Welcome! This guide will help you get started with general purpose graphics processing unit (GPU) programming, otherwise known as GPGPU. It is intended to:
- Teach you the basics of parallel GPU programming, such as the SIMD model.
- Walk you through some key algorithms, such as scan/prefix sum, quicksort, and game of life.
- Show you working examples of code from OpenAI’s Triton, CUDA, OpenCL, torch.compile, Numba, and HIP/HCC.
- Help you determine which framework to use, and go over any common pitfalls.
This guide focuses more on the algorithms and architecture, with a heavy emphasis on how to effectively use the computational model. In my personal experience, I found GPU programming to be a fascinating concept, although many of the existing resources seemed to be focused primarily on system-level details. It wasn't until I learned the more general algorithmic design principles that I was able to use GPU programming more effectively. So, I hope this guide can fill that space, and help you become a more proficient GPU programmer!
What is a GPU?
A GPU is essentially a massively parallel processor, with its own dedicated memory. It is much slower and simpler than a CPU when it comes to single-threaded operations, but can have tens or even hundreds of thousands of individual threads. Each GPU core, or stream multiprocessor (SM) essentially uses a mechanism similar to the CPU's SMT to host potentially thousands of threads at once. For example, the NVIDIA A100 has 2048 threads per SM, and 108 SMs, resulting in a total of 221,184 individual threads (Wikipedia Ampere).
GPU Programming Model
Luckily, on the developer's side, we don't have to manage hardware at such a low level. Instead, we lay out our program as a "grid," where each "block" in the grid works on its own SM and has its own dedicated memory. Within each block, we also have a number of threads (also laid out in a grid) that will each simultaneously execute our program, which we call a "kernel." When we decide on such a layout, we can largely rely on whatever layout is most intuitive for the problem at hand, and the hardware driver will take care of the rest. If we use more blocks than available SMs, then those remaining blocks will simply be queued and run as soon as an existing one is free. If we use more threads than available, then those existing threads will be queued up as well. Of course, there are certain performance benefits from specifying a block size and tuning the grid parameters. But, at a high level, we get a lot more freedom for how to conceptualize and design our algorithms. A diagram of this grid is shown in Figure 1.
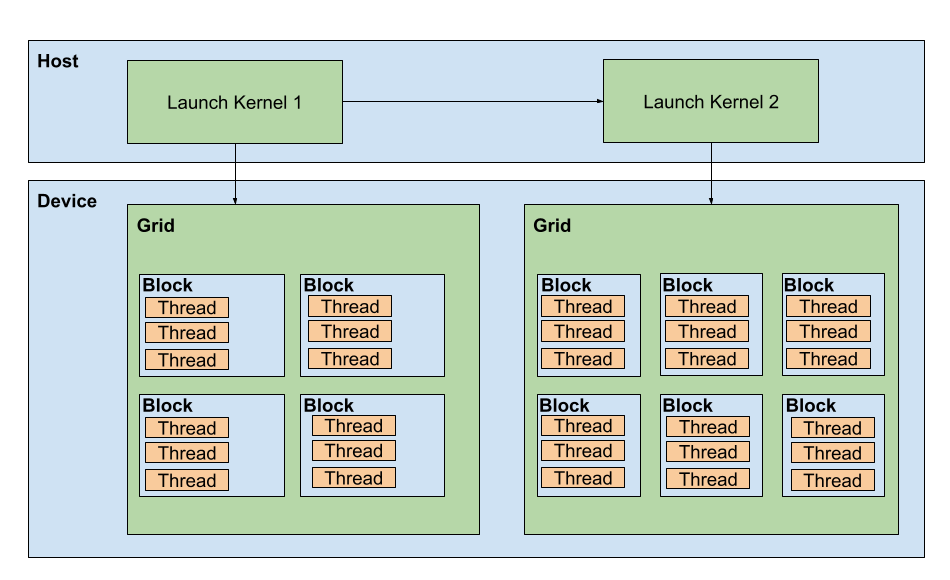
Part of the reason that the GPU is able to handle so many threads is because of its limited capabilities/instruction set. For example, rather than doing branch prediction, a GPU will simply choose to switch to another thread and continue execution there while waiting (gpgpu: Why dont we need branch prediction). So, the GPU is able to constantly keep its powerful backend fully saturated, hence the performance in massively parallel operations.
Unfortunately, this also comes at a cost. If you take a look at the diagram above in Figure 1, you’ll notice that there are two rows—one for the “device,” which is the term we usually use when describing the GPU, and one for the “host,” which refers to the CPU. The CPU is called the host since it is the main device, and it issues commands. With GPU programming, this limited instruction set means that most GPUs don't support recursion, and some don’t support arbitrary loops (Why is recursion forbidden in OpenCL? - Computer Graphics Stack Exchange). In my own testing, for example, I found that putting a loop inside of a conditional was forbidden on certain systems (e.g., if x == 0 then while j < k…). All of this means that we must constantly coordinate our algorithm on the CPU side, and only use the GPU for one computation at a time. In this light, you can almost conceptualize the GPU as a device that can only run a fixed, finite, pre-defined list of instructions every time the host launches a kernel. Of course, this is changing, but this basic model still holds for the lowest common denominator of devices.
Luckily, by leveraging the host to run multiple GPU programs back-to-back, we can still run Turing Complete computations. The best way to do this is by running the exact same kernel program, on a bunch of elements at once, and repeating this process, switching kernels as many times as we need. Hence the source of the name of this programming model: Single Instruction/Multiple Data, or SIMD.
One caveat is that on certain NVIDIA devices, we can instead use Dynamic Parallelism to do this instead, and completely bypass needing to return back to the host. Essentially, you can write a CUDA program that uses recursion, like you would on the CPU, and the device will automatically take care of the work of launching a series of kernels for you (Quicksort can be done using CUDA. – Parallel Computing). Because it doesn’t have to wait for the host to launch new kernels, it is faster and easier to code. But, it is computationally equivalent to simply launching a series of kernels, and it works on NVIDIA’s CUDA only.
What is up with all the different GPU programming languages?
The first contender to truly take GPGPU seriously was NVIDIA, with CUDA. Soon after, other hardware manufacturers, specifically Apple, began to create a competitor called OpenCL, by working with the Kronos Group (the same group that brought you OpenGL and Vulkan). This soon became supported by other vendors, like Apple, IBM, and Intel, and is now the most widely supported compute framework in the world.
However, OpenCL was always behind CUDA in terms of features and developer experience. Also, both frameworks are known to have a steep learning curve (hence why you might be reading this guide!). So, these two problems have spawned a large number of alternatives to CUDA. Unfortunately, many of these have eventually been abandoned or lack the support to use in a wide context.
Low-level languages, focused on competing with CUDA:
- HIP/HCC/ROCm: AMD’s competitor that attempts to be open source so it can be used everywhere.
- oneAPI: Intel’s competitor that attempts to be open source so it can be used everywhere.
- SYCL: A new compute language/framework, created by Kronos, in response to OpenCL becoming outdated.
- Vulkan Compute: A new compute language/framework, created by Kronos, in response to OpenCL becoming outdated.
- Metal: Apple’s compute framework, which is still used today for ML development on Apple devices.
High-level languages, focused on making it easier to do GPGPU development:
- OpenAI’s Triton
- torch.compile
- JuliaGPU
- Turbo.js
We will discuss some of these in later articles of this four-part series. Read on for Part 2: Your first GPU algorithm: Scan/prefix sum
Last updated: September 3, 2024