If you break things before they break, it'll give you a break and they won't break.
(Clearly, this is management-level material.)
[This is part six of my ten-week Introduction to Istio Service Mesh series. My previous article was Part 5: Istio Tracing & Monitoring: Where Are You and How Fast Are You Going?]
Testing software isn't just challenging, it's important. Testing for correctness is one thing (e.g. "does this function return the correct result?"), but testing for failures in network reliability (the very first of the eight fallacies of distributed computing) is quite another task. One of the challenges is to be able to mimic or inject faults into the system. Doing it in your source code means changing the very code you're testing, which is impossible. You can't test the code without the faults added, but the code you want to test doesn't have the faults added. Thus the deadly embrace of fault injection and the introduction of Heisenbugs -- defects that disappear when you attempt to observe them.
Let's see how Istio makes this oh so easy.
We're All Fine Here Now, Thank You ... How Are You?
Here's a scenario: Two pods are running our "recommendation" microservice (from our Istio Tutorial), one labeled "v1", the other labeled "v2". As you can see, everything is working just fine:
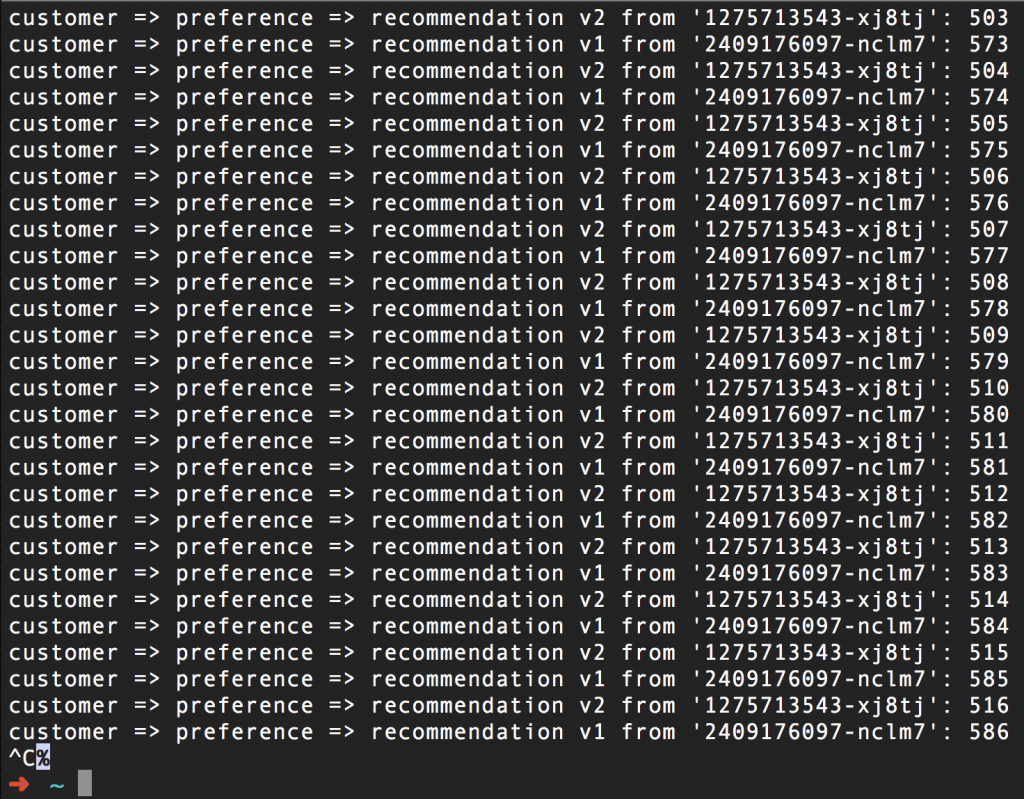
(By the way, the number on the right is simply a counter for each pod)
Everything is working swimmingly. Well... We can't have that now, can we? Let's have some fun and break things -- without changing any source code.
Give Your Microservice A Break
Here's the content of the yaml file we'll use to create an Istio route rule that breaks (503, server error) half the time:
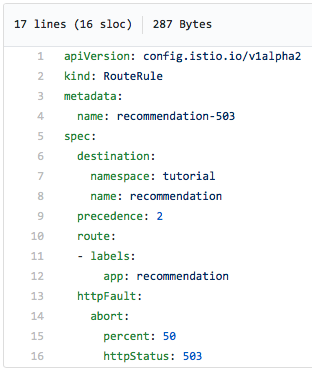
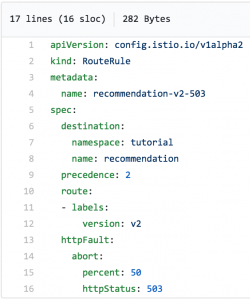
Notice that we're specifying a 503 error be returned 50 percent of the time.
Here's another screen capture of a curl command loop running against the microservices, after we've implemented the route rule (above) to break things. Notice that once it goes into effect, half of the requests result in 503 errors, regardless of which pod (v1 or v2) is the endpoint:
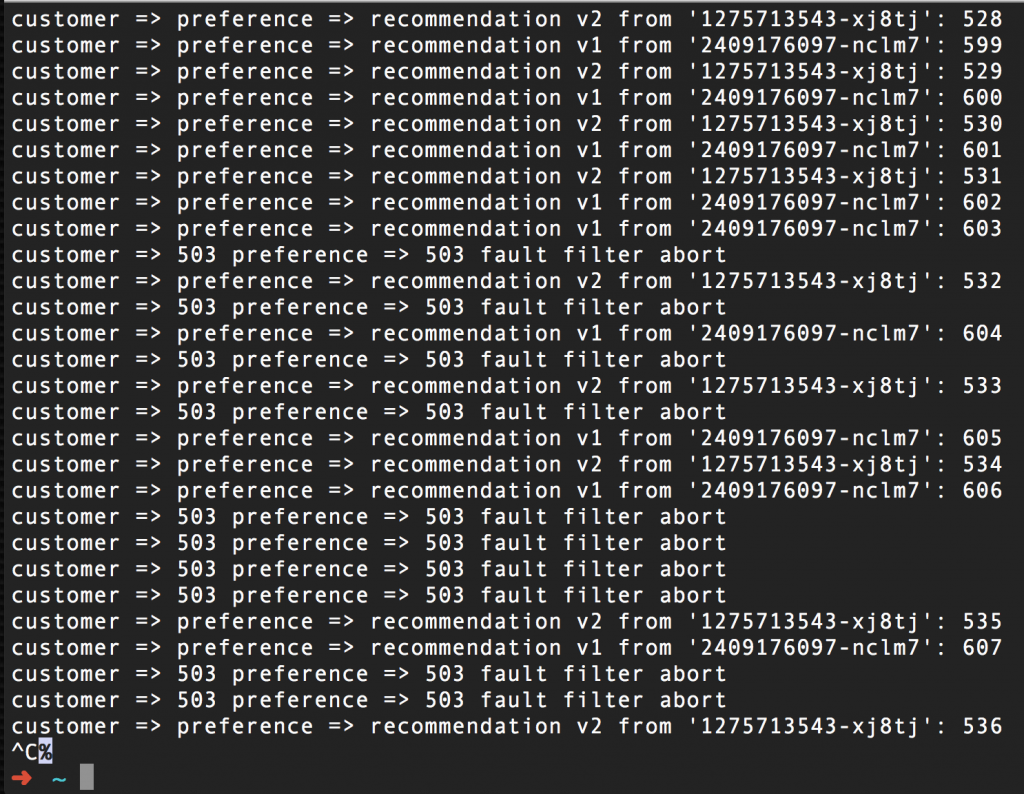
To restore normal operation, you need to simply delete the route rule; in our case the command is istioctl delete routerule recommendation-503 -n tutorial. "Tutorial" is the name of the Red Hat OpenShift project where this tutorial runs.
Delay Tactics
Generating 503 errors is helpful when testing the robustness of your system, but anticipating and handling delays is even more impressive -- and probably more common. A slow response from a microservice is like a poison pill that sickens the entire system. Using Istio, you can test your delay-handling code without changing any of your code. In this first example, we are exaggerating the network latency.
Note that, after testing, you may need (or desire) to change your code, but this is you being proactive instead of reactive. This is the proper code-test-feedback-code-test... loop.
Here's a route rule that will... Well, you know what? Istio is so easy to use, and the yaml file is so easy to understand, I'll let it speak for itself. I'm sure you'll immediately see what it does:
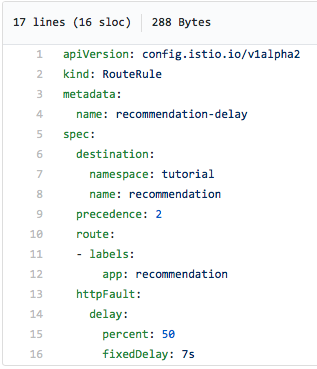
Half the time we'll see a seven-second delay. Note that this is not like a sleep command in the source code; Istio is holding the request for seven seconds before completing the round trip. Since Istio supports Jaeger tracing, we can see the effect in this screen capture of the Jaeger UI. Notice the long-running request toward the upper right of the chart -- it took 7.02 seconds:
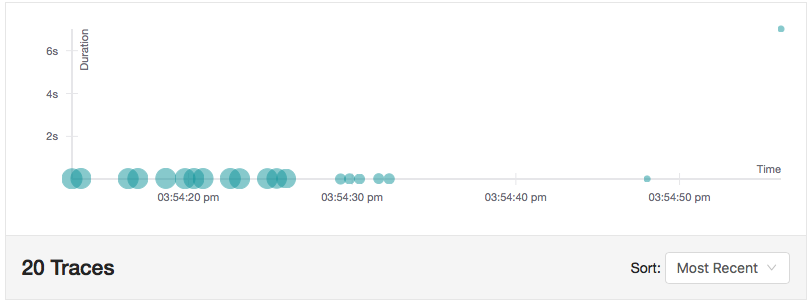
This scenario allows you to test and code for network latencies. Of course, removing the route rule removes the delay. Again, I hate to belabor the point, but it's so important. We introduced this fault without changing our source code.
Never Gonna Give You Up
Another useful Istio feature related to chaos engineering is the ability to retry a service N more times. The thought is this: requesting a service may result in a 503 error, but a retry may work. Perhaps some odd edge case caused the service to fail the first time. Yes, you want to know about that and fix it. In the meantime, let's keep our system up and running.
So we want a service to occasionally throw a 503 error, and then have Istio retry the service. Hmmm... If only there was a way to throw a 503 error without changing our code.
Wait. Istio can do that. We just did that several paragraphs ago.
Using the following file, we'll have 503 errors being thrown by our "recommendation-v2" service half the time:
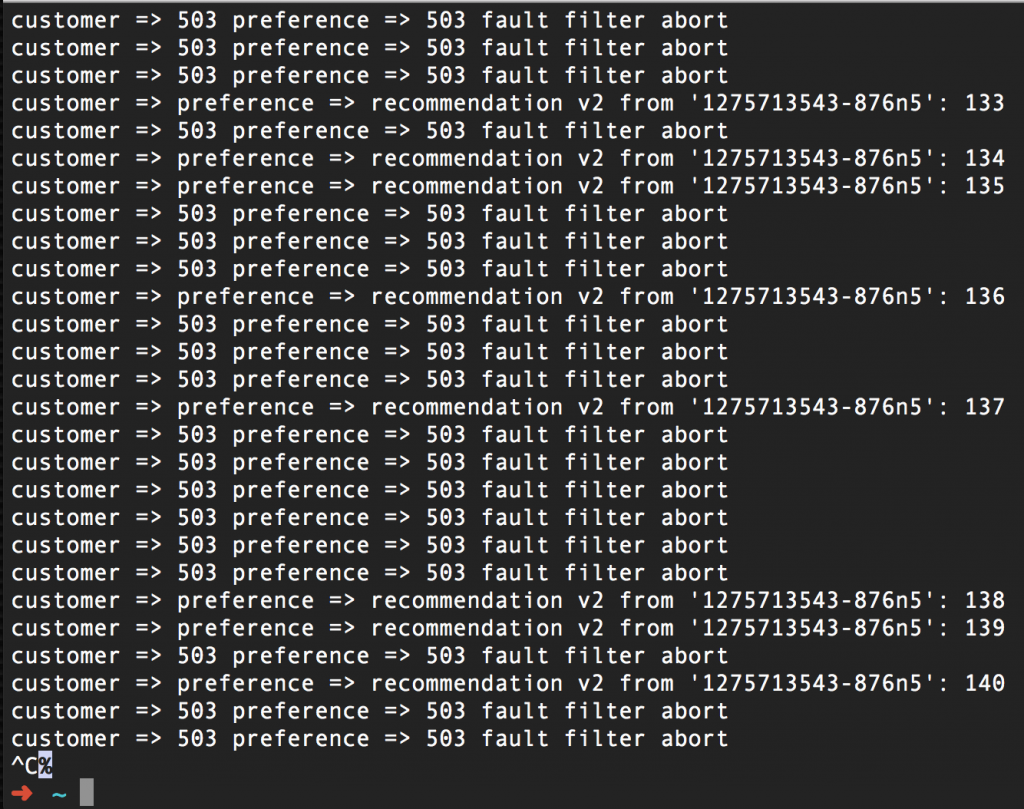
Sure enough, some requests are failing:
Now we can introduce the Retry feature of Istio, using this nifty configuration:
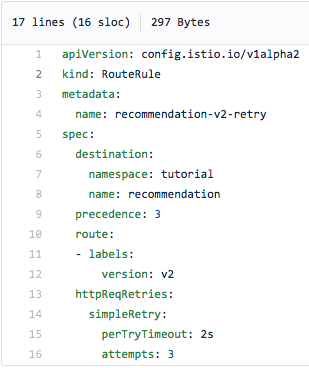
We've configured this route rule to retry up to 2-3 times, waiting two seconds between attempts. This should reduce (or hopefully eliminate) 503 errors:
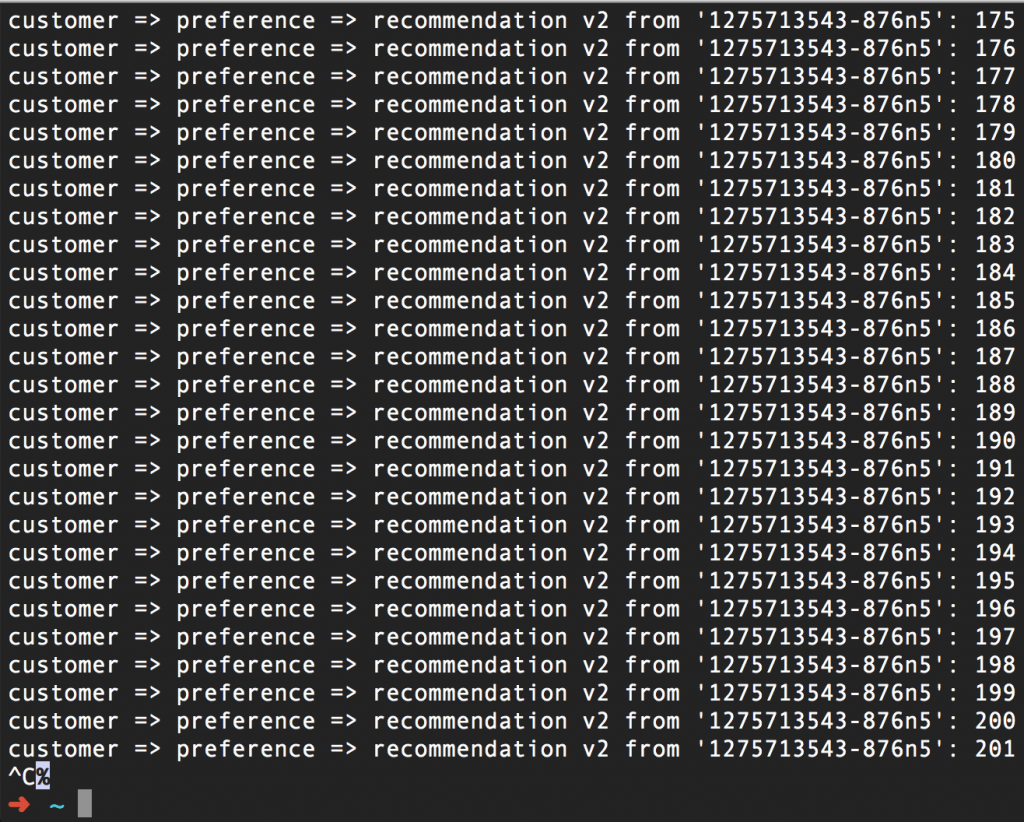
Just to recap: We have Istio tossing 503 errors for half of the requests, and we also have Istio performing three retries after a 503 error. As a result, everything is A-OK. By not giving up, but by using the Retry, we kept our promise.
Did I mention we're doing all this with no changes to our source code? I may have mentioned that. Two Istio route rules were all it took:

Never Gonna Let You Down
Now it's time turn around and do the opposite; we want a scenario where we're going to wait only a given time span before giving up and deserting our request attempt. In other words, we're not going to slow down everything while waiting for one slow service. Instead, we will bail out of the request and use some sort of fallback position. Don't worry dear website user... We won't let you down.
Istio allows us to establish a Timeout limit for a request. If the service takes longer than the Timeout, a 504 (Gateway Timeout) error is returned. Again, this is all done via Istio configuration. We did however add a sleep command to our source code (and rebuilt and redeployed the code in a container) to mimic a slow service. There's not really a no-touch way around this; we need slow code.
After adding the three-second sleep to our recommendation (v2 image and redeploying the container), we'll add the following timeout rule via an Istio route rule:
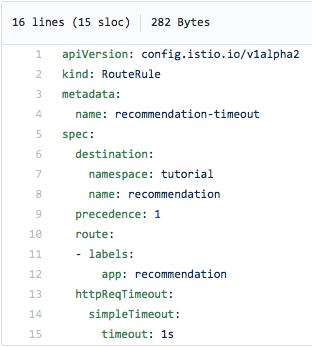
As you can see, we're giving the recommendation service one second before we return a 504 error. After implementing this route rule (and with the three-second sleep built into our recommendation:v2 service), here's what we get:
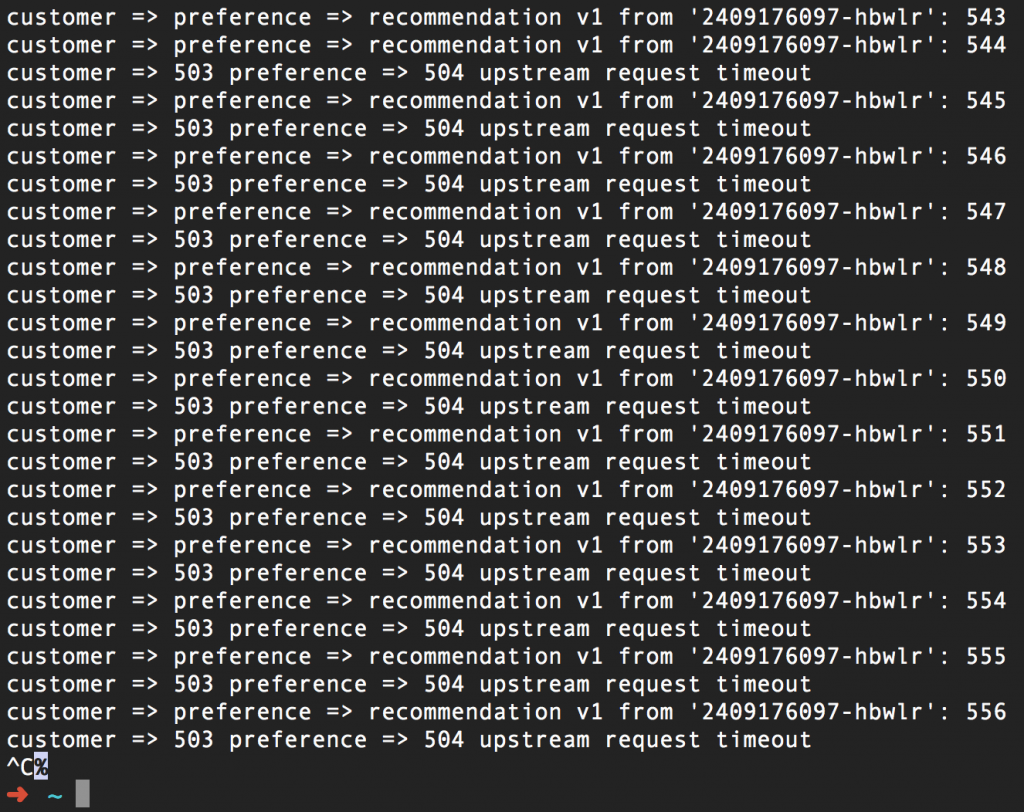
Where Have I Heard This Before?
Repeating, ad nauseam: we are able to set this timeout function with no changes to our source code. The value here is that you can now write your code to respond to a timeout and easily test it using Istio.
All Together Now
Injecting chaos into your system, via Istio, is a powerful way to push your code to the limits and test your robustness. Fallbacks, bulkheads, and circuit breaker patterns are combined with Istio's fault injection, delays, retries, and timeouts to support your efforts to build fault-tolerant, cloud-native systems. Using these technologies (combined with Kubernetes and Red Hat OpenShift), give you the tools needed to move into the future.
And to give yourself a break.
All articles in the "Introduction to Istio" series:
- Part 1: Introduction to Istio; It Makes a Mesh of Things
- Part 2: Istio Route Rules: Telling Service Requests Where to Go
- Part 3: Istio Circuit Breaker: How to Handle (Pool) Ejection
- Part 4: Istio Circuit Breaker: When Failure Is an Option
- Part 5: Istio Tracing & Monitoring: Where Are You and How Fast Are You Going?
- Part 6: Istio Chaos Engineering: I Meant to Do That
- Part 7: Istio Dark Launch: Secret Services
- Part 8: Istio Smart Canary Launch: Easing into Production
- Part 9: Istio Egress: Exit Through the Gift Shop
- Part 10: Istio Service Mesh Blog Series Recap