Post-training represents one of the most active areas in large language model (LLM) development today. While pre-training establishes a model’s general understanding of language and world knowledge, post-training transforms that general foundation into something useful, safe, and domain-specific. This overview explores the current landscape of post-training methods, from supervised fine-tuning and continual learning to parameter-efficient and reinforcement learning approaches. It concludes with a look at how to get started using these methods through the open source Training Hub library.
The basics: Pre-training
Every language model begins as a collection of randomly initialized parameters, a blank neural canvas. Pre-training is the process of filling that canvas with broad linguistic and semantic knowledge drawn from diverse text corpora.
The model starts with a vocabulary, a set of interpretable subwords or tokens that define its input and output space. Training proceeds by predicting the next token in a sequence given all tokens that came before it, a process known as next-token prediction.
In Figure 1, consider the simple sentence "The dog eats the apples." During pre-training, the model learns to predict each word in turn: given the, predict dog; given the dog, predict eats, and so forth.

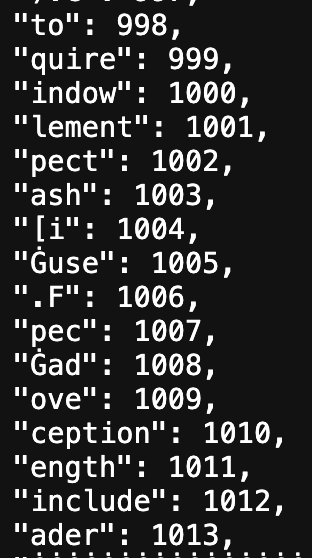
In practice, the tokens are rarely clean word boundaries. Figure 2 illustrates that subword tokenization often results in smaller, less readable fragments that still represent meaningful units to the model.
Through this process, the model learns the statistical relationships between tokens across billions of examples, enabling it to form coherent patterns, semantic links, and syntactic rules. As shown in Figure 3, the goal is to build a probability distribution over sequences that predicts the most likely next token given the preceding context. Once this general linguistic capability is established, post-training techniques can specialize and align the model for real-world tasks.
From language to utility: The role of post-training
Pre-training yields a model that can form sentences and predict plausible continuations. Post-training answers the question: how can this model be made useful?
Post-training encompasses methods that teach a model to:
- Follow human instructions
- Answer questions and reason through problems
- Align with safety, domain, or brand requirements
- Retain knowledge while learning new data
Supervised Fine-Tuning (SFT)
The most fundamental post-training method is supervised fine-tuning. The goal is simple: given an input sequence, train the model to produce a corresponding output sequence.
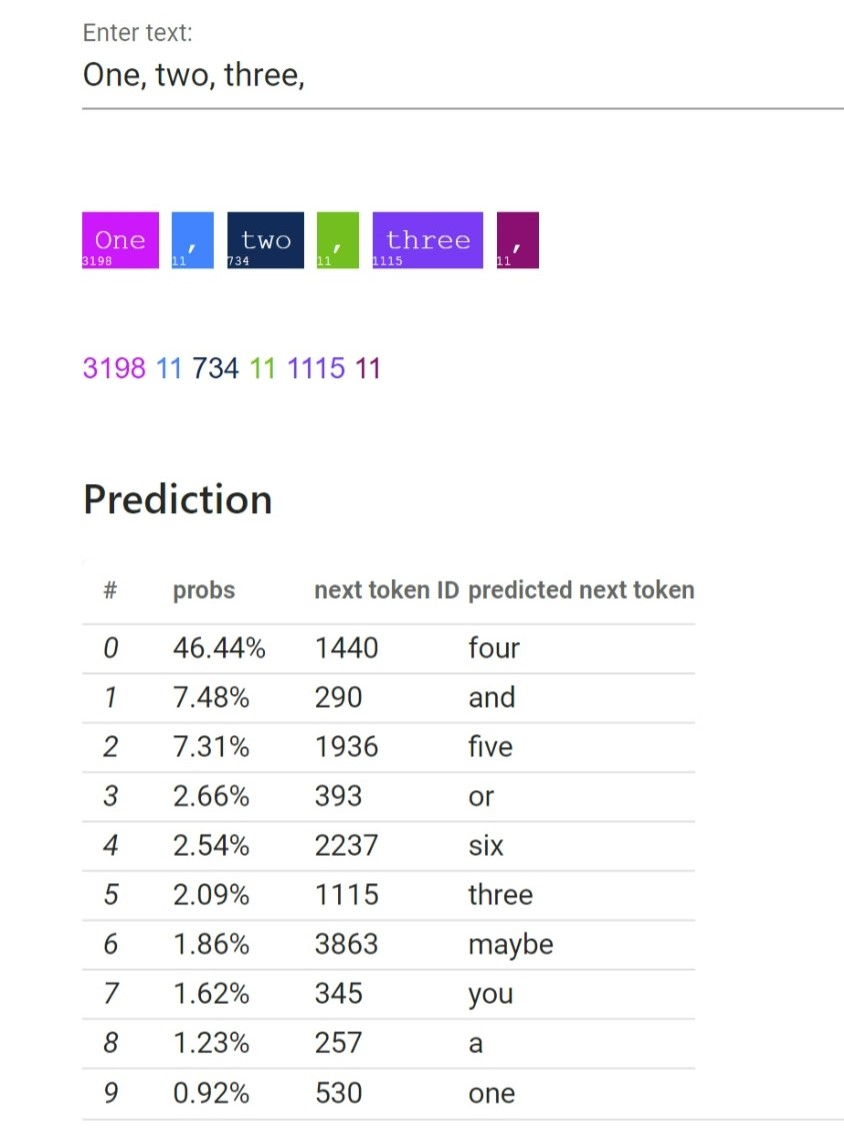
In Figure 4, an example input "What is the capital of France?" is paired with the target output "The capital is Paris." The model learns this generally through the same core next-token prediction, this time with the input as a pre-existing condition, and the output being the following learned sequence.

However, natural dialogue introduces a complication. The model must distinguish between the roles of participants, identifying what comes from the user versus what the model should generate. Without this distinction, the model cannot structure or even understand how to engage in multi-turn conversations correctly.
Messages-formatted data
To solve this, SFT relies on messages-formatted data, often referred to as instruction tuning or multi-turn chat tuning. Each message in a conversation is tagged by role (for example, user, assistant, system), enabling the model to understand who said what.
Under the hood, these roles are represented by special tokens that mark message boundaries. Figure 5 shows how user and assistant tokens are inserted to separate dialogue turns. Different model families define these tokens uniquely, leading to interoperability challenges illustrated in Figure 6.


To simplify user interaction, models implement a chat template, a translation layer that converts natural text into the appropriate tokenized format. Figure 7 demonstrates how a raw prompt like "What is the capital of France?" is transformed internally into user and assistant sequences.

When preparing SFT data, each training example becomes a JSON line containing a list of message dictionaries with role and content pairs. Here is a canonical example:
{
"Messages": [
{
"role": "user",
"content": "What is the capital of France?"
},
{
"role": "assistant",
"content": "The capital is Paris."
}
]
}This structure allows models to learn consistent dialogue patterns and participate in multi-turn exchanges effectively.
Continual learning
Once a model has been fine-tuned, organizations often need to extend it with new knowledge or domains over time, a process known as continual learning. For example, you might update a model with annual financial data or incorporating evolving internal documentation.
The challenge lies in catastrophic forgetting. During standard fine-tuning, all weights are updated, and new learning can overwrite old knowledge. Current research explores methods that preserve general performance while accommodating incremental updates.
Orthogonal Subspace Fine-Tuning (OSFT)
One promising solution is Orthogonal Subspace Fine-Tuning (OSFT), a continual-learning approach that targets the least important model weights for updating. By identifying which parameters contribute least to previous tasks and general model performance, OSFT minimizes forgetting while learning new information.
OSFT uses adaptive singular value decomposition (SVD) to decompose each weight matrix into ranked components. High-rank (large singular value) directions capture critical information, while low-rank components correspond to redundant or less significant details.
During OSFT, a threshold defined by the unfreeze rank ratio determines which parts of the model remain trainable. As shown in Figure 8, setting this ratio to 1 reverts to full fine-tuning, while 0 freezes all parameters. Typical use cases strike a balance (for example, 0.5), allowing the model to learn new tasks while retaining essential prior knowledge.
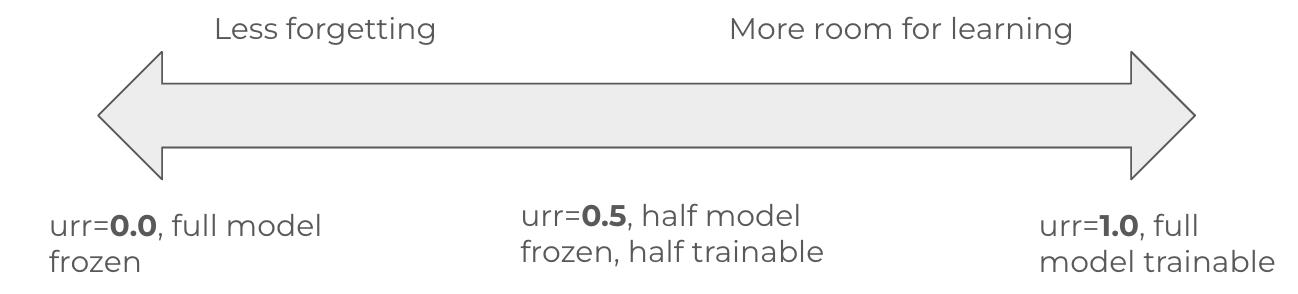
This tunable trade-off provides fine-grained control. Increasing the ratio improves learning capacity, while decreasing it protects existing performance.
Parameter-efficient fine-tuning (PEFT)
Parameter-efficient fine-tuning (PEFT) methods further reduce memory and compute costs by modifying only a small subset of parameters or adding lightweight trainable components. These methods are ideal when the base model already contains sufficient knowledge and only minor adaptations are needed.
Prompt tuning
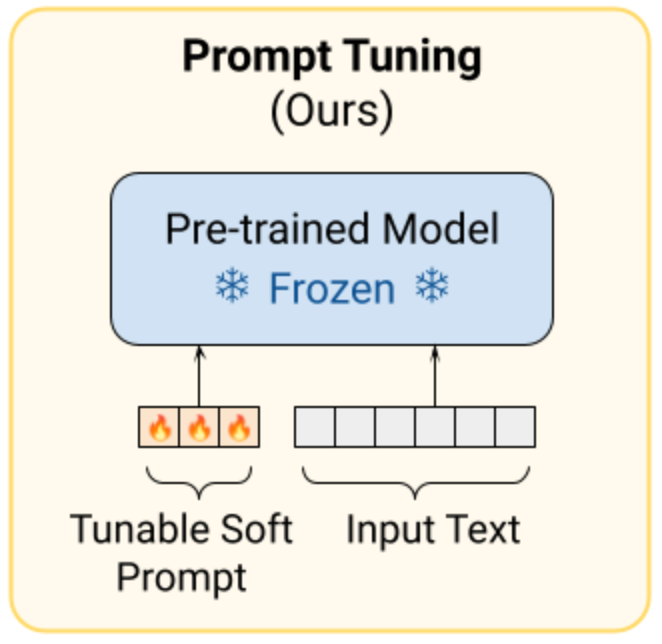
The simplest form of PEFT is prompt tuning (Figure 9). Instead of adjusting the model’s core weights, prompt tuning learns a small set of soft prompt vectors that are prepended to every input. These vectors act as a trainable instruction, guiding the model toward task-specific behavior without altering its internal representations.
Low-Rank Adaptation (LoRA)
A more expressive PEFT technique is Low-Rank Adaptation (LoRA) (Figure 10). LoRA injects small trainable matrices into existing model layers. These matrices approximate the weight updates that would occur during full fine-tuning but with a fraction of the parameters.
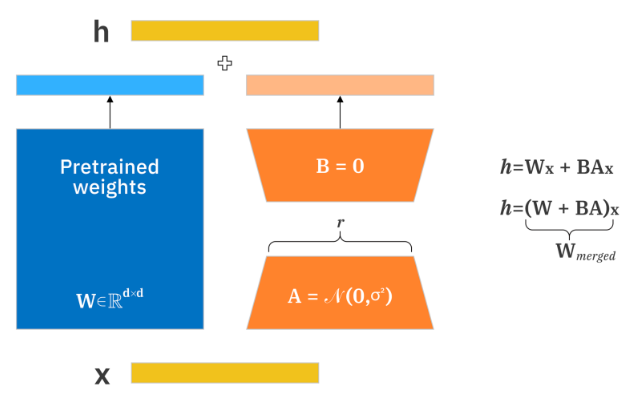
Under the hood (Figure 11), LoRA decomposes a full-rank weight update ΔW into the product of two smaller matrices A and B, such that ΔW ≈ A × B. This reduces the computational complexity from O(n²) to O(2n).
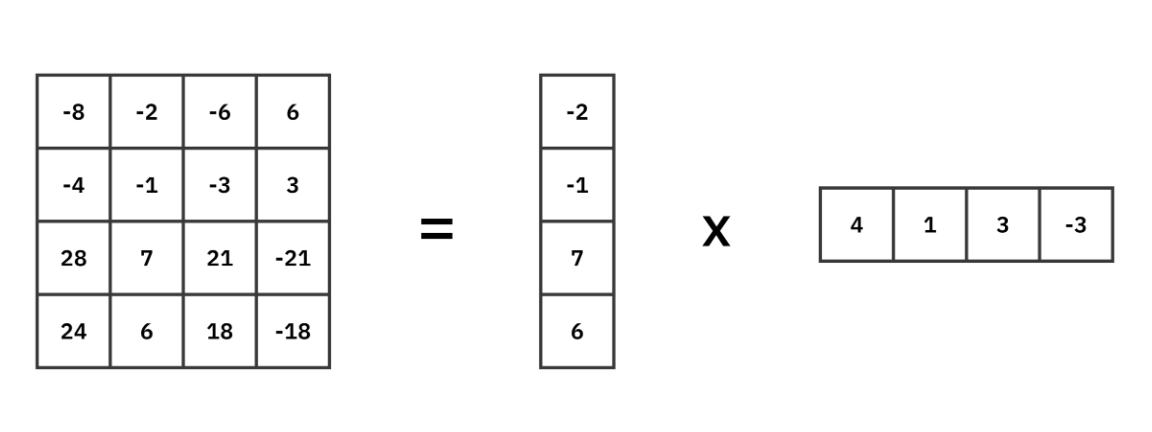
While the approximation limits capacity compared to full fine-tuning, LoRA is highly efficient, often achieving comparable performance on lightweight tasks with significantly less training data and hardware cost.
Modern extensions include QLoRA, which introduces quantization to further shrink memory usage, and OLoRA, which improves initialization stability through QR-based orthonormalization.
Reinforcement learning for language models
Another key branch of post-training is reinforcement learning (RL), where models improve through iterative feedback rather than static labels. RL enables guided exploration, helping models refine reasoning, factual accuracy, and alignment with human preferences.
Reinforcement learning basics
In classical RL (Figure 12), an agent interacts with an environment by taking actions, receiving rewards, and observing new states. Rewards quantify how desirable an output is according to predefined metrics or evaluators.
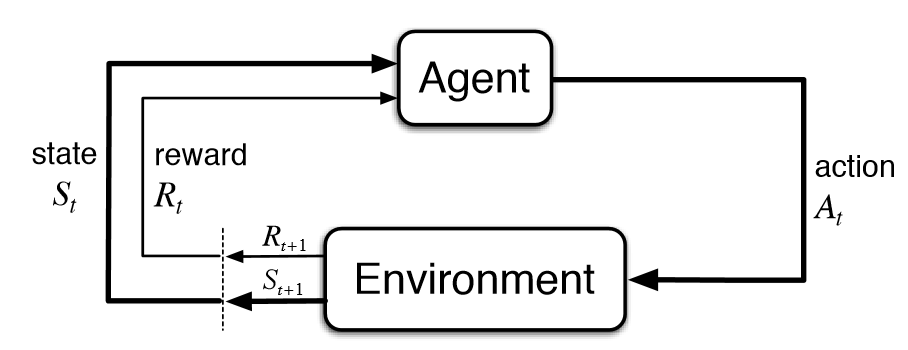
For example, consider the game chess. The state is simply the current board state. The agent (or model) takes an action by moving a piece. Based on this action, the agent receives a reward from the environment (or engine) based on how good the move was. The agent then also receives an updated board state after the opponent’s subsequent move. The goal of an RL system is to use that reward to guide the agent to make a better move, or action, moving forward. In the context of language models, actions instead correspond to generated token sequences, with the inputs serving as "state".
Rules-based verifiers
A practical way to apply RL to models is through rules-based verifiers. These deterministic evaluators automatically check whether a model’s response satisfies objective criteria (for instance, numeric correctness). This allows for scalable and automatic reward assignment, accelerating learning cycles. For example, a math-solving model might receive a reward of 1 for a correct answer and 0 otherwise. Through repeated interactions, it learns which reasoning patterns lead to higher expected rewards.
Group Relative Policy Optimization (GRPO)
One of the most common RL approaches for language and reasoning models today is Group Relative Policy Optimization (GRPO). As illustrated in Figure 13, GRPO begins by sampling multiple rollouts, different solution paths the model might take for a single prompt. Using a higher temperature encourages diversity in exploration.
A rules-based verifier evaluates each rollout, assigning rewards (in our example binary, 1 for correct, 0 for incorrect). These rewards are then normalized to compute advantages, which weight how strongly the model should prefer certain reasoning paths.
This strategy offers flexibility:
- For difficult tasks with few correct rollouts, the model heavily reinforces the rare successful paths.
- For easy tasks where many rollouts succeed, rewards are spread evenly to maintain creative diversity.
GRPO therefore improves both reasoning stability and correctness while preserving the model’s expressive capacity.
Emerging extensions such as Dr-GRPO and DAPO further refine training stability and reward normalization. Other reinforcement approaches, such as Direct Preference Optimization (DPO) for offline alignment and Reinforcement Learning from Human Feedback (RLHF) for interactive tuning, continue to advance the state of post-training research.
Beyond reinforcement learning
Post-training ties into a number of additional emerging areas such as:
- Model merging, which blends weights from multiple fine-tuned models to combine capabilities.
- Post-training compression, including quantization and sparsification, which reduce model size while maintaining accuracy.
- Inference optimization, focusing on serving, batching, and latency improvements.
Together, these form a complete lifecycle: pre-training for language mastery, post-training for specialization, and inference for efficient deployment.
Getting started with post-training
Developers can experiment with these algorithms today through the open source Training Hub, an abstraction layer providing unified access to modern post-training methods.
Training Hub offers a consistent Python interface that supports multiple community back end implementations for algorithms and training configurations. It is available on GitHub and installable from PyPI.
Currently, the library supports SFT and includes the first official OSFT implementation out of the box, with forthcoming support for reinforcement learning and parameter-efficient fine-tuning methods such as LoRA expected by the end of 2025.
Training Hub in action
Using Training Hub is straightforward. Each algorithm is represented as a Python function. For example, to perform supervised fine-tuning:
from training_hub import sft
sft(
model_path="/path/to/model", # or Hugging Face repo/name
data_path="/path/to/data",
ckpt_output_dir="/path/to/save/checkpoints",
num_epochs=3,
learning_rate=1e-5,
)This single function handles data loading, training, and checkpointing, as shown in the preceding code snippet. For advanced users, numerous configuration parameters are available (see example code snippet below) including batch size, maximum tokens per GPU, checkpoint intervals, and distributed training options. Multi-GPU training can be enabled by adjusting nproc_per_node, and multi-node training simply extends those settings across nodes.
# Prepare all training parameters
training_params = {
# Required parameters
'model_path': model_path,
'data_path': data_path,
'ckpt_output_dir': ckpt_output_dir,
# Core training parameters
'num_epochs': num_epochs,
'effective_batch_size': effective_batch_size,
'learning_rate': learning_rate,
'max_seq_len': max_seq_len,
'max_tokens_per_gpu': max_tokens_per_gpu,
# Data and processing parameters
'data_output_dir': data_output_dir,
'warmup_steps': warmup_steps,
# Checkpointing parameters
'checkpoint_at_epoch': checkpoint_at_epoch,
'save_samples': save_samples,
'accelerate_full_state_at_epoch': accelerate_full_state_at_epoch,
# Distributed training parameters
'nproc_per_node': nproc_per_node,
'nnodes': nnodes,
'node_rank': node_rank,
'rdzv_id': rdzv_id,
'rdzv_endpoint': rdzv_endpoint,
}For continual learning, the OSFT function provides the same interface (see the following example code snippet), introducing two additional parameters:
unfreeze_rank_ratiocontrols the proportion of trainable weights, as described earlier.osft_memory_efficient_initreduces overhead during SVD-based decomposition.
from training_hub import osft
osft(
model_path="/path/to/model", # or Hugging Face repo/name
data_path="/path/to/data",
ckpt_output_dir="/path/to/save/checkpoints",
unfreeze_rank_ratio=0.25, # <--- OSFT-specific
osft_memory_efficient_init=True, # <--- OSFT-specific
num_epochs=3,
learning_rate=1e-5,
effective_batch_size=16,
max_tokens_per_gpu=2048,
max_seq_len=1024,
)This modular design will extend to future algorithms such as LoRA or GRPO, each sharing a common configuration schema with minimal algorithm-specific additions.
Conclusion
Language model post-training has evolved into a diverse ecosystem of methods that adapt, align, and tune foundational models for practical use. From supervised fine-tuning to continual learning, parameter-efficient adaptation, and reinforcement learning, each approach addresses a different dimension of customization, such as accuracy, memory efficiency, safety, and adaptability.
With open source tools like Training Hub, these advanced techniques are now accessible to a broad developer community, which accelerates innovation in model alignment, reasoning, and deployment across enterprise and research environments.
Check out the Training Hub GitHub repository.