As an architect in the Red Hat Consulting team, I’ve helped countless customers with their integration challenges over the last six years. Recently, I had a few consulting gigs around Red Hat AMQ 7 Broker (the enterprise version of Apache ActiveMQ Artemis), where the requirements and outcomes were similar. That similarity made me think that the whole requirement identification process and can be more structured and repeatable.
This guide is intended for sharing what I learned from these few gigs in an attempt to make the AMQ Broker architecting process, the resulting deployment topologies, and the expected effort more predictable—at least for the common use cases. As such, what follows will be useful for messaging and integration consultants and architects tasked with creating a messaging architecture for Apache Artemis, and other messaging solutions in general. This article focuses on Apache Artemis. It doesn’t cover Apache Kafka, Strimzi, Apache Qpid, EnMasse, or the EAP messaging system, which are all components of our Red Hat AMQ 7 product offering.
Typical customer requirements
In my experience, a typical middleware use case has fairly basic messaging requirements and constraints that fall under a few general categories. Based on the findings in these areas, there are a few permutations of the possible solutions with pros and cons, and the final resulting architectures are fairly common. Designing, documenting, communicating the constraints and implementing these common architectures, should be well understood by messaging SMEs. Anything different from these standard architectures should be expected to require additional effort and lead to a bespoke architecture with unique non-functional and operational characteristics.
This article covers the following hypothetical but common messaging scenario. Here is a customer describing the typical messaging requirements:
- We have around 100 microservices with Spring Boot and Apache Camel that use messaging extensively.
- All of our services are scalable and high availability (HA), and we expect the messaging layer to have similar characteristics.
- We use mostly point-to-point but we also have a few publish-subscribe interactions.
- Most of our messages are small in the KB range, but there are those that are fairly large in the single-digit MBs range.
- We don’t know our current message throughput, it changes as we add new services using messaging.
- We don’t use any exotic features, but we have use cases with message selectors, scheduled delivery, and TTL.
- We need to preserve the message ordering with and without message grouping.
- We primarily use JMS from our Java-based services and AMQP from the few .NET services.
- We don’t like XA, but in a handful of services, we use distributed transactions involving the message broker.
- We can replay messages if necessary, but we cannot lose any message, and we use only persistent messages.
- We put all failed messages in DLQs and discard later.
- We want to know all of the best practices and naming conventions.
- All broker-to-broker communication and client-to-broker communication must be secured.
- We want to control who can create queues, read and write messages, and browse.
If you hear these above requirements, you are in familiar territory, and this article should be useful to you. If not, and there are specific hardware, throughput, topological, or other requirements, clone the Apache Artemis repo and go deeper. And don’t forget to share what you learn with others later.
The constraints identification approach
In addition to the obvious customer requirements and wishes, other hard and soft constraints will shape the resulting architecture. The customer might or might not be aware of these constraints and dependencies, and it is your job to dig deep and discover them all.
The approach I follow is to start from the fundamental and hard to change requirements, such as infrastructure and storage, as shown in Figure 1. Explore what options there are for each and document the constraints with pros and cons. Then, do the same for the orchestration layer, if present.
The fundamental constraints will then dictate what is possible in the upper layers, such as options for high availability and scalability. Further up in the layers the flexibility increases, and one can choose swap load balancers and different client implementations without impacting the layers below.

Finding the answers to these points and identifying what is most important and where the customer is willing to make a compromise will help you identify a workable architecture. Next, let’s go deeper, and see what the specific constraints are for an Apache Artemis-based solution.
Infrastructure
This an area where the customer will have the least amount of flexibility, and your goal is to identify how the message broker fits within the available infrastructure in a reliable configuration. It is unlikely that a customer will change their infrastructure provider for their messaging needs, so try to identify a fit-for-purpose solution.
Typically, common messaging infrastructures are based on on-premise infrastructure with virtualizers, NFS storage, and F5 load balancers. This infrastructure all can be within a single data center or spread across two data centers (rather than three, unfortunately). In an alternative scenario, the customer might be using AWS (or equivalent), such as EC2, EBS, EFS, RDS, or ELBs. Typically, all of these options spread across three AZs in a single region. That is the most common AWS setup for a small-to-midsize integration use case.
Apart from computing, storage, and load balancers, at this stage, we want to identify the data center's topology, network latency, and throughput. Is the client using a single datacenter, two data centers, or any other odd number? Is it an active-active, or active-passive data center topology?
Last but not least, what are the operating system, JDK, and client stacks? This information is easily verifiable from the AMQ 7-supported configuration page, including what is tested, what is supported, for how long, and whatnot.
While on-premise and cloud-based infrastructures offer similar resources, the difference typically is in the number of data centers and the operation, failover, and disaster recovery models. Influencing these fundamental models is a slow process, which is why we want to identify these constraints first.
Storage
Once we have identified the broader infrastructure level details, the next step is to focus on storage. Storage is a part of the infrastructure layer but it requires separate considerations here. When HA is a requirement (which is always the case), storage is the most critical and limiting factor for the messaging architecture. Pay special attention to what options the customer's infrastructure offers, as the answer will significantly limit the possible deployment topologies.
Storage capacity
Capacity is hardly a real issue, as typically there are many unknowns when estimating the exact storage capacity required. Most customers:
- Use the message broker as their temporary staging area, where messages are consumed as fast as the consumers can handle. Typically there are no consumer service RPOs defined, and it is not clear for how long messages can keep accumulating.
- Put messages into DLQs, but will not have a clear idea of what to do with these messages later. Replaying failed messages is dependent on the actual business requirements and is not always desirable.
- Expect that if a message is 1MB in size, it will consume 1MB on the disk. As you all know from experience by now, that is not the case. The same message could end up consuming multiple times more storage, depending on the type of messaging interaction style, caching, and other configurations.
All of these and other scenarios can lead to the accumulation of messages in the broker and consume hundreds of gigabytes of storage. If the customer has no answers to these points, the only proven approach for estimating the required storage size is "finger in the air." Luckily, Artemis—like its predecessors—has flow control, which can protect the broker from running out of storage. This question typically comes down to whether to throw an exception or block the producers to protect the broker.
Storage type
Storage type is much more important and dictates what high-availability options will be required later. For example, if the broker is on Kubernetes, there is no master/slave, and therefore, there is no need for a shared file system with a distributed lock such as NFSv4, GFS2, or GlusterFS. But, the file system should ensure that the journal has high availability.
When the broker is on VMs (not on Kubernetes), the simpler option to implement and operate is to use a supported shared file system. Notice that AWS EFS service is not a full NFSv4 spec, but it is still supported as a shared storage option for Artemis. If a shared file system is not present, alternatively, you can use a relational database as storage with a potential performance hit. Check which relational databases are supported (currently, that is Oracle, DB2, MSSQL). Note that using AWS RDS is a viable option here too.
If no shared file system or relational database is possible, you can consider replication. Replication requires additional considerations. One big advantage of replication is that the messaging and middleware team will not depend on any storage team to provision the infrastructure. Also, there won’t be a cost for shared filesystems or relational databases, and the broker performs its data replication. There are customers who like this aspect, but all good things come at a cost, such as the fact that a reliable replication requires a minimum of three master and three slave brokers to avoid split-brain situations.
There is also the option of using the network pinger, which is risky and not recommended in practice. The network pinger avoids the need for three of everything, but you should only use the network pinger if you are unable to use three or more live backup groups. If you are using the replication high availability policy, and if you have only a single live backup pair, configuring network pinging reduces (but does not remove) the chances of encountering network isolation.
Another cost is that split-brain could happen, not only for network partitions and server crashes, but also as a consequence of overload, CPU starvation, long I/O waits, long garbage collection pauses, and other reasons. Also, replication can happen only within a single datacenter and LAN and requires a reliable, low-latency network. AWS AZs in the same region are considered different data centers, as Amazon does not commit to networking latency SLAs either. Finally, replication also has a performance hit compared to a shared store option.
Ultimately, the critical point about storage is that while we can make the broker process and the client process HA, the datastore itself also has to be HA and durable, and this is possible only through data replication. As part of AMQ architecture, it is important to identify who is replicating the data (the file system, the database, or the message broker itself through replication) to ensure that the data is highly available.
Orchestration
Here, the question boils down to checking whether the customer will run the message broker on container orchestrators such as Kubernetes and Red Hat OpenShift, on bare VMs through homegrown bash scripts, or Red Hat Ansible playbooks. If the customer is not targeting OpenShift, the questions in this section can be skipped. If the messaging infrastructure will run on containers and be orchestrated by Kubernetes, there are a few constraints and architectural implications to consider.
For example, there is no master/slave failover (so no hot backup broker present). Instead, there is a single pod per broker instance that is health monitored and restarted by Kubernetes, which ensures broker HA. The single pod failover process with Kubernetes is different from master/slave with replication failover on-premise. Because there is no master/slave failover, there is no need for message replication between master/slave either. There is also no need for distributed file locking, which means that there is no need for a shared file system with distributed locking capabilities and that one can still use these file systems to mount the same storage to different Kubernetes nodes and pods, but the locking capability of the file system is not a prerequisite any longer.
For example, in the case of a node failure, Kubernetes would start a broker pod on a different node and make the same PV and data available. Because there is no master/slave, there is no need for ReadWriteMany, but only for ReadWriteOnce volume types. That said, you might still need a shared file system that can be mounted to different nodes in the case of node failure (such as AWS EBS, which can be mounted to different EC2 instances in the same region).
So, are there messaging clients located outside of the cluster? Connecting to the broker from within an OpenShift cluster is straightforward through Kubernetes services, but there are restrictions for connecting to the broker from outside of the Kubernetes cluster.
Next, can external clients use a protocol that supports SNI? The easiest option is typically to use SSL and access the broker from the router. If using TLS for clients is not possible, consider using NodePort binding which requires cluster-admin permissions.
Finally, there is a scaledown controller to drain and migrate messages when scaling down broker pods in a cluster.
There might be a few other differences, but failover, discovery, and scaledown is automated, and the broker fundamentals do not change on Kubernetes and Openshift.
High availability
When a customer talks about "high availability," what they mean is a full-stack, highly-available messaging layer. That means HA storage, HA brokers, HA clients, HA load balancers, and HA anything else that might be in between. To cover this scenario, you have to consider the availability of every component in the stack, as shown in Figure 2:
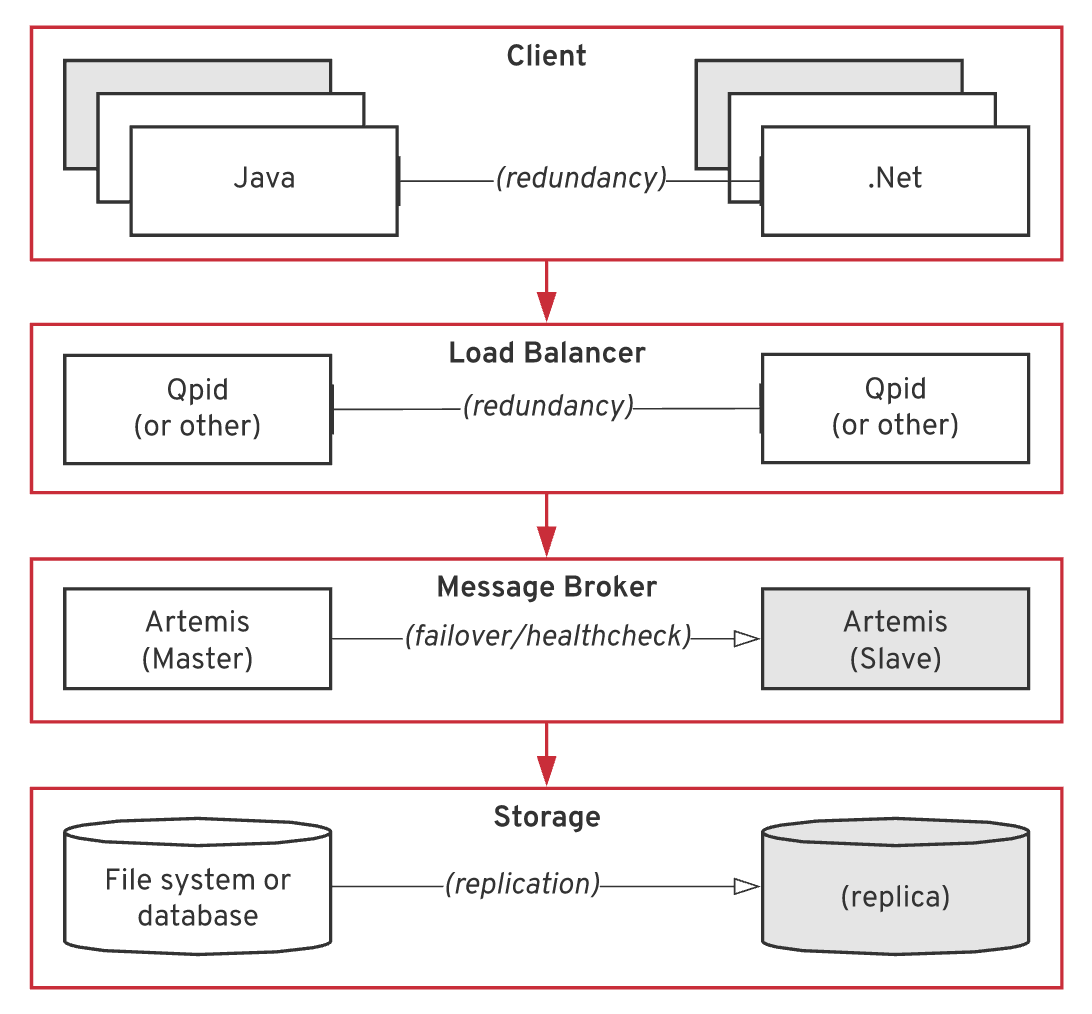
Storage
The only way to ensure HA for data is by replicating the data. You have to identify who replicates the data and where the data is replicated: locally, across VMs, across DCs, and so on. Most customers will want to survive a single data center outage without a message loss, which requires a cross data center replication mechanism. The easiest option is to delegate the journal replication to the file system. This option has implications on cost and dependency on infrastructure teams. For example, if you replicate data using a database, consider the cost and performance hit. If you replicate data using Artemis journal replication but consider the customer's maturity to operate a broker cluster, consider split-brain scenarios, data center latencies, and performance hits.
Broker
On Kubernetes, broker HA is achieved through health checks and container restarts. On-premise, the broker HA is achieved through master/slave (shared store or replication). When replication is used, the slave will already hold the queues in memory, and therefore is pretty much ready to go in case of failover. With shared storage, when the slave gets hold of the lock, then the queues need to be read from the journals ahead of the slave takeover. The time for a shared storage slave to take over will be dependent on the number and size of messages in the journal.
When we talk about broker HA, it comes down to an active-passive failover mechanism (with Kubernetes being an exception). But Artemis also has an active-active clustering mechanism used primarily for scalability rather than HA. In active-active clustering, every message belongs to only one broker, and losing an active broker will make its messages also unaccessible—but a positive side effect of that issue is that the broker infrastructure is still up and functioning. Clients can use active instances and exchange messages with the drawback of temporarily not accessing the messages that are in the failed broker. To sum up, active-active clustering is primarily for scalability, but it also partially improves the availability with temporary message unavailability.
Load balancer
If there is a load balancer, prefer one that is already HA in the organization, such as F5s. If Qpid is used, you will need two or more active instances for high availability.
Clients
This is probably the easiest part, as most customers will already run the client services in redundantly HA fashion, which means two or more instances of consumers and producers most of the time. A side effect of running multiple consumers is that message ordering is not guaranteed. This is where message groups and exclusive consumers can be used.
Scalability
Scalability is relatively easier to achieve with Artemis. Primarily, there are two approaches to scaling the message broker.
Active-active clustering
Create a single logical broker cluster that is scaled transparently from the clients. This can be three masters and three slaves (replication or shared storage doesn’t matter) to start with, which means that clients can use any of the masters to produce and consume the messages. The broker will perform load balancing and message distributions. Such a messaging infrastructure is scalable and supports many queues and topics with different messaging patterns. Artemis can handle large and small messages effectively, so there is no need for using separate broker clusters depending on the message size either.
A few of the consequences of active-active clustering are:
- Message ordering is not preserved.
- Message grouping needs to be clustered.
- Scaling down requires message draining.
- Browsing the brokers and the queues is not centralized.
Client-side partitioning
Create separate, smaller master/slave clusters for different purposes. You can have a separate master/slave cluster for real-time, batch, small messages, large messages, per business domain, criticality, team, etc. When a broker pair reaches its capacity limit, create a separate broker pair and reconfigure clients to use it.
This technique works as long as the clients can choose which cluster to connect to (hence the name client-side partitioning). There is also a use case here for Apache Qpid where you can add new brokers and assign addresses to them without the clients needing to know anything about the location of these brokers, and therefore, simplifying the clients and making the messaging network dynamic.
Load balancer
While a load balancer is not a mandatory component of the messaging stack, it is an architectural decision whether you are going to use client-side load balancing or an external load balancer. With an external load balancer, you have the fact that customers like using their existing load balancers such as F5 for messaging, too. Plus, load balancers:
- Already exist in many organizations, they are already HA, and they support many protocols—so it makes sense to use them for messaging too.
- Allow a single IP for all clients.
- Can do health checks and failover to the master broker (that is, a probe attempting to connect to the relevant acceptor).
There are clients, such as the .NET client with the AMQP protocol, do not support the failover protocol OOTB (here is also an example showing how to mitigate this limitation). Using a load balancer helps with these clients.
Apache Qpid
Apache Qpid can act as an intelligent load balancer for the AMQP protocol only. It supports closest-, lowest latency-, and multicasting-type distributions. You will need to run multiple instances of Qpid to make it HA. That means the clients have to be configured to use multiple IPs. Qpid can also support many topologies, and allow having connections from more secure to less secure directions rather than the other way.
Qpid comes into its own in a geographically-spread meshing message where clients do not know the location of each other and any of the brokers they might be sending messages to, bi-directional messaging beyond the firewall, and building redundant messaging network routes. It's also easy to scale the number of brokers without changing the clients, and the topology can change without a change to the clients as well (dynamic messaging infrastructure).
You can also use Qpid to create multiple brokers sharding an address without the need to use broker clustering, but this feature is only useful if message ordering is not that important, or to act as a client connection concatenator (especially useful for IoT scenarios).
Client-side load balancing
Using a load balancer is not required in reality. You can configure messaging clients to connect to a broker cluster directly. A client can connect to a single broker and discover all other brokers, changing topologies, etc. Consider what happens if the single broker the client is trying to connect is down. For the answer, a list of broker IPs can be passed, and custom load balancing strategies implemented.
Client-side load balancing has advantages: The client can publish to multiple brokers and perform load balancing. This feature can be disabled if publishing to a single broker is required. The downside here is that the client-side load balancing is a client-specific implementation, and the options mentioned here vary across clients.
Clients
With Artemis, there are multiple clients, protocols, and possible combinations. In terms of protocols, here are a few high-level pointers. Another thing to consider here is which protocol can be converted to which protocols when consumers and producers use different wire protocols and clients. The protocol and client choices are unlikely to impact the broker architecture, but they will impact the client service development efforts, and this issue can easily turn into a mess.
AMQP 1.0
AMQP 1.0 should be the default starting option when possible. This option is one of the most tested and used. It is also cross-language, and the only supported option for .NET clients. Keep in mind that Interconnect (the enterprise version of Apache Qpid) supports AMQP 1.0 only, and if Interconnect is in the architecture, the clients have to use AMQP to interact with it.
A limitation of AMQP is that it does not offer XA transaction support
Core
The Core protocol is one of the most advanced, feature-rich, and tested protocols for Artemis. It is the only supported protocol when using EAP with embedded Artemis, and it is the recommended protocol when XA is required.
OpenWire
This protocol is here for legacy compatibility reasons with AMQ 6 (Apache ActiveMQ broker) clients. It is useful in situations when the client code cannot change, so you are stuck with OpenWire. An attractive point about this protocol is that it supports XA.
Reference architectures
Having identified requirements, dependencies, and specific constraints, the next step is coming up with possible deployment architectures. I’m a firm believer in the mantra, "There is no reference architecture for the real world." Consequently, there is no simple process to follow and map the findings to a target architecture. It is the combination of all requirements, constraints, and possible compromises that lead to identifying the most suitable architecture for a customer.
For demonstration purposes, the following are common Artemis deployment topologies for AWS, on bare VMS instead of Kubernetes. The same topologies also apply for on-premise deployments where similar alternative infrastructure services are present. The considerations that apply to all of the deployments below are:
- Client-side load balancing or a load balancer can be used for all of these deployments.
- Load balancers can be co-located with the broker, client, in a dedicated layer, or a combination of these.
- Slave brokers can be kept in separate hosts as demonstrated below, or co-located with a master broker.
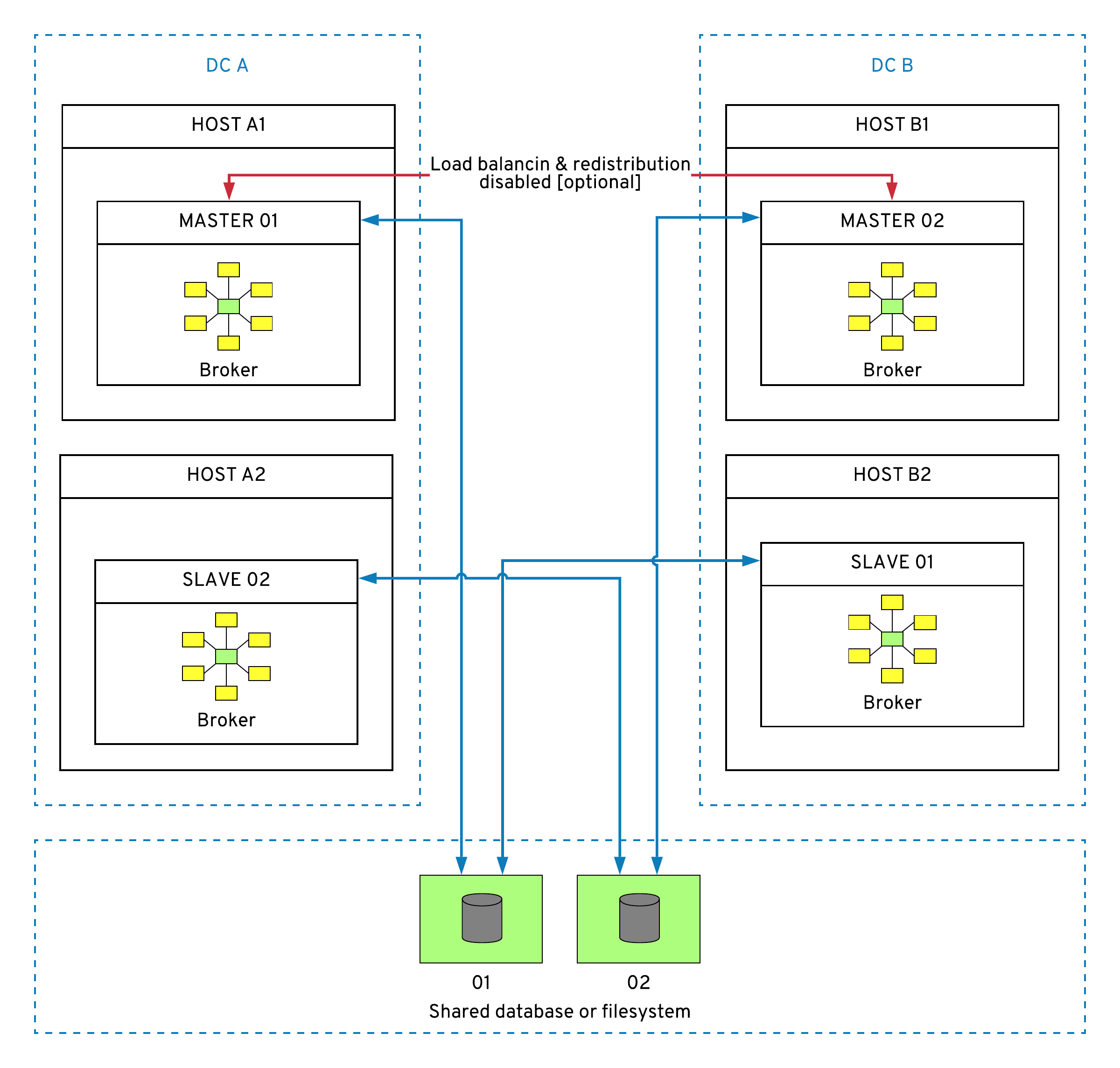
Non-clustered Apache Artemis with shared storage
The simplest HA architecture for Artemis is a single master/slave cluster with shared storage. The example that follows is a scalable version of that set up with two separate master/slave clusters. Notice that there is no clustering (server-side message distribution or load balancing) between the masters. As a result, the clients need to decide which master/slave cluster to use.
Pros
The pros of this approach are:
- It is a simple but highly available Artemis configuration and operational model.
- It is the same topology as in Apache ActiveMQ with master/slave.
- There is no possibility for split-brain, no stuck messages, and message order guaranteed.
Cons
The cons are that this approach requires a shared file system or database, which has an additional cost. Typically, database-based storage is expected to perform worse than file-based storage.
Other notes
Additional notes include the fact that journal high availability is achieved through file system or database (AWS EFS or RDS ) data replication. Optionally, masters can be clustered for message distribution, load balancing, and scalability. The number of master/slave pairs can vary (there are two in Figure 3), and scaling is achieved by adding more master/slave pairs and using client-side partitioning.
Also, in the case of VM or DC failure, it ensures HA.
Clustered Apache Artemis with shared storage
In this topology, we have three master/slave pairs, ensuring HA. In addition, all of the masters are clustered and provide server-side load balancing and message distribution. In this setup, the clients can connect to any member of the cluster and exchange messages. Such a cluster can also scale and change topology without affecting client configuration.
Pros
The pros of this option are that it offers:
- The same topology as in Apache ActiveMQ with master/slave and Network-of-Brokers.
- Server-side message distribution and load balancing.
- No possibility for split-brain scenarios.
Cons
The cons are that it requires a shared file system or database, which has an additional cost. Typically, database-based storage is expected to perform worse than file-based storage.
Other notes
With this approach, journal high availability is achieved through file system or database (AWS EFS/RDS ) data replication. Optionally, masters can be non-clustered to prevent server-side load balancing. The number of master/slave pairs can vary (there are three in Figure 4), and scaling is achieved by adding more master/slave pairs transparently to the clients.
Finally, this approach ensures HA in the case of VM or DC failure.

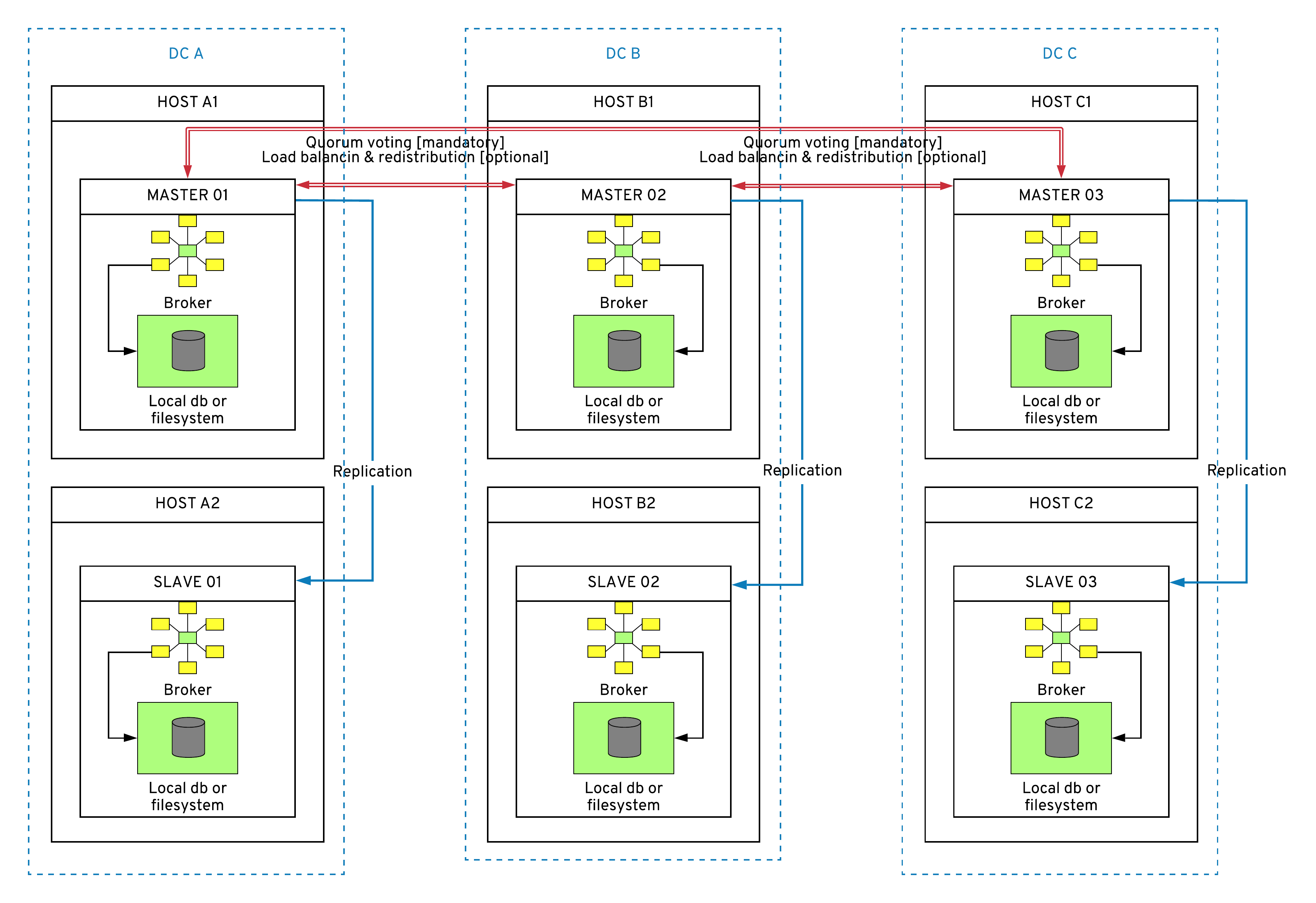
Clustered Apache Artemis with replication
This architecture is a variation of the previous one, where we replace shared storage between Master and slave with replication. As such, this architecture has all of the benefits of server-side load-balancing and transparency for the clients. An added benefit of this architecture is that it does not require a highly-available shares storage layer. Instead, the brokers replicate the data.
Pros
The pros of this approach are that:
- Data replication is performed by the broker, not by the infrastructure services.
- There is no extra cost or dependency on the infrastructure for journal replication.
- It offers scalable and highly available messaging infrastructure.
Cons
The cons are that:
- Replication is sensitive to network latency, opening the possibility of split-brain scenarios. Notice that the replication in Figure 4 is within the same DC.
- Compared to other options, this one has complex configuration and operational models.
- It requires a minimum of three master and three slave brokers (as in the diagram below).
Other notes
With this approach:
- The number of master/slave pairs can be different (odd number required).
- Optionally, server-side message distribution and load balancing can be disabled.
- It ensures HA in the case of VM failure, but not in the case of DC failure.
- It requires a quorum and a certain number of brokers to be alive.
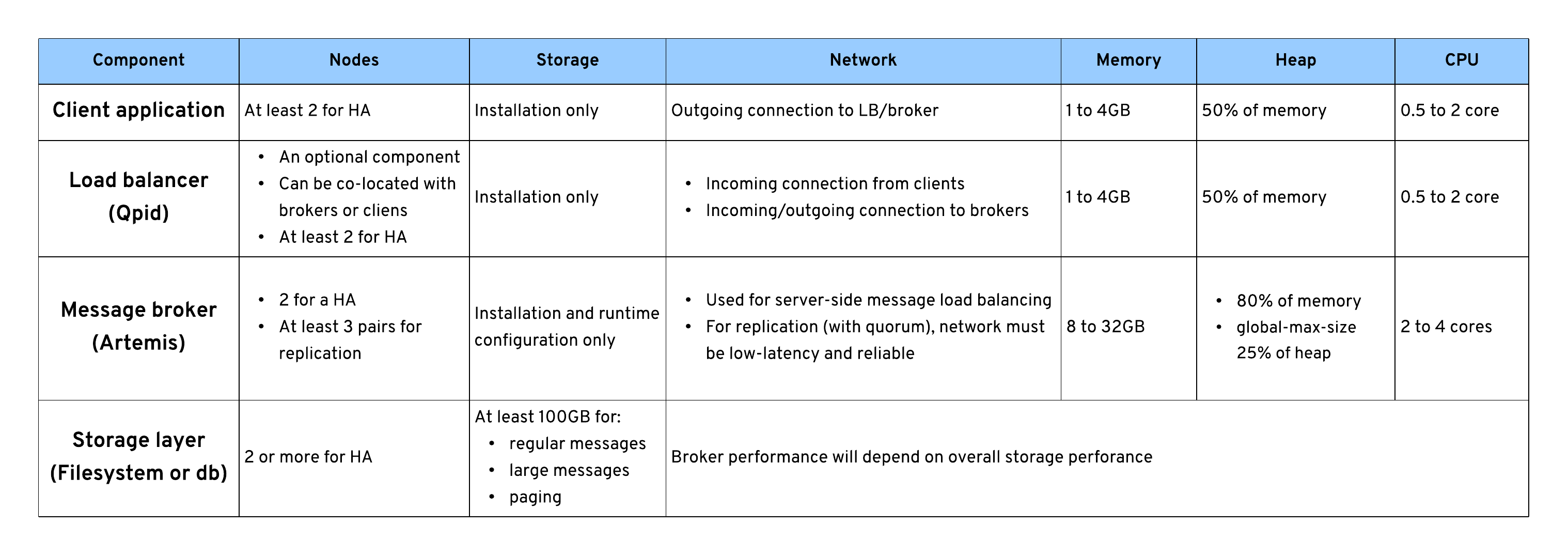
Capacity planning
The numbers and ranges shown in Figure 5 are provided only as a guide and starting point. Depending on the use case, you might have to scale up or down your individual architectural components.
Summary
Over the years, I have hardly seen two messaging architectures that are absolutely the same. Every organization has something unique in the way they manage their infrastructure and organize their teams, and that inevitably ends up reflected in the resulting architectures. Your job as a consultant or architect is to find the most suitable architecture within the current constraints, and educate and guide the customer towards the best possible outcome. There is no right or wrong architecture, but deliberate trade-off commitments in a context.
In this article, I tried to cover as many areas of Artemis as possible from an architecturally significant point of view. But by doing so, I had to be opinionated, ignore other areas, and emphasize what I think is significant based on my experience. I hope you find it useful and learned something from it. If that is the case, say something on Twitter and spread the word.
Last updated: August 14, 2023