [{role: 'system', content:
'you are a helpful agent that reviews a chat transcript and figures out how well questions about the users ' +
'favorite color are answered ' +
'The LLM can ask clarifying questions. ' +
'The LLM should ask for the City and Country, if it has not already been provided, when asked for a favorite color. '
}];
const ratingQuestion =
'Use only the conversation in the context to find answers ' +
'Given that the right answer when you are in Ottawa Canada is black and that the right answer is when you are in Montreal Canada is red, report the percentage success in the conversation in answering the question "what is my favorite color" ' +
'Only answers where the specific color is returned should be considered as an instance for calculation of the percentage' +
'Do not include requests for additional information in the total requests for a favorite color' +
'Explain your answers ' +
'Always return the percentage in the format [Percentage: X].\n ' +
'<context> ' +
data +
'<context/> ';We first tried using ollama31-8B, a model that would fit into our GPU (4070Ti Super 16G), and run at a reasonable speed. Unfortunately the results were underwelming. We won't go into too many details as it's not core to this post but in the end we only got reasonable results from a larger 70B model and OpenAI ChatGPT. For smaller models despite trying all sorts of different models and hints in the prompt we could not get reasonable results. Once we switched to the larger models the results were much better without having to work on the prompt too much. The main thing the larger models struggled with was following the instruction that requests for additional information not negatively affect the percentage of success.
Our main takeaway is to be carefull not to assume how well an LLM can perform based on the results when using the smaller 7B/8B models. Larger models will likely be better and also much easier to get reasonable results with. Unfortunately that mean running slowly (which is what we did with local 70B runs) or using hosted services (either public or within your organization).
In the end we did the hard work of evaluating the results by hand as well as using a few differet models. This ended up being subjective as right/wrong in the flow needed some allowances to make sense when comparing between the flows.
Before you look at the results its imporant to make it clear that these results are based on the flow we outlined, and what we considered the ideal output as shared earlier. Your milage may vary on how this applies to other flows, tools, etc. It is not intended to be performance comparison, only to share our experience trying out tool use with Node.js and Ollama. The full runs for each model and the output from the ratings by the models are available in mhdawson/ai-tool-experimentation in the ollama subdirectory. In the evaulation we only considered the percentage of success of answering questions about the users favorite color and requests for additional information when information was needed was considered ok. The summary percentage was taken by adding the percentage from each of the 10 runs and dividing by 10.
The results were as show in Figure 1:
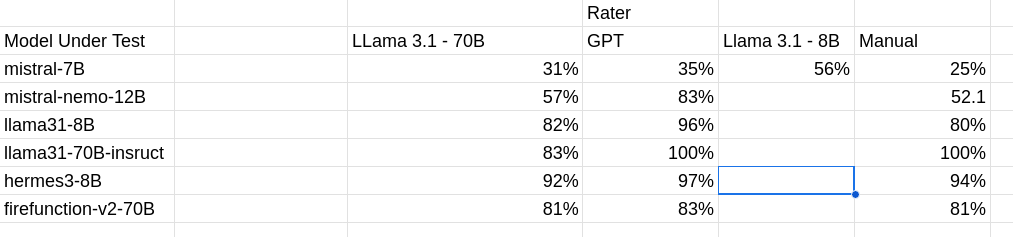
Figure 1 - accuracy as rated by different raters.
As mentioned earlier using a smaller model did not do a great job of matching "human review" which is shown as the "Manual" column. We only show llama 3.1 8B for one entry as an example but we did try a number of models and prompts. Both ChatGPT and llama 3.1 70B did a reasonable job of matching human review.
Interestingly, the two mistral models seemed to struggle the most which may explain our ealier experience with function calling/models the older mistral model is what we'd mostly used in prior exploration and we used a similar question flow.
For our question sequence the llama31-70B model did best, followed by the hermes3-8B model (However,see the next section for a big caveat on that). Further, exploration of the hermes3 model based on how well it did for a smaller model.
Based on these results, our impression is that function calling has improved since our earlier explorations but it will still be important to understand your typical flow and explore different models to see how well they work for your usecase.
A last minute wrinkle
Our question flow pretty much only consisted of questions that involved calling a tool, and from the output flows we could see that some models seemed to call multiple functions even when asked for only the favorite color, or call functions more often that other models.
We decided we should take a quick look at how a model acted when asked a question that would not involved calling a function. To that end we added a question about the fastest car in the world in the middle:
const questions = ['What is my favorite color?',
'My city is Ottawa',
'My country is Canada',
'I moved to Montreal. What is my favorite color now?',
'My city is Montreal and my country is Canada',
'My city is Ottawa and my country is Canada, what is my favorite color?',
'What is the fastest car in the world?',
'What is my favorite hockey team ?',
'My city is Montreal and my country is Canada',
];It was a surprise that with both llama3.1 models (even the 70B one) the model attempted to call non-existent functions and failed to answer the new question:
....
QUESTION: What is the fastest car in the world?
CALLED:favoriteHockeyTeamTool
CALLED:fastestCarInTheWorldTool
fastestCarInTheWorldTool
CALLED:carsInfoTool
carsInfoTool
RESPONSE:It looks like we're having some issues with the tools. The favoriteHockeyTeamTool and fastestCarInTheWorldTool are not returning any useful information.So while llama3.1 70B did best on our original flow, it starts to fall down when we introduce questions that can't be answered by one of the tools provided.
Other models seemed to do just fine (Hermes3, mistal-nemo) and answered the new question from their existing knowledge base without trying to call a function.
QUESTION: What is the fastest car in the world?
RESPONSE:
The Bugatti Chiron Super Sport 300+ holds the title of being the fastest production car in the world, reaching a top speed of 304 miles per hour.This highlights that our earlier question sequence/evaluation focussed too much on whether functions where called when needed and left out the important aspect of making sure that imaginary functions are not called and that the model can still answer questions from its knowledge base when tools are provided. Testing to make sure that a model is going to call and not call functions appropriately when answering questions seems both important and hard to get right.
Wrapping up
We wanted to take an updated look at function calling, particularly after a leading tool like Ollama announced support. We learned a lot even with the limited exploration that we did.
We hoped that his blog post has helped you understand how you can uses tools/function calls when using Node.js and the Ollama JavaScript APIs and some of the things to look out for as you explore how they might work(or not) in your use case.
If you want to learn more about what the Red Hat Node.js team is up to check these out:
- https://developers.redhat.com/topics/nodejs
- https://developers.redhat.com/topics/nodejs/ai
- https://github.com/nodeshift/nodejs-reference-architecture
- https://developers.redhat.com/e-books/developers-guide-nodejs-reference-architecture