For the past three years, I've been participating in adding just-in-time compilation (JIT) to CRuby. Now, CRuby has the method-based just-in-time compiler (MJIT), which improves performance for non-input/output-bound programs.
The most popular approach to implementing a JIT is to use LLVM or GCC JIT interfaces, like ORC or LibGCCJIT. GCC and LLVM developers spend huge effort to implement the optimizations reliably, effectively, and to work on a lot of targets. Using LLVM or GCC to implement JIT, we can just utilize these optimizations for free. Using the existing compilers was the only way to get JIT for CRuby in the short time before the Ruby 3.0 release, which has the goal of improving CRuby performance by three times.
So, CRuby MJIT utilizes GCC or LLVM, but what is unique about this JIT?
MJIT does not use existing compiler JIT interfaces. Instead, it uses C as an interface language without losing compilation speed. Practically the same compilation speed as with the existing JIT interfaces is achieved by using precompiled headers and a memory filesystem.
Choosing C as a JIT interface language significantly simplifies JIT implementation, maintenance, and debugging. Doing so also makes the JIT independent from a particular C compiler. Precompiled headers are a pretty standard feature of modern C/C++ compilers.
Disadvantages of GCC/LLVM-based JIT
Enough about the advantages of GCC/LLVM-based JITs. Let us speak about the disadvantages:
- GCC/LLVM-based JITs are big.
- Their compilation speed can be slow.
- It is hard to implement combined optimizations of code written in different programming languages.
Regarding the last point, in the case of CRuby, Ruby and C must be optimized together as you can be using implementation languages of different Ruby methods. Let us consider these disadvantages in more detail.
GCC/LLVM size
First of all, GCC and LLVM are big compared to CRuby. How big? If we ask SLOCCount, GCC and LLVM sources are about three times larger than CRuby, as shown in Figure 1. CRuby is already a big project by itself, with its source consisting of more than 1.5 million lines of code:
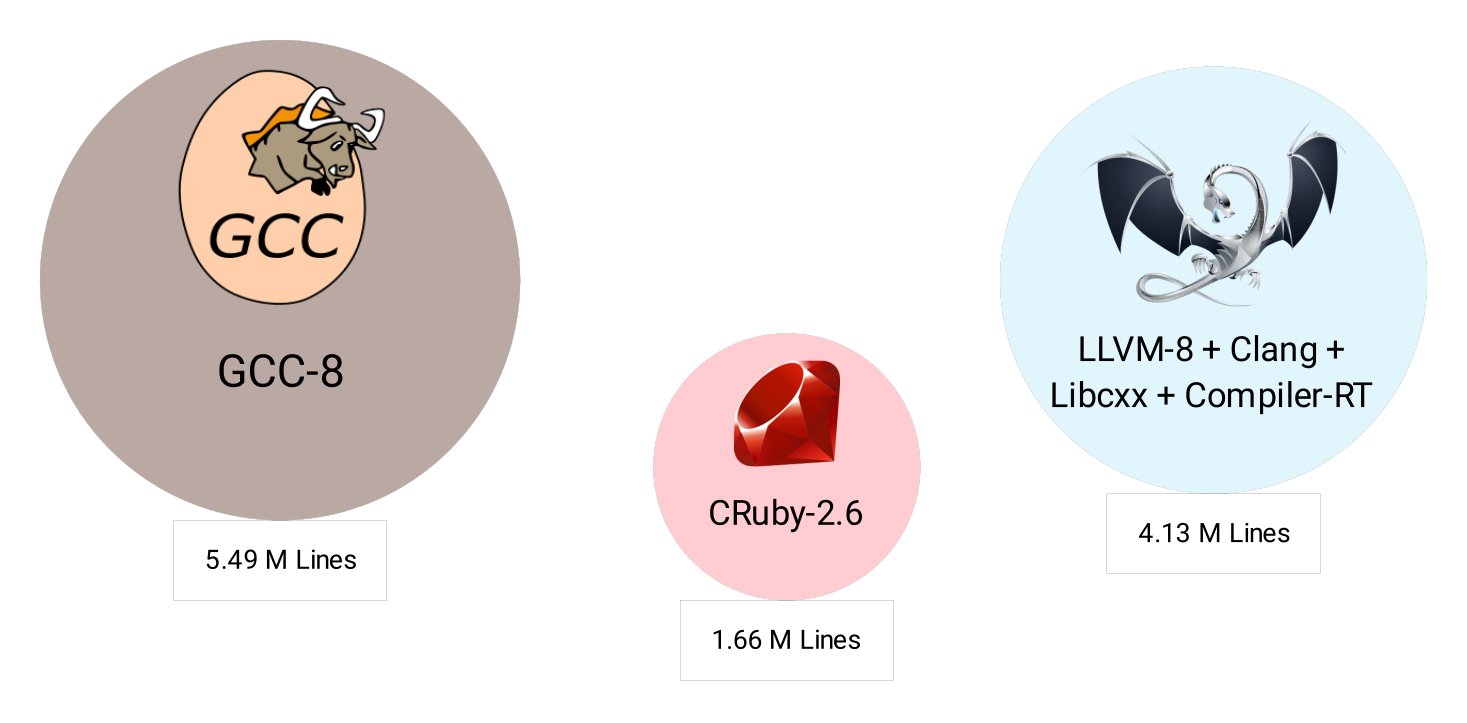
As for the machine code, GCC and LLVM binaries are much bigger, from 7 to 18 times bigger, as shown in Figure 2:
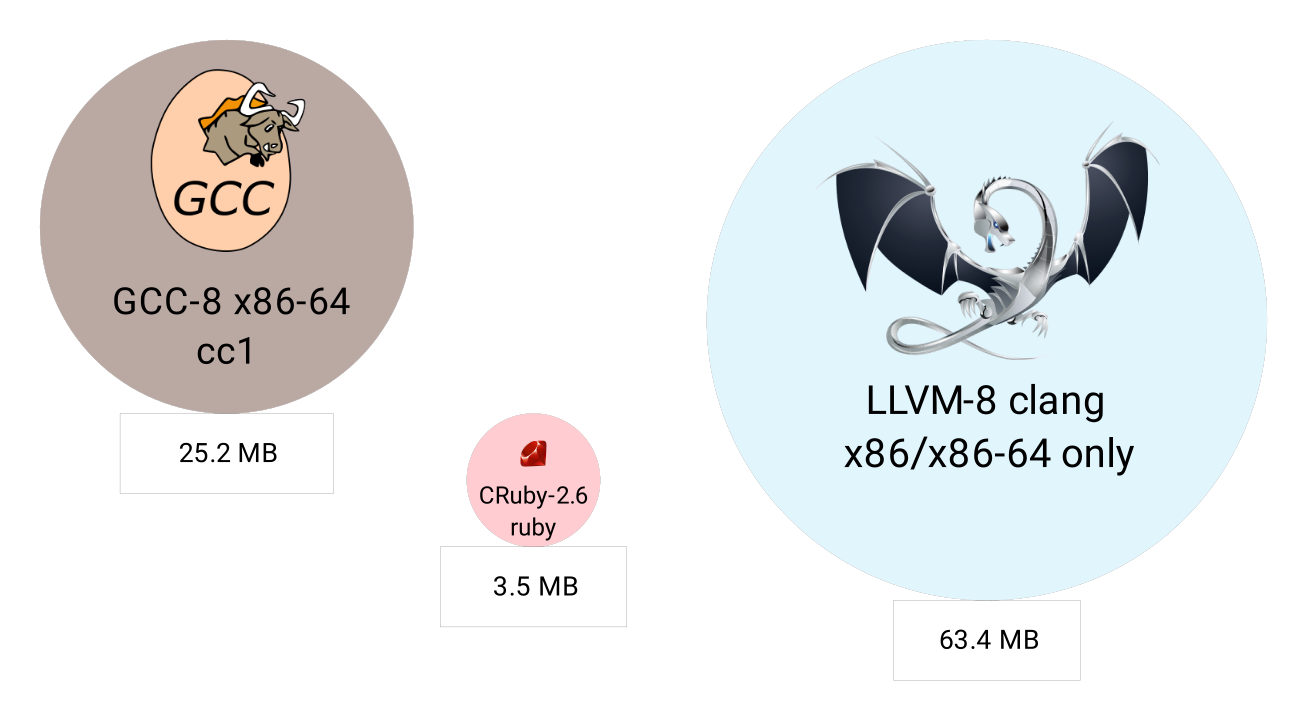
Imagine adding a JIT for a simple language with LLVM. You can easily increase its interpreter binary code size by a hundred times. CRuby with the current JIT requires much less memory than JRuby or Graal/TruffleRuby. Still, the large code size can be a serious problem for cloud, IoT, or mobile environments.
GCC/LLVM compilation speed
Second, GCC/LLVM compilation speed is slow. It might feel like 20ms on a modern Intel CPU for a method compilation with GCC/LLVM is short, but for less powerful but widely used CPUs this value can be a half-second. For example, according to the SPEC2000 176.gcc benchmark, the Raspberry PI3 B3+ CPU is about 30 times slower than the Intel i7-9700K (score 320 vs. 8520).
We need JIT even more on slow machines, but JIT compilation becomes intolerably slow for these. Even on fast machines, GCC/LLVM-based JITs can be too slow in environments like MinGW. Faster JIT speed can also help achieve desirable JIT performance through aggressive adaptive optimization and function inlining.
What might a faster JIT compilation look like? A keynote about the Java Falcon compiler at the 2017 LLVM developers conference suggested about 100ms per method for an LLVM-based JIT compiler and one millisecond for the faster tier-one JVM compiler. Answering a question about using LLVM for a Python JIT implementation, the speaker (Philip Reems) said that you first need a tier-one compiler implementation. With MJIT for Ruby, we went from the opposite direction by implementing a tier two compiler first.
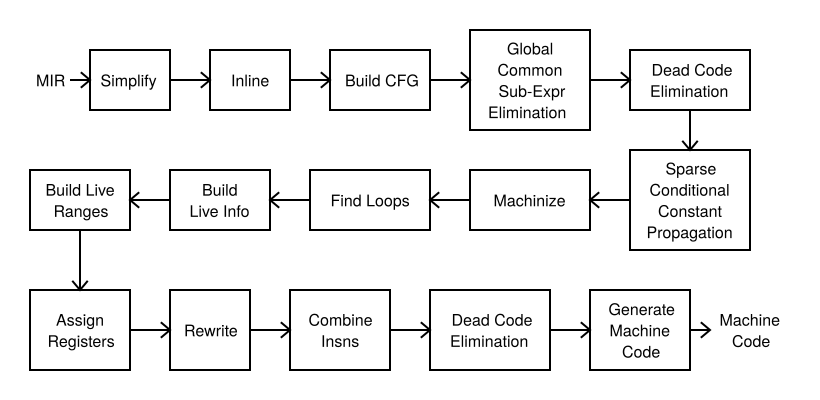
So, why is GCC/LLVM compilation slow? Here is a full list of GCC-8 backend passes presented in their execution order, as shown in Figure 3:

There are 321 compiler passes and 239 of them are unique. This fact probably reflects that the GCC community has had more than 600 contributors. Some of these passes are repeated runs of the same optimizations (e.g., dead code elimination). Many compiler passes traverse the intermediate representation (IR) more than once. For example, the register allocator traverses it at least eight times. Running all of these passes requires a lot of time. There are those who think that by switching off most of the passes we can speed up GCC/LLVM compilation proportionally. Unfortunately, this is not true.
The biggest problem for using GCC and LLVM in a lightweight JIT compiler is long initialization time. For small code, initialization can take a majority of the compilation time, and small-method code is a typical scenario for Ruby and other programs in other dynamic high-level languages.
The following diagram illustrates the long startup time of GCC-8/LLVM-8 on an Intel i7-9700K under Fedora Core 29, as shown in Figure 4:

So, you can not switch off optimizations and proportionally speed up GCC and Clang.
Function inlining with GCC/LLVM
Function inlining is the most important optimization for better JIT performance. Method calls are expensive and inlining permits optimizations in a bigger scope.
When both are written in Ruby, inlining one method into another one is a not a problem. We can do this on the VM instruction level or when we generate machine code. The problem is inlining a method written on C into a method written on Ruby or vice versa.
Here is a small example:
x = 2
10.times {x *= 2}
Ruby code interpreted by the CRuby VM calls the method times, which is implemented in C. This C code repeatedly calls another Ruby method interpreted by the VM and implementing a multiplication operation, as shown in Figure 5:

How can we integrate all three parts of the code into one generated function? Let us consider the current structure of MJIT, as shown in Figure 6:

A C function that implements a standard Ruby method and can be inlined should be in the precompiled header. The more code we insert into the environment header, the slower the MJIT precompiled header generation, and thus the slower the MJIT startup. Another consequence is slower JIT code generation because of bigger precompiled header.
We could also rewrite C code in Ruby. Sometimes this could work, but in the majority of cases, doing so would result in slower generated code.
Lightweight JIT compiler
After analyzing the current disadvantages of MJIT, I came to the conclusion that a lightweight JIT compiler could solve these issues. I think the lightweight JIT compiler should be either an addition to the existing MJIT compiler or the only JIT compiler in cases where the current one does not work.
There is another reason for the lightweight JIT compiler. I believe this compiler could be a good solution for MRuby JIT and would help to expand Ruby usage from a mostly server market to the mobile and IoT markets.
So, last year I started to work on a lightweight JIT compiler mostly in my spare time. Because I'd like to use the JIT compiler not only for Ruby, I decided to make it a universal JIT compiler and a standalone project.
MIR
The central notion of JIT is a well-defined intermediate language called Medium Internal Representation, or MIR. You can find the name in Steven Muchnik's famous book "Advanced Compiler Design and Implementation." The Rust team also uses this term for a Rust intermediate language. Still, I decided to use the same name because I like it: MIR means "peace" and "world" in Russian.
MIR is strongly typed and flexible enough. MIR in different forms is capable of representing machine code for both CISC and RISC processors. Although this lightweight JIT compiler is a standalone project, I am planning to try it first with CRuby or MRuby JIT.
To get a better understanding of MIR, let us consider the Eratosthenes prime sieve algorithm code as an example. Here is the C code for sieve:
#define Size 819000
int sieve (int iter) {
int i, k, prime, count, n; char flags[Size];
for (n = 0; n < iter; n++) {
count = 0;
for (i = 0; i < Size; i++)
flags[i] = 1;
for (i = 0; i < Size; i++)
if (flags[i]) {
prime = i + i + 3;
for (k = i + prime; k < Size; k += prime)
flags[k] = 0;
count++;
}
}
return count;
}
And here is the MIR textual representation for the same code. There are no hard registers in MIR, only typed variables. The calling convention is also hidden:
m_sieve: module
export sieve
sieve: func i32, i32:iter
local i64:flags, i64:count, i64:prime, i64:n, i64:i, i64:k, i64:temp
alloca flags, 819000
mov n, 0
loop:
bge fin, n, iter
mov count, 0; mov i, 0
loop2:
bgt fin2, i, 819000
mov ui8:(flags, i), 1; add i, i, 1
jmp loop2
fin2:
mov i, 0
loop3:
bgt fin3, i, 819000
beq cont3, ui8:(flags,i), 0
add temp, i, i; add prime, temp, 3; add k, i, prime
loop4:
bgt fin4, k, 819000
mov ui8:(flags, k), 0; add k, k, prime
jmp loop4
fin4:
add count, count, 1
cont3:
add i, i, 1
jmp loop3
fin3:
add n, n, 1; jmp loop
fin:
ret count
endfunc
endmodule
The first operands in the func pseudo-instruction are the function return types (a MIR function can return multiple values), and after that, all function arguments are declared. Local variables are declared as 64-bit integers through the local pseudo-instruction.
Lightweight JIT compiler project goals
I set performance goals for the JIT compiler. Compared to GCC with -O2, this compiler should have 100 times faster compilation, 100 times faster start-up, and 100 times smaller code size. As for the generated code performance, I decided that it should be at least 70% of GCC -O2 performance.
The implementation should be simple too at less than 10K C lines, because I want wider adoption of this tool. Simple code is easier to learn and maintain. I'd like also to avoid any external dependencies for this project. At the end of the article, you can see the actual results I have now.
How to achieve these performance goals
Optimizing compilers are big and complex because they are trying to improve any code, including rare edge cases. Because they do a lot of things, compilation speed becomes important. These compilers use the fastest algorithms and data structures for compiled programs of different sizes, from small to huge ones, even if the algorithms and data structures are complicated.
So, to achieve our goals, we need to use a few of the most valuable optimizations, optimize only frequently occurring cases, and use algorithms with the best combination of simplicity and performance.
So what are the most valuable optimizations? The most important optimizations are those for effectively exploiting the most commonly used CPU resources: instructions and registers. Therefore, the most valuable optimizations are good register allocation (RA) and instruction selection.
Recently, I did an experiment by switching on only a fast and simple RA and combiner in GCC. There are no options to do this, I needed to modify GCC. (I can provide a patch if somebody is interested.) Compared to hundreds of optimizations in GCC-9.0 with -O2, these two optimizations achieve almost 80% performance on an Intel i7-9700K machine under Fedora Core 29 for real-world programs through SpecCPU, one of the most credible compiler benchmark suites:
| SPECInt2000 Est. | GCC -O2 | GCC -O0 + simple RA + combiner |
|---|---|---|
| -fno-inline | 5458 | 4342 (80%) |
| -finline | 6141 | 4339 (71%) |
You might ask, "How is this possible? What do the other numerous optimizations do?" Having worked for many years on optimizing compilers, I would like to take this opportunity to say how difficult it is to improve the performance of well-established optimizing compilers.
The reality of optimizing compiler performance
In the integrated circuit world, there is Moore's law, which says that the number of transistors on the circuit doubles every 18 months.
In the optimizing compiler world, people like to mention Proebsting's law to show how hard it is to improve the performance of generated code. Proebsting's law says that optimizing compiler developers improve generated code performance by two times every 18 years.
Actually, this "law" is too optimistic, and I never saw that anyone tested this. (It is hard to check because you need to wait 18 years.) So, recently I checked it on SPEC CPU2000. SPEC CPU is one of the most credible benchmark suites used by optimizing compiler developers. It contains a set of CPU-intensive applications from the real world; for example, a specific version of GCC is one of the benchmarks. There are many versions of SPEC CPU: 2000, 2006, and 2017. I used the 2000 version because it does not require days to run it. I used the 17-year-old GCC-3.1 compiler (the first GCC version supporting AMD64) and the recent version GCC-8 in their peak performance modes on the same Intel i7-4790K processor:
| GCC 3.1 (-O3) | GCC 8 (-Ofast -flto -march=native) | |
|---|---|---|
| SPECInt2000 w/o eon | 4498 | 5212 (+16%) |
The actual performance improvement is only 16%, which is not close to the 100% Proebsting's law states.
Looking at the progress of optimizing compilers, people believe we should not spend our time on their development at all. Dr. Bernstein, an author of the SipHash algorithm used in CRuby, expressed this point of view in one of his talks.
There is another point of view that we should still try to improve the performance of generated code. By some estimates, in 2013 (before active cryptocurrency mining) computers consumed 10% of all produced electricity. Computer electricity consumption in the year 2040 could easily equal the total electricity production from the year 2016.
A one percent compiler performance improvement in energy-proportional computing (an IT industry goal) means saving 25 terawatt-hours (TWh) out of the 25,000 TWh annual world electricity production.
Twenty-five terawatt-hours is equal to the average annual electricity production of six Hoover dams.

Although the optimizing compiler topic is interesting to me, let us return to the MIR project description.
The current state of the MIR project
Figure 7 shows a diagram detailing the current state of the MIR project:

Currently, I can create MIR through an API or from MIR textual or binary representation. The MIR binary representation is up to 10 times more compact and up to 10 times faster to read than the textual one.
I can interpret MIR code and generate AMD64 machine code in memory from MIR. Recently, I got rid of the only external dependency used by the MIR interpreter, the Libffi foreign function interface library.
I can generate C code from MIR, and I am working on a C-to-MIR compiler, which is about 90% done in my opinion.
Possible future directions for the MIR project
Figure 8 shows the possible development directions for this project:

Generating MIR from LLVM internal representation permits the use of code from different languages implemented with LLVM; for example, Rust or Crystal.
Generating MIR from Java bytecode would allow the same for languages implemented with JVM.
Generating WebAssembly from MIR could allow using MIR code in web browsers. Actually, MIR features are pretty close to these of WebAssembly. The only big difference is that WebAssembly is a stack-based internal representation, and MIR is a register-based one.
There will be many interesting possibilities if all the directions are implemented.
MIR generator
Currently, the most interesting component, at least for me, is the MIR generator producing optimized machine code. Figure 9 shows how it works:
Here is the process in more detail. First, we simplify MIR as much as possible, which means only using register indirect memory addressing. It also means that immediate instruction operands are used only in move instructions. During this pass, we also remove unused instructions through local value numbering.
Then, we inline function calls represented by the MIR instructions inline and calland, after that, build the control-flow graph (CFG)—in other words, the basic blocks and edges between them. Next, we transform code to reuse already calculated values in global scope through so-called global common subexpression elimination (GCSE). This step is an important optimization for inlined code.
The next pass mostly removes instructions found redundant on the previous pass through a dead code elimination optimization. Then, we do sparse conditional constant propagation (SCCP). This step is also an important optimization for inlined code when there are constant call arguments. We also find that there can be constant expression values.
Constant values can switch off CFG paths during any execution. Switching off these paths can make other values constant, too. SCCP is a combined optimization, which means its result is better than performing the two separate optimizations of constant propagation and removing unused CFG paths.
After that, we run the machine-dependent code. Most x86 instructions, for example, additionally require the instruction result operand to be the same as one of the input operands. Therefore, the machine-dependent code is run to produce two-operand instructions. This code also generates additional MIR instructions for call parameter passing and returns.
The next step is to find natural loops in the MIR code CFG. This information will be used for the subsequent register allocation. Then, we calculate live information for MIR variables. In the compiler world, this technique is known as a backward data-flow problem.
Once that work is complete, we calculate program points where MIR variables live. This info is used in a fast register allocator that assigns target hard registers, or stack slots, to MIR variables and removes various copy instructions. After the register assignment, we rewrite the MIR code, changing variables to the assigned hard registers or stack slots.
Then, we try to combine pairs of data-dependent MIR instructions into ones whose forms can represent a machine instruction. This is an instruction selection task. This pass also does copy propagation optimization.
After instruction combining, there are usually many instructions whose output is never used. We delete such instructions. And then, finally, we generate machine code in memory. Each MIR instruction is encoded by a machine instruction. For AMD64, the encoding can be complicated.
MIR generator features
These days, most compiler optimizations are implemented for static single assignment form. This is a special form of IR where we have only one assignment to each variable in the function IR. It was invented by IBM researchers a long time ago.
Using SSA simplifies the optimization implementations, but building and destroying this form is expensive. Using SSA for the MIR generator's short-pass pipeline makes little sense to me, so I don't use it.
Also, I don't generate position-independent code. I don't see any reasons to do this now. Generating such code is more complicated and decreases performance. For the AMD Geode processor (used in one version of the laptop for the One Laptop per Child initiative) the performance decrease achieved 7%. For modern processors, the performance decrease is much smaller but still exists.
Possible ways to compile C to MIR
To start using MIR in CRuby, I need a C-to-MIR compiler. There are several ways to implement this feature. I could implement an LLVM IR-to-MIR compiler or write a GCC port targeting MIR, but doing this would create a big dependency on a particular external project. It is not an easy task either. Once, I worked in a team that specialized in porting GCC to new targets and the standard estimation was at least six months of work to create a simple "hello, world" program.
On the other hand, people have written small C compilers pretty quickly. Here, I can mention the Tiny C Compiler, and the recent 8cc and 9cc compiler projects.
So, I decided to write my own C-to-MIR compiler first. This compiler should implement standard C11 without optional features, such as variable arrays, complex numbers, and atomic data.
The major goal is simplicity, not speed. Again, doing this makes studying the code easier for other people and reduces the effort required to maintain it.
C-to-MIR compiler
Simplicity is usually achieved by dividing tasks into small, manageable subtasks. There is even an extreme nanopass compiler design used for studying compiler topics in education.
My approach to the C compiler implementation is classic division on four passes of approximately the same size, as shown in Figure 10:

I don't use any tools for the compiler, like YACC. Also, I don't modify the ANSI standard grammar, although it is ambiguous. I use a parsing expression grammar (PEG) manual parser. It is a parser with moderate backtracking and it is simple and small but a bit slower than deterministic parsers.
The MIR-to-C compiler is mostly implemented. It passes around 1,000 tests from different C test suites. Recently, I achieved an important milestone: a successful bootstrap. The new c2m compiles its own sources and generates a MIR binary. The execution of this MIR binary processes c2m sources again and generates another MIR binary, and the two MIR binary files are identical (option -el of the c2m invocation that follows means the execution of generated MIR code through lazy machine code generation):
cc -O3 -fno-tree-sra -std=gnu11 -Dx86_64 -I. mir-gen.c c2mir.c c2mir-driver.c mir.c -ldl -o c2m ./c2m -Dx86_64 -I. mir-gen.c c2mir.c c2mir-driver.c mir.c -o 1.bmir ./c2m 1.bmir -el -Dx86_64 -I. mir-gen.c c2mir.c c2mir-driver.c mir.c -o 2.bmir
Still, a lot of effort should be made to finish the missing obligatory C11 standard features (e.g., wide characters), achieve full call ABI compatibility, generate more efficient code for switches, and implement the GCC C extensions necessary for the CRuby JIT implementation.
LLVM IR-to-MIR compiler
I am also working on an LLVM IR-to-MIR compiler. Currently, I am focusing on translating the LLVM IR produced by Clang from standard C code. Doing so will be useful when we want to generate more optimized MIR code and don't need a fast C compiler (e.g., when building a MIR-based JIT for a programming language).
The only missing part now is the translation of composite values, which are generated by Clang in rare cases when passing small structures in function calls or returning them from function calls. In the future, this translator could be extended to support code generated from other programming languages implemented with LLVM, such as Rust.
I hope that LLVM IR will stabilize in the near future and no extensive maintenance will be necessary.
Possible ways to use MIR for CRuby MJIT
So how do I plan to use the MIR project for CRuby? Figure 11 shows how the current MJIT works:

MIR compiler as a tier-one JIT compiler in CRuby
Figure 12 shows how the future MJIT would look after implementing a MIR-based JIT compiler as a tier-one compiler:

The blue parts show the new data-flow for MJIT. When building CRuby, we could generate MIR code for the standard Ruby methods written in C. We can load this MIR code as a MIR binary. This part could be done very quickly.
MJIT could create MIR code for a Ruby method through the MIR API. This MIR code could inline the already existing MIR code functions. The corresponding machine code can be generated by the MIR generator. This is a fast method, but we could also generate machine code by translating MIR into C and then using GCC or LLVM. This is a much slower method, but it permits us to use the full spectrum of GCC/LLVM optimizations, plus it permits efficient implementation of inlining C code into Ruby code and vice versa.
MIR compiler as a single JIT compiler in CRuby
For some environments, the MIR JIT compiler could be used as a single JIT compiler. In this case, MIR with MJIT would look as you see in Figure 13:

MIR compiler and C-to-MIR compiler as a single JIT compiler in CRuby
Instead of directly generating MIR for the JIT compiler, we could generate C code first and translate it into MIR with the C-to-MIR translator. In this case, MJIT would look as you see in Figure 14:

I discussed the lightweight JIT compiler project with a few people, and two of them independently wanted to generate C code for JIT. It would make their life easier to use a MIR-based JIT compiler for their own JIT implementations.
The C-to-MIR JIT compiler is pretty small, has a fast startup, and can be used as a library to read the generated C code from memory. Although the C-to-MIR translator was not designed to be fast, it is still about 15 times faster than GCC with -O2. All of this makes such an approach viable.
Current performance results
And finally, here are the current performance results for the MIR generator and interpreter compared to GCC-8.2.1. I used the sieve benchmark on an Intel i7-9700K machine running Fedora Core 29. The sieve C code has no include directives and is only about 30 preprocessed lines:
| MIR-gen | MIR-interp | gcc -O2 | gcc -O0 | |
|---|---|---|---|---|
| compilation [1] | 1.0 (75us) | 0.16 (12us) | 178 (13.35ms) | 171 (12.8ms) |
| execution [2] | 1.0 (3.1s) | 5.9 (18.3s) | 0.94 (2.9s) | 2.05 (6.34s) |
| code size [3] | 1.0 (175KB) | 0.65 (114KB) | 144 (25.2MB) | 144 (25.2MB) |
| startup [4] | 1.0 (1.3us) | 1.0 (1.3us) | 9310 (12.1ms) | 9850 (12.8ms) |
| LOC [5] | 1.0 (16K) | 0.56 (9K) | 93 (1480K) | 93 (1480K) |
The compilation speed of the MIR-generator is about 180 times faster than GCC with -O2. It takes 80 microseconds to generate the code for the sieve. And the sieve code generated by the MIR generator is only 6% slower.
The MIR generator's object size is much smaller than the object size of cc1. MIR generator has a fast startup time and is suitable for use as a tier1 JIT compiler.
Here are the notes for each table row:
- [1]: Wall time of compilation of sieve code (without any include file and with using the memory file system for GCC).
- [2]: The best wall time of 10 runs.
- [3]: The stripped sizes of
cc1for GCC, and the MIR core and interpreter or generator for MIR. - [4]: Wall time of object code generation for an empty C file, or of the generation of an empty MIR module through the API.
- [5]: Based only on the files required for the AMD64 C compiler and the minimal number of files required to create and run MIR code.
Current MIR SLOC distribution
Figure 15 shows a source line distribution for the current version of the MIR project. The MIR-to-C compiler is about 12 thousand lines of C code. MIR core is about nine thousand lines:

The MIR generator is less than five thousand lines.
Machine-dependent code used by the generator is about two thousand lines, so you can estimate the effort required to port the MIR generator to another target. For example, I expect that porting MIR to Aarch64 will take me about one to two months of work.
MIR project competitors
I've been studying JITs for a long time. Before starting the MIR project, I thought about adapting the existing code. Here is a comparison of MIR with the simple compiler projects I considered:
| Project | SLOC | License | IR type | Major Optimizations | Output |
|---|---|---|---|---|---|
| MIR | 16K C | MIT | non-SSA | Inlining, GCSE, SCCP, RA, CP, DCE, LA | Binary code |
| DotGNU LibJIT | 80K C | LGPL | non-SSA | Only RA and primitive CP | Binary code |
| .NET RyuJIT | 360K C++ | MIT | SSA | MIR ones minus SCCP plus LICM, Range | Binary code |
| QBE | 10K C | MIT | SSA | MIR ones plus aliasing minus inlining | Assembler |
| LIBFirm | 140K C | LGPL2 | SSA | RA, Inlining, DCE, LICM, CP, LA, Others | Assembler |
| CraneLift | 70K Rust | Apache | SSA | DCE, LICM, RA, GVN, CP, LA | Binary Code |
Here are the abbreviations used in the table:
- CP: Copy propagation
- DCE: Dead code elimination
- GCSE: Global common sub-expression elimination
- GVN: Global value numbering
- LA: Finding loops in CFG
- LICM: Loop invariant code motion
- RA: Register allocation
- Range: Range analysis
- SCCP: Sparse conditional constant propagation
Others include:
- Partial redundancy elimination
- Loop unrolling
- Scalar replacement
- Tail recursion elimination
- Expression reassociation
- Function cloning
- Strength reduction
- Loop optimizations
- Load store motion
- Jump threading
After studying these projects closely, I decided to start the MIR project. The biggest cons of the existing projects were their size, the fact that it would be hard for me to achieve my goals using them, and that I can not control the projects. Also, the smaller source size of the MIR project makes studying the code easier for other people and reduces the effort required to maintain it.
Plans for the MIR project
The MIR project is pretty ambitious. I've decided to develop it in an open way because this permits me to receive valuable feedback from many people in the project's early stages. You can follow the progress of the project on GitHub.
Although MIR is still in the early stages of development, I plan to start using it for a CRuby/MRuby JIT implementation soon. It would be a useful way to improve the MIR compiler implementation and find missing features.
If the use of a MIR-based compiler for Ruby JIT is successful, I will work on the first release of the MIR project code, which I hope will be useful for JIT implementations of other programming languages.
Last updated: March 28, 2023