Red Hat OpenShift Data Foundation is a key storage component of Red Hat OpenShift. It offers unified block, file, and object storage capabilities to support a wide range of applications.
One of the new exciting features in OpenShift Data Foundation 4.14 is OpenShift Data Foundation Regional Disaster Recovery (RDR), which offers RDR capabilities for Rados Block Device pools (RBD pools) and Ceph File System (CephFS) (via volsync replication) pools. With RBD images replicated between clusters, OpenShift Data Foundation RDR protects customers from catastrophic failures. With OpenShift Data Foundation RDR, we can:
- Protect an application and its state relationship across Red Hat OpenShift clusters.
- Failover an application and its state to a peer clusters.
- Relocate an application and its state across peer clusters.
In this article, we will summarize the test results collected during OpenShift Data Foundation RDR testing from a resource utilization point of view and define recommendations that can serve as best practices when sizing an OpenShift Data Foundation RDR environment. Our testing focused mainly on the scalability of the OpenShift Data Foundation RDR solution. More information about Red Hat OpenShift and OpenShift Data Foundation RDR, including configuration instructions, can be found in the official OpenShift Data Foundation disaster recovery (DR) documentation.
Summary objectives
In OpenShift Data Foundation 4.14, we focused our performance tests on a configuration of up to 100 RBD images being replicated between primary and secondary clusters. The goal was to estimate the resource requirements needed when planning an OpenShift Data Foundation DR environment and to offer best practice recommendations for such a configuration.
OpenShift Data Foundation DR, when enabled, will introduce a new object DRPolicy which defines drclusters and schedulinginterval. The drclusters in DRPolicy defines what clusters will be part of the OpenShift Data Foundation DR solution and the schedulingInterval defines the frequency of asynchronous data replication between the clusters.
We tested different schedulinginterval within DRPolicy and we concluded that schedulinginterval:15m is the optimal scheduling interval. Shorter scheduling intervals are possible and they can be used when creating DRPolicy, but we find such high cadence replication tends to be highly resource consuming. Hence, such configurations were not the focus of this particular test. In OpenShift Data Foundation RDR 4.14 the recommended schedulinginterval is 15 minutes.
From a scalability point of view, we can say that mirroring 100 RBD images at the time of writing this document can be considered working with schedulinginterval:15m, which was used in our tests. We plan to run more extensive tests in future OpenShift Data Foundation DR releases and scale beyond 100 RBD images replicated between primary and secondary clusters.
When planning OpenShift Data Foundation DR deployment it is necessary to pay attention to storage requirements on clusters and CPU/memory limits for the rook-ceph-rbd-mirror pod.
Test environment configuration
Software used for testing:
- OpenShift Data Foundation 4.14 as part of Red Hat OpenShift 4.14 cluster.
Hardware configuration:
- Red Hat OpenShift 4.14 was installed on bare metal clusters, and on top of it we configured Red Hat OpenShift Data Foundation clusters.
Testing procedure
In the test scenario, 100 pods were created and each of them mounted one Persistent Volume Claim (PVC) and we used this mounted PVC inside every pod as a location where we send read/write operations during the test. PVC claims were created using the default block ocs-storagecluster-ceph-rbd storage class.
The test duration was 2 hours. During this time we ran extensive mixed randrw (random read/write) operations (70% write, 30% read) on the primary cluster and OpenShift Data Foundation DR provided data replication between clusters. Both clusters were monitored during this time for storage space consumption, CPU limits, and memory consumption. Overall change rate for 100 pods generating load was approximately 400 GB within a schedulinginterval:15m. This is important because we need to know how much data was generated/changed so we can actively propose desired sizing.
We wanted to find the requirement from a storage, CPU and memory resource perspective when deploying OpenShift Data Foundation DR. With a test duration of 2h we wanted to avoid bias which could be introduced in short running tests.
How does OpenShift Data Foundation disaster recovery work?
OpenShift Data Foundation DR replicates data asynchronously (not real time sync) at schedulinginterval sample. We tested schedulinginterval:15m and storage requirements from snapshots point of view were observed. We also monitored CPU and memory usage for the rook-ceph-rbd-mirror pod which is responsible for syncing operations between OpenShift Data Foundation DR clusters.
Replication works in “pull mode” from the secondary cluster, and the rook-ceph-rbd-mirror pod on the secondary cluster is responsible for pulling data from the primary cluster. OpenShift Data Foundation storage operators synchronize both volume persistent data and Kubernetes metadata for PVs (Persistent Volumes).
Currently the rook-ceph-rbd-mirror resource default limits are 1 CPU and 2 GB of memory. Our test covered different configurations for the rook-ceph-rbd-mirror pod in order to compare and prove whether different resource limits help with RBD mirror performance. We will present these results further in the document.
DRpolicy defines async policy between two drClusters that are part of an OpenShift Data Foundation DR solution and also async schedulinginterval will be used for volumereplications when replicating data between primary and secondary clusters.
When a volumereplication object is created on the primary cluster for a particular PVC, it will start the OpenShift Data Foundation DR process for it. More about OpenShift Data Foundation DR concepts are possible to find in the OpenShift Data Foundation DR documentation. A high level view of Red Hat OpenShift and OpenShift Data Foundation DR can be depicted as presented in Figure 1.
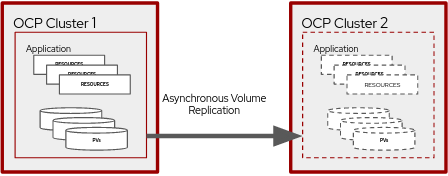
Resource requirements
When planning an OpenShift Data Foundation DR installation, one main consideration is to figure out the requirements necessary for the OpenShift Data Foundation DR setup. An OpenShift Data Foundation DR setup is built on top of Red Hat OpenShift/OpenShift Data Foundation installation, and the following section covers the resource requirements for a successful deployment of OpenShift Data Foundation DR in such an environment. We describe various resource (like storage, CPU, and Memory) utilization and describe the best practices in order to effectively use the same.
Storage space requirements
In a typical OpenShift Data Foundation DR environment, applications will write data to the primary OpenShift Data Foundation cluster and then these updates will be pulled to the secondary cluster on an interval basis. For the primary cluster we have to consider the impact to free space within the cluster since OpenShift Data Foundation DR will create and maintain 5 mirror-snapshots for every protected PVC (RBD image)—these are created on schedulinginterval intervals as long as there are changes in the dataset—e.g. an application is writing new data to the primary cluster.
OpenShift Data Foundation DR will keep 5 mirror-snapshots on the primary cluster, and afterwards the oldest image snapshot is automatically removed if the limit of 5 mirror-snapshots is reached. For OpenShift Data Foundation DR we recommend to keep the default of five mirror-snapshots.
If OpenShift Data Foundation DR is disabled or corresponding images are removed, OpenShift Data Foundation DR will automatically clean up mirror-snapshots.
It is important to understand when OpenShift Data Foundation DR is enabled on a particular pool with many PVCs containing a big dataset it can influence free space on the underlying Ceph cluster due to OpenShift Data Foundation DR mirror-snapshots creation.
We also want to point out that the current default value of 5 mirror-snapshots might be reduced to a lower number of mirror-snapshots created in future OpenShift Data Foundation DR releases.
Primary cluster storage requirements
The primary OpenShift Data Foundation DR cluster, as stated above, will maintain 5 mirror-snapshots of the dataset for the entire time the dataset is changing and when there are differences which need to be replicated to the secondary cluster.
Secondary cluster storage requirements
After dataset replication from primary to secondary cluster, the secondary cluster will create a single snapshot of the dataset and it is also necessary to take this into consideration when calculating storage space requirements on the secondary cluster.
Based on the above explanation we created the table below to demonstrate the storage space requirements.
Table 1: Storage requirements for OpenShift Data Foundation DR primary and secondary cluster.
|
Storage requirements |
Primary cluster |
Secondary cluster |
|
Dataset |
5 x Dataset |
2 x Dataset |
It can be considered by some that 5 mirror-snapshots can be overwhelming for a primary cluster, but this is chosen with data safety and persistence in mind, and we recommend using the default value for rbd_mirror_concurrent_image_syncs pool parameter.
For the secondary cluster this requirement is not so strict and it will create only one mirror-snapshot on top of the dataset. It is also recommended to have proper monitoring in place and monitor free space on OpenShift Data Foundation clusters independently of OpenShift Data Foundation DR.
As a general recommendation here we can say that when OpenShift Data Foundation DR is enabled and mirror-snapshot creations start, it must not cause the underlying storage system to approach close to its maximum available storage.
Particularly we have to be sure that none of the full_ratio, backfillfull_ratio, or nearfull_ratio parameters should fire an alert after OpenShift Data Foundation DR is enabled. More about ceph alerts can be found in Ceph documentation.
Current values for these parameters are as stated below:
full_ratio 0.85
backfillfull_ratio 0.8
nearfull_ratio 0.7
We can say that from a free storage capacity perspective, it is necessary to take into account the above recommendations when planning OpenShift Data Foundation DR deployments on customer sites.
CPU recommendations
OpenShift Data Foundation DR works in pull mode where changes are pulled from primary cluster by the secondary cluster at every schedulinginterval. This makes it really important to monitor RBD mirror pod CPU usage on the secondary cluster.
Default CPU limit for the rbd mirror pod in OpenShift Data Foundation DR is 1 CPU and memory limit is 2 GB of RAM.
For most cases 1 CPU for rook-ceph-rbd-mirror pod is sufficient, however it was noticed that data synchronization from the primary to secondary cluster will be faster if the rbd-mirror pod on the secondary cluster has allocated 2 CPUs. Increasing requests/limits for the rook-ceph-rbd-mirror pod from 1 to 2 CPUs speeds up the sync process by around 20%. We see the comparison for this test in Figure 2.
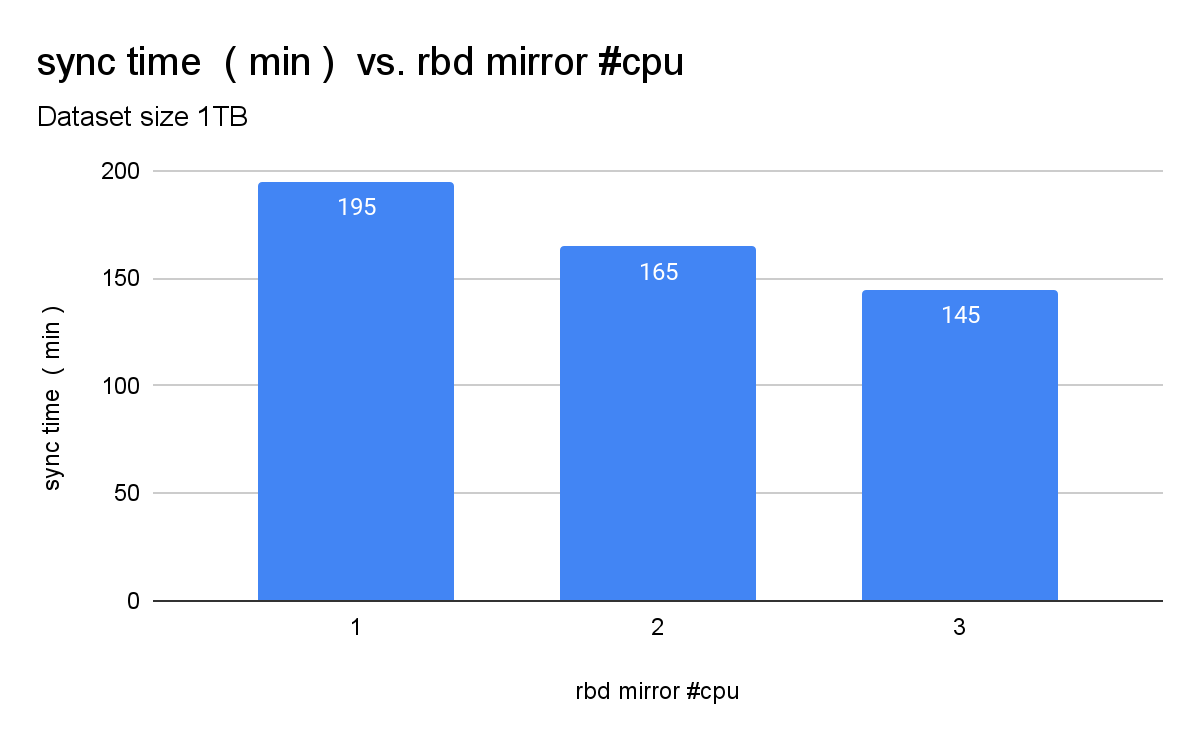
With a limit of 2 CPUs for the rbd-mirror pod, data replication will be faster and if cluster capacities allow, our recommendation is to increase rbd-mirror CPU limits to 2 CPU.
We also ran additional tests with a 3 CPU limit for the rook-ceph-rbd-mirror pod. For this test case we noticed faster data synchronization between the primary and secondary cluster. For cases when the recommended CPU limit of 2 CPU for the rook-ceph-rbd-mirror pod are not enough, and if there are enough spare resources in that case, assigning a 3 CPU limit for rook-ceph-rbd-mirror pods can be beneficial. Increasing rook-ceph-rbd-mirror pod limits beyond 3 CPUs did not result in linear reduction of synchronization time in our tests.
Increasing the CPU limit for the mirror pod from 1 to 2 caused synchronization time to be faster by around 20% if compared to a limit of 1 CPU for the rook-ceph-rbd-mirror pod, and increasing the rook-ceph-rbd-mirror pod limit to 3 CPUs reduced synchronization time by an additional 10%.
Based on the above data we see that changing CPU limits for rook-ceph-rbd-mirror pods from 1 CPU to 2 CPUs reduces synchronization time and in busy environments it is recommended to consider this option to increase CPU limits for rook-ceph-rbd-mirror pods.
Our tests did not detect issues with memory limits of the rook-ceph-rbd-mirror pods. The current default limit of 2 GiB proved sufficient for the workload we tested and we recommend keeping it.
Conclusions
- We have to plan properly for storage space on the primary and secondary clusters. The primary cluster is currently more affected with storage requirements due to the 5 mirror-snapshots OpenShift Data Foundation DR creates. It is necessary to take into consideration that once OpenShift Data Foundation DR is enabled it should not cause any of
full_ratio,backfillfull_ratio, ornearfull_ratioCeph alerts to report errors because of this action, so plan accordingly. - It is important to understand that if you decide to use a shorter
schedulingintervalthan the default of 15m for cases where big datasets are replicated with high change rates, it can cause problems related to storage free space on the primary cluster. rook-ceph-rbd-mirrorpod will benefit if its CPU limits are increased to 2. There might be different configurations for OpenShift Data Foundation DR—e.g., where the secondary cluster acts as primary for some PVCs and this means that defining a CPU limit of 2 for rbd-mirror pods across the whole OpenShift Data Foundation DR setup is fine.- Current memory limits for rbd-mirror pods of 2 GB were sufficient during our tests. Using integrated Red Hat OpenShift tools like Prometheus or other custom made observability tools helped us monitor these test cases. We recommend you monitor memory utilization and adapt the request/limit as necessary.
- OpenShift Data Foundation will perform better if it has more OSDs available in the cluster and if network latency is low.