This second article continues a series discussing Kubernetes storage concepts. I will define the concepts of volumes, persistent volume claims, and storage classes, and why they should matter to a developer. I will also explain how persistent volumes and storage provisioners enable system administrators to manage storage for a Kubernetes cluster while offering developers self-service to storage. You will also discover the special abilities of stateful sets.
Follow the series:
The first part of this series explains why storage is essential, even for developers developing "stateless" applications based on microservices architectures. I also explain the role of Kubernetes in managing and providing storage volumes for applications running as pods.
I describe the unique needs of containerized applications. You will discover how CSI drivers enable advanced storage features necessary for production environments and are useful for CI/CD pipelines.
3 concepts of Kubernetes storage for developers:
There are three main concepts of Kubernetes storage that developers must know to facilitate collaboration with system admins and to improve connections between applications and Kubernetes storage services:
1. Which volume types to use and which to avoid
Storage in Kubernetes originally started with just a volume attribute inside a pod resource. Multiple containers from a pod can mount the same volume, possibly in different paths, because each container has its own isolated file system.
Kubernetes originally defined many volume types that connect to different storage services and protocols, such as AWS EBS or FibreChannel LUNs (Figure 1). It would be best if you avoided most volume types because they embed environmental data, such as an iSCSI initiator address, which is not very flexible for system administrators. You do not want to change your manifests because one environment uses OpenStack cinder disks, another uses NFS, or the NFS server address differs between data centers.

Some volume types, such as emptyDir and downwardAPI, have valid uses. You can also use volumes for run-time access to configuration data from ConfigMaps and secrets. But for persistent data stored as disk files, you should focus on the persistent volume claim (PVC) volume type as the general-purpose mechanism to configure storage for an application.
2. PVC: Best volume type for persistent data storage
A persistent volume claim (PVC) resource represents a request for storage by an application. A persistent volume claim specifies desired storage characteristics, such as capacity and access mode. It does not specify a storage technology such as iSCSI or NFS. With the persistent volume claim volume type, the only configuration setting is the name of a persistent volume claim resource in the same namespace as your pod.
The lifecycle of a PVC is tied not to a pod but a namespace. Multiple pods from the same namespace but potentially different workload controllers can connect to the same PVC. You can also sequentially connect and detach storage to different application pods as you need to initialize, convert, migrate, or back up data.
Kubernetes matches each persistent volume claim to a persistent volume (PV) resource that can satisfy the requirements of the claim (Figure 2). It is not an exact match. A PVC could be bound to a PV with a larger disk size than requested, and a PVC that specifies single access could be bound to a PV that is shareable for multiple concurrent accesses. PVCs do not enforce policy but declare what an application needs, which Kubernetes provides on a best-effort basis.
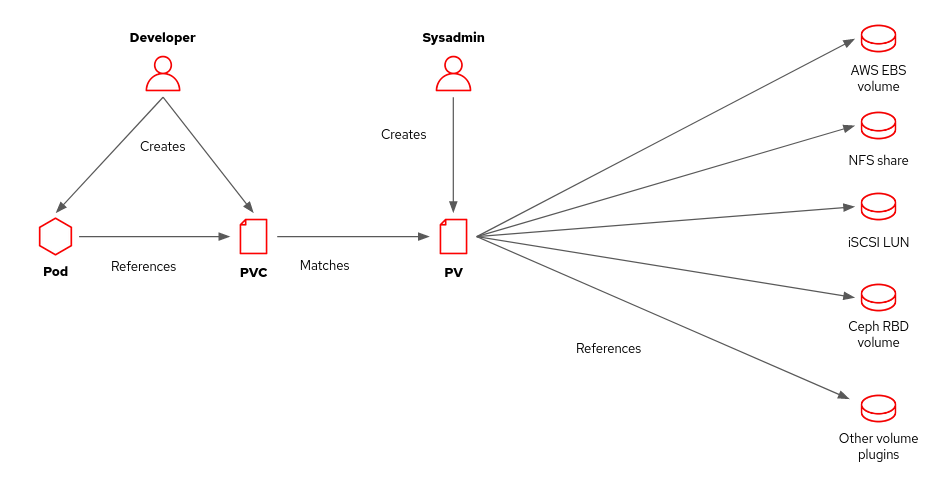
Even if your PVC specifies a size, storage space might not be guaranteed or reserved for your application. The result depends on the underlying storage technology. For example, the same shared volume in a file server backs multiple volumes, or thin volumes could back them from a Ceph RBD server.
In the old days of Kubernetes, a cluster administrator created a set of PV resources in advance as a pool of volumes available for application requests. From time to time, the administrator must create more space and find and clean up unused volumes. That process was called manually provisioned storage.
Each manually provisioned PV specifies all the parameters required for access to a storage service or server: AWS IAM credentials for EBS volumes or an NFS server address and share path. This practice is good for separating concerns because the cluster administrator decides which types of storage are available and isolates developers from all connection parameters required for access to each storage service. However, manual provisioning places a large workload on system administrators.
3. Storage classes
PVs and PVCs improved over the initial feature of volume types from Kubernetes but still required a lot of labor from IT. So Kubernetes incorporated dynamic volume provisioners, which create persistent volumes on demand to match persistent volume claims.
Under this system, PVCs do not specify provisioned storage but instead refer to a storage class (Figure 3). Cluster administrators create storage classes as required to manage different storage services or different storage tiers of the same service. Each storage class specifies a storage provisioner and the connection parameters the provisioner accepts.

For example, one storage class might connect to an NFS server and another to a Fibre Channel Storage Area Network (SAN). By specifying the corresponding class, PVCs connect to the desired storage service.
In another example, one storage class might specify the Azure Standard HDD disk type, and another might specify the Azure Premium SSD disk type. By choosing between these classes, a developer picks either cheaper or higher-performance storage.
A dynamic storage provisioner connects to the storage service to perform any task that might be required to make storage available. The task could require creating a new LUN that matches the size of a PVC or just mounting a shared folder.
Dynamic storage provisioners make storage a self-service in Kubernetes, alleviating the workload on system administrators and enabling agility for developers.
As a developer, you might not require access to any network storage service during development. Your local Kubernetes cluster might use a minimal storage provisioner that uses host folders or disk partitions. So you can test your application using the same PVC resources and pod manifests as the production environment. Or your local Kubernetes cluster might come preconfigured with a set of manually provisioned PVs.
Persistent volumes vs. stateful set workload controllers
A common misconception among developers is that you must use stateful set workload controllers to manage pods that require persistent storage. Other workload controllers, such as a job or a deployment, can manage pods that mount volumes from PVCs.
For example, when running a single database pod, it is perfectly fine to use a deployment resource to manage a relational database pod. If you need to manage a relational database running as multiple pods, you probably require more than the capabilities of a Kubernetes stateful set alone. Do not underestimate the complexity of such configurations.
Kubernetes stateful sets alone do not make any application magically capable of using high-availability and scalability features such as replication, sharding, and distributed transactions. The application has to be designed and configured for such features.
A few application needs might match stateful set features, such as the Cassandra example from Kubernetes documentation. Unfortunately, most databases require fine-tuned settings for each instance or pod, and stateful sets do not provide a clean way of feeding these per-instance settings.
You can craft startup scripts that configure databases to work as part of a stateful set, such as in the replicated MySQL example from Kubernetes documentation; it isn't trivial. Instead of creating those snowflakes, you might consider using a specialized controller for your database workload, such as the CrunchyData PostgreSQL operator.
So what is the difference between a stateful set and other Kubernetes workload controllers regarding persistent storage? The difference is that a stateful set allows each pod to use separate storage.
Most workload controllers include only a pod template, which refers to one or more PVCs. The workload controller does not manage these PVCs. If you create multiple pods from the same template, as in a deployment with more than one replica, these pods refer to the same set of PVCs. They are all sharing the same volumes and their files.
Unlike other workload resources, stateful sets include an array of PVC templates in addition to a pod template. Scaling a stateful set creates a set of PVCs for each pod (Figure 4). Each pod gets its dedicated set of volumes and doesn't share files with other pods from the same stateful set—at least not from the volumes managed by the stateful set. You can still refer to PVCs not managed by a stateful set.

Kubernetes facilitates developer and system administrator collaboration
The main concepts that a developer needs to know about storage in Kubernetes are volumes in pods, persistent volume claims, and storage classes. Persistent volumes and storage provisioners are the domain of system administrators. But knowledgeable developers can collaborate more effectively with administrators to ensure that applications work as designed under load. Developers can also plan how to handle disaster recovery and data sharing between applications.
The final article of this series, Why CSI drivers are essential in Kubernetes storage, completes the presentation of essential Kubernetes storage concepts by introducing CSI drivers. The article emphasizes the need for storage products designed for Kubernetes versus storage designed for traditional physical and virtual data centers or Infrastructure-as-a-Service (IaaS) clouds.
Thanks a lot to Andy Arnold and Greg Deffenbau for their reviews of this article.
Last updated: October 31, 2023