Kubernetes Operators might seem complex at first, but if you understand Kubernetes, you can easily extend that knowledge to Kubernetes Operators. Part 1 of this series provided an overview of Kubernetes Operators and what they do. This article explains aspects of how a Kubernetes cluster works, including the structure of a cluster, how workloads are managed, and the reconciliation process.
The structure of Kubernetes Operators
A Kubernetes cluster treats an operator like an application that's deployed as a workload. This specialized application manages another resource, such as another application hosted in Kubernetes.
An operator manages an operand using a set of managed resources:
- Operand: The managed resource that the operator provides as a service.
- Managed resources: The Kubernetes objects that an operator uses to create the operand.
Out of the box, Kubernetes is good at managing stateless workloads. They are similar enough that Kubernetes uses the same logic to manage all of them. Stateful workloads are more complex, and each one is different, requiring custom management. This is where operators come in.
A basic operator consists of the components depicted in Figure 1.
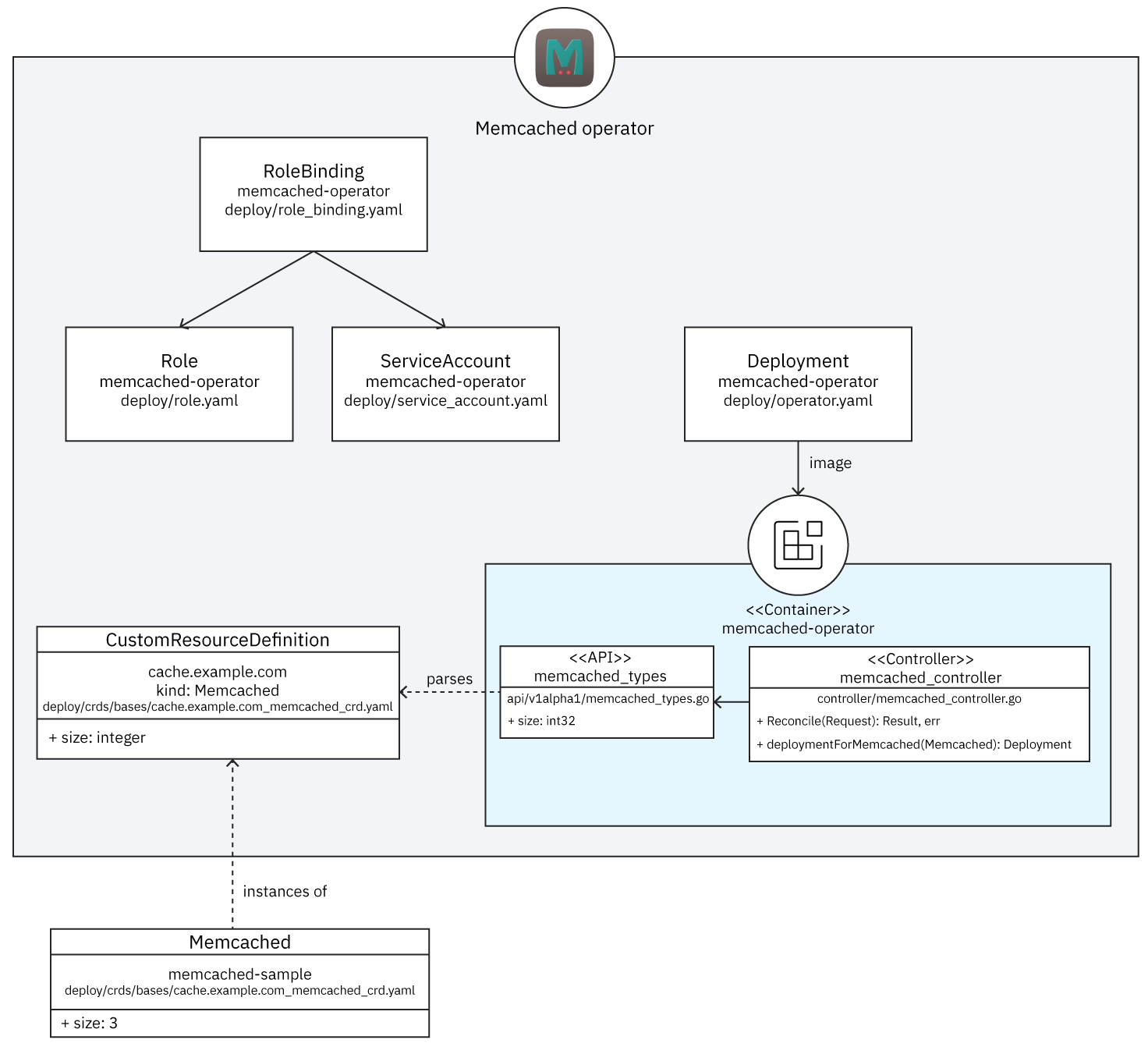
The following components form the three main parts of an operator:
- API: The data that describes the operand’s configuration. The API includes:
- Custom resource definition (CRD), which defines a schema of settings available for configuring the operand.
- Programmatic API, which defines the same data schema as the CRD and is implemented using the operator’s programming language, such as Go.
- Custom resource (CR), which specifies values for the settings defined by the CRD; these values describe the configuration of an operand.
- Controller: The brains of the operator. The controller creates managed resources based on the description in the custom resource; controllers are implemented using the operator’s programming language, such as Go.
- Role and service accounts: Kubernetes role-based access control (RBAC) resources with permissions that allow the controller to create the managed resources.
A particular operator can be much more complex, but it will still contain this basic structure.
The Kubernetes architecture
A Kubernetes cluster consists of a control plan, worker nodes, and a cloud provider API, as Figure 2 shows.
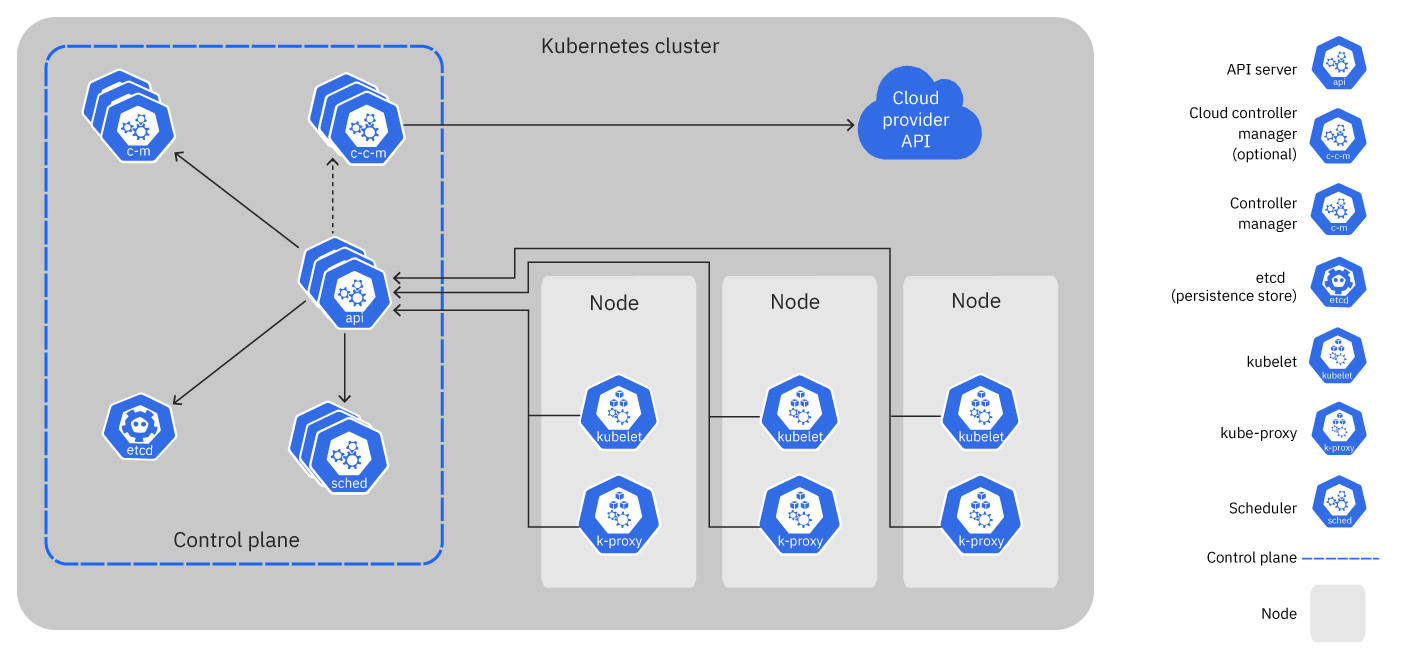
The following components form the two main parts of a cluster:
- Worker nodes: The computers that run the workloads.
- Control plane: The components that manage the cluster, its nodes, and workloads.
- API server: An API for the control plane that clients use to manage the cluster.
- Controller manager: Runs the controller processes; each controller has a specific responsibility as part of managing the cluster.
Operators only use the worker nodes and control plane components.
Operators run in the worker nodes. However, operators implement controllers, which run in the control plane. Because operators run controllers in the worker nodes, they effectively extend the control plane into the worker nodes.
A cluster always has two states: desired and current. The desired state represents objects that should exist in the cluster. The current state represents the objects that actually exist. Controllers manage a cluster’s state, reconciling the current state to match the desired state. Kubernetes controllers run in the control plane.
Almost every Kubernetes object includes two nested object fields that store the objects' desired and current state—specification (represented in YAML by the spec section) and status (represented in YAML by the status section). These two fields are what an operator's controller uses to reconcile its operands. When you want to update the desired state, you update the settings in the specification field in the custom resource. After the cluster has updated the operand, the controller will save the currently observed state of the managed resources in the status field, thereby storing the custom resource's representation of the current state.
Deploying workloads in Kubernetes
The way an operator deploys and manages a workload is similar to how an administrator deploys and manages a workload. A basic workload deployed into a Kubernetes cluster has the structure shown in Figure 3.
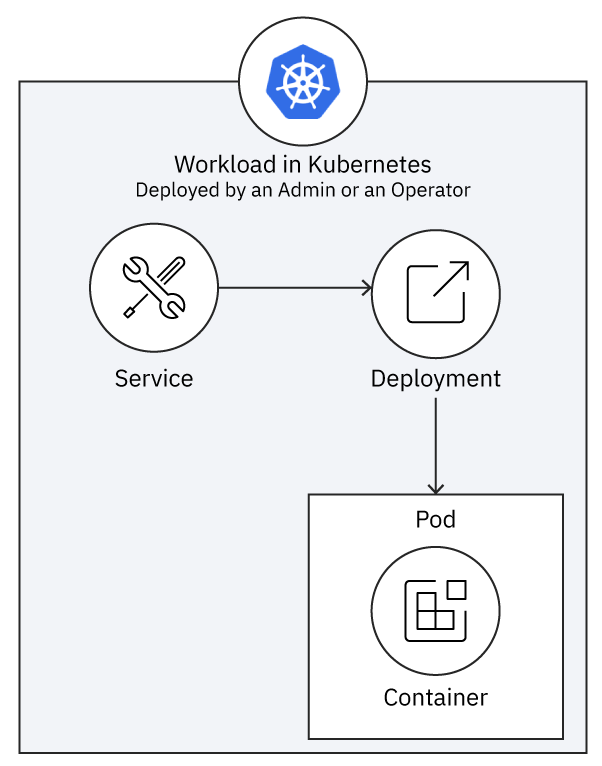
The workload consists of a Deployment that runs a set of Pod replicas, each of which runs a duplicate Container. The Deployment is exposed as a Service, which provides a single fixed endpoint for clients to invoke behavior in the set of replicas.
How operators deploy a workload
An operator deploys a workload in very much the same way that a human administrator (or a build pipeline) does. Operators are, after all, meant to automate tasks done by IT administrators.
As Figure 4 illustrates, the Kubernetes API does not know whether the client is an admin or an operator, so the cluster deploys the workload the same way. Everything that happens in the control plane is the same.
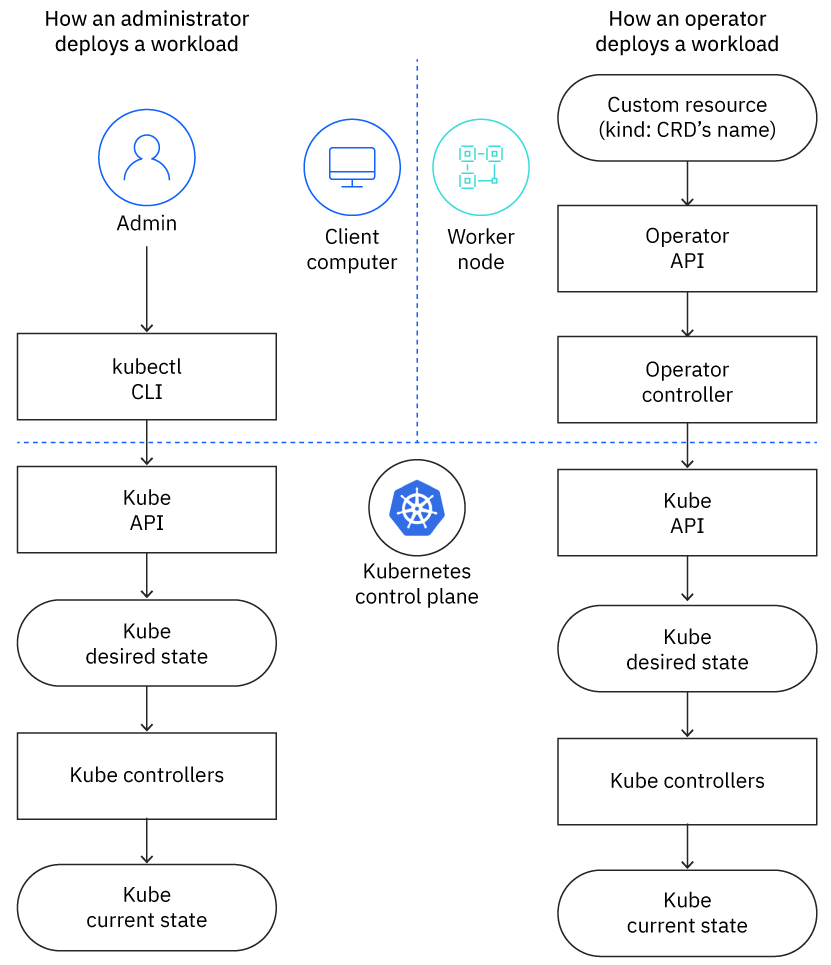
Kubernetes’ workload deployments
An administrator uses client tools such as the kubectl CLI and YAML files to tell the cluster what resources to create, such as those to deploy a workload. When an admin runs a command like kubectl apply -f my-manifest.yaml, what actually happens?
- The client tool talks to the Kube API, which is the interface for the control plane.
- The API performs its commands by changing the cluster’s desired state, such as adding a new resource described by
my-manifest.yaml. - The controllers in the control plane make changes to the cluster’s current state to make it match the desired state.
Voilà! A workload is deployed.
Operators’ workload deployment
When an operator deploys a workload, it does pretty much the same thing:
- The CR acts like the administrator's YAML file, providing an abstract description of the resource that should be deployed.
- The controller uses its API to read the CR and uses the Kubernetes API to create the resource described by the CR, much like an admin running
kubectlcommands.
The Kubernetes API doesn't know whether its client is an admin using client tools or an operator running a controller. Either way, it performs the client's commands by updating the desired state, which Kubernetes' controllers use to update the current state. In this way, the operator does what the admin would do, but in an automated way that's encapsulated in its controller's implementation.
How operators reconcile Kubernetes cluster states
Remember that a Kubernetes cluster always has two states. The desired state represents objects that should exist in the cluster, and the current state represents the objects that actually exist.
In Kubernetes Operators, controllers manage a cluster’s state, reconciling the current state to match the desired state. Kubernetes controllers run in the control plane. The following section examines how reconciliation happens in regular Kubernetes workloads, then how Kubernetes Operators extend that reconciliation into the worker nodes.
The reconciliation loop in the control plane
In a typical Kubernetes cluster, a controller manager runs controllers in a reconciliation loop in the control plane. Each controller is responsible for managing a specific part of the cluster's behavior. The controller manager runs a control loop that allows each controller to run by invoking its Reconcile() method.
When a controller reconciles, its task is to adjust the current state to make it match the desired state. Therefore, the control loop in the controller manager is a reconciliation loop, as the diagram in Figure 5 shows.

The reconciliation loop in the worker nodes
While Kubernetes controllers run in the control plane, the operators' controllers run in the worker nodes. This is because an operator is deployed into a Kubernetes cluster as a workload. And just like any other workload, the cluster hosts an operator's workload in the worker nodes.
Each operator extends the reconciliation loop by adding its custom controller to the controller manager's list of controllers (see Figure 6).
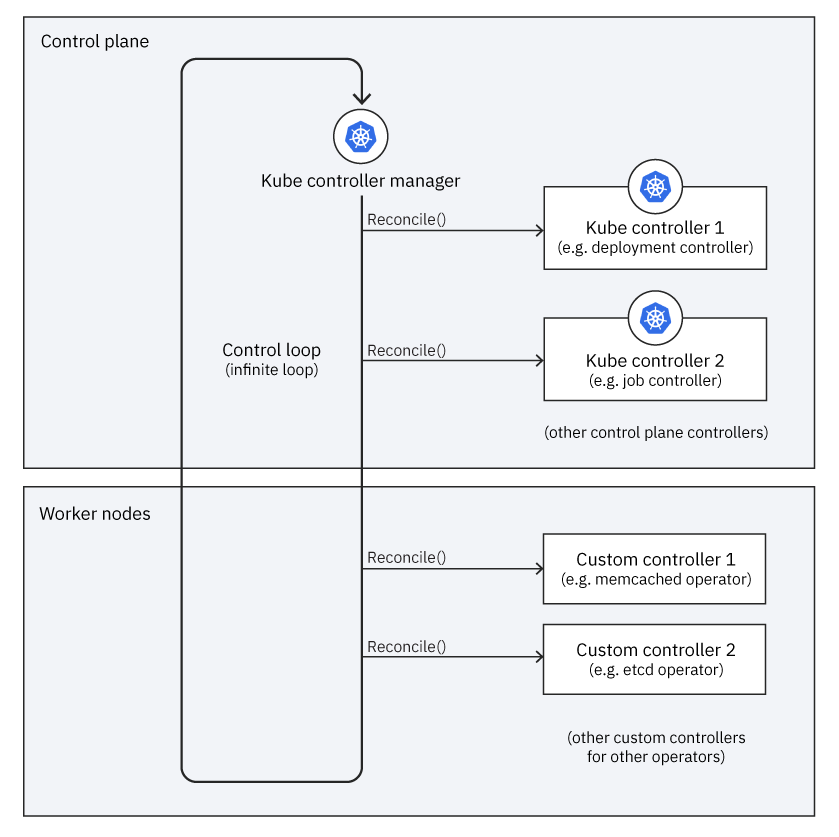
When the controller manager runs the reconciliation loop, it does two things:
- Tells each controller in the control plane to reconcile itself.
- Tells each operator’s custom controller to reconcile itself.
And as with a standard controller, Reconcile() allows the custom controller to react to any changes since the last time it reconciled itself.
Reconcile states
So far, we've covered the relationship between a cluster's desired state and its current state and how a controller reconciles between those two states for the resources it manages.
The way Kubernetes' controllers and an operators' custom controllers reconcile is analogous, as illustrated by Figure 7.
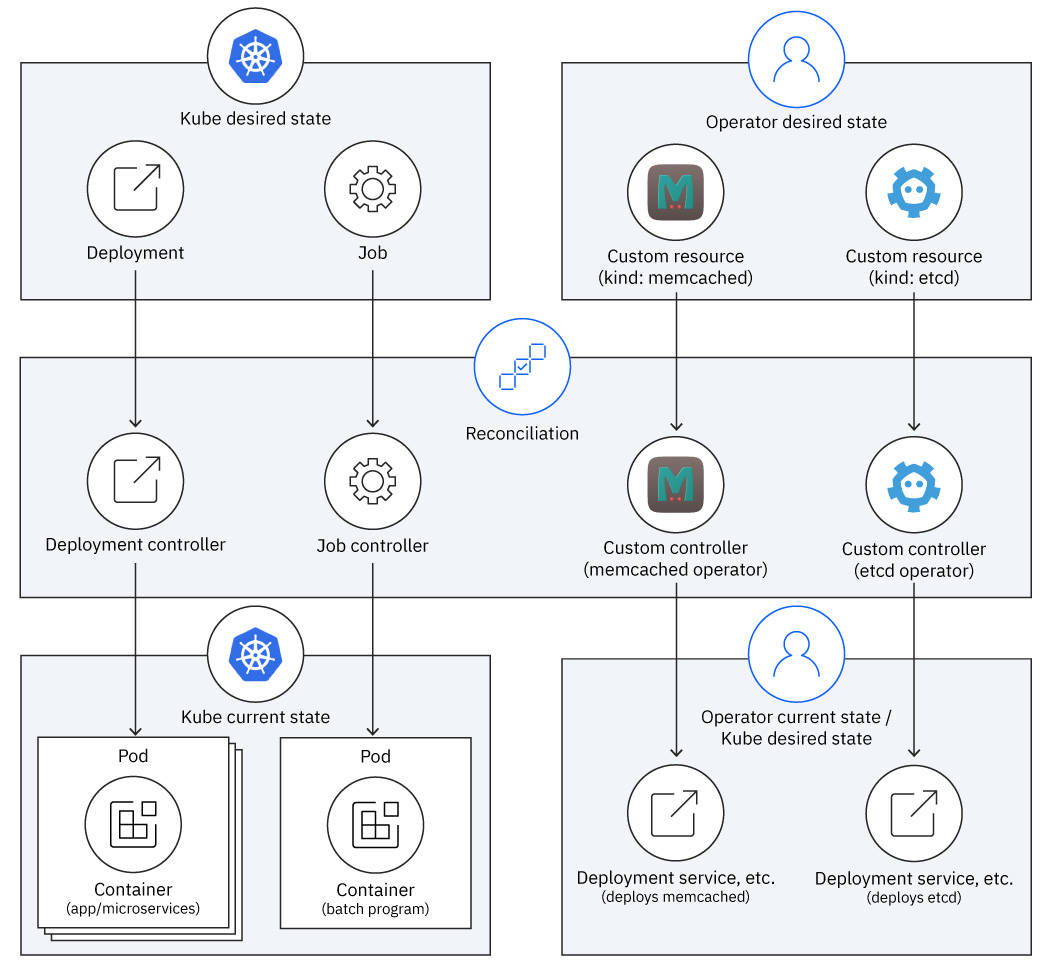
Operator controllers work one level of abstraction higher than the Kubernetes controllers. The Kubernetes controllers reconcile built-in kinds like Deployment and Job into lower-level kinds like Pods. Custom controllers reconcile CRDs like Memcached and Etcd into workload kinds like Deployment and Service. So, a custom controller's current state becomes a Kubernetes controller's desired state.
Both kinds of controllers reconcile between the desired and current state, but it takes two rounds of transformation to deploy a workload for an operator's custom resource:
- The operator’s controller transforms the custom resource into a set of managed resources (that is, the workload) that are the operator’s current state but are also the control plane’s desired state.
- The Kubernetes controllers transform the managed resources into running pods (aka the operand) in the control plane’s current state.
Summary
This article has demonstrated how you can extend your understanding of Kubernetes to their operators. Operators work like Kubernetes in several respects:
- An operator's brain is a controller whose responsibilities are like those of a typical Kubernetes controller in the control plane.
- The way an operator deploys a workload is similar to how an administrator deploys a workload. The control plane doesn't know the difference.
- The control plane implements a reconciliation loop that allows each controller to reconcile itself, and operators add their controllers to that loop.
- While Kubernetes controllers and custom controllers adjust between their desired state and their current state, operators manage desired state as a custom resource and reconcile it into a current state that is a set of managed resources that Kubernetes controllers use as their desired state.
With this knowledge, you'll be better prepared to write your own operators and understand how they work as a part of Kubernetes.
Last updated: August 24, 2022