As organizations move from large language model (LLM) experimentation to production deployment, the choice of inference platform becomes a critical business decision. This choice impacts not just operational performance, and also flexibility, cost optimization, and the ability to adapt to rapidly evolving business needs.
vLLM, which stands for virtual large language model, is a library of open source code maintained by the vLLM community. It helps large language models (LLMs) perform calculations more efficiently and at scale.
Specifically, vLLM is an inference server that speeds up the output of generative AI applications by making better use of the GPU memory.
This article examines why vLLM's technical architecture and abilities, particularly its KV-Cache management, parallelization strategies, and with the upcoming llm-d distributed capabilities provides the most sustainable path for production LLM deployment.
The open source advantage
The evolution of LLM inference has been fundamentally shaped by open source innovation. vLLM has achieved remarkable success in supporting diverse models, features, and hardware back ends over the past 1.5 years, growing from a UC Berkeley research project into the default serving solution for open source AI. See Figure 1.
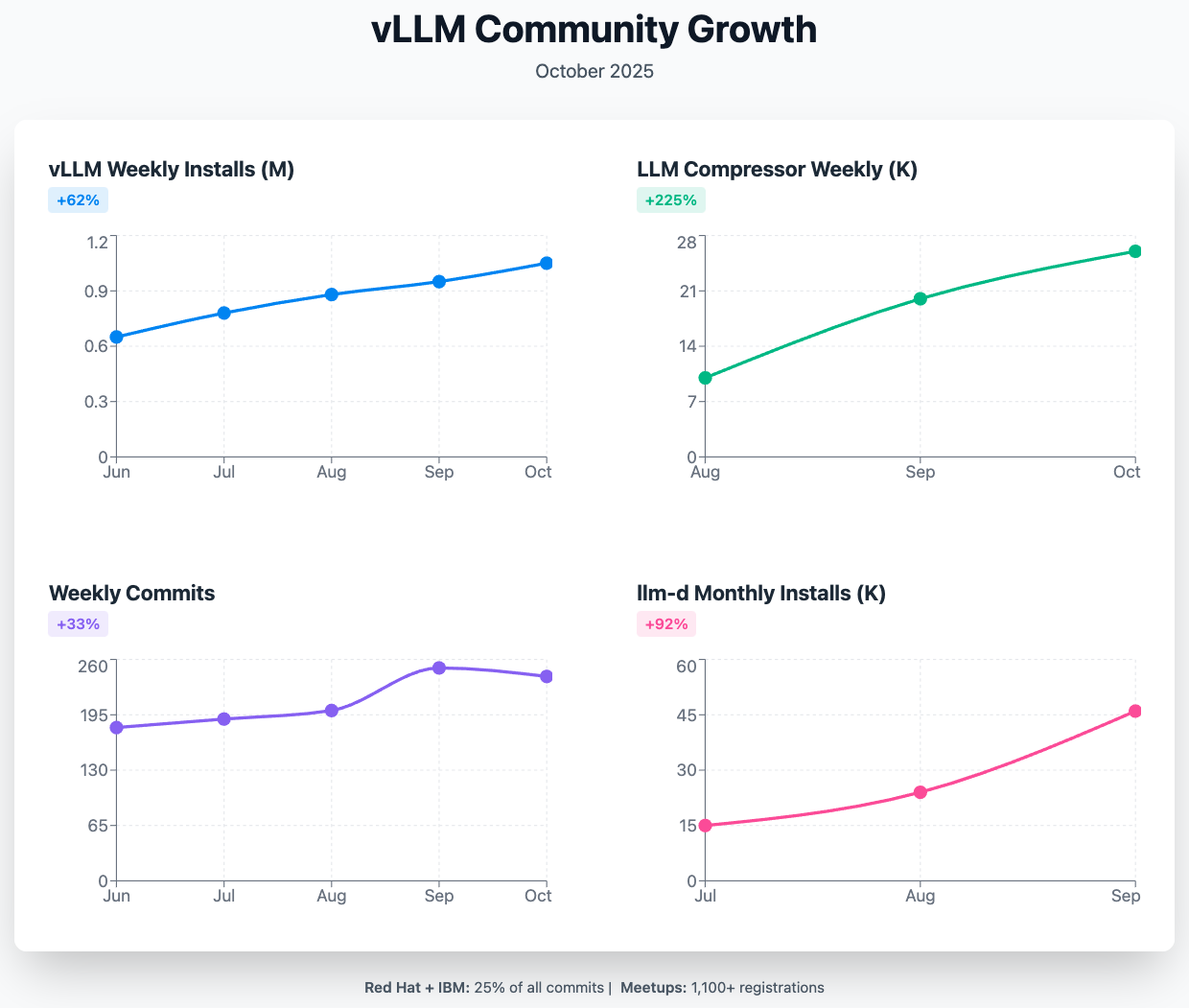
This transformation illustrates a critical advantage; open source projects can iterate and adapt faster than proprietary solutions. vLLM is now a hosted project under PyTorch Foundation, ensuring long-term sustainability and governance that enterprises require.
Enterprise support meets open innovation
Red Hat's approach to vLLM mirrors its successful Linux and Openstack strategy. We take community innovation and then add enterprise-grade support, security, and operational tooling. Vendor lock-in is replaced by transparent development, community contribution, and the flexibility to customize components for your specific requirements.
With vLLM, additional strategic advantages are possible:
- Hardware independence: Unlike TensorRT-LLM (NVIDIA-specific), vLLM supports NVIDIA GPUs, AMD CPUs and GPUs, Intel CPUs,GPUs and XPUs, PowerPC CPUs, and TPU.
- Rapid feature adoption: vLLM introduces a comprehensive re-architecture of its core components, including the scheduler, key-value (KV) cache manager, worker, sampler, and API server.
- Ecosystem integration: Native compatibility with Hugging Face, OpenAI APIs, and Kubernetes ecosystems.
- Cost optimization: Freedom to choose the most cost-effective hardware for specific workloads.
Architectural flexibility and parallelization strategies
An LLM presents unique scaling challenges. For example, a 70 billionB parameter model requires approximately 140 GB of memory just for weights in floating point 16 FP16 precision, far exceeding single accelerator capacities. Red Hat OpenShift AI addresses such challenges through four complementary parallelization strategies, each solving different scaling challenges.
Data parallelism: Scaling across models
Data parallelism (DP) represents the simplest scaling pattern, running complete model replicas across multiple servers, with each one processing a different batch of requests. This approach:
- Maintains full models: Each accelerator or server holds the complete model weights.
- Distributes requests: Load balancers distribute incoming requests across replicas.
- Enables linear scaling: Adding servers proportionally increases throughput.
- Simplifies deployment: No model sharding complexity.
Each server has a complete model copy, and different requests are processed in parallel (Figure 2).
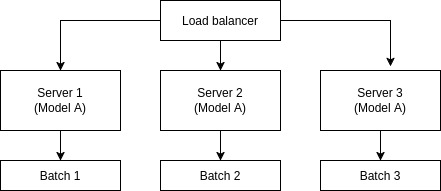
This pattern works exceptionally well with Red Hat OpenShift AI's model serving capabilities. Based on KServe with ReplicaSets for model copy serving, this enables automatic scaling based on request load while maintaining model serving simplicity.
Pipeline parallelism: Layer-wise distribution
Pipeline parallelism (PP) faces challenges with most modern LLMs. Inter-stage data transfer becomes a bottleneck, GPUs idle while waiting for data from previous stages, and each stage adds latency, impacting time-to-first-token. Furthermore, a mixture of experts (MoE) architecture with selective activation doesn't map cleanly to sequential pipeline stages.
These limitations have led many production deployments to favor tensor parallelism for intra-node scaling and data parallelism for inter-node scaling, though PP still has value in specific scenarios like memory-constrained environments or when combined with other parallelization strategies.
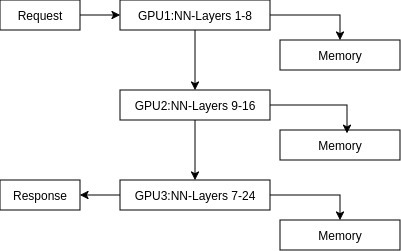
Pipeline parallelism divides the model by layers, with different accelerators handling different neural network layers. It's a technique vLLM uses to provide the following (shown in Figure 3):
- Sequential processing: Requests flow through GPUs in sequence.
- Memory balance: Distributes memory requirements evenly.
- Flexible deployment: Spans multiple nodes without high-speed interconnects.
- Micro-batching: Maintains GPU utilization through careful scheduling.
Tensor parallelism: Distributing model weights
vLLM's tensor parallel (TP) implementation is hardware-agnostic, supporting various interconnect technologies across different accelerator types. For models too large for a single accelerator, tensor parallelism splits model weights across multiple GPUs:
- Horizontal layer splitting: Each matrix multiplication is distributed across GPUs.
- Synchronized computation: GPUs communicate through high-speed interconnects (NVLink, infinity fabric).
- Memory efficiency: Enables serving models 4-8x larger than single GPU capacity.
- Low latency: Minimal communication overhead with proper hardware.
A traditional matrix operation looks like Figure 4.
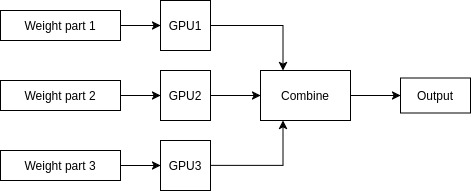
Original Matrix Operation:
[Large Weight Matrix] × [Input] = [Output]A single matrix operation split across GPUs, assuming a high-speed interconnect (NVLink), accomplishes this instead (Figure 5).

Expert parallelism: Distributing MoE experts across nodes
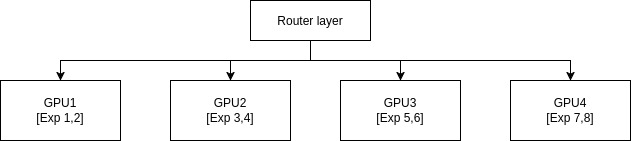
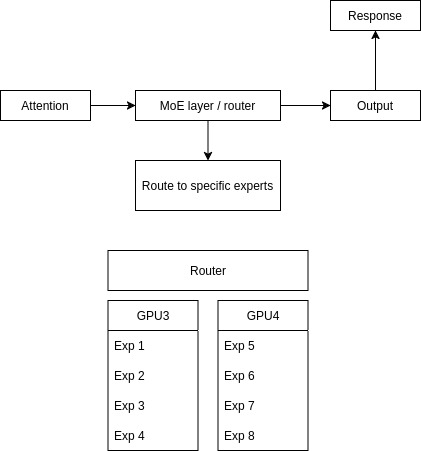
For mixture-of-experts (MoE) architectures, expert parallelism (EP) distributes individual experts across multiple GPUs or nodes. Instead of every GPU holding all experts, each device stores only a subset, and a router layer dynamically dispatches tokens to the appropriate experts (Figure 6).
- Distributed expert sharding: Experts are partitioned across GPUs and nodes, allowing models with hundreds of experts to scale far beyond single-device memory limits.
- Dynamic token routing: Each token is sent only to its assigned expert, reducing compute overhead compared to dense model execution.
- Expert parallel load balancing (EPLB): Prevents "hot" experts from overloading by dynamically replicating or redistributing popular experts.
- Hierarchical scheduling: In multi-node clusters, routing and replication are coordinated first across nodes and then across GPUs within each node, ensuring even utilization and minimal inter-node traffic.
- Performance gains: Enables higher throughput and efficiency for large-scale MoE models, maintaining near-linear scaling on high-speed interconnects (NVLink, InfiniBand).
vLLM's unified approach
What distinguishes vLLM is its ability to combine these strategies seamlessly. vLLM supports tensor, pipeline, data and expert parallelism for distributed inference.
You can scale dynamically, starting with a single-node deployment and growing as needed, and devise a mixed strategy, using tensor parallelism within nodes, and pipeline parallelism across nodes. You can also optimize your implementation based on available interconnects and GPU memory, and you use the same API regardless of your parallelization strategy.
This flexibility is critical when you deploy across hybrid cloud environments where hardware configurations vary between on-premises and cloud deployments.
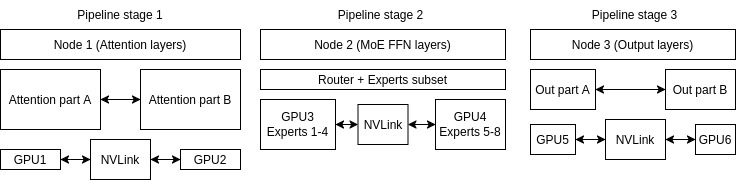
A hybrid TP+PP+EP+DP deployment (MoE model) could look like Figure 7.
The request flow is illustrated in Figure 8.
A summary of each method:
- Tensor parallel (TP): Attention and Output layers split within nodes.
- Pipeline parallel (PP): Different model stages across nodes .
- Expert parallel (EP): MoE experts distributed across GPUs in Node 2.
- Data parallel (DP): Entire pipeline can be replicated for more throughput.
Better memory management with KV cache
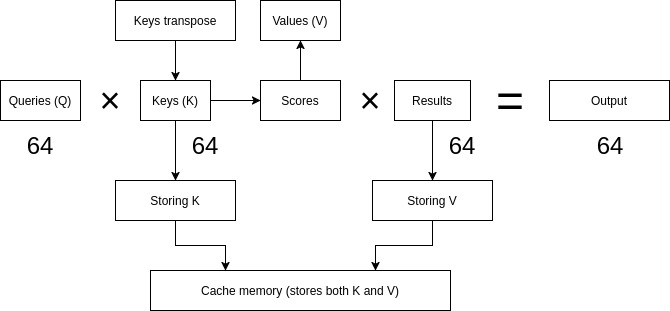
The KV cache represents one of the most critical features in LLM inference optimization. During attention computation, a model must access previous token representations. This process becomes memory-intensive as sequence lengths grow.
Efficient KV cache management can mean the difference between serving ten concurrent users or 100 on the same hardware at the same time, because cache reuse trades computation for memory efficiency.
Step 1 is the prefill stage (Figure 9).
For each new token, the decode phase must occur (Figure 10).
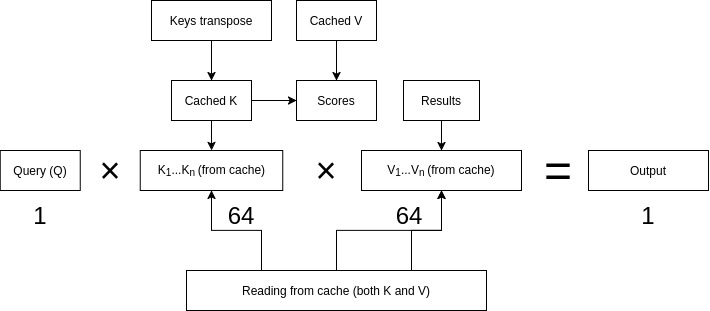
To summarize the process:
- Prefill: Computes K and V for all input tokens, stores both in cache
- Decode: For each new token, reads ALL previous K and V values from cache
- Both K and V matrices must be cached (not just V)
- Cache size grows with sequence length
Prefill and decode: Two distinct phases
LLM inference consists of two fundamentally different phases: Prefill and decode.
Prefill phase (prompt processing):
- Processes all input tokens in parallel.
- Compute-intensive with high GPU utilization.
- Generates initial KV cache entries for all prompt tokens.
- Latency proportional to prompt length.
- Benefits from larger batch sizes.
Decode phase (token generation):
- Generates one token at a time, sequentially.
- Memory-bandwidth bound operation.
- Reads the entire KV cache for each new token.
- Latency proportional to number of output tokens.
- Benefits from efficient cache management.
PagedAttention: vLLM's memory breakthrough
vLLM introduced PagedAttention, a breakthrough in KV cache management that treats GPU memory like virtual memory in operating systems. This has several useful features:
- Non-contiguous storage: KV cache blocks can be stored anywhere in GPU memory.
- Dynamic allocation: Memory allocated only as sequences grow.
- Memory sharing: Identical prompt prefixes share KV cache blocks.
- Near-zero waste: Eliminates internal fragmentation common in static allocation.
This design allows vLLM to sustain much larger batch sizes, higher concurrency, and better GPU utilization than systems that rely on static, monolithic KV cache buffers.
Continuous batching: Maximizing GPU utilization
Traditional static batching waits for all sequences in a batch to complete before processing new requests. vLLM's continuous batching features:
- Dynamic request addition: New requests join running batches between decoding steps.
- Early completion handling: Finished sequences free resources instantly.
- Optimal GPU usage: Maintains high utilization by mixing prefill and decode operations.
- Preemption support: Can pause low-priority requests for urgent ones.
Practical implications for deployment
These memory management innovations translate to concrete operational benefits. With vLLM, you get high concurrency so you can serve more users with the same hardware, while significantly reducing infrastructure requirements. There's improved latency, too, so you get faster time-to-first-token through efficient scheduling. The end result is greater flexibility so you can handle varying sequence lengths without reconfiguration.
The KVcache optimizations are even more critical with the upcoming llm-d distributed architecture, where efficient memory usage enables new deployment patterns previously impossible with traditional approaches.
Scaling with llm-d: Kubernetes-native distributed inference
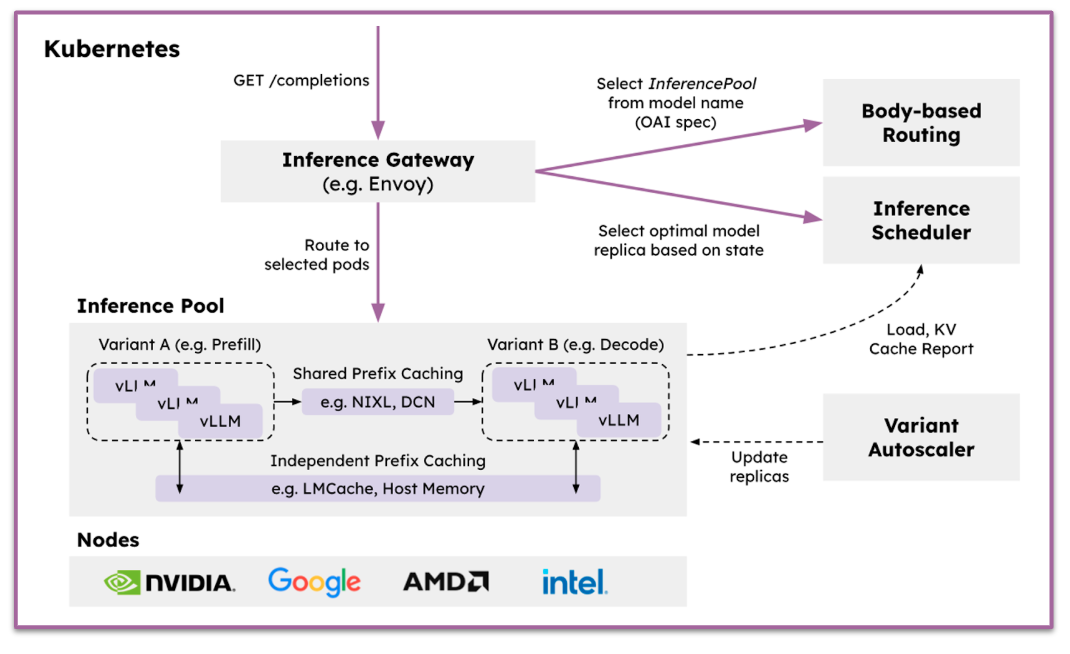
While vLLM excels as a high-performance inference engine, production deployments at scale require sophisticated orchestration and intelligent request routing. The llm-d project, launched in May 2025 by Red Hat, Google Cloud, IBM Research, NVIDIA, and CoreWeave, addresses this by providing a Kubernetes-native distributed serving stack built on top of vLLM.
llm-d is not a feature of vLLM, it's a complementary orchestration layer. Think of it like the relationship between Linux and Kubernetes: vLLM provides the inference engine, while llm-d provides distributed orchestration and intelligent scheduling across multiple vLLM instances. llm-d integrates three foundational open source technologies into a unified serving stack:
- vLLM: The high-performance inference engine that executes model inference.
- Inference Gateway (IGW): An official Kubernetes project extending Gateway API with AI-aware routing.
- Kubernetes: The industry-standard orchestration platform for deployment and scaling.
By combining these technologies, llm-d enables organizations to deploy LLM inference at scale across hybrid cloud environments with the fastest time-to-value and competitive performance per dollar.
Beyond single-server deployment
In addition, there's llm-d integration through a new LLMInference CRD in KServe (Figure 11). This provides a single and coherent API that unifies the serving experience across use cases and maturity levels, supporting a smooth journey into generative AI for enterprise users.
Intelligent inference scheduling
Traditional load balancing uses simple round-robin routing, treating all servers equally. llm-d's vLLM-aware scheduler makes intelligent decisions by routing requests to instances with matching cached prefixes, distributing load based on whether instances are handling compute-intensive prefill or memory-bound decode operations, and using real-time telemetry from vLLM to avoid overloaded instances while prioritizing low-latency paths. This intelligent routing reduces infrastructure costs by 30% to 50% while maintaining latency service-level objectives.
Disaggregated serving
llm-d orchestrates vLLM's native disaggregated serving (through the KVConnector API) at production scale, separating prefill and decode across specialized workers:
- Prefill workers: Handle compute-intensive prompt processing on high-performance GPUs (H100s, MI300X) and scale independently based on demand.
- Decode workers: Focus on memory-bound token generation using cost-effective GPUs (A100s, L40S) and scale based on concurrent sessions.
- KV cache transfer: Provides efficient cache movement using NVIDIA NIXL over UCX, support for offloading to storage backends (future delivery), and global cache awareness across the cluster.
This allows right-sizing infrastructure: Expensive GPUs only for prefill, cost-optimized hardware for serving thousands of concurrent users.
Distributed prefix caching
llm-d extends vLLM's prefix caching across multiple instances with two approaches. Local caching offloads to memory and disk on each instance with zero operational cost, and shared caching () allows KV transfer between instances with global indexing for cluster-wide cache awareness.
Deployment patterns
llm-d enables several advanced enterprise patterns:
- Heterogeneous hardware: Mix GPU vendors and generations based on workload. You can dedicate high-end GPUs for prefill, cost-optimized GPUs for decode, or CPU clusters for low-frequency requests.
- Dynamic scaling: Independently adjust prefill capacity during peak hours while maintaining steady decode capacity for active sessions, with automatic resource allocation and failover.
- Geographic distribution (on the llm-d project roadmap): Deploy centralized prefill workers in primary data centers with edge decode workers near users for low-latency responses.
Integration with Red Hat OpenShift AI
OpenShift AI provides enterprise packaging for llm-d with unified deployment with KServe for all components, service mesh routing between workers, full observability with pre-built dashboards, and GitOps configuration management. Enterprise security features include consistent RBAC policies, encrypted communication between workers, audit logging for distributed flows, and network policy enforcement.
There are several operational benefits to using vLLM, as well:
- Cost optimization: Two to three times better GPU utilization and 40% to 60% less over-provisioning.
- Scalability: Independent scaling of components, proven to 100+ node deployments.
- Resilience: Failure isolation between phases, automatic failover, graceful degradation.
Break free from hardware lock-in
The rapid evolution of AI accelerators has created a diverse hardware landscape. While specialized solutions like TensorRT-LLM deliver special optimizations for NVIDIA GPUs, they create vendor lock-in that limits deployment flexibility. vLLM's hardware-agnostic design provides freedom to choose the optimal accelerator for each use case.
Comprehensive hardware support
vLLM supports:
- NVIDIA GPUs (first-class optimizations for H100, with support for every NVIDIA GPU from V100 and newer)
- AMD GPUs (MI200, MI300, and Radeon RX 7900 series)
- Google TPUs (v4, v5p, v5e, and the latest v6e)
- AWS Inferentia and Trainium (trn1/inf2 instances)
- Intel Gaudi (HPU) and GPU (XPU)
- and CPUs featuring support for x86, ARM, and PowerPC
This broad support enables several strategic advantages. You might, for instance, choose AMD MI300X for price and performance on certain workloads, or use AWS Inferentia for cost-effective inference on AWS, or deploy on existing CPU infrastructure for low-throughput use cases.
It also makes your supply chain more resilient by avoiding a dependency on a single GPU vendor, allowing you to negotiate better pricing and choose from multiple options and from hardware most readily available in your region.
This flexibility allows you to build an environment that's right for your workload, whatever the reason might be. For example:
- NVIDIA H100s for maximum performance.
- AMD GPUs deployments prioritizing open source.
- TPUs for Google Cloud deployments.
- Intel Gaudi for specific enterprise agreements.
Hybrid cloud deployment patterns
vLLM on Red Hat OpenShift AI enables true hybrid cloud flexibility. For on-premises deployment, you keep your sensitive data processing on your local infrastructure, and you can ensure that your workloads are designed for compliance requirements. You also get a predictable capacity for your baseline workload. When it's time for cloud burst scaling, you can handle peak loads with cloud resources, and implement geographic expansion without infrastructure investment. Alternatively, you can experiment with new hardware (H100s, TPU v6e).
On the edge, you can deploy on appropriate hardware and use CPU or smaller GPU inference. And of course, thanks to Red Hat Edge Manager, it's all integrated with central management.
Unified operations across environments
Red Hat OpenShift AI provides consistent operations regardless of deployment location (public or private cloud):
- Single control plane: Manage all deployments from a unified interface.
- Consistent API: Same application integration across environments.
- Unified monitoring: Aggregated metrics across hybrid deployments.
- Policy enforcement: Consistent security and compliance policies.
Every industry has its own set of unique requirements. With the flexibility of an infrastructure using vLLM, it's easy to architect something especially for the needs of a specific industry. Here are some examples.
Financial services:
- On-premises NVIDIA GPUs for sensitive data processing.
- AWS Inferentia for public-facing chatbots.
- CPU inference for branch edge deployments.
Healthcare provider:
- AMD MI300X in private cloud for cost optimization.
- Google TPUs for research workloads.
- Intel CPUs for clinical decision support.
Retail organization:
- Centralized GPU clusters for training and complex inference.
- Edge CPU deployment in stores.
- Cloud scaling for seasonal peaks.
This hardware and deployment flexibility ensures that architectural decisions made today won't constrain options tomorrow, a critical consideration as the AI hardware landscape continues to evolve rapidly.
Model ecosystem and compatibility
vLLM has evolved to support performant inference for more than 100 model architectures. This spans nearly every prominent open source large language model, multimodal (image, audio, video), encoder-decoder, speculative decoding, classification, embedding, and reward models. This comprehensive support represents a fundamental advantage over specialized solutions that focus on limited model families.
Beyond the traditional LLM
vLLM's architecture supports diverse model types.
Language models:
- IBM's Granite series.
- Mistral and Mixtral MoE models.
- Llama family (including Llama 3.1 405B).
- Google's Gemma models.
- Alibaba's Qwen models.
Multimodal models:
- Vision-language models (LLaVA, Qwen-VL).
- Document understanding models.
- Audio-language models.
- Video understanding capabilities.
Ease of model integration
Adding new models to vLLM follows a standardized process:
- Model architecture definition: Implement using familiar PyTorch patterns.
- Attention backend integration: Leverage existing optimized kernels.
- Tokenizer support: Direct Hugging Face compatibility.
- Configuration mapping: Standard YAML-based configuration.
This standardization means new models can often be added timely, which is critical for organizations wanting to experiment with latest models. A great example for vLLM’s agility to adapt to the changing model landscape would be introducing a support for gpt-oss, which was released August 5, 2025, and shortly after, vLLM v0.11.0 release included support for serving it in production environments.
Hugging Face ecosystem integration
vLLM offers native Hugging Face compatibility, simplifying model loading, tokenizer use, and configuration preservation. This allows for direct loading of models from Hugging Face Hub and S3, supports existing and custom tokenizer implementations with optimizations, and ensures compatibility with model-specific configurations and fine-tuned variants.
Comprehensive model support ensures organizations can adopt new models as they emerge, without platform migrations or architectural changes a critical capability as the AI landscape continues its rapid evolution.
Enterprise deployment with Red Hat OpenShift AI
Red Hat OpenShift AI is a flexible, scalable MLOps platform with tools to build, deploy, and manage AI-enabled applications. Built using open source technologies, it provides trusted, operationally consistent capabilities for teams to experiment, serve models, and deliver innovative apps. Read more about how OpenShift AI is solving this challenge in Accelerating generative AI adoption: Red Hat OpenShift AI achieves impressive results in MLPerf inference benchmarks with vLLM runtime.
KServe integration: Intelligent model serving
The integration between vLLM and KServe within OpenShift AI provides enterprise-grade serving capabilities.
Gen AI features
vLLM's gen AI features include multi-node/multi-GPU inference with its serving runtime, Key-Value cache offloading with vLLM + LMCache integrations, and efficient model reuse via Model Cache. It also offers KEDA integration for autoscaling based on external metrics, rate-limiting and request routing through Envoy AI Gateway integration, and access to llm-d capabilities via the LLMInferenceService CRD.
Advanced autoscaling
Advanced autoscaling in vLLM provides request-based scaling for optimal resource usage, scale-to-zero capabilities for cost optimization, predictive scaling based on traffic patterns, and multi-metric scaling considering GPU utilization, queue depth, and latency.
Traffic management
Traffic management features include canary deployments for safe model updates, blue-green deployments for instant rollback, A/B testing for model comparison, and shadow traffic for validation.
Service mesh integration
Service mesh integration offers end-to-end encryption with Istio, advanced routing and load balancing, circuit breaking and retry logic, and distributed tracing for debugging.
Automated operations
Of course there's important automation that's possible, too. Streamline tasks that would otherwise be repetitive, and prone to error, so you and your teams can focus on strategic initiatives with the confidence that maintenance isn't being neglected:
- Health checking and automatic recovery
- Resource optimization recommendations
- Automated certificate management
- Log aggregation and analysis
Security and compliance
Enterprise deployments require robust security.
Access control:
- RBAC integration with enterprise identity providers
- Model-level access permissions
- API key management
- Audit logging for all operations
Data protection:
- Encryption at rest and in transit
- Private endpoint options
- Network policy enforcement
- Compliance reporting tools
Supply chain:
- Signed container images
- Software Bill of Materials (SBOM) generation
- Vulnerability scanning
- Policy-based deployment controls
MLPerf-validated performance
Red Hat, in collaboration with Supermicro, has made significant strides in addressing this challenge through the publication of impressive MLPerf inference results using Red Hat OpenShift AI with NVIDIA GPUs and the vLLM inference runtime. These results validate:
- Production-grade performance at scale
- Efficient resource utilization
- Consistent latency under load
- Multi-instance coordination capabilities
Integrated observability
Comprehensive monitoring without additional tooling.
Metrics and dashboards:
- Pre-built Grafana dashboards for vLLM metrics
- Pre-built Grafana dashboard for request scheduler metrics driving routing decisions
- Token generation rates and latencies
- GPU utilization and memory usage
- Queue depths and rejection rates
Alerting and response:
- Automated alerts for SLA violations
- Integration with enterprise monitoring systems
- Runbook automation capabilities
- Capacity planning insights
Cost management and optimization
Planned features designed for enterprise cost control:
- Chargeback and showback: Track usage by team or project
- Resource quotas: Prevent runaway costs
- Spot instance support: Reduce costs for batch workloads
- Idle detection: Automatically scale down unused resources
This enterprise-grade platform transforms vLLM from a high-performance inference engine into a complete production solution, ready for mission-critical deployments.
Feature comparison: vLLM versus TGI versus TensorRT-LLM
| Feature category | OpenShift AI with vLLM | TGI | TensorRT-LLM |
|---|---|---|---|
| Core optimization features | |||
| Continuous batching | ✓ | ✓ | ✓ |
| PagedAttention | ✓ | ✓ | ✓ |
| KV-Cache optimization | ✓ Advanced | ◐ Basic | ✓ |
| Prefill/Decode optimization | ✓ | ◐ | ✓ |
| Speculative decoding | ✓ | ✓ | ✓ |
| FlashAttention support | ✓ v2 & v3 | ✓ v2 | ✓ |
| Parallelization strategies | |||
| Data parallelism | ✓ | ✓ | ✓ |
| Tensor parallelism | ✓ | ✓ | ✓ |
| Pipeline parallelism | ✓ | ◐ | ✓ |
| Expert parallelism (MoE) | ✓ | ◐ | ✓ |
| Distributed deployment | |||
| Distributed serving (llm-d) | ✓ llm-d | ✗ | ✓ |
| Disaggregated prefill/decode | ✓ | ✗ | ✓ |
| Cross-region deployment | ✓ | ◐ | ◐ |
| Hardware ecosystem support | |||
| NVIDIA GPUs | ✓ V100+ | ✓ | ✓ Optimized |
| AMD GPUs | ✓ MI200/300 | ✓ ROCm | ✗ |
| Intel Gaudi/GPU | ✓ | ◐ | ✗ |
| Google TPUs | ✓ v4/v5/v6e | ✓ | ✗ |
| AWS Inferentia | ✓ | ✓ | ✗ |
| CPU support | ✓ x86/ARM/PowerPC | ◐ | ✗ |
| Model ecosystem | |||
| Supported model count | >100 architectures | ~40 models | ~60 models |
| Multimodal models | ✓ | ◐ | ◐ |
| State-space models | ✓ | ✗ | ✗ |
| Custom model integration | ✓ Easy | ◐ Moderate | ✗ Complex |
| Enterprise readiness | |||
| Active development & product support | ✓ | ✗ | ✓ |
| Open source license | ✓ Apache 2.0 | ✓ Apache 2.0 | ✓ Apache 2.0 |
| Kubernetes native | ✓ | ✓ | ◐ |
| OpenAI API compatible | ✓ | ✓ | ◐ Via Triton |
| Red Hat OpenShift AI | ✓ Native | ◐ | ✗ |
| Autoscaling support | ✓ KServe | ✓ | ◐ |
| Quantization support | |||
| GPTQ | ✓ | ✓ | ✓ |
| AWQ | ✓ | ✓ | ✓ |
| FP8 | ✓ | ◐ | ✓ |
| INT4/INT8 | ✓ | ✓ | ✓ |
Key differentiators for OpenShift AI with vLLM
- Hardware flexibility: Broadest accelerator support including AMD, Intel, Google TPUs, and CPUs
- Model ecosystem: Supports more than 100 model architectures (compared to 25-40 in alternative solutions)
- Distributed architecture: Upcoming llm-d enables disaggregated prefill/decode and system wide kv-cache routing for distributed optimal scaling
- Enterprise integration: Native Red Hat OpenShift AI support with KServe autoscaling
- Memory efficiency: Advanced PagedAttention and KV-Cache management
- Open development: PyTorch Foundation project with rapid community innovation
Conclusion
The choice of LLM inference platform represents a strategic commitment that will impact your organization's AI capabilities for years to come. Our analysis demonstrates that vLLM on Red Hat OpenShift AI uniquely addresses the three critical requirements for enterprise LLM deployment:
- Flexibility: Deploy on any hardware (NVIDIA, AMD, Intel, TPUs) across hybrid clouds.
- Scalability: Advanced memory management and upcoming llm-d architecture enable 10-100x better resource utilization.
- Sustainability: Open source foundation with enterprise support eliminates vendor lock-in.
While TensorRT-LLM offers NVIDIA-specific optimizations and TGI provides Hugging Face integration, only vLLM delivers the architectural flexibility required for a rapidly evolving AI landscape. With support for over 100 model architectures, hardware-agnostic design, and the backing of both PyTorch Foundation, OpenShift AI with vLLM provides the most robust foundation for long-term success.
Explore our OpenShift AI learning paths and visit the OpenShift AI product page to learn more.