Everybody out of the pool!
Well ... not everybody. Just those bad actors. You know, those microservices that aren't playing nice, that are not doing their job, that are too slow, etc. We're talking about Istio, Circuit Breakers and Pool Ejection.
[This is part three of my ten-week Introduction to Istio Service Mesh series. My previous article was Part 2: Istio Route Rules: Telling Service Requests Where to Go. Rather see this in a video? Check out the video edition here.]
How Things Should Be
When you are managing your microservices with Kubernetes -- such as is done with OpenShift -- your capacity is auto-scaled up or down based on demand. Because microservices run in pods, you may have several microservice instances running in containers at a single endpoint, with Kubernetes handling the routing and load balancing. This is great; this is how it is supposed to be. All good.
As we know, microservices are small and ephemeral. Ephemeral may be an understatement; services will pop up and disappear like kisses from a new puppy. The birth and death of a particular instance of a microservice in a pod is expected, and OpenShift and Kubernetes handle it quite well. Again, this is how it is supposed to be. All good.
How Things Really Are
But what happens when one particular microservice instance -- container -- goes bad, either by crashing (503 errors) or, more insidiously, taking too long to respond? That is, it wasn't auto-scaled out of existence; it failed or became slow all on its own. Do you try again? Reroute? Who defines "taking too long", and should we wait and try again later? How much later?
When did this tiny microservice stuff all of a sudden get so complicated?
Istio Pool Ejection: Reality Meets Its Match
Again, Istio comes to the rescue (don't act surprised, these blog posts are about Istio, after all). Let's take a look at how the Circuit Breaker pattern with Pool Ejection works in Istio.
Istio detects faulty instances, or outliers. In the Istio lexicon this is known as outlier detection. The strategy is to first detect an outlier container and then make it unavailable for a pre-configured duration, or what's called a sleep window. While the container is in the sleep window, it is excluded from any routing or load balancing. An analogy would be front porch lights on Halloween night: If the light is off, the house isn't participating, for whatever reason. You can skip it and save time, visiting only the active houses. If the homeowner arrives home 30 minutes later and turns on the porch light, go get some candy.
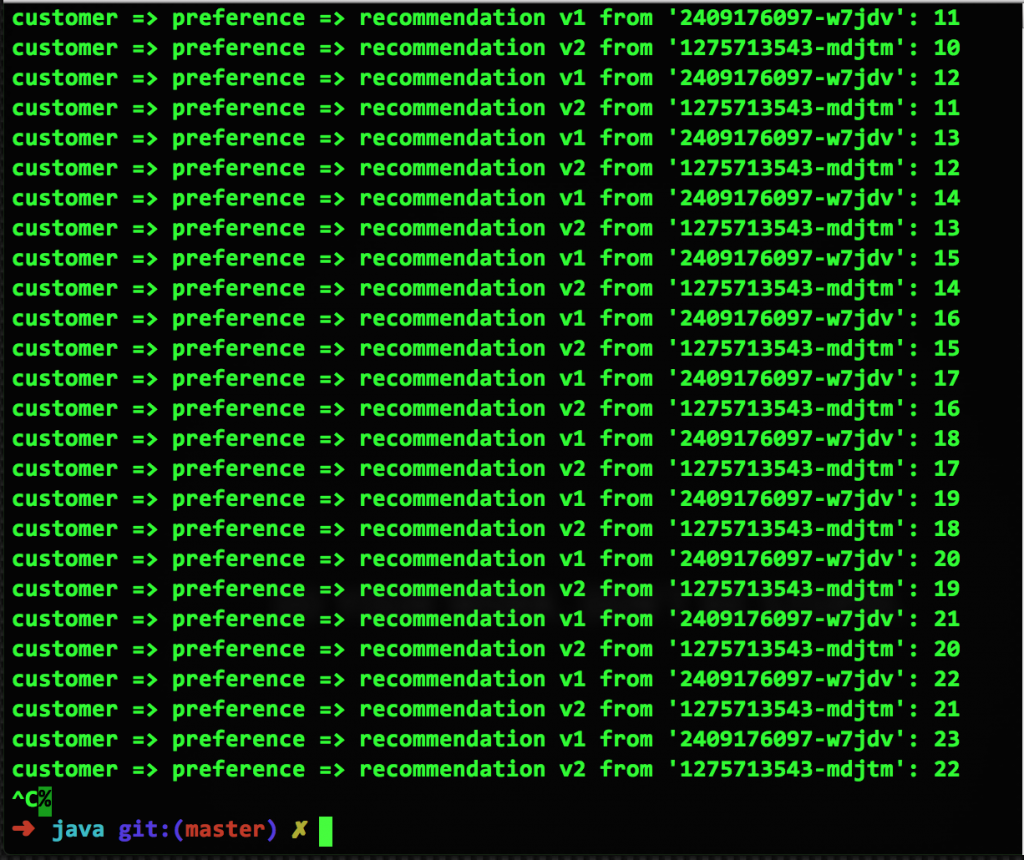
To see how this plays out in Kubernetes and OpenShift, here's a screen capture of a normally-operating microservices sample, taken from the Red Hat Developer Demos repo. In this example, there are two pods (v1 and v2), each running one container. With no Route Rules applied, Kubernetes defaults to an evenly-balanced, round-robin routing:
Preparing For Chaos
To enforce pool ejection, you first need to insure you have a routerule in place. Let's use a 50/50 split of traffic. In addition, we'll use a command to increase the number of v2 containers to two. Here's the command to scale up the v2 pods:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
Taking a look at the contents of the route rule, we can see that traffic is split 50/50 between the pods.

Here's a screen capture of that rule in action:
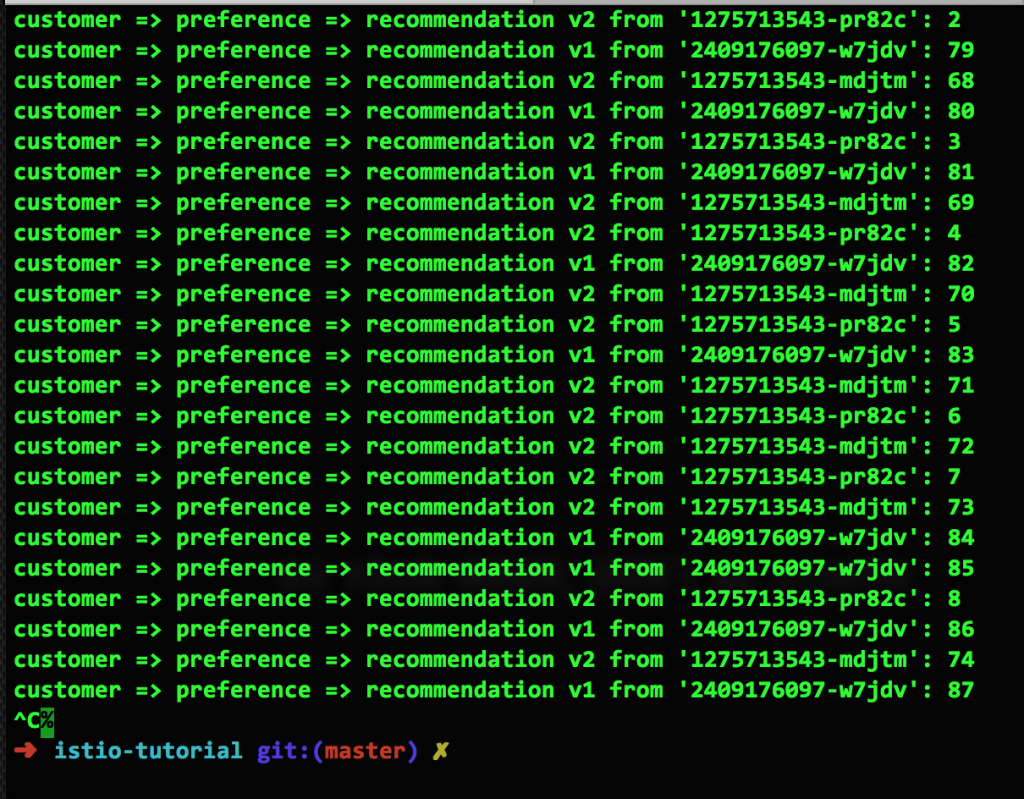
The astute observer will note that this is not an even, 50/50 mix (it's 14:9). However, over time, it will even out.
Let's Break Stuff!
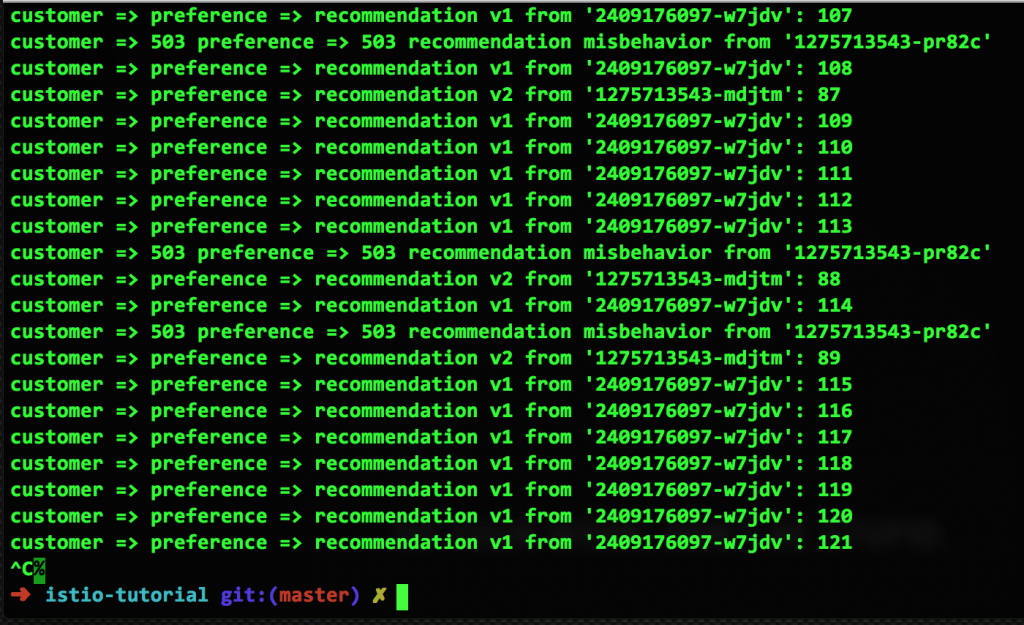
Now let's introduce a failure in one of the v2 containers, leaving: one healthy v1 container, one healthy v2 container, and one failing v2 container. Here is the result:
Finally, Let's Fix Stuff
So now we have a container that's failing, and this is where Istio pool ejection shines. By activating a simple configuration, we are able to eject the failing container from any routing. In this example, we'll eject it for 15 seconds, with the idea that it will correct itself (e.g. by restarting or returning to higher performance). Here's the configuration file and a screen capture of the results:

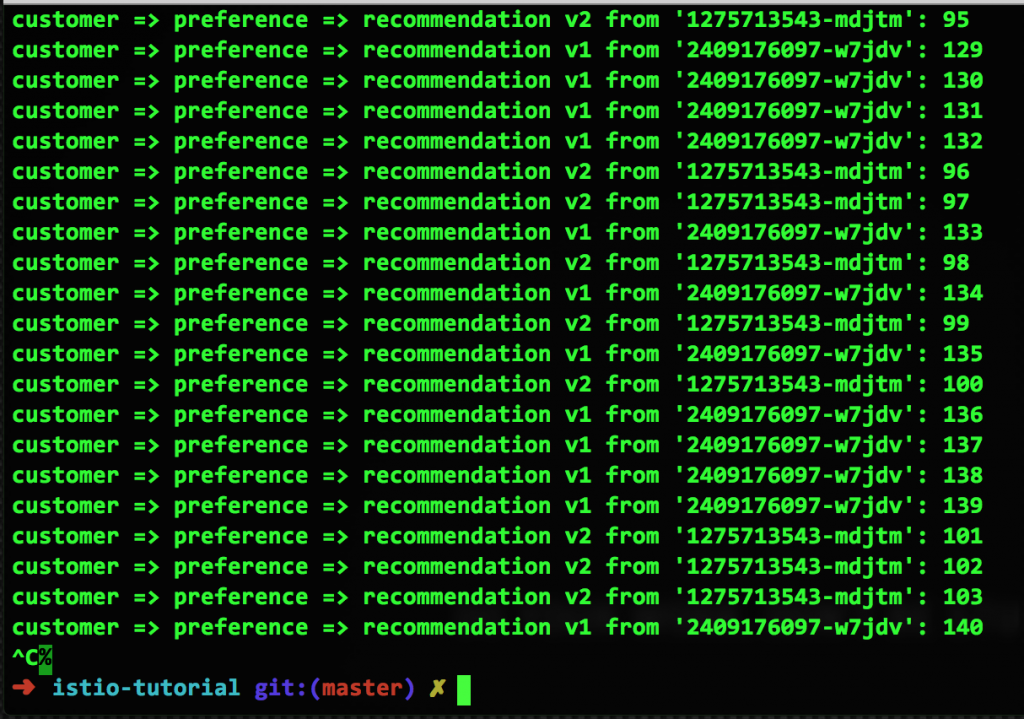
The failing v2 container is not being used. After the 15 seconds has elapsed, the container is automatically added back into the pool. This is Istio pool ejection.
Starting To Build An Architecture
Combining Istio pool ejection with monitoring, you can start to build a framework where faulty containers are removed and replaced automatically, reducing or eliminating downtime and the dreaded pager call.
Next week's blog post will take a look at the monitoring and tracing provided by Istio.
All articles in the "Introduction to Istio" series:
- Part 1: Introduction to Istio; It Makes a Mesh of Things
- Part 2: Istio Route Rules: Telling Service Requests Where to Go
- Part 3: Istio Circuit Breaker: How to Handle (Pool) Ejection
- Part 4: Istio Circuit Breaker: When Failure Is an Option
- Part 5: Istio Tracing & Monitoring: Where Are You and How Fast Are You Going?
- Part 6: Istio Chaos Engineering: I Meant to Do That
- Part 7: Istio Dark Launch: Secret Services
- Part 8: Istio Smart Canary Launch: Easing into Production
- Part 9: Istio Egress: Exit Through the Gift Shop
- Part 10: Istio Service Mesh Blog Series Recap
