In the era of emerging Large Language Models (LLMs), we have all been impressed by how these new generations of AI models are capable of generating unbelievable results. The excitement is so significant that the industry is now at a turning point where we are witnessing the arrival of more and more LLMs, and we are experimenting with various ways to leverage these models for more specific use cases.
On one hand, part of the LLM industry focuses on creating new models and fine-tuning generic ones. On the other hand, another part of the industry leverages these emerging generic LLMs to create smarter applications.
As a non-data scientist, I’m fascinated by how developers can easily experiment with various scenarios to create smart applications using these generic models, simply by providing enough context and content. An emerging concept in this field is called Retrieval-Augmented Generation (RAG).
RAG enhances LLMs by providing access to live, up-to-date data, thus bridging gaps in their training. This approach enables the creation of highly personalized experiences tailored to specific business needs using proprietary enterprise data.
In the world of RAG, the current trend is using embedding stores, most commonly vector databases, where we can store data as vectors to efficiently retrieve relevant information. To create a production-ready application using RAG and vector databases, one needs to figure out the best solution for their use case to integrate the content properly into these vector databases.
One effective way to integrate data into vector databases is by using the Apache Camel. Apache Camel is the Swiss army knife of integration. It’s a versatile library capable of handling any sort of integration scenarios and can connect to almost any system. So, no matter where you are collecting your data from, and regardless of the format, frequency, or transformation needed, Apache Camel offers a solution for any scenario.
Apache Camel is an integration library that has been evolving for years with the industry. So it’s no surprise that in this new era it’s also evolving as the tech industry integrates LLMs into our architectures. New components have been recently introduced to Apache Camel to integrate with Langchain4j, Bedrock, and new vector databases such as Qdrant and Milvus. And this is just the beginning; one can expect many improvements as the AI industry continues to advance rapidly.
Let me introduce some of the ways you could use Apache Camel and Langchain4j to ingest your data into vector databases. I will showcase how to successfully and seamlessly integrate data into a Qdrant database. I will then leverage this content with RAG to demonstrate how easy it is to use a generic LLM to build a smart application with sufficient content.
Use Apache Camel to build ingestion pipeline
The biggest advantage of building a robust data ingestion pipeline with Apache Camel is the flexibility it offers. As a Camel developer hero, you can tailor your pipeline to match your specific scenario. With Apache Camel, you can:
- Connect to various data sources (e.g., databases, APIs, file systems).
- Apply any transformations to the collected data as needed using standard patterns (cleaning, normalizing, enriching).
- Convert the transformed data into vector representations using the new Camel Langchain4j Embedding component.
- Seamlessly ingest the vectorized data into the Qdrant database, thanks to the Embedding DataFormat for the Camel Qdrant component.
Moreover, by mastering your data pipeline yourself, you can better manage your embeddings and update or delete data from your database as your content evolves over time.
Example: creating a data ingestion pipeline from AWS S3
This pipeline will process data files stored in an AWS S3 bucket through a Camel Quarkus application, convert them into vector representations, and then ingest these vectors into a Qdrant database, as shown in Figure 1.
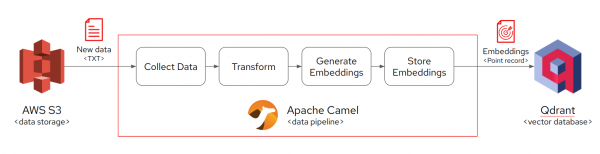
Here’s the Camel Route for this data ingestion pipeline:
from("aws2-s3://my-bucket")
// Convert the file content to a String
.convertBodyTo(String.class)
// Use Langchain4j to generate embeddings
.to("langchain4j-embeddings:test")
// Transform the data type to a format suitable for Qdrant
.transform(new DataType("qdrant:embeddings"))
// Set the header to perform an UPSERT operation in Qdrant
.setHeader(Qdrant.Headers.ACTION, constant(QdrantAction.UPSERT))
// Ingest the data into Qdrant
.to("qdrant:my-collection");Step-by-step explanation:
- Reading data from AWS S3
The pipeline begins by connecting to an AWS S3 bucket my-bucket.
- Data conversion
Each object fetched from S3 is initially in the form of a stream, which is then converted to a String. This transformation is crucial for text-based processing that follows.
- Generating embeddings
The String data is passed to the langchain4j-embeddings:test endpoint, where embeddings are generated using an embedding model managed by the Quarkus Langchain4j extension. This integration simplifies the process by handling model management internally, thus not requiring specific embedding model details in the route.
- Preparing data for Qdrant
The vector data is transformed to meet the data format requirements of Qdrant using the qdrant:embeddings DataType. This DataType is a part of the Qdrant Camel component, designed to seamlessly prepare the Langchain4j embeddings for the Qdrant database.
- Configuring database operations
The header for the Camel route is set to perform an UPSERT operation in Qdrant.
- Ingestion into Qdrant database:
Finally, the processed and formatted data is routed to the Qdrant database using qdrant:my-collection. This completes the cycle from data retrieval to storage, ready for retrieval and analysis in various AI applications.
Note on Document Processing
In this demo, we directly ingest data from S3 and convert it to String values, which are then ready to be transformed into vector representations. For processing larger text files, consider splitting and tokenising the files to manage them more efficiently. One straightforward approach is to integrate the the Langchain4j Document Splitter inside a Camel Processor.
Video demonstration: implementing the data ingestion pipeline
To give you a clearer picture of how all these components work together, I’ve created a video demonstration. This video visually showcases the process of using Apache Camel and Langchain4j to ingest data into vector databases, specifically focusing on the interaction with a Qdrant database using real-world data from an AWS S3 bucket.