Over the last few months, we have explored how to leverage large language models (LLMs) with Llama Stack and Node.js. While TypeScript/JavaScript is often the second language supported by frameworks used to leverage LLMs, Python is generally the first. We thought it would be interesting to go through some of the same exploration by porting over our scripts to Python.
This is the first of a 4-part series in which we'll explore using Llama Stack with the Python API. We will start by looking at how tool calling and agents work when using Python with Llama Stack using the same patterns and approaches that we used to examine other frameworks. In part 2, we'll explore retrieval-augmented generation with Llama Stack and Python.
Setting up Llama Stack
Our first step was to get a running Llama Stack instance that we could experiment with. Llama Stack is a bit different from other frameworks in a few ways.
First, instead of providing a single implementation with a set of defined APIs, it aims to standardize a set of APIs and drive a number of distributions. In other words, the goal is to have many implementations of the same API, with each implementation shipped by a different organization as a distribution. As is common with this approach, a reference distribution is provided, but there are already several alternative distributions available. You can see the available distributions here.
The other difference is a heavy focus on plug-in APIs that allow you to add implementations for specific components behind the API implementation itself. For example, that would let you plug in an implementation (maybe one that is custom tailored for your organization) for a specific feature like Telemetry while using an existing distribution. We won't go into the details of these APIs in this post, but hope to look at them later.
With that in mind, our first question was which distribution to use in order to get started. The Llama Stack quick start that existed when we started showed how to spin up a container running Llama Stack, which uses Ollama to serve the large language model. Because we already had a working Ollama install, we decided that was the path of least resistance.
Getting Llama Stack running
We followed the original Llama Stack quick start, which used a container to run the stack with it pointing to an existing Ollama server. Following the instructions, we put together this short script that allowed us to easily start/stop the Llama Stack instance:
export INFERENCE_MODEL="meta-llama/Llama-3.1-8B-Instruct"
export LLAMA_STACK_PORT=8321
export OLLAMA_HOST=10.1.2.46
podman run -it \
--user 1000 \
-p $LLAMA_STACK_PORT:$LLAMA_STACK_PORT \
-v ~/.llama:/root/.llama \
llamastack/distribution-ollama:0.2.8 \
--port $LLAMA_STACK_PORT \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env OLLAMA_URL=http://$OLLAMA_HOST:11434
Our existing Ollama server was running on a machine with the IP 10.1.2.46, which is what we set OLLAMA_HOST to.
We wanted to use a model that was as close to the models we'd used with other frameworks, which is why we chose meta-llama/Llama-3.1-8B-Instruct, which mapped to llama3.2:8b-instruct-fp16 in Ollama.
Otherwise, we followed the instructions for starting the container from the quick start so Llama Stack was running on the default port. We ran the container on a Fedora virtual machine with IP 10.1.2.128, so you will see us using http://10.1.2.128:8321 as the endpoint for the Llama Stack instance in our code examples.
At this point, we had a running Llama Stack instance that we could start to experiment with.
Read the docs!
While it is always a good idea to read documentation, that is not quite what we mean in this case. At the time of this writing, Llama Stack is moving fast, and we found it was not necessarily easy to find what we needed by searching. Also, the fact that the TypeScript client was auto-generated sometimes made it a bit harder to interpret the Markdown documentation.
The good news, however, is that the stack supports a docs endpoint (in our case, http://10.1.2.128:8321/docs) that you can use to explore the APIs (Figure 1). You can also use that endpoint to invoke and experiment with the APIs, which we found very helpful.

From the initial page, you can drill down to either invoke specific APIs or look at the specific schemas. For example, Figure 2 shows the schema for the agent API after drilling down to look at the tool_choice option.
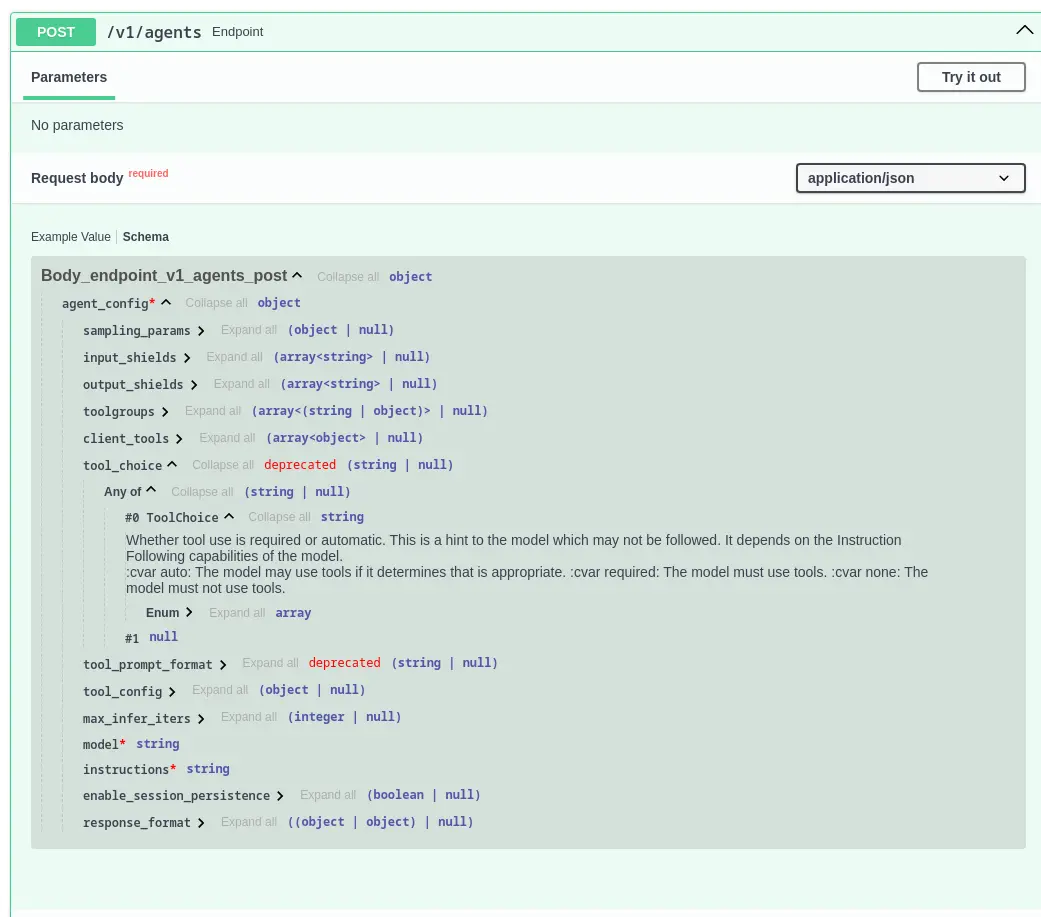
If you have trouble finding an example or documentation that shows what you want to do, using the docs endpoint is a great resource.
Our first Python Llama Stack application
Our next step was to create an example that we could run with Python. A Python client is available, so that is what we used: llama-stack-client-python. As stated in the documentation, it is an automatically generated client based on an OpenAPI definition of the reference API. There is also Markdown documentation for the implementation itself. As mentioned in the previous section, the docs endpoint was also a great resource for understanding the client functionality.
To start, we wanted to implement the same question flow that we used in the past to explore tool calling. This consists of providing the LLM with 2 tools:
favorite_color_tool: Returns the favorite color for a person in the specified city and country.favorite_hockey_tool: Returns the favorite hockey team for a person in the specified city and country.
Then, we ran through this sequence of questions to see how well they were answered:
questions = [
"What is my favorite color?",
"My city is Ottawa",
"My country is Canada",
"I moved to Montreal. What is my favorite color now?",
"My city is Montreal and my country is Canada",
"What is the fastest car in the world?",
"My city is Ottawa and my country is Canada, what is my favorite color?",
"What is my favorite hockey team ?",
"My city is Montreal and my country is Canada",
"Who was the first president of the United States?",
]
The full source code for the first example is available in python-ai-experimentation/llama-stack-local-function-calling/favorite-color.py.
Defining the tools
In our first application, we used local tools defined as part of the application itself. Llama Stack has its own format for defining the tools (every framework seems to have its own, unless you are using MCP).
For Llama Stack, the definitions ended up looking like this:
available_tools = [
{
"tool_name": "favorite_color_tool",
"description": "returns the favorite color for person given their City and Country",
"parameters": {
"city": {
"param_type": "string",
"required": True,
},
"country": {
"param_type": "string",
"required": True,
},
},
},
{
"tool_name": "favorite_hockey_tool",
"description": "returns the favorite hockey team for a person given their City and Country",
"parameters": {
"city": {
"param_type": "string",
"description": "the city for the person",
"required": True,
},
"country": {
"param_type": "string",
"description": "the country for the person",
"required": True,
},
},
},
]
Tool implementations
Our tool implementations were the same as in previous explorations except that we of course have ported them to Python:
def get_favorite_color(args):
city = args.get("city")
country = args.get("country")
if city == "Ottawa" and country == "Canada":
return "the favoriteColorTool returned that the favorite color for Ottawa Canada is black"
if city == "Montreal" and country == "Canada":
return "the favoriteColorTool returned that the favorite color for Montreal Canada is red"
return (
"the favoriteColorTool returned The city or country "
"was not valid, assistant please ask the user for them"
)
def get_favorite_hockey_team(args):
city = args.get("city")
country = args.get("country")
if city == "Ottawa" and country == "Canada":
return "the favoriteHocketTool returned that the favorite hockey team for Ottawa Canada is The Ottawa Senators"
if city == "Montreal" and country == "Canada":
return "the favoriteHockeyTool returned that the favorite hockey team for Montreal Canada is the Montreal Canadians"
return (
"the favoriteHockeyTool returned The city or country "
"was not valid, please ask the user for them"
)
funcs = {
"favorite_color_tool": get_favorite_color,
"favorite_hockey_tool": get_favorite_hockey_team,
}Asking the questions
For the first example, we used the chat completion APIs (as opposed to the agent APIs). The call to the API providing the tools looked like this:
for _i, question in enumerate(questions):
print(f"QUESTION: {question}")
messages.append({"role": "user", "content": question})
response = client.inference.chat_completion(
messages=messages,
model_id=model_id,
tools=available_tools,
)
result = handle_response(messages, response)
print(f" RESPONSE: {result}")Invoking tools
Because we are using the completions API, calling the tools is not handled for us; we just get a request to invoke the tool and return the response as part of the context in a subsequent call to the completions API. For Llama Stack, our handleResponse that does that looks like this:
def handle_response(messages, response):
# push the models response to the chat
messages.append(response.completion_message)
if response.completion_message.tool_calls and len(response.completion_message.tool_calls) != 0:
for tool in response.completion_message.tool_calls:
# log the function calls so that we see when they are called
log(f" FUNCTION CALLED WITH: {tool}")
print(f" CALLED: {tool.tool_name}")
func = funcs.get(tool.tool_name)
if func:
func_response = func(tool.arguments)
messages.append(
{
"role": "tool",
"content": func_response,
"call_id": tool.call_id,
"tool_name": tool.tool_name,
}
)
else:
messages.append(
{
"role": "tool",
"call_id": tool.call_id,
"tool_name": tool.tool_name,
"content": "invalid tool called",
}
)
# call the model again so that it can process the data returned by the
# function calls
return handle_response(
messages,
client.inference.chat_completion(
messages=messages,
model_id=model_id,
tools=available_tools,
),
)
# no function calls just return the response
return response.completion_message.contentSo far, this is all quite similar to the code we used for other frameworks, with tweaks to use the format used to define tools with Llama Stack and tweaks to use the methods provided by the Llama Stack APIs.
An interesting wrinkle
When we first ran the example using the same tool implementations that we had used before, we saw the following output when the LLM did not have the information needed by one of the tools:
python favorite-color.py
Iteration 0 ------------------------------------------------------------
QUESTION: What is my favorite color?
CALLED: favorite_color_tool
RESPONSE: {"type": "error", "message": "The city or country was not valid, please ask the user for them."}
QUESTION: My city is Ottawa
CALLED: favorite_color_tool
RESPONSE: {"type": "error", "message": "The city or country was not valid, please ask the user for them."}
QUESTION: My country is Canada
CALLED: favorite_color_tool
RESPONSE: "black"
This wasn't what we expected. With other frameworks (when we used a similar 8B Llama model) the RESPONSE: was a better-formatted request for the information needed, instead of the direct output from the tool itself. This is likely related to how Llama Stack handles what it sees as errors returned by the tool.
We found that by tweaking the response from the tool to call out the assistant specifically by changing the following:
return (
"the favoriteColorTool returned The city or country "
"was not valid, please ask the user for them"
)to this:
return (
"the favoriteColorTool returned The city or country "
"was not valid, assistant please ask the user for them"
)Adding the single word assistant in front of please ask the user for them helped the model handle the response in a way that the flow was as expected. The RESPONSE became a request for more information when needed. With this change, the flow as as follows:
python favorite-color.py
Iteration 0 ------------------------------------------------------------
QUESTION: What is my favorite color?
CALLED: favorite_color_tool
RESPONSE: I don't have enough information to determine your favorite color. Can you please provide me with your city and country?
QUESTION: My city is Ottawa
CALLED: favorite_color_tool
RESPONSE: I still don't have enough information to determine your favorite color. Can you also please provide me with your country?
QUESTION: My country is Canada
CALLED: favorite_color_tool
RESPONSE: Your favorite color is black.
QUESTION: I moved to Montreal. What is my favorite color now?
CALLED: favorite_color_tool
RESPONSE: Your favorite color is now red.
QUESTION: My city is Montreal and my country is Canada
CALLED: favorite_color_tool
RESPONSE: Your favorite color is still red.
QUESTION: What is the fastest car in the world?
RESPONSE: I don't have any functions available to answer this question.
QUESTION: My city is Ottawa and my country is Canada, what is my favorite color?
CALLED: favorite_color_tool
RESPONSE: Your favorite color is black.
QUESTION: What is my favorite hockey team ?
CALLED: favorite_hockey_tool
RESPONSE: Your favorite hockey team is The Ottawa Senators.
QUESTION: My city is Montreal and my country is Canada
CALLED: favorite_hockey_tool
RESPONSE: Your favorite hockey team is the Montreal Canadiens.
QUESTION: Who was the first president of the United States?
RESPONSE: I don't have any functions available to answer this question.Llama loves its tools
In the output, you might have noticed that when we asked questions that were not related to the tools, the response was that the LLM could not answer the question. This is despite us knowing the answer is in the data the model was trained on:
QUESTION: Who was the first president of the United States?
RESPONSE: I don't have any functions available to answer this question.QUESTION: What is the fastest car in the world?
RESPONSE: I don't have any functions available to answer this question.We have seen this before with Llama 3.1 and other frameworks. In addition, we double-checked that the default with Llama Stack for tool choice was "auto," which means it should decide when or if tools should be used. So at this point, it seems that Llama loves its tools so much that if you provide a tool, it feels it must use one of them.
Using Model Context Protocol (MCP) with Llama Stack
No look at tool calling with a framework would be complete without covering MCP. Model Context Protocol (MCP) is a protocol that allows integration between LLMs and tools, often as part of an agent. One interesting aspect of MCP is that tools hosted in a server can be consumed by different frameworks—even frameworks that use a different language from which the server was written.
To round out this initial exploration of Llama Stack, we will look at using those same tools through the same MCP server with Llama Stack.
Where is my MCP server now?
In our previous explorations, the MCP server was started by our application, ran on the same system as our application, and communication was through Standard IO (stdio for short). This is fine if your application needs to access tools that are local to the machine where the application is running, but not so good otherwise. As an example, it would likely be better to lock down access to a database to a single centralized machine instead of letting all client machines running an application connect to the database directly.
The MCP support built into Llama Stack works a bit differently than what we saw with the other frameworks. MCP servers are registered with the Llama Stack instance, and then the tools provided by the MCP server are accessible to clients that connect to that instance. The MCP support also assumes a Server-Sent Events (SSE) connection instead of stdio, which allows the MCP server to run remotely from where the Llama Stack is running.
Starting the MCP server
Our ported Python version of our CP server python-ai-experimentation/llama-stack-mcp/favorite-server/server.py was based on stdio, just like the original in JavaScript. However, because Llama Stack needs a server that supports SSE, the question was how we could use it with Llama Stack. We'd either need to modify the code or find some kind of bridge.
Luckily for us, Supergateway allows us to start our existing MCP server and have it support SSE. The script we used to do that is in python-ai-experimentation/llama-stack-mcp/start-mcp-server-for-llama-stack.sh and was as follows:
npx -y supergateway --port 8002 --stdio "python favorite-server/server.py"This does mean that we need to install Node.js (which includes the binary for npx) in addition to Python when running the MCP server.
We chose to run it on the same machine on which our Llama Stack container was running, but it could have been run on any machine accessible to the container.
Registering the MCP server
Before an MCP server can be used with Llama Stack, we must tell Llama Stack about it through a registration process. This provides Llama Stack with the information needed to contact the MCP server.
Our Python script to register the server was python-ai-experimentation/llama-stack-mcp/llama-stack-register-mcp.py, as follows:
#!/usr/bin/env python3
import logging
from llama_stack_client import LlamaStackClient
logging.getLogger("httpx").setLevel(logging.WARNING)
def main():
client = LlamaStackClient(
base_url="http://10.1.2.128:8321",
timeout=120.0,
)
try:
# Register the MCP toolgroup
client.toolgroups.register(
toolgroup_id="mcp::mcp_favorites",
provider_id="model-context-protocol",
mcp_endpoint={"uri": "http://10.1.2.128:8002/sse"},
)
print("Successfully registered MCP toolgroup: mcp::mcp_favorites")
except Exception as e:
print(f"Error registering MCP toolgroup: {e}")
return 1
return 0
if __name__ == "__main__":
exit(main())The toolgroup_id is the ID that we will need when we want the LLM to use the tools from the MCP server. You should only have to register the MCP server once after the Llama Stack instance is started. Because we ran the MCP server on the same host as the Llama Stack instance, you can see that the IP addresses are the same.
Using tools from the MCP server
From what we can see so far, you can only use tools from an MCP server through the Llama Stack agents APIs, not the continuation APIs that we used for our first application. Therefore, we switched to the agent API for our second application.
When using the agent API, interaction with tools is handled for you behind the scenes. Instead of getting a request to invoke a tool and having to invoke and return the response, this happens within the framework itself. This simplified the application significantly, as we just had to tell the API which tool group we wanted to use and then ask our standard set of questions. The agent APIs also manage memory so that was another simplification, as we did not need to keep a history of the messages that had already been exchanged.
The code to create the agent and tell it which MCP server we wanted to use was as follows:
# Create the agent
agentic_system_create_response = client.agents.create(
agent_config={
"model": model_id,
"instructions": "You are a helpful assistant",
"toolgroups": ["mcp::mcp_favorites"],
"tool_choice": "auto",
"input_shields": [],
"output_shields": [],
"max_infer_iters": 10,
}
)
agent_id = agentic_system_create_response.agent_id
# Create a session that will be used to ask the agent a sequence of questions
session_create_response = client.agents.session.create(
agent_id, session_name="agent1"
)
session_id = session_create_response.session_idYou can see that we used mcp::mcp_favorites to match the toolgroup_id we used when we registered the server. Having done that it was a simple matter of asking each question using the agent API.
The code is a bit longer that it might have been otherwise because, as of the time of writing, the agent API only supports a streaming API, which takes a few more lines in order to collect the response:
for i, question in enumerate(questions):
print("QUESTION: " + question)
response_stream = client.agents.turn.create(
session_id,
agent_id=agent_id,
stream=True,
messages=[{"role": "user", "content": question}],
)
# as of March 2025 only streaming was supported
response = ""
for chunk in response_stream:
# Check for errors in the response
if hasattr(chunk, "error") and getattr(chunk, "error", None):
error_msg = getattr(chunk, "error", {}).get(
"message", "Unknown error"
)
print(f" ERROR: {error_msg}")
break
# Check for successful turn completion
elif (
hasattr(chunk, "event")
and getattr(chunk, "event", None)
and hasattr(chunk.event, "payload")
and chunk.event.payload.event_type == "turn_complete"
):
response = response + str(
chunk.event.payload.turn.output_message.content
)
print(" RESPONSE:" + response)The full source code for this application is in python-ai-experimentation/llama-stack-mcp/llama-stack-agent-mcp.py. The flow ran and used the same tools; we just don't get the information about tools when they are called, as the application does not see the tool calls, only the final response:
(llama-stack-mcp) user1@fedora:~/newpull/python-ai-experimentation/llama-stack-mcp$ python llama-stack-agent-mcp.py
Iteration 0 ------------------------------------------------------------
QUESTION: What is my favorite color?
RESPONSE:To determine your favorite color, I'll need to know your city and country. Can you please tell me where you're from?
QUESTION: My city is Ottawa
RESPONSE:To determine your favorite color, I'll need to know your country as well. Can you please tell me what country you're from?
QUESTION: My country is Canada
RESPONSE:Your favorite color is black.
QUESTION: I moved to Montreal. What is my favorite color now?
RESPONSE:Since you've moved to a new city, your favorite color might change. However, I don't have any information about the relationship between cities and favorite colors. The function `favorite_color_tool` only takes into account the city and country, but it's not clear if moving to a new city changes your favorite color.
If you'd like to know your new favorite color, I can try calling the `favorite_color_tool` function again with your new city and country.
QUESTION: My city is Montreal and my country is Canada
RESPONSE:Your favorite color has changed to red since you moved to Montreal.
QUESTION: What is the fastest car in the world?
RESPONSE:Unfortunately, I don't have any information about cars or their speeds. The functions provided earlier were related to determining favorite colors based on city and country, but they don't include any information about cars. If you'd like to know more about cars or their speeds, I can try to help with that, but it would require a different set of functions or data.
QUESTION: My city is Ottawa and my country is Canada, what is my favorite color?
RESPONSE:Since we previously determined that your favorite color was black when you lived in Ottawa, Canada, the answer remains the same.
Your favorite color is still black.
QUESTION: What is my favorite hockey team ?
RESPONSE:Unfortunately, I don't have any information about your favorite hockey team. The functions provided earlier were related to determining favorite colors based on city and country, but they don't include any information about sports teams.
However, if you'd like to know the favorite hockey team for a person given their City and Country, we can use the `favorite_hockey_tool` function. Can you please tell me your city and country?
QUESTION: My city is Montreal and my country is Canada
RESPONSE:Your favorite hockey team is the Montreal Canadiens.
QUESTION: Who was the first president of the United States?
RESPONSE:Unfortunately, I don't have any information about the presidents of the United States. The functions provided earlier were related to determining favorite colors and hockey teams based on city and country, but they don't include any information about historical figures or events.
If you'd like to know more about the presidents of the United States, I can try to help with that, but it would require a different set of functions or data.It is interesting that the flow was a bit different because the agent uses a more sophisticated way of "thinking," but in our case, it seems to have "overthought" instead of just calling the tool to get the answer:
QUESTION: I moved to Montreal. What is my favorite color now?
RESPONSE:Since you've moved to a new city, your favorite color might change. However, I don't have any information about the relationship between cities and favorite colors. The function `favorite_color_tool` only takes into account the city and country, but it's not clear if moving to a new city changes your favorite color.
If you'd like to know your new favorite color, I can try calling the `favorite_color_tool` function again with your new city and country.Compared to what we saw when using the completions API:
QUESTION: I moved to Montreal. What is my favorite color now?
CALLED: favorite_color_tool
RESPONSE: Your favorite color is now red.What about access to the local application environment?
The Llama Stack approach to MCP support is good for most cases, except when you want to access the local environment where the application is running, instead of where the Llama Stack is running or some other machine completely. If you want to access the environment where the application is running instead, what do you do?
While Llama Stack does not have built-in MCP support for this, it is quite easy to add it in a similar manner to what we did in for Ollama in A quick look at MCP with large language models and Node.js. We start an MCP server locally, communicate with it over stdio, and convert the tools it provides into the format needed for the use of local tools.
The code to start the local MCP server and connect to it was:
# Server parameters for the Python favorite server
server_params = StdioServerParameters(
command="python",
args=[os.path.abspath("favorite-server/server.py")],
env=None,
)
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as mcp_session:
# Initialize the connection
await mcp_session.initialize()
In the case of Llama Stack, the code needed to convert the tool descriptions provided by the MCP server into the format needed by Llama Stack was as follows:
tools_response = await mcp_session.list_tools()
tools_list = tools_response.tools
available_tools = []
for tool in tools_list:
tool_dict = {
"tool_name": tool.name,
"description": tool.description,
"parameters": (
tool.inputSchema.get("properties", {})
),
}
for param_name, parameter in tool_dict["parameters"].items():
if "type" in parameter:
parameter["param_type"] = parameter["type"]
del parameter["type"]
if (
"required" in tool.inputSchema
and param_name in tool.inputSchema["required"]
):
parameter["required"] = True
available_tools.append(tool_dict)
With that, we could provide those tool descriptions in the completion API. When tools calls were requested by the LLM, we could convert those requests into invocations of the tools through the MCP server as follows:
for tool_call in response.completion_message.tool_calls:
# Log the function calls so that we see when they are called
log(f" FUNCTION CALLED WITH: {tool_call}")
print(f" CALLED: {tool_call.tool_name}")
try:
# Call the MCP server tool
func_response = await mcp_session.call_tool(
tool_call.tool_name, arguments=tool_call.arguments or {}
)
# Add tool responses to messages (in API-compatible format)
if func_response.content:
for content_item in func_response.content:
messages.append(
{
"role": "tool",
"content": content_item.text,
"call_id": tool_call.call_id,
"tool_name": tool_call.tool_name,
}
)
except Exception as e:
messages.append(
{
"role": "tool",
"content": f"tool call failed: {e}",
"call_id": getattr(tool_call, "call_id", "unknown"),
"tool_name": tool_call.tool_name,
}
)The full code for the example using tools from a local MCP server with Llama Stack is in python-ai-experimentation/llama-stack-mcp/llama-stack-local-mcp.py. It's nice that you can easily use both a local MCP server or one registered with the Llama Stack, depending on what makes the most sense for your application.
Wrapping up
This post looked at using Python with large language models and Llama Stack. We explored how to run tools with the completions API, the agent API, and how to do so with inline tools, local MCP tools, and remote MCP tools. We hope it has given you, as a Python developer, a good start on using large language models with Llama Stack.
Read the next part in this series: Retrieval-augmented generation with Llama Stack and Python.
Explore more AI tutorials on our AI/ML topic page.
Last updated: August 5, 2025