If you develop applications with a cloud-first mindset, you probably use (or plan to use) object storage with the S3 API from Amazon Web Services (AWS). Even if you do not use AWS, all large and smaller public cloud providers offer object storage compatible with the S3 API.
If you plan to work with artificial intelligence (AI), most AI tools require S3 storage to store data from models, training, and tuning, besides the raw data on which AI models make inferences and the results of such inferences.
But, if you have to work on premises, or have to create applications which must work both on premises and on cloud, you require something that provides an S3-compatible API outside of cloud providers. Red Hat OpenShift Data Foundation is a nice alternative proven to support large scale deployments, multiple clouds, and hybrid cloud scenarios.
A basic deployment of OpenShift Data Foundation is pretty resource intensive, in both memory and CPU, because its underlying Ceph technology is preconfigured for reliable production deployments. This may be a significant barrier for experimenting with the product, using it on your notebook for local testing, or as part of your CI/CD pipelines. But what if I told you there’s a much lighter way of deploying OpenShift Data Foundation, which provides you with the S3 capabilities that you need?
Among the components of OpenShift Data Foundation, there’s the Multi-Cloud Object Gateway (MCG). It can provide S3 services without any of Ceph, and it can work using any local or network storage available on your OpenShift cluster as Kubernetes storage, that is, as PVCs.
It is true that the MCG was designed to support multi-cloud scenarios, acting as a front-end for multiple S3 backends which could be on cloud and on-premises. The Multi-Cloud Object Gateway offers location transparency, replication, and other services on top of those backends. It is not well-known that the MCG can also work by itself, without any other S3 backend. You can deploy the MCG standalone in small environments, such as edge clusters based on Single Node OpenShift.
The commands and screenshots here were tested using Red Hat OpenShift 4.14 but everything should work the same way with newer OpenShift releases such as 4.15 and 4.16.
Deploying the Multi-Cloud Object Gateway standalone
The process for deploying the MCG by itself is pretty simple and described in the OpenShift Data Foundation product documentation. It consists of just two steps:
- Installing the OpenShift Data Foundation operator (using defaults).
- Creating a Storage System custom resource with a deployment type of Multi-Cloud Object Gateway and a reference to an existing storage class for its PVCs.
The product documentation is a bit misleading, stating the requirement to use the Local Storage Operator (LSO) and the steps to configure a set of local disks as a local volume set. None of that is required by the Multi-Cloud Object Gateway! You could use other forms of local storage, such as the LVM Storage operator on Single Node OpenShift, or even manually provisioned PVs for any kind of networked storage. As long as you have sufficient memory for the MCG pods, and you can create a couple PVCs, you should be good.
Figure 1 illustrates the final step configuring the StorageSystem from OpenShift Data Foundation, in a test cluster using an NFS storage provisioner.
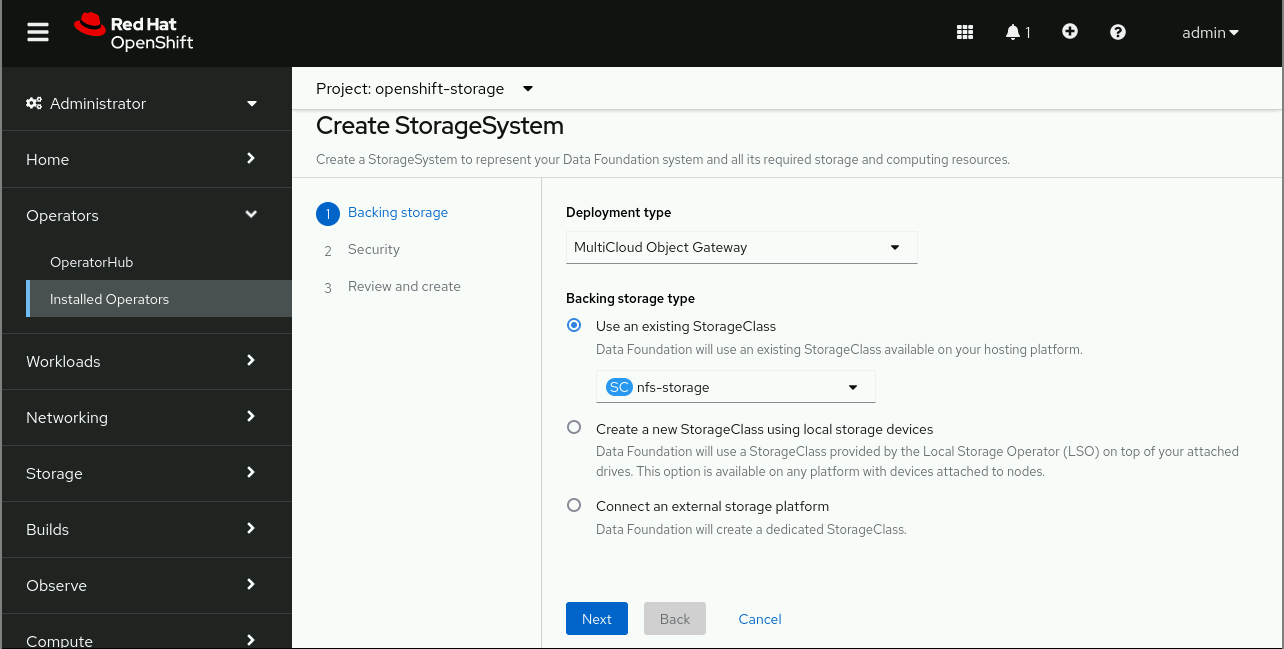
The product documentation states that you need about 10Gi memory for the OpenShift Data Foundation operator and Multi-Cloud Object Gateway pods, which may be too much for a test bed. You can deploy the MCG with smaller resource requirements by skipping the UI from the OpenShift Data Foundation operator and, instead of creating a Storage System custom resource, creating just a NooBaa custom resource manually, as explained by the Red Hat Quay product docs. That way, you should be able to use as little as 2Gi memory.
Go ahead, log in on your test OpenShift cluster with cluster-admin privileges, install the OpenShift Data Foundation operator, and deploy the Multi-Cloud Object Gateway standalone. Be patient, it takes a few minutes for the MCG to initialize itself and, during that time, the Storage > Data Foundation page of the OpenShift web console may report a degraded Storage System, with an unhealthy object storage service. The alert should disappear after a few minutes.
You can check the healthy of your Multi-Cloud Object Gateway deployment by checking its NooBaa custom resource:
$ oc get noobaa -n openshift-storage
NAME S3-ENDPOINTS STS-ENDPOINTS IMAGE PHASE AGE
noobaa ["https://192.168.50.14:31549"] ["https://192.168.50.14:31176"] registry.redhat.io/odf4/mcg-core-rhel9@sha256:a5389f06c3c97918e15bef6ef1259c84007864f17dc6c8c4d61337227cbe6758 Ready 4m8sIf the phase is Ready, it should be good. The status attribute of the NooBaa custom resource provides a more detailed health status, if you need.
Creating S3 buckets as a regular OpenShift user
Once the Multi-Cloud Object Gateway is up and running, you don’t need special privileges to use object storage. If your OpenShift user can create pods and deployments, it can also create Object Bucket Claims (OBCs). They are similar to Persistent Volume Claims (PVCs), but they work with object storage.
The Developer perspective of the OpenShift Web Console does not provide pages to manage storage. You can switch to the Administrator perspective and manage PVCs, without gaining access to OpenShift cluster administration, but OBCs are a custom resource type from OpenShift Data Foundation and its Storage > Object Storage menus and pages are available only to cluster administrators.
Unprivileged OpenShift users are allowed to create and manage OBCs but they must use YAML, at least until a future release of OpenShift Data Foundation fixes that navigation issue and enables regular OpenShift users to navigate to its object storage pages.
Enter any OpenShift project to which you have edit rights (it doesn’t have to be a project you created) and click +Add > Import from YAML. Or, alternatively, click the “+” icon on the top menu, near your username. See Figure 2.
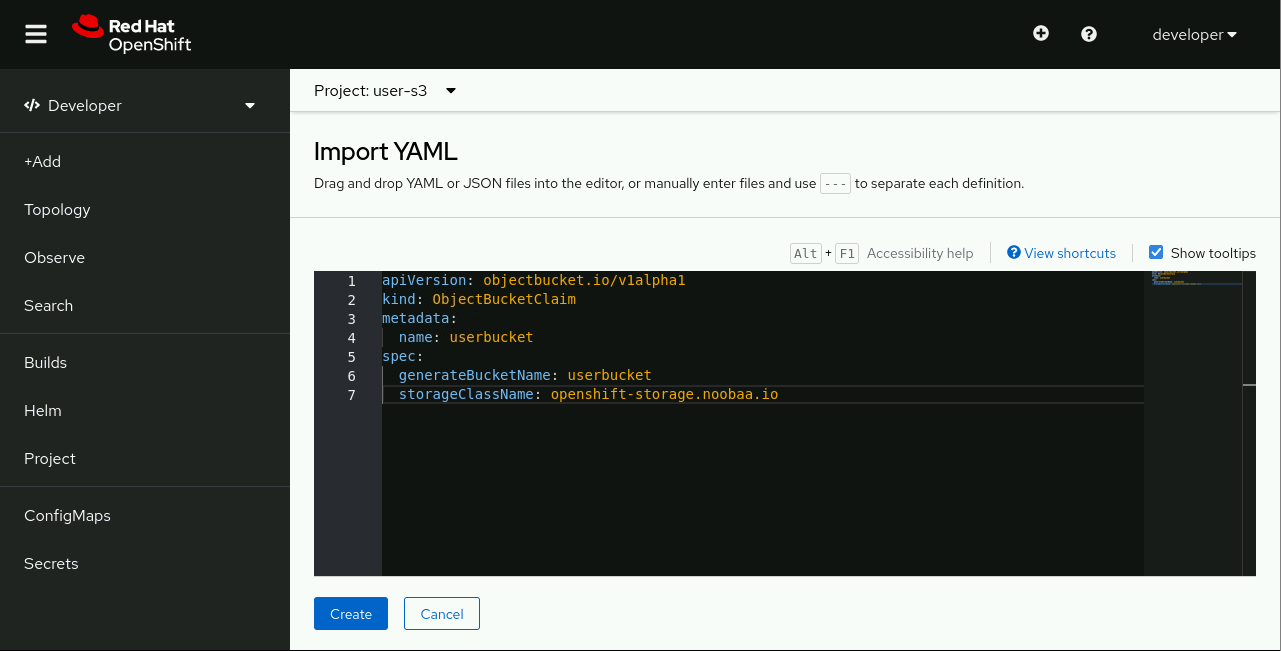
Then type (or paste) a small YAML snippet similar to the following:
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: userbucket
spec:
generateBucketName: userbucket
storageClassName: openshift-storage.noobaa.ioYou don’t have to, but it’s easier if the metadata.name and the spec.generateBucketName of your OBC have the same values. The actual name of your S3 bucket will get a random hash value to prevent collisions because S3 bucket names must be unique in an entire S3 service. S3 Buckets from different users could collide, and OpenShift Data Foundation prevents that by appending a hash.
The storage class name openshift-storage.noobaa.io is the default class from OpenShift Data Foundation. There could be additional storage classes configured for different S3 backends. Unlike PVCs, where the name of a storage class is optional, OBCs require the name of an existing storage class.
How do you find which of your storage classes can work with OBCs? Just check the name of their provisioner: it must be openshift-storage.noobaa.io/obc for the Multi-Cloud Object Gateway.
Of course, you could create the above YAML in a local file and use the oc create -f command instead of the web console. Whatever the method, if your OBC is valid, it creates an S3 bucket on MCG and two Kubernetes resources that provide S3 connection parameters: a ConfigMap and a secret. Those resources have the same name as their OBC.
Adding OBCs to the web console navigation menu
After you create an OBC you see a page with its details and you can verify that OpenShift Data Foundation mutates it to include additional data, such as its auto generated S3 bucket name. Once you leave that page, the only way of finding your OBCs is by using the Search page of the web console.
The search page require that you select one or more resource types before it displays any resources. Type “claim” and then click Object Bucket Claim in the Resources drop down, as shown in Figure 3.
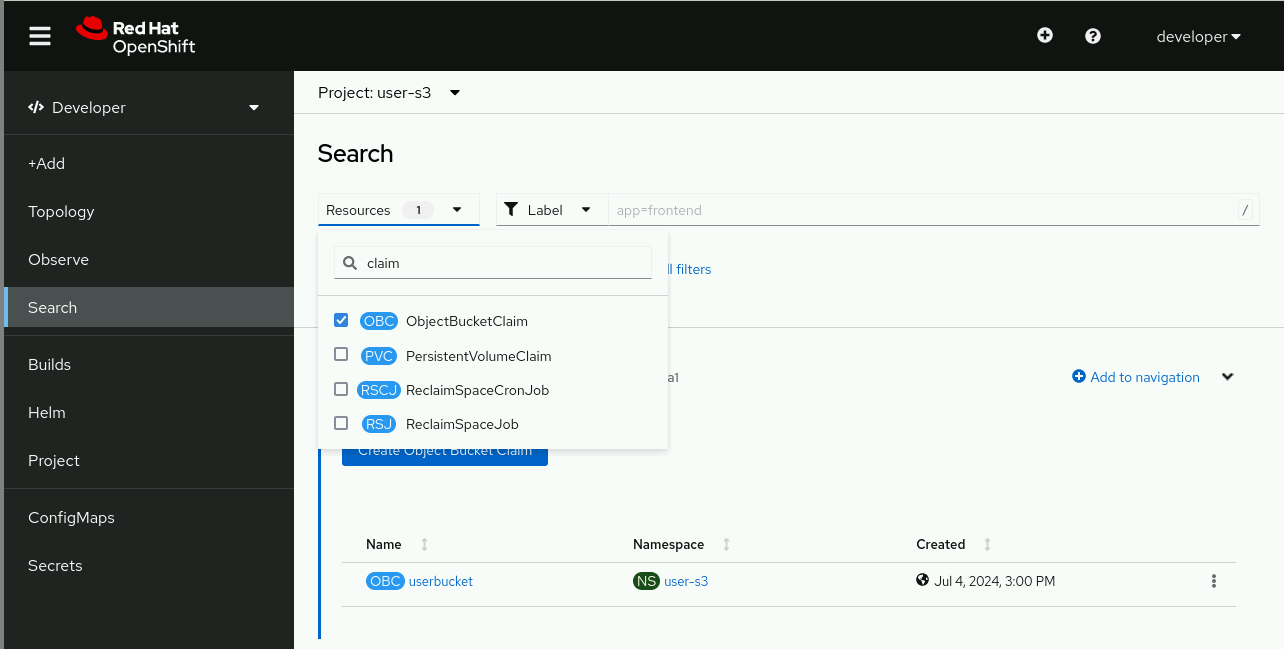
Before you leave the search page, notice the link with a plus sign: Add to navigation. Click it and there will be an Object Bucket Claims menu item right above ConfigMaps and Secrets, in the left navigation pane. This way you can quickly check on the OBCs from your projects, without leaving the Developer perspective. See Figure 4.
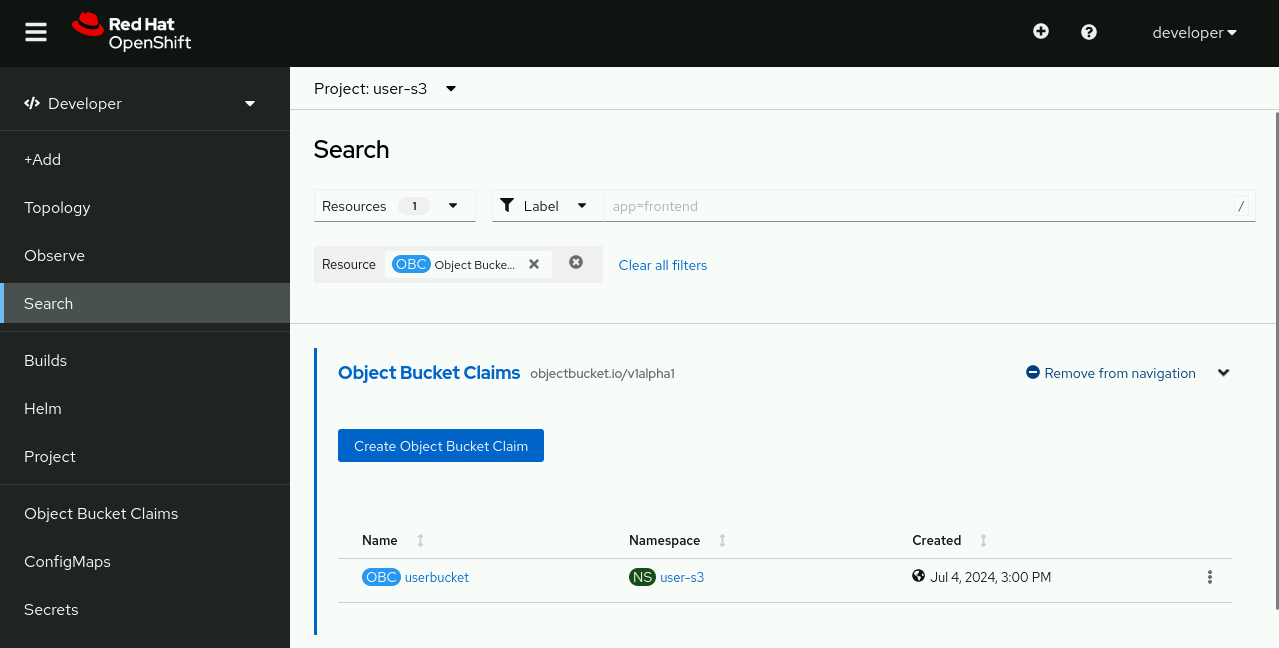
Accessing object buckets as a regular S3 user
For every OBC, OpenShift Data Foundation creates a ConfigMap and a secret. These contain keys which provide S3 API connection parameters and AWS API credentials, ready for consumption by your deployments and other Kubernetes workloads.
You need a way to browse objects inside S3 object buckets, download, and upload data to those objects. OpenShift Data Foundation doesn’t come with a nice GUI front-end like the Amazon Web Services console does, but any tool that works with S3 should work with OpenShift Data Foundation, from CLI tools like rclone to desktop tools like FileZilla Pro. Pick your preferred one. Here we use the AWS CLI. Follow the installation instructions from Amazon, if you don’t have it on your test machine.
First, extract AWS credentials from the secret with the same name as your OBC. Open your secret on the web console, scroll down, and click Reveal values, to the right, close to an eye icon, as shown in Figure 5.
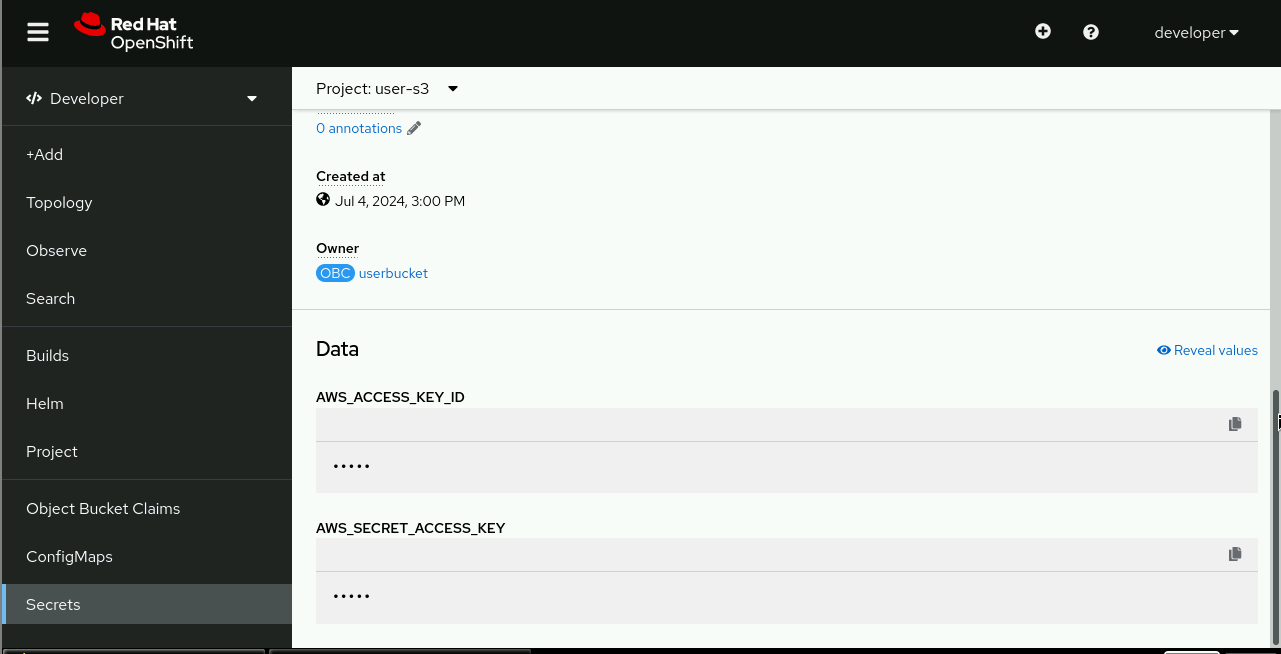
Cut-and paste the values to your S3 tool. Notice the link changes to Hide values after you click it.
Alternatively you can use the following command to initialize the standard environment variables expected by most S3 tools. Just be sure to set the right project with oc project:
$ export AWS_ACCESS_KEY_ID=$(oc get secret userbucket -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d)
$ export AWS_SECRET_ACCESS_KEY=$(oc get secret userbucket -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d)Then extract the bucket name from the configuration map, using the BUCKET_NAME key (Figure 6).
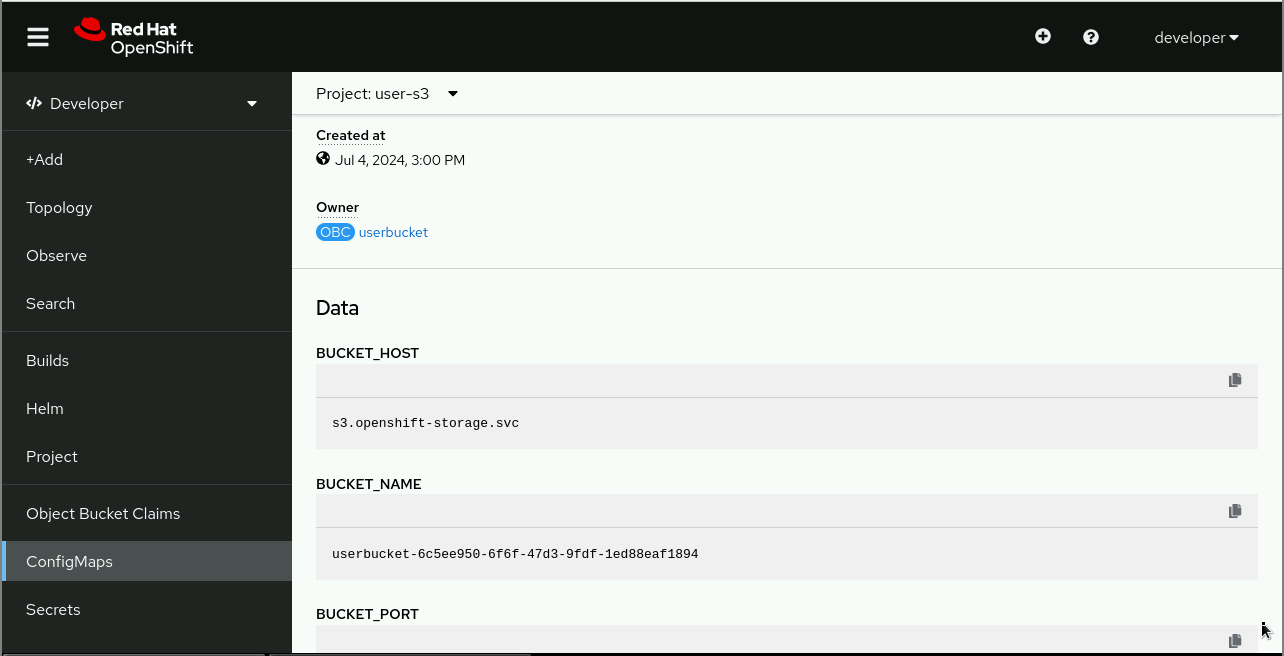
You don’t need other keys such as BUCKET_REGION. And you shouldn’t use BUCKET_HOST because it works only from pods inside the same OpenShift cluster. It is an internal Kubernetes Service hostname (svc) and as such it’s not resolvable outside of its Kubernetes cluster.
Alternatively you can use the following command to initialize a shell variable to use with S3 CLI tools:
$ BUCKET_NAME=$(oc get configmap userbucket -o jsonpath='{.data.BUCKET_NAME}')Finally, we need an S3 endpoint which is accessible from outside your OpenShift cluster. If you have cluster-admin privileges, you could just fetch the hostname of the s3 route inside the openshift-storage project. Unprivileged OpenShift users cannot view resources inside that project, and must manually construct the endpoint as follows:
- Start with
s3-openshift-storage. - Append the default apps domain from your cluster, the same one appended to all routes.
If you don’t know your apps domain, and don't want to create a route just to check it, look at your web console URL: it also uses the apps domain, by default.
For example, my cluster’s web console is at:
https://console-openshift-console.apps.ocp4.example.com
Which tells me the apps domain is apps.ocp4.example.com and I should use as my S3 endpoint the value s3-openshift-storage.apps.ocp4.example.com.
Because I’ll use the AWS CLI, let’s create one final shell variable:
$ BUCKET_HOST=s3-openshift-storage.apps.ocp4.example.comThere’s a caveat: the AWS CLI does not use the system CA trust root from RHEL, CentOS, Fedora, and similar Linux distributions. This forces you to disable TLS validation, by adding the --no-verify-ssl switch to all AWS commands, which is not a good thing.
Assuming your machine is already configured with the proper root CA for the TLS certificate of your OpenShift cluster, you can make TLS validation work by set one more environment variable:
$ export AWS_CA_BUNDLE=/etc/pki/tls/certs/ca-bundle.crtThe path above is the default CA root from Fedora and its downstream Linux distributions. Change it to match the path of the CA root on your environment. Avoid at all costs to access anything, including the OpenShift web console, with TLS validation turned off.
Now we can try uploading some data to our S3 bucket:
$ aws s3 --endpoint https://$BUCKET_HOST ls
2024-07-04 13:07:52 userbucket-3748b788-f16f-4deb-a84c-6b5666362a75
$ aws s3 --endpoint https://$BUCKET_HOST ls $BUCKET_NAME
$
$ echo "testing: 1, 2, 3" > localfile.txt
$ aws s3 --endpoint https://$BUCKET_HOST cp localfile.txt s3://$BUCKET_NAME
upload: ./localfile.txt to s3://userbucket-3748b788-f16f-4deb-a84c-6b5666362a75/localfile.txt
$ aws s3 --endpoint https://$BUCKET_HOST ls $BUCKET_NAME
2024-07-04 13:11:02 17 localfile.txtNotice that the first aws s3 ls command has no output because the bucket is initially empty.
If you use the AWS credentials from an OBC, you can only upload and download data from a single S3 bucket. This may be sufficient for development and testing, especially because you do not have to learn how to manage and configure S3 storage: just use the OBC custom resource type. But if you wish, you can also retrieve S3 administrator credentials from the Multi-Cloud Object Gateway.
Creating and accessing object buckets as an S3 storage administrator
If you know your S3 and need more flexibility than provided by OBCs, you can retrieve the MCG administrator credentials and use S3 API commands to create and configure buckets. You can also use S3 APIs to configure AWS credentials and ACLs on S3 buckets and objects. Advanced S3 features, such as events, versioning, and WORM, are also available.
To retrieve the Multi-Cloud Object Gateway administration credentials, you need access to the openshift-storage project, which usually means being a cluster administrator. The credentials are inside the noobaa-admin secret.
The following commands set AWS environment variables with MCG administrator credentials:
$ export AWS_ACCESS_KEY_ID=$(oc get secret noobaa-admin -n openshift-storage -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d)
$ export AWS_SECRET_ACCESS_KEY=$(oc get secret noobaa-admin -n openshift-storage -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d)And, as a cluster administrator, you can also get the S3 API endpoint directly from the OpenShift Data Foundation route:
BUCKET_HOST=$(oc get route s3 -n openshift-storage -o jsonpath='{.spec.host}')The following commands create a new bucket and demonstrate that the MCG administrator also has access to the bucket from the OBC in previous examples:
$ aws s3 --endpoint https://$BUCKET_HOST ls
2024-07-04 13:12:37 userbucket-3748b788-f16f-4deb-a84c-6b5666362a75
2024-07-04 13:12:37 first.bucket
$ aws s3 --endpoint https://$BUCKET_HOST mb s3://another-bucket
make_bucket: another-bucket
$ echo 'another test 3, 2, 1' > local-admin-file.txt
$ aws s3 --endpoint https://$BUCKET_HOST cp local-admin-file.txt s3://another-bucket/another-test.txt
upload: ./local-admin-file.txt to s3://another-bucket/another-test.txt
$ aws s3 --endpoint https://$BUCKET_HOST ls
2024-07-04 13:13:50 another-bucket
2024-07-04 13:13:50 userbucket-3748b788-f16f-4deb-a84c-6b5666362a75
2024-07-04 13:13:50 first.bucket
$ aws s3 --endpoint https://$BUCKET_HOST ls userbucket-3748b788-f16f-4deb-a84c-6b5666362a75
2024-07-04 13:11:02 17 localfile.txt
$ aws s3 --endpoint https://$BUCKET_HOST cp local-admin-file.txt s3://userbucket-3748b788-f16f-4deb-a84c-6b5666362a75/admin-test.txt
upload: ./local-admin-file.txt to s3://userbucket-3748b788-f16f-4deb-a84c-6b5666362a75/admin-test.txt
$ aws s3 --endpoint https://$BUCKET_HOST ls userbucket-3748b788-f16f-4deb-a84c-6b5666362a75
2024-07-04 13:14:37 21 admin-test.txt
2024-07-04 13:11:02 17 localfile.txtWhen you try the previous commands, be sure to replace the hash on userbucket with the correct hash generated by your environment.
If you noticed, Multi-Cloud Object Gateway initializes its PVC storage with a bucket named first.bucket. It does that to check that it has write access to its storage backends.
If you go this way, you have to learn a lot more about MCG because you will have to configure additional access credentials and ACLs. After all, you do not wish to let all your users share the same S3 administration credentials and mess with each other’s objects.
Wrap up
If you are an OpenShift user, it’s quick and easy to deploy the Multi-Cloud Object Gateway from OpenShift Data Foundation to enable S3 storage for your developers and data scientists and them use Object Bucket Claims (OBC) to provision S3 buckets.
Even if they aren’t OpenShift users they can still access S3 buckets from MCG using their local machines and standard S3 tools or Jupyter notebooks: just provide your users with the S3 connection parameters and AWS credentials generated by MCG. You don’t need a real cloud provider account and pay cloud provider bills to consume S3 storage.
The Multi-Cloud Object Gateway from OpenShift Data Foundation is based on the open source project NooBaa. OpenShift Data Foundation integrates the NooBaa operator that manages NooBaa on Kubernetes. For an even lighter deployment of NooBaa, and if you are not afraid of building it from sources, you can try the NooBaa core subproject. NooBaa-core provides alternative ways to deploy and run NooBaa without Kubernetes, for example, by running the noobaa-core nsfs command.
For more information about managing S3 storage with the Multi-Cloud Object Gateway, please review the Managing hybrid and multicloud resources guide inside the OpenShift Data Foundation product documentation and the NooBaa upstream documentation.
Thanks to Aaren Wong, Eran Tamir, and Javier Barea Palma for reviewing drafts of this article.
