There are many different factors to consider when using Red Hat OpenShift Data Foundation to set up a storage cluster. This article dives into some specifics to consider when building a production-grade resilient scalable deployment of OpenShift Data Foundation. We'll need to dig into the following points to design and build out a suitable deployment architecture:
- What does the underlying platform environment look like in terms of architecture/topology/design?
- What underlying storage is available and how is that presented?
- Replication options.
To start, if you're new to OpenShift Data Foundation, please see the architecture documentation to get a high level understanding of what the operator provides and is doing. Under the covers, OpenShift Data Foundation uses Rook and Ceph. If you are unfamiliar with Ceph, it is essentially a software-defined storage system that was designed to be set up on commodity hardware to where multiple physical servers with attached disks are clustered together. It's worth reviewing this Introduction to Ceph and spending some time getting to grips with its core architecture and components beforehand to gain some familiarity with its concepts.
When running Ceph on Kubernetes, OpenShift Data Foundation automates the deployment, but it is not a silver bullet. Understanding how the cluster is spread across the underlying infrastructure and where the actual storage comes from is of paramount importance for a successful design and deployment.
As a reference, for supportability specifics, the knowledge-centered service (KCS) article Supported configurations for Red Hat OpenShift Data Foundation 4.X should cover any possible confusion of what can and can’t be done.
Topology
Regardless of how the storage is presented, be that through some existing dynamic storage class or directly attached disks, it is critical to have a fault tolerant topology. You need to first consider:
- How many storage nodes you want in the cluster
- How many OSDs (disks) per node
- Where the nodes are located
The above points are the main elements which define the underlying Ceph configuration and thus the placement groups and controlled replication under scalable hashing (CRUSH) maps that get created by the operator.
If you just install OpenShift Data Foundation without much thought and label seemingly random nodes as storage nodes, it will work, although the topology may be poor. For example, you may have multiple nodes in the same availability zone and fail to spread the data evenly across failure domains. OpenShift Data Foundation relies on building its topology based on node labels. The node labels that are used to form the topology in hierarchical order from highest to lowest are:
topology.kubernetes.io/region
topology.kubernetes.io/zone
topology.rook.io/datacenter
topology.rook.io/room
topology.rook.io/pod
topology.rook.io/pdu
topology.rook.io/row
topology.rook.io/rack
topology.rook.io/chassisThe region, zone, and rack labels are more commonly used, with OpenShift Data Foundation primarily utilizing zone and rack labels to determine the topology of Ceph pools. While other labels contribute to the CRUSH hierarchy for OSDs, the pools created by OpenShift Data Foundation do not utilize these other labels as failure domains, unlike zones and racks.
The Kubernetes region and zone labels are common node labels. Depending on your cloud/underlying platform, you may find your nodes already have logical region/zone labels. The topology labels can help to correctly paint a picture of your cluster’s deployment to give Rook the information needed to deploy the Ceph topology. It may make most sense to leverage the Kubernetes region and zone labels where you can. For VMWare you may want to consider specifying regions and zones configuration for a cluster on vSphere if you hadn’t already. This will give your storage cluster some information on how it should deploy the Ceph cluster.
When the node labels are missing, the OpenShift Data Foundation operator makes a best effort to determine the failure domains automatically. The failure domain essentially defines how the data will be spread. For example, if zone labels are present for each of the nodes for three different zones, Ceph will spread the data replicas across the three zones. By adding node labels, you will ensure the optimal data resiliency instead of relying on distribution of data that does not have any topology information and would spread the data to random nodes.
Zone-based example
As an example, Figure 1 illustrates a topology containing three zones with two servers per zone with a single disk per node initially (with the potential to scale with additional disks per node). The topology and thus the failure zone is based upon the topology.kubernetes.io/zone label of the nodes.
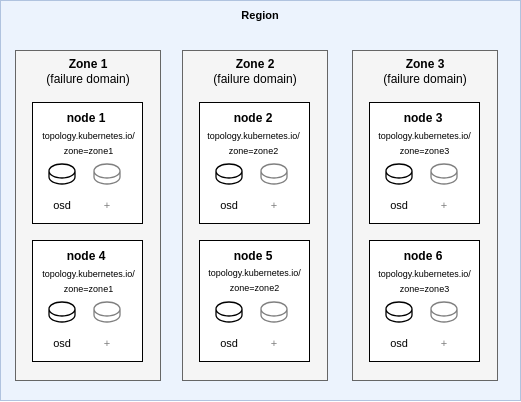
In a Ceph style layout, it would look like this:
.
└── region
├── zone (topology.kubernetes.io/zone=zone1)
| |── host: ocs-deviceset-0-data
| | └── osd
| └── host: ocs-deviceset-4-data
| └── osd
├── zone (topology.kubernetes.io/zone=zone2)
| |── host: ocs-deviceset-1-data
| | └── osd
| └── host: ocs-deviceset-3-data
| └── osd
└── zone (topology.kubernetes.io/zone=zone3)
|── host: ocs-deviceset-2-data
| └── osd
└── host: ocs-deviceset-5-data
└── osdElaborating on this example, the default block pool has a total replica count of 3 with 1 replica per zone (in this example, "zone" is the defined failure domain). When data is written to the cluster it will be stored on one OSD in each zone, so you have a total of 3 replicas of the data spread across the zones.
Flexible scaling
Flexible scaling is a feature that, if enabled in the StorageCluster, sets the failureDomain to host. This allows replicas to be distributed evenly across all nodes, regardless of distribution in zones or racks. This contrasts to the default behavior, in which OpenShift Data Foundation will use zones if already defined or automatically define three racks to simulate some topology. Enabling flexible scaling must be set during cluster creation since it would have a high impact on the Ceph pool creation and the CRUSH rule associated with the pool. Thus, modifying flexibleScaling in flight isn't possible and this won't change the relevant resources and the CRUSH rule of the pool.
If your CRUSH rule for the pool is based on a host failure domain, the distribution of data could be random depending on where the storage nodes sit. If you just have a 3 storage node setup and they are pinned to specific zones, it’s not of huge concern as a replica would live on each. However, If you're planning on running across more than 3 storage nodes using host for the CRUSH rule of the pool distribution will be random at node level. See Figure 2. If any zone or other topology labels are defined, topology will be ignored at their level. Only host-level distribution of data is enforced with the flexible scaling feature.
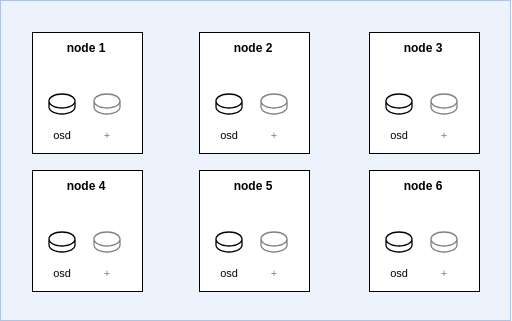
In a Ceph style layout, it would look like this:
.
└──
├── host: ocs-deviceset-0-data
| └── osd
├── host: ocs-deviceset-1-data
| └── osd
├── host: ocs-deviceset-2-data
| └── osd
├── host: ocs-deviceset-3-data
| └── osd
├── host: ocs-deviceset-4-data
| └── osd
└── host: ocs-deviceset-5-data
└── osdVerifying the topology
The following commands will show you how to validate that a pool is using the expected host, zone, or other level for its hierarchy. To run these commands, you can do so within the rook-ceph toolbox container. See How to configure the Rook-Ceph Toolbox.
To enable the rook-ceph toolbox pod (if not already enabled/running):
oc patch OCSInitialization ocsinit -n openshift-storage --type json --patch '[{ "op": "replace", "path": "/spec/enableCephTools", "value": true }]'Enter the pod:
oc rsh -n openshift-storage $(oc get pods -n openshift-storage -l app=rook-ceph-tools -o name)Display the OSD tree:
ceph osd df treeDisplay the pool with the replication factor and CRUSH rule:
ceph osd pool ls detailList all the CRUSH rules and the associated bucket for each pool:
ceph osd crush rule dumpUnderlying storage
If you're using bare metal (using actual raw storage) with the local storage operator, the topology can be quite simple to define to match your bare metal topology with hosts, racks, and zones. In other environments such as VMware in which devices are provisioned using a dynamic StorageClass, things may require further consideration. In VMware, if you're deploying using the default StorageClass , it will likely be either VSAN or VMFS. By using either of these, you could find yourself in a situation where replication on replication is happening. The extra level of replication will reduce performance so it’s worth it to spend some time looking at where your underlying storage for OpenShift Data Foundation is being presented from and what that means.
Replication policies/tiers
Replication requirements should be evaluated as not all workloads that require storage will be the same. You may wish to introduce a tier system to which would represent how the data is replicated. Some storage requirements may just be "scratch space", thus there is no point in keeping more copies of the data than what we need. Other application data may be quite important and thus you want more total assurance the data is fully replicated. With that in mind, you may want to define multiple storage classes each with a different pool, such as bronze/silver/gold tiers of replication.
In a simple default setup you’d have three nodes each with a single disk and the replica for each pool would be three. For each write in this setup, every OSD would keep a copy of the data. If these were 2TB disks, you’d have 2TB usable out of 6TB total. If you were to have multiple pools with different amounts of replicas then the usable space would depend on usage of each pool.
Out of the box you’ll find a default resource for the following resources :
CephBlockPoolCephFilesystemCephObjectStore
The failureDomain of all of these default pools in the cluster will be consistent with the zones or racks etc created in the topology previously. An example pool for block storage would look like this:
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
spec:
enableRBDStats: true
failureDomain: zone
replicated:
replicasPerFailureDomain: 1
size: 3
targetSizeRatio: 0.49This example would ensure three copies of the data exist in total with each copy being stored in a different zone (failureDomain), so if you lose one zone you would still have two copies of this data.
For support details on different replication options see: Data Availability and Integrity considerations for replica 2 pools and supported configurations.
Conclusion
An OpenShift Data Foundation storage cluster requires careful consideration of various factors, including the underlying platform environment, available storage, and replication options. Understanding the topology and how data is distributed across nodes and failure domains is crucial for achieving a resilient design. By leveraging node labels and configuring appropriate replication policies, you can ensure that your deployment is both fault-tolerant and scalable.
Last updated: June 20, 2024