I am a GCC compiler engineer, and for the past 15 years, I have primarily focused on the GCC register allocator and instruction scheduler. The major development of the GCC register allocator and instruction scheduler was completed quite some time ago, and these days, my main responsibility is maintaining these essential GCC components. About six years ago, I began dedicating half of my work time to improving performance of CRuby, the de facto standard Ruby implementation. A significant portion of this effort involved implementing the CRuby just-in-time (JIT) compiler.
My initial attempt to implement a CRuby JIT was MJIT (method based just-in-time compiler). MJIT provided a rapid way to implement JIT for CRuby. It was based on utilizing the GCC compiler, which generated machine code as .so files in the memory file system, subsequently loaded by a dynamic loader for execution. However, GCC proved to be slow as a JIT compiler. To improve MJIT compilation speed, I employed precompiled headers and generated machine code in parallel with Ruby program execution. Takashi Kokubun adopted MJIT, improving it and integrating it into the CRuby release, where he continued to maintain it thereafter.
MJIT notably improved the performance of Optcarrot, a classic Ruby benchmark, by threefold. However, it struggled to enhance performance for many widely-used applications, such as Ruby on Rails.
I dedicated a year of work to MJIT, gaining valuable experience and insights into the JIT requirements for CRuby. It became clear that developing an effective JIT for CRuby was a multi-year endeavor requiring dedicated efforts from a select few. Undaunted, I embarked on this ambitious multi-year project.
Initially, I decided to create a universal lightweight JIT compiler based on a machine-independent medium internal representation (MIR). This compiler aimed to achieve speeds 100 times faster than GCC and generate code with performance comparable to that produced by GCC with -O2 optimizations. These goals were successfully achieved. While the MIR project has made significant strides and is already employed for JIT implementations in various programming languages, it has yet to reach its culmination. The ultimate objective of the MIR project is to simplify JIT implementation for dynamic programming languages. MIR should facilitate code specialization and execution trace optimizations. The long-term aspiration is to develop a meta-tracing JIT compiler for automatically generating JITs from a C-written interpreter. More detailed information on these objectives can be found in one of my previous blog posts.
My intention was to leverage the power of MIR for a new CRuby JIT, forming a part of my long-term strategy.
The introduction of Shopify YJIT for CRuby a couple of years ago disrupted my long-standing strategy. In response, I accelerated the process by implementing different specializations at the instruction level of CRuby virtual machine (VM), departing from the singular approach of MIR and incorporating the current state of the MIR JIT compiler. Last year, I introduced specialization at the VM instruction level, introducing a new collection of specialized VM instructions known as SIR (specialized internal representation). Specialization is achieved through basic block versioning invented by Maxime Chevalier-Boisvert and speculative techniques.
SIR, in addition to specialization, functions as a register transfer language (RTL), whereas the original VM instructions are stack-based. Employing RTL enhances the interpreter's performance, but it's not actually necessary for improving the performance of the MIR-based JIT.
Over the past six months, I have focused on an MIR-based JIT that compiles SIR, already specialized at the interpreter level.
The success of YJIT led to a pivotal decision by my management team and me: to discontinue work on the MIR-based JIT for CRuby. The YJIT team has done an exemplary job, and their approach aligns well with the goal of further enhancing JIT performance. They are transitioning from direct machine code generation to generating internal representation (IR) and optimizing it as an intermediate step. Given Shopify's strategic interest in CRuby JIT and the ample resources dedicated to this pursuit, the future of CRuby JIT is in capable hands.
This article provides an overview of the MIR-based JIT for CRuby and summarizes the results of the unfinished project, along with my ideas for further improving MIR-based JIT and YJIT performance. I hope this post proves valuable not only to JIT developers at large but also to those specifically involved in Ruby JIT development.
MIR-based JIT design
Here, I will describe the major features of the MIR-based JIT design and highlighting its differences from YJIT.
As I mentioned earlier, the majority of code specialization for the MIR-based JIT occurs at the interpreter level. This specialization encompasses type specialization, method call specialization, array element, and instance variable access specialization. Specialization is achieved through a combination of lazy basic block versioning and speculative techniques. Basic block versioning specialization incurs no additional cost, while speculative specialization requires certain guards to verify assumed specialization conditions. More comprehensive details about the specialized internal representation and this process can be found in my previous blog post.
Figure 1 shows a data flow diagram for the MIR-based JIT (all images can be clicked to increase their size):
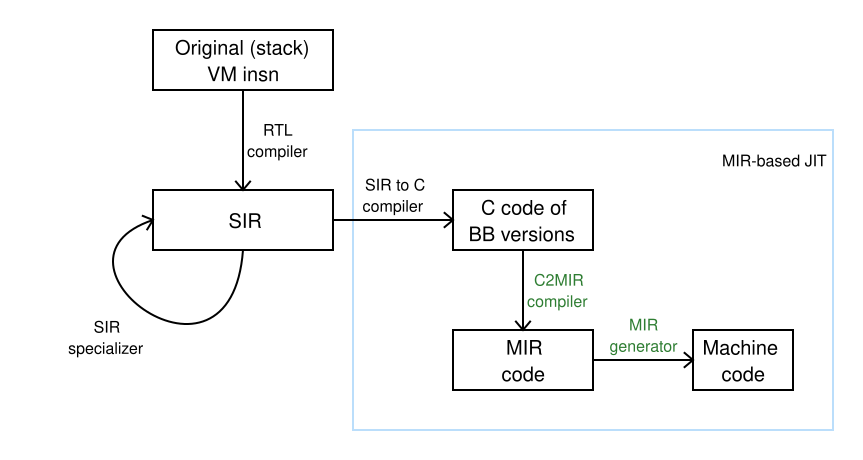
Components of the universal MIR JIT compiler are highlighted in green.
Once the execution count of a basic block version reaches a specific threshold, it is sent to the MIR-based JIT. The behavior of YJIT differs in this aspect. When the call count for a particular method surpasses a threshold, YJIT starts JITting basic block versions of the method in a lazy manner. Essentially, YJIT will not generate machine code for a Ruby code fragment like while i < 1_000_000 do i += 1; end unless it is within a frequently executed method. In contrast, the MIR-based JIT will certainly generate machine code for such a fragment.
To provide a more accurate description of basic block generation by the MIR-based JIT, when a loop comprises a single basic block, the generated code incorporates the complete loop rather than solely the basic block of the loop. Similarly, if a basic block contains a method call consisting of only one block, the generated code can inline the entire method.
The transition between the interpreter and machine code generated by YJIT comes with a significant cost. Hence, the YJIT team has concentrated on minimizing the frequency of such transitions.
Conversely, for the MIR-based JIT, the same transition is virtually cost-free. The CRuby interpreter employs a direct dispatch technique using the GCC extension labels as values. Each CRuby VM instruction carries the address of the label associated with the code responsible for implementing the instruction. Figure 2 illustrates this approach.
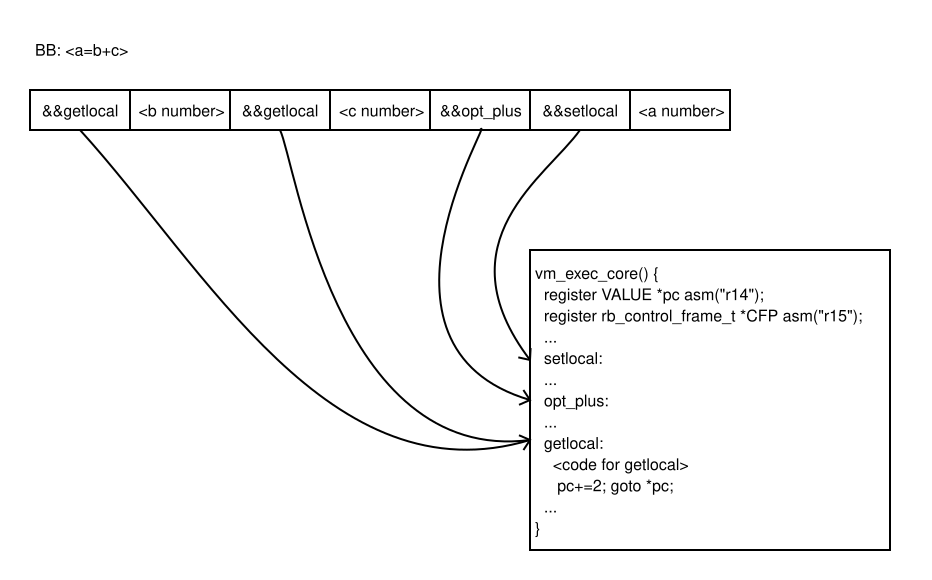
When the MIR-based JIT generates machine code for a basic block, it reroutes the first instruction of the basic block to the machine code (see Figure 3).
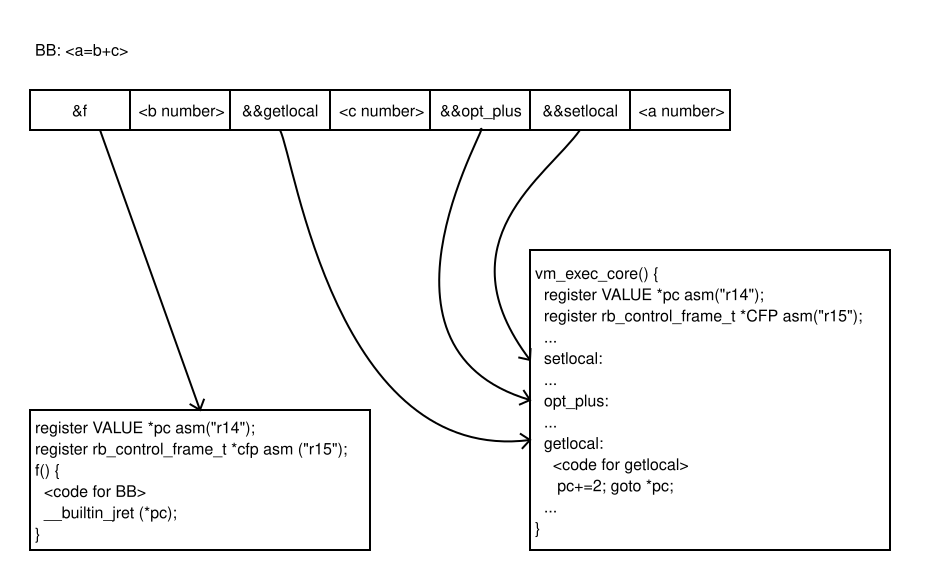
To improve the interpretation speed, variables that describe the execution context, such as cfp (CRuby VM control frame pointer) or pc (CRuby VM program counter), are allocated to specific machine registers through the use of the GCC extension explicit local register variables.
The machine code generated by the MIR-based JIT employs the same registers for the same variables using the GCC extension explicit global register variables, also implemented in MIR. This obviates the need to transfer the execution context state between the interpreter and JITted code and back. The MIR project supports a distinct call ABI, in which the MIR function can be invoked and returned through direct and indirect jumps.
YJIT directly generates machine code from VM instructions. Only recently, YJIT's development has shifted towards optimizing an internal representation first, including at least doing register allocation, before generating machine code from that internal representation.
The MIR-based JIT generates machine code through a series of steps. First, it generates C code in memory for a basic block version. Next, the C-to-MIR compiler from the MIR project generates MIR code, also in memory. Finally, the MIR code is optimized and compiled into machine code using the MIR-generator from the MIR project. While it is possible to generate MIR code directly, for the prototype, I found it more manageable to generate C code first, as it is more readable.
MIR-based JIT performance
To assess the performance of the MIR-based JIT, I conducted benchmarks on the following:
- base: the base interpreter (
miniruby) - sir: the interpreter with specialized internal representation (
miniruby --sir) - yjit: YJIT (
miniruby --yjit) - mir: MIR-based JIT (
miniruby --mirjit)
All measurements were conducted on an Intel i5-13600K with 64 GB of memory under x86-64 Fedora Core 36.
I employed the following micro-benchmarks (located in the sir-bench directory):
- aread: reading an instance variable through
attr_reader - aref: reading an array element
- aset: assignment to an array element
- awrite: assignment to an instance variable through
attr_writer - bench: a rendering benchmark
- call: empty method calls
- complex-mandelbrot: complex number version of mandelbrot
- const2: reading
Class::Const - const: reading Const
- fannk: fannkuch
- fib: fibonacci
- ivread: reading an instance variable (
@var) - ivwrite: assignment to an instance variable
- mandelbrot: non-complex version of mandelbrot
- meteor: meteor puzzle
- nbody: modeling planet orbits
- nest-ntimes: nested
ntimesloops (6 levels) - nest-while: nested while loops (6 levels)
- norm: spectral norm
- pent: pentamino puzzle
- red-black: red-black trees
- sieve: Eratosthenes sieve
- trees: binary trees
- while: while loop
The hot code for each micro-benchmark was encapsulated within a Ruby method, which was invoked sufficiently to trigger machine code generation by YJIT (as previously mentioned, YJIT initiates code generation only from calls to frequently executed methods). Each benchmark was executed three times, and the minimum time (or smallest maximum resident memory) was selected. Figure 4 presents the wall execution time for the micro-benchmarks:
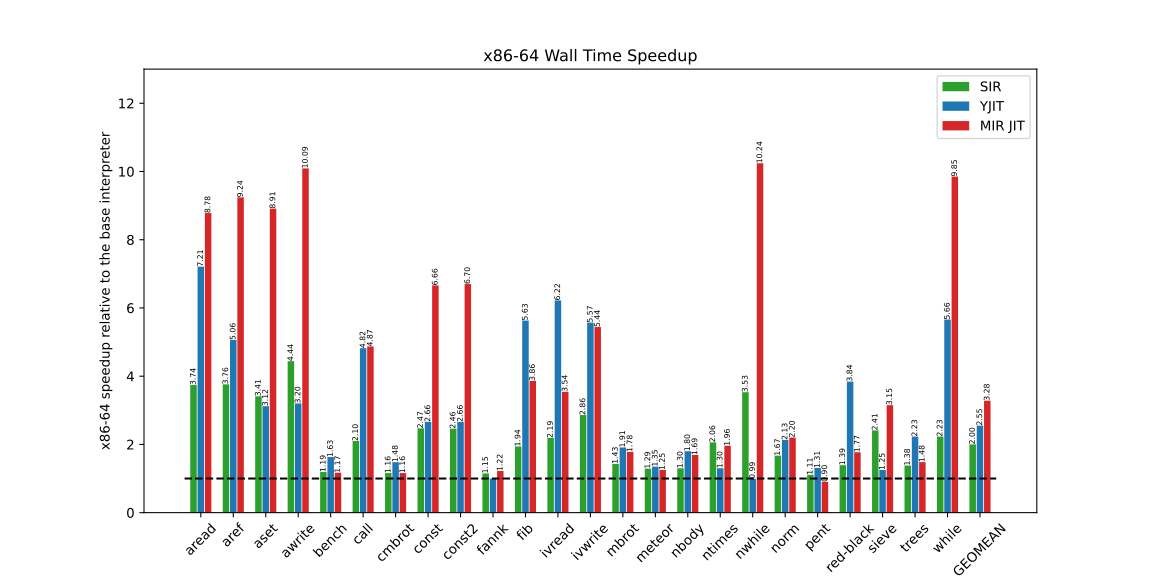
The CPU time remains consistent, as YJIT and the MIR-based JIT do not operate concurrently with Ruby program execution.
Furthermore, Figure 5 illustrates the maximum resident memory increase relative to the base interpreter on the Intel CPU machine.
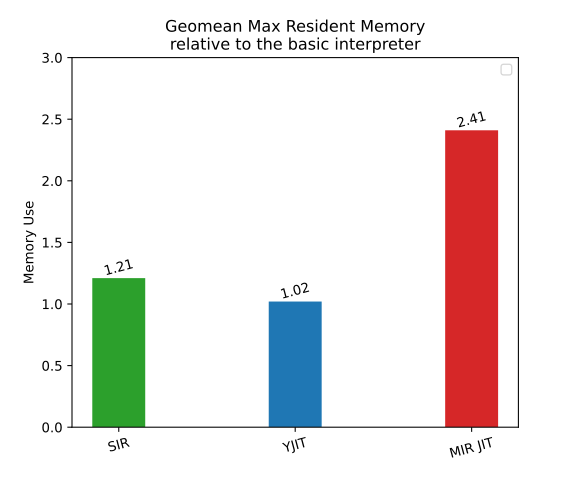
It is apparent that MIR-based JIT consumes more memory than YJIT. MIR-based JIT allocates a substantial amount of memory in advance for basic block versions (BBVs). This primarily contributes to the observed results. While YJIT previously encountered a similar issue, it was recently resolved. This is an aspect where further improvement can be made in the MIR-based JIT.
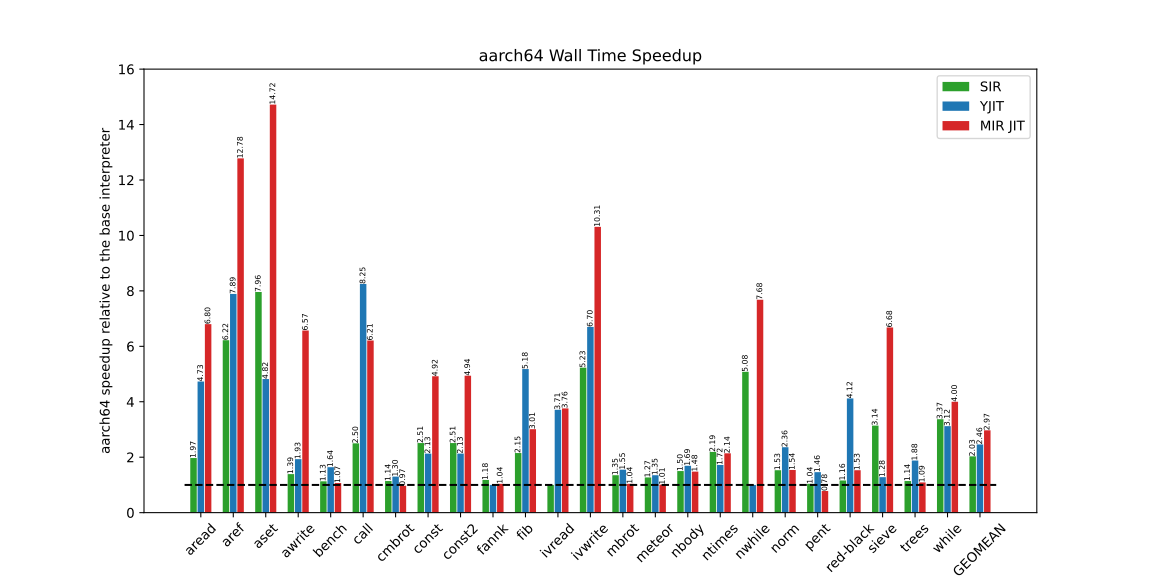
The MIR JIT compiler generates code for x86-64, aarch64, ppc64, riscv64, and s390x architectures. Thus, I also evaluated MIR-based JIT on another architecture. I conducted the benchmarks on aarch64 Fedora Core 34 within a virtual machine (UTM) on an M1 Apple Mac mini with 16 GB memory, operating under macOS. Due to the virtual machine environment, the accuracy of these results might be somewhat diminished. The outcomes are presented in Figure 6.
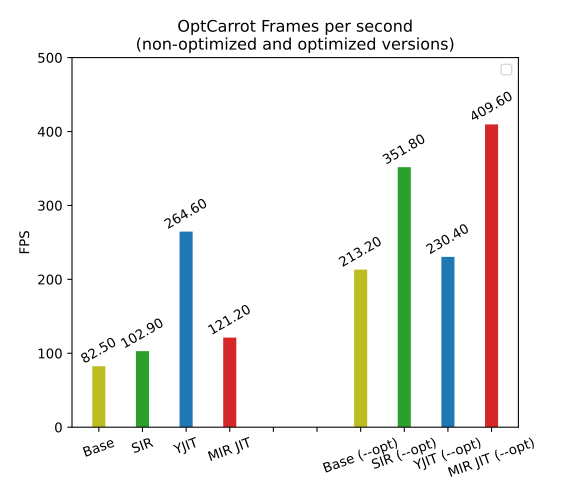
Additionally, I tested the classical Ruby mid-sized benchmark, Optcarrot, using 3,000 frames. Figure 7 shows the x86-64 results.
It would be ideal to present performance enhancements for widely used real-world applications here. However, SIR, the foundation on which MIR-based JIT operates, is not yet prepared for such reporting. While the SIR interpreter successfully passes all basic CRuby tests (approximately 2,000 tests), it struggles with a significant number of tests from the extended CRuby test suite (roughly 25,000 tests).
9 ideas to improve MIR-based CRuby JIT performance
Here are my suggestions for improving the MIR-based JIT, ordered by importance.
1. Trace JIT and inlining
The MIR-based JIT currently generates code for individual basic blocks (BBs). To enhance performance, we could identify traces of frequently executed BBs and re-jit these traces as a whole. This could substantially enhance code performance by improving code locality and enabling comprehensive optimization by the MIR-generator for the entire trace.
Typical Ruby code consists of numerous method calls. To generate longer traces and traces containing loops, call inlining needs to be performed.
Many of Ruby's standard methods are implemented in C. To inline them, we must translate this C code into an internal representation, from which the JIT forms traces for optimization. This translation can be achieved by manually converting the C code into the internal representation or employing a C-to-IR translator. For MIR, the existing C-to-MIR translator could be used. For YJIT's internal representation, a new LLVM IR to YJIT IR translator might be necessary. However, this approach would likely require significant restructuring of the existing CRuby code.
Another approach to inline standard methods could involve translating the methods implemented in C code into Ruby code. To achieve better performance with the generated code, these methods need to be treated in a way that avoids the creation of CRuby control frames, as this process consumes considerable time. In any case, the second approach to inlining will likely yield worse generated code than the first one.
I believe it's worth considering a hybrid approach, wherein widely-used iterator methods are translated into the IR, while less frequently used methods are rewritten in Ruby.
2. Polymorhic caches
In the current MIR-based JIT, call (or instance variable access) instructions cache only one method (or instance variable). The generated code reverts to the interpreter if the method is not present in the cache. Implementing caching for multiple methods could enhance the performance of machine code produced by the MIR-based JIT. YJIT has already employed this technique, and this is the major reason why YJIT outperforms the MIR-based JIT in benchmarks such as tree, red-black, and optcarrot.
3. Optimized local variable handling
The current MIR-based JIT always reads and writes CRuby local variable values from the CRuby VM stack. A more efficient approach would be to maintain CRuby local variables in MIR registers, which would likely be assigned to CPU registers. This synchronization between registers and the CRuby VM stack should occur only when there is a genuine transition from generated code to interpretation. This would speed up the generated code by reducing memory access and the notifications sent to CRuby's generational GC about new heap objects.
4. Dynamic memory allocation for BBVs
Currently, significant memory is allocated ahead for Basic Block Versions (BBVs) of each Ruby method, even when it might not be necessary. While this simplifies MIR-based JIT and SIR interpreter development, a more optimal approach would be to allocate memory for each BBV on a demand basis, akin to YJIT's recently implemented optimization, which notably improved its performance.
5. Delayed BBV generation
BBVs are re-jitted when changed, which can happen when the destination BBV is generated, and the branch destination in a given BBV is modified. Since BBVs are generated lazily, this process can generate redundant code. Delaying BBV generation until all or most destination BBVs are created could mitigate the need for re-jitting.
6. Generated code memory management
Presently, there are no constraints on the size of generated BBV code. For large Ruby programs, this could lead to excessive memory consumption for generated code. Implementing a memory limit for generated code size and removing less frequently used generated code when the limit is reached would optimize memory utilization.
7. Direct MIR code generation
Instead of generating C code for BBVs, the MIR-based JIT could generate MIR code directly. This would enhance compilation speed, reduce memory usage during JIT operation, and decrease the code size of CRuby with MIR-based JIT, albeit only slightly (by around 5%, based on my estimation).
8. Floating point calculation optimization
While not the typical domain for Ruby applications, performance in floating-point calculations could be improved by eliminating unnecessary transformations of IEEE-doubles to/from CRuby values.
CRuby employs tagged values where floating-point values on 64-bit machines have the two least significant bits (a tag) set to '10'. To put IEEE-double into CRuby value, two mantissa bits, used for the tag, are stored in the exponent, thus reducing the exponent range. IEEE-double values that cannot be put into the CRuby value are stored in the heap.
Currently, CRuby VM arithmetic instructions unpack IEEE-double operands from CRuby values and pack the result back. Avoiding this packing/unpacking (referred to as boxing/unboxing) for subsequent arithmetic instructions within a basic block could improve the performance of floating point calculations.
9. Parallel code generation
Presently, Ruby program execution halts when the MIR-based JIT or YJIT commences generating machine code. Enhancing performance could involve generating code in parallel with Ruby program interpretation. While this could improve the wall time of execution for Ruby programs, it could also introduce complexities and might not be beneficial for server-based applications with numerous long-running Ruby instances that fully utilize all available CPUs.
Conclusion
The MIR-based CRuby JIT can be found in this repository. You are welcome to use the JIT sources for any purpose you desire.
Implementing a high-performance CRuby JIT is an exceptionally challenging endeavor. Furthermore, it's a task too immense for a single individual to tackle. Fortunately, Shopify possesses an ample pool of human resources for such an undertaking. The success achieved by the Shopify YJIT team has led to a decision to halt my efforts on the MIR-based JIT for CRuby. However, I have no regrets regarding my work on the MIR-based JIT. The experience gained through this endeavor has enriched my understanding of JITs.
My engagement with CRuby JIT has provided valuable insights into ways further to enhance the performance of both YJIT and MIR-based JIT. Foremost among these insights is the optimization of frequently executed traces and the inlining of method calls, including standard Ruby methods written in C.
I hope the Shopify YJIT team will implement the tracing JIT or someone within the Ruby community will take on this task someday. The Ruby community is a formidable driving force that contributes to the resilience of the Ruby project!