For the past two years I've worked on a project implementing a universal lightweight Just-in-Time (JIT) compiler known as MIR. The cornerstone of the project is a machine-independent medium-level intermediate representation (MIR).
A big part of the project consists of code that compiles C source code into MIR. Because MIR can be interpreted and just-in-timed, I easily extended this C-to-MIR compiler into a C interpreter and JIT compiler.
I have previously written about other parts of the MIR project (see MIR: A lightweight JIT compiler project, but I never wrote in detail about the C-to-MIR compiler, C interpreter, or JIT. In this article, I would like to correct these omissions.
Motivation for a C-to-MIR compiler
Originally, I started the MIR project to address drawbacks of the current CRuby JIT by adding tiered JIT compilation.
To start using the MIR project to implement a Ruby JIT compiler, I needed a C-to-MIR compiler. Standard Ruby methods implemented in C can be translated into MIR and can be inlined with MIR code generated from Ruby bytecode. The combined code can be optimized and just-in-timed into high-performance machine code.
There are several ways to implement a C-to-MIR compiler. I could implement an LLVM IR-to-MIR compiler or write a GCC port targeting MIR. But this would create a dependency on an external project. It is not an easy task, either, and could create a maintenance burden in the future.
On the other hand, some people have written small C compilers pretty quickly. Here I can mention the lacc, 8cc, and 9cc compiler projects.
Also, I want to extend the C language in the future to mark program points where the C-to-MIR compiler should profile the code and generate speculative and de-optimized code depending on the execution profile. For example, the C code implementing the CRuby virtual machine's plus bytecode for integers checks the operand types. It also checks that the plus method for integers was not redefined, that there is no overflow, that it doesn't need to use multi-precision numbers, and so on. All these checks would be the marked program points I am talking about.
It is hard to implement such extensions for GCC or Clang, get approval to include them into GCC or Clang repositories, or support them on the side.
So I decided to write my own C-to-MIR compiler first. It should implement standard C11 without rarely used optional standard features such as variable arrays, complex numbers, and atomic data.
The major implementation goal was simplicity, not compilation speed. This makes studying the code easier for other people and reduces the effort required to maintain it.
The C interpreter and JIT
The C-to-MIR compiler has an API interface and I can use the compiler as a library. MIR, on the other hand, includes an interpreter and a JIT. By gluing together all this code, I found it easy to create a C interpreter and JIT. I only needed to write a small driver program.
Combining the C-to-MIR compiler, MIR interpreter, and JIT with the driver produced an executable c2m that works as a C interpreter and JIT.
As MIR, the JIT generates code for the x86-64, aarch64, ppc64 (big and little endian), and s390x architectures. c2m works on these architectures, too.
c2m options are analogous to widely used cc options: -E, -c, -S, -o <file>, -Iinclude_dir, -Dmacro[=value], -Umacro, -Llibrary_dir, and -ldynamic_library.
Instead of assembler code, c2m generates textual MIR representation. For example, the command
c2m -S file1.c file2.c
creates the text MIR files file1.mir and file2.mir.
Instead of object files, c2m generates a binary MIR representation. For instance, the command
c2m -c file1.c file2.c
creates the binary MIR files file1.bmir and file2.bmir.
Instead of an executable, c2m generates a linked binary MIR file. For instance, the command
c2m file1.c file2.c
creates one linked binary MIR file, a.bmir (the name can be changed with the -o option).
Analogous to using cc on assembler and object files, you can use textual and binary MIR files on the c2m command line, for instance:
c2m file1.mir file2.bmir
This command creates a linked binary MIR file, a.bmir.
There are a few options specific to c2m. To interpret C code, use the -ei option. For example, the command
c2m echo.c -ei 1 2 Hello
compiles the program echo.c (which should contain a main function) into MIR, and the MIR will be executed in the interpreter. Options on the command-line after -ei will be passed to the main function as arguments (argc and argv).
To execute the same program in the MIR JIT, use the -eg option:
c2m echo.c -eg 1 2 Hello
The -el option requests lazy JIT generation. c2mwill not generate machine code for a function until the function is called for the first time:
c2m echo.c -el 1 2 Hello
To see how the MIR JIT compiler optimizes MIR code and generates machine code, use the -dg option. Be cautious, however, because it outputs a lot of information.
C-to-MIR compiler internal details
As I wrote earlier, the major implementation goal for the C-to-MIR compiler was simplicity. Usually, we can achieve simplicity by dividing tasks into small, manageable subtasks. There is even an extreme nano-pass compiler design used for studying compiler topics in education.
My approach to the C compiler implementation is a classic division into four passes of approximately the same size: preprocessor, parser, context checker, and MIR generator, as shown in Figure 1.

I don't use any tools like YACC for the compiler. Although the ANSI C standard grammar is ambiguous, I don't modify it. I use a parsing expression grammar (PEG), a manual parser with rare backtracking. It is simple and small but a bit slower than deterministic parsers.
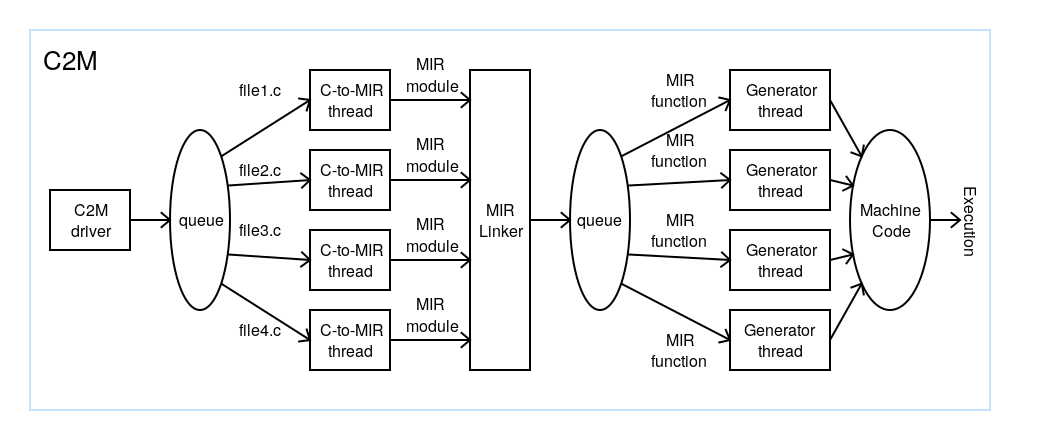
A typical JIT, such as in the Java Virtual Machine, runs in threads in parallel with code execution. I also designed the MIR JIT and C-to-MIR compilers to be used in a multithreaded environment. Therefore, it was easy to make c2m compile different source files in parallel and generate machine code in parallel for different C functions.
You can define the number of parallel tasks for c2m to run simultaneously by using the -poption. For example, in this invocation
c2m -p4 file1.c file2.c file3.c file4.c -eg program arguments
c2m will create four threads first. These threads can compile the four source files in parallel. The threads will take source files from a queue of source files to produce MIR code.
After compiling and linking the generated MIR code, four new threads will do optimizations and machine-code generation for each MIR function. Analogously, these new threads take MIR functions from a queue of MIR functions. So, you can generate machine code for four functions simultaneously. Figure 2 illustrates the parallel operation of c2m.
The current state of the C interpreter and JIT
The C-to-MIR compiler is mostly implemented. It passes about 1,000 tests from different C test suites.
About a year ago I achieved an important milestone: A successful bootstrap. c2m compiles its own sources and generates an MIR binary. Then, an execution of this MIR binary processes the c2m sources again and generates another MIR binary. The two MIR binary files are identical:
cc -O3 -fno-tree-sra -std=gnu11 -Dx86_64 -I. mir-gen.c c2mir.c c2mir-driver.c mir.c -ldl -o c2m ./c2m -Dx86_64 -I. mir-gen.c c2mir.c c2mir-driver.c mir.c -o 1.bmir ./c2m 1.bmir -el -Dx86_64 -I. mir-gen.c c2mir.c c2mir-driver.c mir.c -o 2.bmir
To get a better understanding of the MIR project's size, the pie chart in Figure 3 shows the lines of code in all of the c2m sources, as reported by sloccount.

ABI compatibility
The C ABI (application binary interface) can be quite complicated. For example, on some architectures, the C ABI requires code to pass small structures fully in registers (see for example the aarch64 ABI or s390x ABI) or partially in registers (see for example the ppc64 BE ABI and ppc64 LE ABI), or to pass different parts of the structures in different classes of registers, whether integer or floating point (for instance, in the x86-64 ABI).
Fully implementing the C ABI is not a simple task. Some C implementations ignore full-call ABI compatibility or omit long double implementation for the target ABI. Because the C-to-MIR compiler will communicate with code generated by GCC/Clang to implement JIT in Ruby, full-call ABI compatibility is a must. For instance, an interpreter value in MRuby is represented by a small C structure.
I spent considerable effort implementing the C ABI for its four targets. Besides changes to C-to-MIR code, the implementation required changes in the MIR design. I believe the current design will make it easy to add a new target with a different ABI in the future.
How the MIR C compiler compares with other C compilers
There are a lot of implementations of C. For comparison with my C implementation I've chosen the following C compilers:
- GCC version 10.2.1. This compiler is widely used, and the most portable industrial C compiler.
- Clang version 10.0.1. This is a popular industrial C compiler with a modern design supporting many targets.
- PCC version 1.2.0.DEVEL. This is a modern version of the Portable C compiler, originally released a very long time ago (1979). It supports C11 on a lot of targets, including x86_64, but most of the supported targets are outdated.
- TCC version 0.9.27. The tiny C11 compiler is a two-pass compiler with its own assembler and linker. It supports i386/x86-64, arm, arm64, and riscv64.
- Cproc. Michael Forney's C11 implementation is based on the QBE compiler backend. QBE can be considered a mini LLVM with an analogous IR and a small SSA optimization pipeline. QBE supports x86-64 and is moving toward arm64 support. Comparing Cproc is useful to compare the performance of the MIR-generator and the QBE, as both can be used for lightweight JIT compilers.
- cparser. This is a C99 implementation based on a pretty sophisticated backend, libFirm version 1.22. The compiler targets i386/x86-64 and 32-bit arm, mips, riscv, and sparc.
- lacc. This is a C89 implementation supporting only x86_64.
- Chibicc. Rui Ueyama's latest C11 implementation, for educational goals; targets only x86_64.
I also tried to benchmark the following C compilers:
- SCC. Unfortunately, it crashes with an internal compiler error on my benchmarks.
- LCC. This old C compiler is described in the book A Retargetable C Compiler: Design and Implementation (Addison-Wesley, 1995). I rejected it because it does not support x86-64.
- 8cc and 9cc. It is hard to use these compilers, and probably makes little sense to check them because Chibicc is the continuation of their development.
Generated code performance
To compare the performance of code generated by the compilers, I use a set of 14 benchmarks, most of which are from the old computer languages shootout. I've chosen these micro-benchmarks because it is problematic to compile more serious benchmarks by all the compilers. My long experience in benchmarking tells me that whatever benchmark you use, people will always criticize you for the choice. I have only one excuse: It is better to have some information than none.
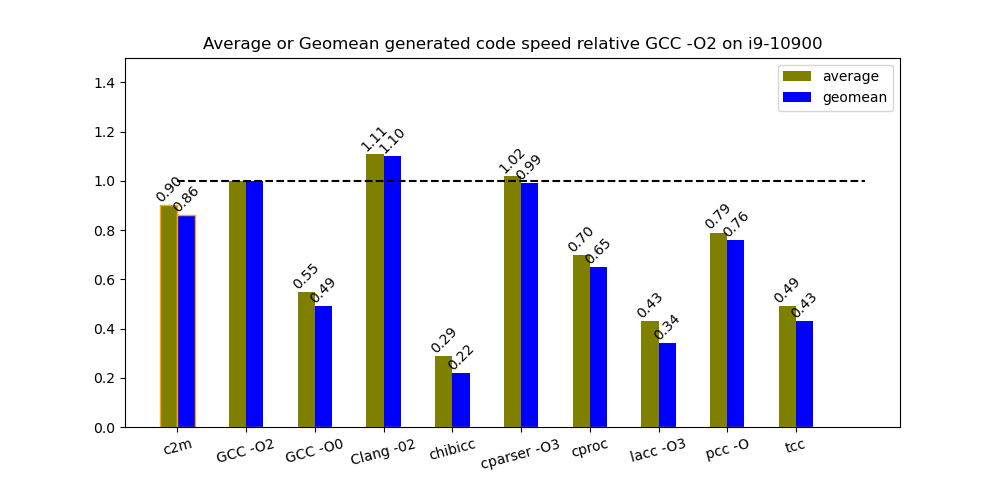
Figure 4 shows average and geomean relative speeds (by measuring CPU time) of the generated code from each compiler on an i9-10900 under Fedora Core 32. The baseline is code generated by GCC with -O2. For c2m, execution time includes the work of the C-to-MIR compiler and JIT, but this work is a small part of the entire execution. I ran each benchmark three times and chose the best time.
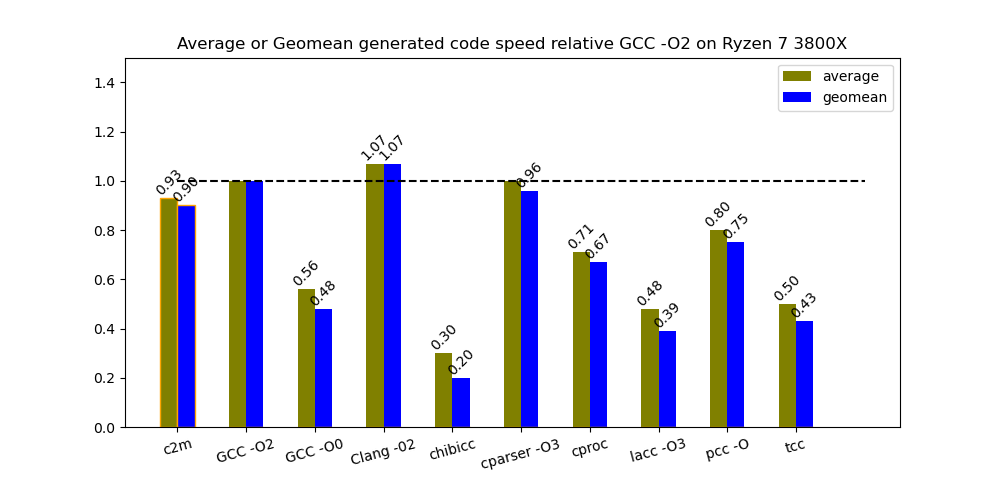
People sometimes criticize me for rarely benchmarking AMD CPUs. Figure 5 shows the results of the benchmarks on AMD Ryzen 7 3800x, which are basically the same.
Bulk compilation speed
To get bulk compilation speed, I compiled the bzip2 source as one file. The file is about 6,500 lines of C code. I used c2m in nonparallel mode to produce an MIR binary. Again, I compiled the source file three times and chose the best time. Figure 6 shows the compilation speed of the compilers relative to the speed of gcc -O2.
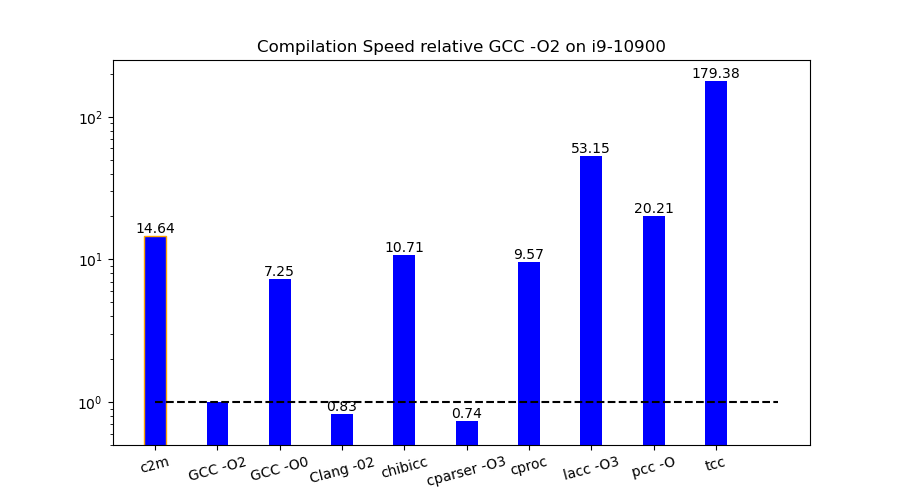
The differences in speed are quite significant, so I have to use a logarithmic scale in the chart. The tiny C compiler has incredible speed. If it had generated better code, it could have been used as a JIT compiler with the C language as its interface.
Besides bulk compilation speed, compiler startup time is very important for JIT compilers of dynamic programming languages, because just-in-timed methods are quite small. GCC and Clang are the worst performers here. If you are interested in this topic, you can read my previous article about the lightweight JIT compiler project.
Compiler code size
The differences in compiler code size are even bigger. The smallest compiler (Chibicc) is almost 1,000 times smaller than the biggest one (Clang), as shown in Figure 7.
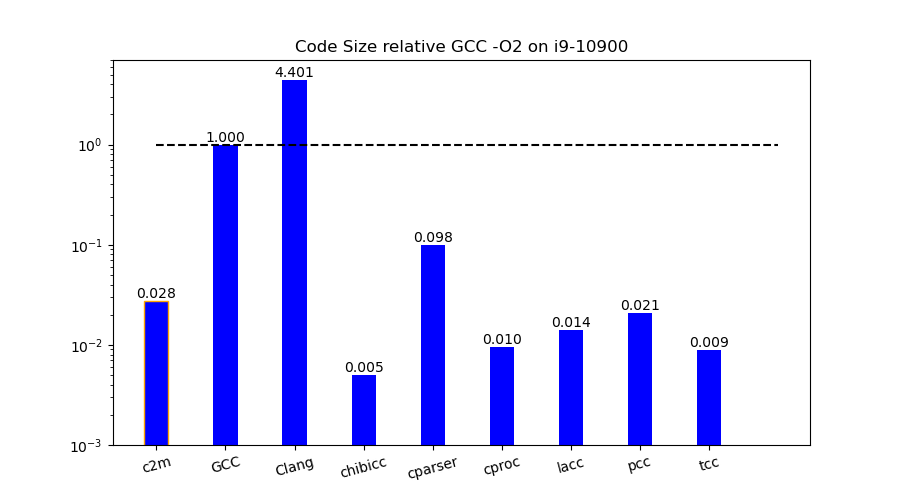
Some compilers have a huge bss section (for instance, on Cproc it is 17MB). Therefore, for size calculations, I used the sizes of only the text and data sections.
I used GCC and Clang from the Fedora Core 32 distribution. For all other compilers, I built them with optimizations (that is, in release mode).
For GCC I took the gcc and cc1 executables. For Clang I used clang and its libraries libclang-cpp and libLLVM. For PCC I used its executables cc, ccom, and cpp. For Cproc I used cproc, cproc-qbe, and qbe. All other compilers consist of one executable.
Future plans for the C-to-MIR compiler
My short-term plan is to offer a first release of the MIR project, including the C-to-MIR compiler, before the end of 2021.
In the following releases, I would like to:
- Improve C-to-MIR compilation speed
- Improve C-to-MIR generated code
- Port MIR to more targets (64-bit riscv and mips64 Linux and Apple M1 macOS)
- Implement speculation/de-optimization extensions on the C and MIR levels
Although C-to-MIR compilation speed was never a major goal, its speed is quite competitive with other C compilers. I have found that some people prefer to use the C language instead of MIR for their JIT implementations. This makes improving C-to-MIR compilation speed an important task. Therefore, I put it as a first priority.
Some people asked me whether it is possible to make a regular C compiler, not a JIT. Writing a compiler is not a difficult or big task if one uses an existing assembler. To make a compiler, we just need to emit assembler code instead of the current machine code. However, to do this right would require emitting debug information (for example, in dwarf format) and generating position-independent code (PIC) to generate code for shared libraries.
Conclusion
The C JIT compiler and interpreter implemented in the MIR project shows competitive generated code and compilation speed. It has the potential to be used for scripting in C and as a JIT compiler for implementing different programming languages. I hope it can also be used for educational purposes.
Last updated: February 5, 2024