We’ve been learning a lot about large language models (LLMs) and how they can be used with Node.js and JavaScript. If you want to follow what we’ve learned, you can check out this learning path that we put together on our journey so far: How to get started with large language models and Node.js.
In our initial learning we followed the most common path by using one of the most popular models from Hugging Face and using tools like ollama and node-llama-cpp to run the models. However, not all models are created equal, and there are a number of aspects that should be considered when choosing a model. The article "Why trust open source AI" is a good introduction to a number of them.
In that context we wanted to try out the Granite model and see what if any differences there were from using the models we’d used previously. We also thought it would be a good opportunity to explore Podman AI Lab as another way to run models.
Getting the Granite large language model running with Podman
We started by installing Podman Desktop. Podman Desktop provides a nice GUI where you can start and manage containers. It supports Windows, macOS, and Linux. Downloads are available from podman-desktop.io/downloads.
Once Podman Desktop was installed we went to the extensions pages, searched for “Podman AI,” and installed the Podman AI Lab extension as shown in Figure 1.
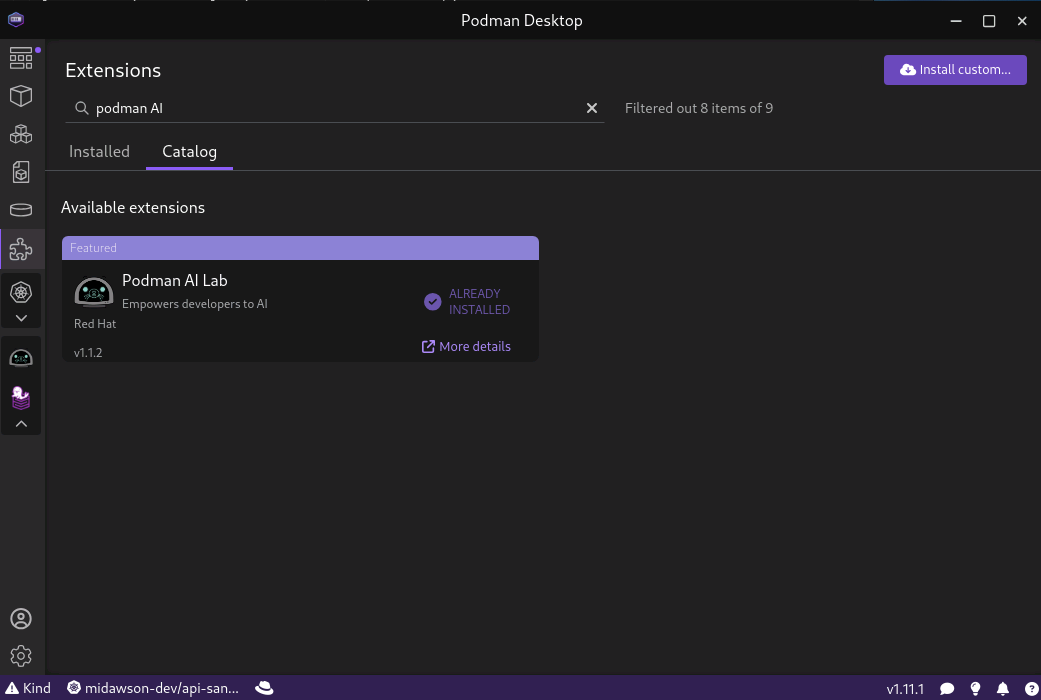
Once the AI Lab extension was installed we could see a new icon in the bar on the left as shown in Figure 2.
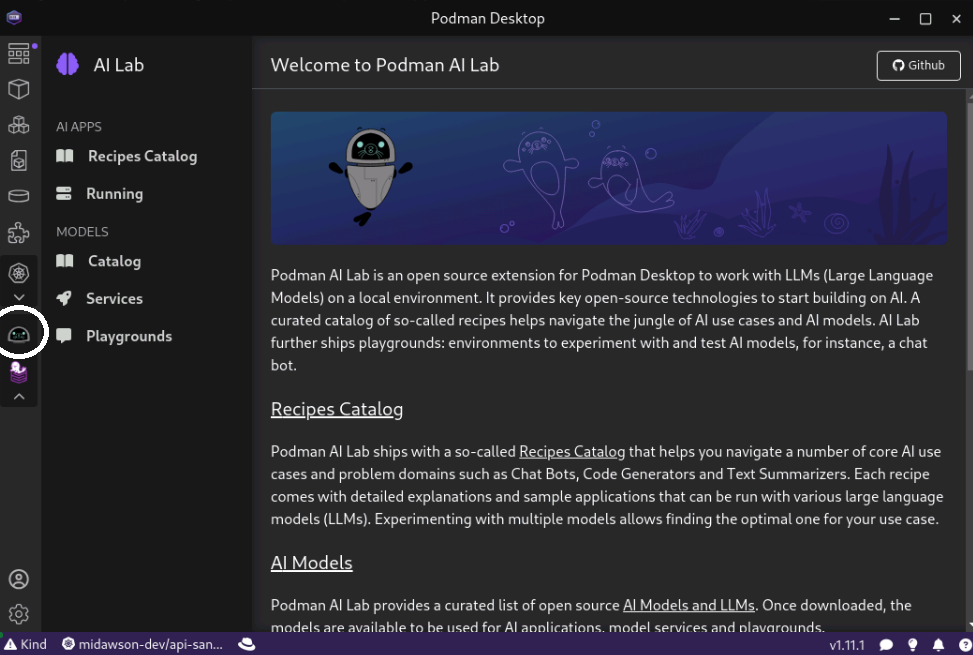
From that page we can go to the Catalog page. The Catalog page allows us to download the Granite model along with many other popular options, as shown in Figure 3.
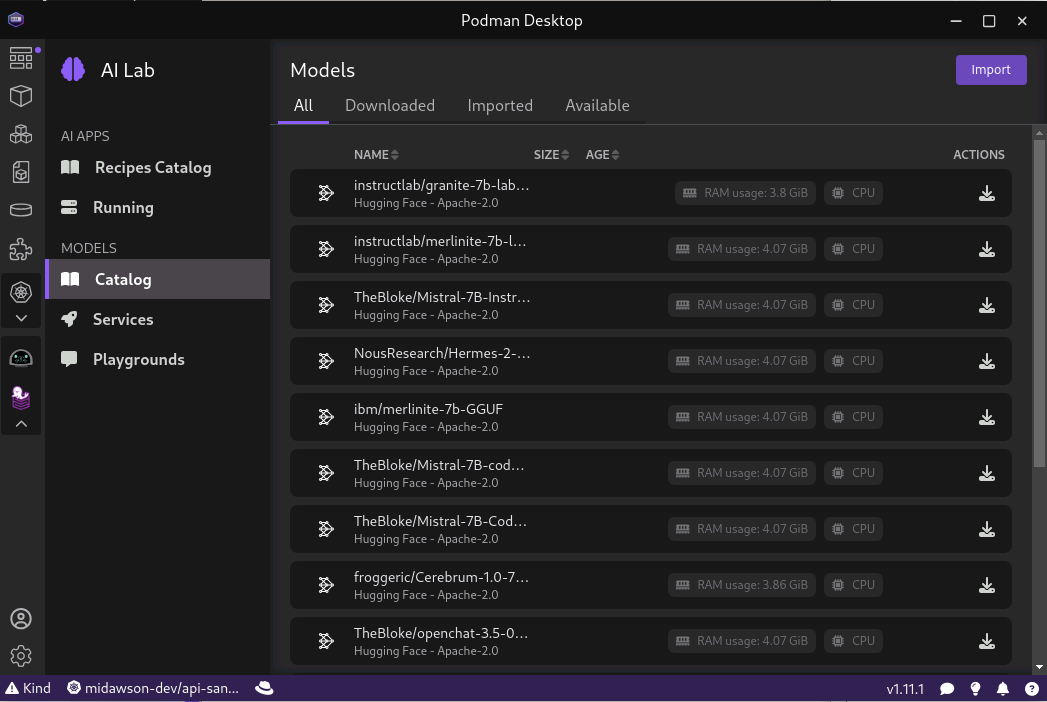
We used the download option on the far right hand side to download the Granite model. This can take a bit of time as the download is 3.8G in size. Once you ask for the model to be downloaded it will begin to download as shown in Figure 4.
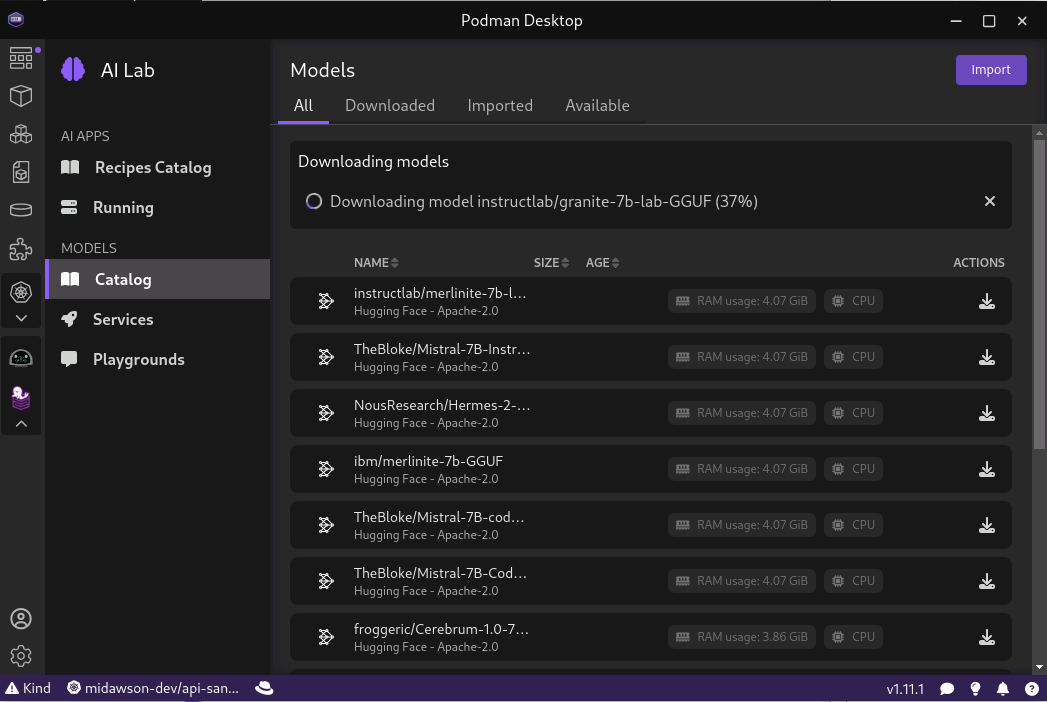
Models can also be downloaded from Hugging Face and imported, but it is nice that it's easy to download the Granite and other popular models without having to do that.
Once the model is downloaded, Podman AI Lab allows us to easily serve the model with an OpenAI compatible endpoint using a service.
Figure 5 shows the Services page.
We asked that a new service be created, which will serve the Granite model we had downloaded earlier. This is shown in Figure 6.
Once complete, we can open the service details to get the URL that we’ll need to access the model, as shown in Figure 7.
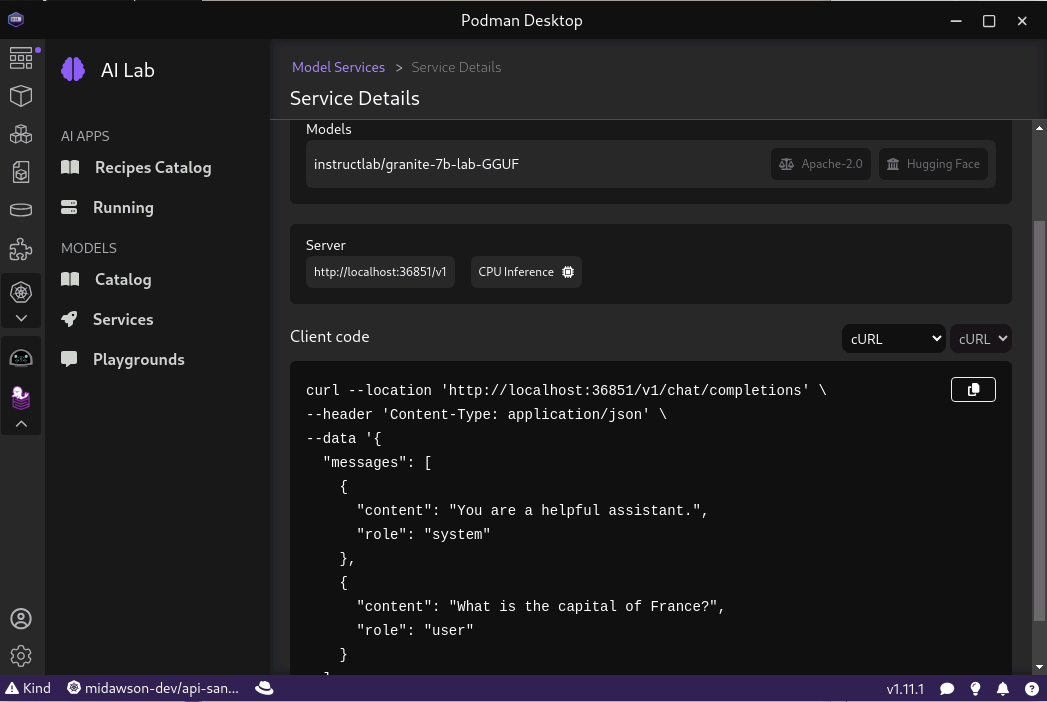
The URL being: http://localhost:36851/v1/chat/completions. We now have the Granite model being served by an endpoint available locally.
Trying out the Granite large language model with Node.js
Next we wanted to see how the Granite model worked with the Node.js and Langchain.js based Retrieval Augmented Generation (RAG) example that we had experimented with earlier.
We started by cloning the ai-experimentation repository:
git clone https://github.com/mhdawson/ai-experimentation.gitWe then went into the lesson-3-4 directory and edited the file langchainjs-backend.mjs to point to the local URL on which the Granite model was being served by Podman. This diff shows the changes we made:
diff --git a/lesson-3-4/langchainjs-backends.mjs b/lesson-3-4/langchainjs-backends.mjs
index dd71cb7..e6048aa 100644
--- a/lesson-3-4/langchainjs-backends.mjs
+++ b/lesson-3-4/langchainjs-backends.mjs
@@ -42,9 +42,9 @@ console.log("Augmenting data loaded - " + new Date());
////////////////////////////////
// GET THE MODEL
-const model = await getModel('llama-cpp', 0.9);
+//const model = await getModel('llama-cpp', 0.9);
//const model = await getModel('openAI', 0.9);
-//const model = await getModel('Openshift.ai', 0.9);
+const model = await getModel('Openshift.ai', 0.9);
////////////////////////////////
@@ -112,7 +112,7 @@ async function getModel(type, temperature) {
{ temperature: temperature,
openAIApiKey: 'EMPTY',
modelName: 'mistralai/Mistral-7B-Instruct-v0.2' },
- { baseURL: 'http://vllm.llm-hosting.svc.cluster.local:8000/v1' }
+ { baseURL: 'http://localhost:36851/v1' }
);
};
return model;If you had looked at langchainjs-backend.mjs earlier you would have seen that it already supported switching between accessing a model served through node-llama-cpp, OpenAI, or Red Hat OpenShift AI. As the option for OpenShift AI used an OpenAI compatible endpoint, and the Podman AI Lab service also provides an OpenAI compatible endpoint all we had to do was:
- Switch the call to
getModel()to use the "Openshift.ai" option. Switch the
basedURLconfigured for the OpenShift.ai option ingetModel()to point to the base URL served by Podman AI Lab. From the URL we shared earlier, that would be:http://localhost:36851/v1
With those changes, we then ran the application with:
node langchainjs-backends.mjsFrom the output we can see the data for the Node.js reference architecture being loaded in order to support Retrieval Augmented Generation, the question being asked to the model, and the model responding with an answer that has been influenced by the Node.js reference architecture:
Loading and processing augmenting data - Wed Jul 03 2024 15:51:33 GMT-0400 (Eastern Daylight Saving Time)
Unknown file type: cors-error.png
Unknown file type: _category_.json
Unknown file type: _category_.json
Unknown file type: _category_.json
Augmenting data loaded - Wed Jul 03 2024 15:51:44 GMT-0400 (Eastern Daylight Saving Time)
Loading model - Wed Jul 03 2024 15:51:44 GMT-0400 (Eastern Daylight Saving Time)
2024-07-03T19:51:44.341Z
{
input: 'Should I use npm to start a node.js application',
chat_history: [],
context: [
Document {
pageContent: '## avoiding using `npm` to start application\n' +
'\n' +
'While you will often see `CMD ["npm", "start"]` in docker files\n' +
'used to build Node.js applications there are a number\n' +
'of good reasons to avoid this:',
metadata: [Object]
},
Document {
pageContent: "- One less component. You generally don't need `npm` to start\n" +
' your application. If you avoid using it in the container\n' +
' then you will not be exposed to any security vulnerabilities\n' +
' that might exist in that component or its dependencies.\n' +
'- One less process. Instead of running 2 process (npm and node)\n' +
' you will only run 1.\n' +
'- There can be issues with signals and child processes. You\n' +
' can read more about that in the Node.js docker best practices',
metadata: [Object]
},
Document {
pageContent: '```\n' +
'\n' +
'It should be noted that users and organizations can modify how `npm init` works, tailoring the resulting package.json to their needs. For more information on this, check out the [official docs](https://docs.npmjs.com/cli/v9/commands/npm-init)',
metadata: [Object]
},
Document {
pageContent: '* [Introduction to the Node.js reference architecture: Node Module Development](https://developers.redhat.com/articles/2023/02/22/installing-nodejs-modules-using-npm-registry)',
metadata: [Object]
}
],
answer: 'It is generally recommended to avoid using `npm` to start a Node.js application. While it may be convenient to use the `CMD ["npm", "start"]` syntax in Dockerfiles, there are several reasons to consider using an alternative approach:\n' +
'\n' +
'- **Simplified deployment**: By not relying on `npm`, you can avoid potential security vulnerabilities and reduce the number of components required to run your application. Additionally, you will only need to manage one process instead of two.\n' +
'- **Easier signal handling**: With a direct `node` command, you can better control signal handling and child processes, which can be especially important in production environments.\n' +
'\n' +
'However, it is essential to acknowledge that users and organizations can customize the `npm init` process to suit their specific needs. For more information on tailoring package.json, refer to the official [docs](https://docs.npmjs.com/cli/v9/commands/npm-init).\n' +
'\n' +
'In summary, while `npm` can be a convenient option, there are valid reasons to consider using an alternative approach for starting a Node.js application. The choice ultimately depends on your specific use case and requirements.'
}
2024-07-03T19:52:27.207ZNote that the run was a bit longer since we were not using GPU acceleration and were on a smaller machine.
Just like past runs with the mistral model we get an answer (the part after answer:) telling us to avoid using the npm command to start Node.js applications. This is a different answer than we get without the additional context provided from the Node.js reference architecture.
If you’ve not gone through the learning path and want to dive deeper into what a Node.js application using Langchain.js and Node.js looks like, you can look through the code in langchainjs-backend.mjs. It was good to see that we could use the existing Langchain.js based application with another method for serving a model (Podman AI desktop) and with a different model (Granite)
Wrapping up
As we mentioned in the introduction, we wanted to try out the Granite model and see what if any differences there were from using the models we’d used previously, and to do that using Podman AI Lab as another way to run models.
As you can see, the experience of using Podman AI Lab and the Granite model went well. It was easy to download and serve the model with Podman AI Lab, and the Granite model worked as expected with the Node.js and Langchain.js based application that implemented Retrieval Augmented Generation (RAG).
If you want to learn more about Node.js and AI you can check out AI & Node.js on Red Hat Developer.
If you would like to learn more about what the Red Hat Node.js team is up to in general, you can check out the Node.js topic page and the Node.js reference architecture.
Last updated: July 24, 2024