Operators are the standard way to package software and to automate day 1 and 2 operations for applications running on Red Hat OpenShift. Even the platform itself is based on cluster operators that encapsulate a single aspect of the OpenShift platform (e.g., how to deploy and update the DNS, API server, etc.), database or the internal registry. There is also a huge ecosystem of third party providers that are delivering their software via an operator.
The general idea behind the concept of operators is to automate installation, updates, backups, configuration, and many other operational tasks that are specific to the application the operator is managing. A concept that will also be useful for managing your own applications on the OpenShift platform. But how to start writing your own operator?
This article provides a conceptual, technology-agnostic overview on how to design an operator that will leverage the REST API of your application.
Why should we care about writing an operator to manage REST resources?
With the adoption and success of Kubernetes, more and more modern applications are designed to run on top of Kubernetes and use its numerous capabilities such as resiliency, scalability, and high availability. The level of integration varies significantly depending on the willingness to introduce new dependencies on the Kubernetes API. However, a common approach to avoid tight coupling is to invert the dependencies by exposing APIs that Kubernetes can consume to provide additional functionality. Examples are health checks and observability which can be used by providing a standard API for Kubernetes to query the health status or to scrape metrics.
In addition, most modern applications provide REST APIs for configuration or data provisioning. The data is usually stored in an external database. In a hybrid or multi-cloud environment, one application could be deployed in different environments and thus the configuration would be distributed across many databases. In this scenario, we face various challenges:
- How do we make sure to apply application configuration consistently to each instance of our application?
- How do we cope with configuration drift, e.g., if someone changes the configuration for a single instance of the application?
- How can we set up a new deployment of our application with the same configuration?
First of all, we need a single source of truth for our configuration, and second we need a mechanism to synchronize the truth to all instances of our application. A common solution to this problem is a GitOps approach. Red Hat Ansible Automation Platform and Argo CD are popular and widely accepted tools in this space.
What options do we have?
We have a few options:
- Using Ansible: Ansible can be applied directly to declaratively describe the desired state in terms of playbooks that call the respective REST APIs when they are executed.
- Using Argo CD: Argo CD can communicate with the Kubernetes API either directly or via configuration tools such as Helm, Jsonnet, and Kustomize. However, since our application is not part of the Kubernetes API, there is no straightforward way to use Argo CD for this purpose.
- Moving the configuration into Kubernetes: We could describe our resources as custom resources and store them in etcd, the database used to store all Kubernetes resources. The application would then completely rely on and thus depend on Kubernetes.
There is a fourth option that is widely adopted and can combine even all 3 options discussed above: the concept of an operator. An operator is a component that runs side-by-side with the application and can manage configuration, updates, backups, and other operational tasks. A Kubernetes Operator usually extends the Kubernetes API (Option 3) with application-specific custom resource definitions (CRD for short, comparable to the schema of your REST resource) to deploy the applications or to manage various other aspects of the application.
In other words, through a Kubernetes Operator, we integrate our application into the Kubernetes API and are then able to adopt many of the Kubernetes-native tools such Argo CD (Option 2). In addition to the extension via CRDs, some controller logic must be written to define what the operator actually should do. This logic can be written in a programming language such as Go or Java, an automation tool such as Ansible (Option 1), or Helm.
The concept of Kubernetes Operators is quite popular—you can find more than 300 operators in OperatorHub.io. Red Hat provides most of their software that runs on OpenShift via operators and many of them follow the same principles that we are describing in this article.
What ingredients do we need to write an operator that manages our application via REST?
So, let us discuss which steps are needed in terms of designing an operator that connects to the REST API of our application. We will describe the steps without a specific implementation in mind. The decisions and concepts should be applicable to Go, Java, and Ansible-based operators. Helm operators are more limited in their scope and are thus not further taken into consideration. We assume that your REST API provides an OpenAPI specification or similar, however, even without such a document, it should be possible to follow along.
Step 1: Determine the REST resources you want to be managed by the operator
First of all, many applications define comprehensive REST APIs that allow them to manage every detail of the application. The question is, do I need everything to be manageable by an operator? We cannot answer this question in general, but most likely you will start with a subset of the available resources. How do we determine the resources the operator could manage? A source can indeed be the OpenAPI schema and the list of all response types (components.responses) or if not available the list of all schemas (components.schemas). See Figure 1.
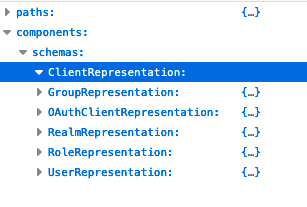
As discussed above, for each resource ask yourself if it should be managed by your operator. Let us look at an example. Keycloak provides an OpenAPI spec that can be found here. A subset of the document is shown in Figure 1. In the components.schema section you will find various schema types. We choose ClientRepresentation for our example since it makes sense to be able to create Clients in order to automate the integration of OIDC clients with Keycloak. We could, for example, plan to create manifests to configure our own application to be integrated with Keycloak. This would enable us to roll out an application together with the Keycloak configuration needed to set up OIDC.
Step 2: Select paths for implementing CRUD operations for the REST resource
The next question to answer is, does the API contain the necessary paths to create (C), read (R), update (U) and delete (D) the resource?

For reading our resource, we need to find a GET operation that returns a response with the expected type. In our Keycloak example, we are looking for GET operations returning a response of type ClientRepresentation. The path /admin/realms/{realm}/clients/{client-uuid} fulfills the requirement and as we can see we need a realm and the client-uuid parameter to uniquely identify our resource. An alternative path would be /admin/realms/{realm}/clients, however, it does not return a specific ClientRepresentation but a list of them that can later be filtered by an appropriate property.
For deleting a resource, we can often use the same path as for reading the resource. We just need to choose another HTTP method, e.g., DELETE. However, it is quite common that APIs define separate /admin paths and move operations that manipulate the state of the resource into this separated path hierarchy. In the case of Keycloak all paths start with /admin and the delete is available at the same path as for the read operation so we can just use: DELETE /admin/realms/{realm}/clients/{client-uuid}.
Similarly, we will probably find a way to update our resource using the same path again but this time via PUT or PATCH. The former will completely replace our resource whereas the latter will only replace those parts that need to be changed. Both can be used but most APIs use only one of both, e.g., Keycloak uses PUT. Hence we can use the PUT /admin/realms/{realm}/clients/{client-uuid} path.
Finally, we need a way to create our resource which is usually implemented via POST (in rare cases PUT can be used instead). A common way to find the corresponding POST path is just drop the last segment of the read path. Otherwise, you should search for POST paths returning the desired resource schema as a response. In our example, we can use POST /admin/realms/{realm}/clients.
The chosen paths can be seen in Figure 2. Let us finally think about errors that could happen when calling the API. For appropriate error handling you should make sure in case of API errors:
- For create: Not to create the custom resource.
- For update: Reset the values to the previous in the custom resource
- For read: To retry the operation several times with backoff
- For delete: Block the deletion of the customer resource, e.g., via a finalizer.
Step 3: Defining Custom Resource Definitions
To interact with the API of your application, you need to define custom resources (CRs for short) that can be reconciled by your operator. The custom resource defines the desired state of your REST resources and should hence resemble their schema. An open question, however, is whether we should define one Custom Resource Definition (CRD) per REST resource or aggregate several REST resources into one or a few CRDs.
How to map REST resources to CRDs
Aggregating multiple REST resources into one CRD reduces the number of resource definitions that must be managed and versioned by your OpenShift Cluster. A rule of thumb is that you could combine those REST resources that have a composite parent-child relation, e.g., in the Keycloak example we could define a single RealmRepresentation CRD that contains ClientRepresentation and UserRepresentation resources. This makes sense since Clients and Users are always part of one Realm. This is also the approach that has been chosen for the current Keycloak operator which defines a single KeycloakRealmImport CRD.
However, the previous major version of the Keycloak operator defined separate CRDs for Realms, Clients, and Users. One drawback of separating CRDs with a dependent lifecycle is that your operator or the user of the operator needs to be aware of those dependencies—e.g., before one can create a Client, one must create a Realm, etc. We will come back to this matter in Step 5.
There are generally at least two categories of CRDs that are usually separated: one for the deployment of your application and one for the configuration of your application. In the case of Keycloak, we have the Keycloak for the deployment and the KeycloakRealmImport CRD for the configuration.
How to map the resource properties
Now, when we have decided how to map REST resources to CRDs, we will face another challenge: there is usually no such thing as a single schema that represents the whole REST resource. Instead, we will find different schemas for creating, updating, or getting a representation of the REST resource. Their properties will overlap but they are usually not the same. Hence, we will first need to identify the different schema types involved in the CRUD operations we have determined in Step 1. In our Keycloak example, it is quite simple, there is only one schema to be considered:
- The response of
GET /admin/realms/{realm}/clients/{client-uuid}is of typeClientRepresentation. - The request body of
POST /admin/realms/{realm}/clientsis of typeClientRepresentation. - The request body of
PUT /admin/realms/{realm}/clientsis of typeClientRepresentation.
If we look at another example, e.g., Apicurio, we will find different types, for instance, in case of the ArtifactMetaData resource:
- The response of
GET /groups/{groupId}/artifacts/{artifactId}is of typeArtifactMetaData. - The request body of
POST /groups/{groupId}/artifactsis of typeCreateArtifact. - The request body of
PUT /groups/{groupId}/artifacts/{artifactId}is of typeEditableArtifactMetaData.
You can find the complete OpenApi doc for Apicurio here.
There are two locations in the CRD where we can map the properties to: the spec and the status. The latter is a read-only part reflecting the current status of the CR.
We should distinguish the following types of properties contained in our REST resource schemas:
- Properties that are only part of the create request body schema:
- Should be mapped to the
specpart of the CRD. However, if the properties are not part of the update request body schema they cannot be changed after creating the resource. An OpenShift user could nevertheless change thespecproperty. In this case, your operator should ignore the new value and overwrite it with the previous one.
- Should be mapped to the
- Properties that are only part of the update request body schema:
- Should be mapped to the
specpart of the CRD. However, if the properties are not part of the create request body schema they can only be set after the resource has been created. The operator should instantly trigger an update after creating the resource in this case.
- Should be mapped to the
- Properties that are only part of the read response schema:
- Should be mapped to the
statuspart of the CRD because they are read-only.
- Should be mapped to the
All other properties should be mapped to the spec part (as long as you want them to be manageable via your CR). You can always come to the conclusion to omit certain properties if they should not be manageable, e.g., because they are without value for the operator such as an internal identifier or flag that is irrelevant on this level.
What about the path parameters?
After mapping the schema properties, we should also take a look at the path parameters. Ideally, the parameters can be mapped to the corresponding properties from the step before. Otherwise, we must make sure to add them to our CRD. When we look at the Keycloak OpenApi doc, we won’t find corresponding properties for client-uuid nor realm in the ClientRepresentation schema, thus we must add them to the spec of our CRD.
What else should be put into the status of a CRD?
As discussed above, the status should contain the read-only properties of our REST resource. However, we should also add information about API errors (error code and error message). This will help to debug if something goes wrong. Furthermore, another valuable information would be to know about the synchronization status, e.g. when has the REST resource been read and when has the REST resource been updated to match the desired state in the CR spec. This brings us to another interesting point. How should we define the synchronization logic in our operator?
Step 4: Choosing a synchronization policy
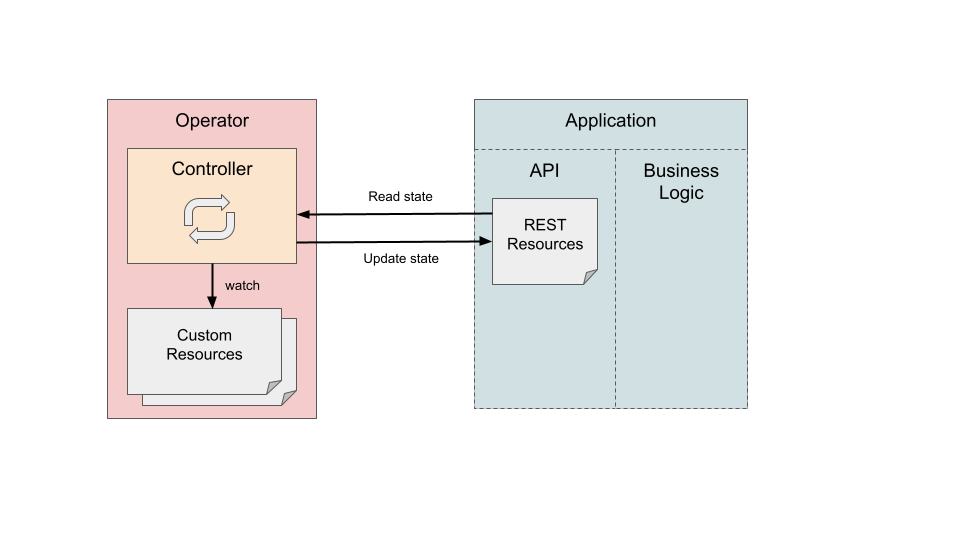
Operators are controllers that run reconciliation loops to compare the actual with the desired state. If the desired state does not match the actual, the operator must conduct actions to change the actual state to the desired one. In our case, the actual state is the state of the REST resource and the desired state is expressed in the spec part of the CR. Hence, we should synchronize the state from the CR to REST resources. But what about the opposite direction?
It is desirable to obtain a single source of truth that should be defined by our CR, or more specifically the spec part of the CR. It follows that, if the REST resource has been changed by some other entity, e.g., because someone has sent a PATCH request from CLI directly to the REST resource, we should not modify the spec part of our CR. Instead, we should change it back to the previous state. We must frequently check the REST resource’s state and if something changes that is not consistent with what we defined in the spec part of the CR we must send a PATCH or UPDATE request. If the change pertains to a field in the status of CR we can simply update it since it reflects the status of the REST resource and not the desired state. See Figure 3.
Another interesting point to consider is how to deal with default values. Let us assume that we create a CR and leave some optional fields empty. Our operator will send a POST request and the resource will be created. It is quite common that there are properties that will be initialized with reasonable default values. Hence, we will have a gap between the desired and actual state, however, it is still consistent since the desired state does not state anything about the property that has been set to a default value.
We have two options: ignoring the default value or reporting it into the CR status object. We should not fall into the trap of writing the default values to the spec (never change the spec from your operator!) The single source of truth is often not the CR itself, e.g., in a GitOps approach, the desired state is stored in a Git repo as a yaml file. If our operator changed the spec, Argo CD would detect a drift and override the CR causing a race condition between Argo CD and our operator.
How often should the operator fetch the resource state and thus potentially trigger a reconciliation loop? We can set a fixed polling interval, e.g., every 5 seconds, however, this could lead to many requests, especially when our operator is managing a multitude of REST resources. A better approach would be to use some event-based mechanism if available for the application that you are managing with the operator. The operator could subscribe to an event source, e.g., a broker, and trigger synchronization only if the REST resource is changed. This would avoid polling the REST resources.
Step 5: Implementing dependencies between REST resources (and consequently also for CRs)
In this last step, we will follow up on what was discussed in the context of Step 3 where we described how to map the REST resources to CRDs. In case you decide to define multiple CRDs to manage REST resources that depend on each other, you will need to implement a dependency mechanism.
The first ingredient for a dependency mechanism is to express the dependency in terms of the available syntax, i.e., what CRDs allow to define. A common way to implement a dependency is to define an identifier property to link the child CR to its parent, e.g., storing the Realm name in the Client CR in the case of our Keycloak example. If a user wants to create a new child CR she must know the parent identifier and thus needs to create it first. Otherwise, the operator should show an error message in the status (e.g., “no realm with the name xy can be found”).
An alternative to this approach is to implicitly create the parent if it does not exist, e.g., create the Realm named xy before the operator creates the Client. This approach is more complex to implement and strongly depends on whether the data for creating the parent can be derived from the child CR. If not, we must add additional properties and this could lead to copying most of the parent properties to the child and finally the approach converges into using a single CRD for parent and child.
Another aspect to consider is how to deal with deleting the parent CR. If the child CR cannot exist without its parent, it must also be deleted. Further, it must be assured that the child is deleted before the parent can be deleted. There is a Kubernetes mechanism called owner reference to the rescue. It can be used as long as the parent and child CR live in the same namespace (and if not you can still implement it yourself). What does this look like? You just need to add an owner reference to the child, e.g.:
apiVersion: example.operator.org/v1alpha1
kind: ClientRepresentation
metadata:
ownerReferences:
- apiVersion: example.operator.org/v1alpha1
kind: RealmRepresentation
name: example
uid: e5abde81-a813-473c-8406-bfac0f5a3ddbThis will cause OpenShift to garbage collect the child CR when its parent is deleted. Second, your operator should add a finalizer to the parent CR. As long as this finalizer is present, OpenShift won’t delete it:
apiVersion: example.operator.org/v1alpha1
kind: RealmRepresentation
metadata:
name: example
finalizers:
- realmrepresentations.example.operator.org/finalizerThe operator should remove the finalizer when it has successfully deleted the respective REST resource represented by the CR.
Conclusion
Operators enable the automation of operational tasks such as configuration, updates, or backups for applications. They run side-by-side with the application and watch its state. Operators constantly run in a reconciliation loop to assure the actual state matches the desired state expressed by custom resources. To close the gap between actual and desired state it manipulates the resource’s state by applying the respective CRUD operations, e.g., updating properties of the resource when they don’t match the desired state.
If the managed application provides a REST API, the operator can leverage it for its CRUD operations. In this article, we described general principles for designing such an operator. We introduced five steps: determining the REST resources, selecting the paths for CRUD operations, defining the custom resource definitions, choosing a synchronization policy, and implementing dependencies between resources.
The provided steps are technology-agnostic and do not assume a specific programming language or framework to be used. In another article, we will show how to apply the principles using the Java Operator SDK (JOSDK).