Developers of software-defined network (SDN) frameworks and applications often use the DPDK utility testpmd to test DPDK features and benchmark network hardware performance. In the upcoming DPDK release 23.07, we've extended the functionality of the noisy_vnf module in testpmd to allow better simulations of heavily loaded servers or complex workloads. This can allow for more realistic benchmarks.
The default DPDK forwarding mode is io, which reads a batch of packets from an Rx queue and writes those packets directly to a Tx queue. Because the packets aren't processed or modified, the throughput achieved with this forwarding mode could be considered a theoretical maximum and not likely to be reproduced by real-world applications. Other forwarding modes like macswap and 5tswap process and modify layer 2 and 3, respectively; however, they do not perform any other per packet or batch processing. These forwarding modes are described in more detail in the DPDK testpmd documentation.
The noisy_vnf module has existed in DPDK since 18.11, but its usefulness has been limited by the inability to combine its use with other forwarding modes like macswap or 5tswap. Instead, it has only forwarded packets unmodified like the io module does. This has hindered its inclusion in complex simulations. With DPDK 23.07, noisy_vnf users will be able to select various forwarding modes, including mac, macswap, and 5tswap.
Network configuration
To illustrate how this can be used, I've configured a small network with a simple application that sends and receives UDP packets; this application measures the round trip time (RTT) between send and receive by embedding a timestamp in the packet on send and comparing that timestamp to the current time receipt. The network path takes traffic out of a physical network interface into a second interface through Open vSwitch, and finally, to testpmd. See Figure 1.
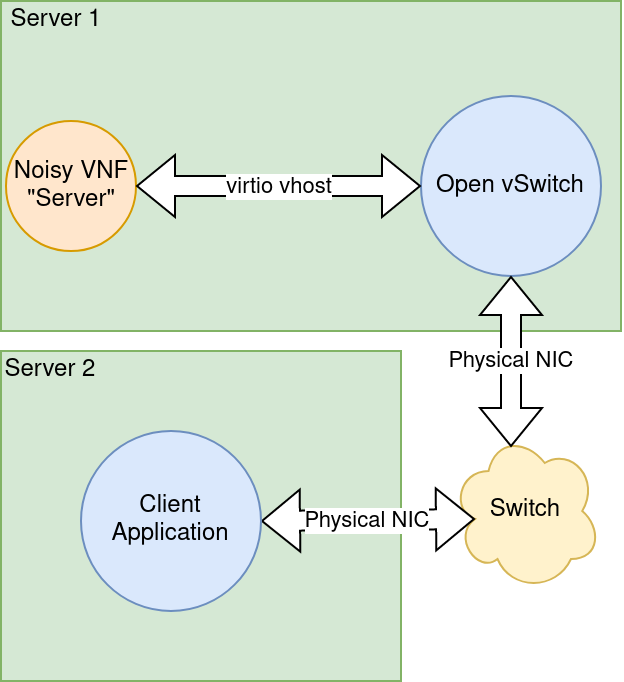
The use of Open vSwitch could allow for a variety of overlay networks to quickly be swapped in or out. For example, a VLAN or GENEVE VPN could easily be configured. But in this example, the default Normal action is left in place; this causes Open vSwitch to act like a traditional switch.
The client application was configured to write a timestamp into the packet that it sent and then compare that with the current time when received to get an accurate measure of end-to-end RTT.
Software configuration
We ran three separate tests to show how noisy_vnf parameters, as described below, can affect transmission rates.
noisy-forward-mode: Thenoisy_vnfforwarding mode; currently onlyio,mac,macswap, and5tswapare supported.noisy-tx-sw-buffer-size: Allocates a FIFO packet queue in number of packets. Ingress packets fill this buffer until it is full or until a flush time has expired.noisy-tx-sw-buffer-flushtime: Flush time, in milliseconds, for the FIFO packet buffernoisy-lkup-memory: The amount of memory to allocate – in MB – for random read/write activity.noisy-lkup-num-reads,noisy-lkup-num-writes,noisy-lkup-num-reads-writes: The number of reads and/or writes to conduct in the memory buffer allocated fromnoisy-lkup-memoryper packet.
The first test only used the 5tswap forwarding mode. Next, noisy_vnf was configured to perform 200 random reads and 20 random writes across 400 MB of memory. Finally, noisy_vnf was configured to perform 32 random reads and 8 random writes across a 200 MB buffer and to buffer 128 packets in a FIFO pipeline. The actual testpmd command-line invocations are included below.
The first set of noisy_vnf parameters attempts to simulate an application that requires a lot of processing per packet, including accessing memory that may have fallen out of the CPU cache; for example, traversing a large data structure like nested hash tables. The second set of parameters attempts to simulate an application that has to queue up multiple packets before processing them all at once. The per-packet read and write rates are much lower but, in aggregate, add up to a larger amount of memory activity per batch of packets.
# 5tswap run
dpdk-testpmd --in-memory --single-file-segment --no-pci --vdev \
'net_virtio_user0,mac=00:01:02:03:04:05,path=/tmp/vhost0,server=1,queues=4' \
-- -i --rxq 4 --forward-mode=5tswap# noisy_vnf run 1
dpdk-testpmd --in-memory --single-file-segment --no-pci --vdev \
'net_virtio_user0,mac=00:01:02:03:04:05,path=/tmp/vhost0,server=1,queues=4' \
-- -i --noisy-tx-sw-buffer-size=0 --noisy-tx-sw-buffer-flushtime=0 \
--noisy-lkup-memory=400 --noisy-lkup-num-writes=20 --noisy-lkup-num-reads=200 \
--noisy-forward-mode=5tswap --rxq 4 --forward-mode=noisy# noisy_vnf run 2
dpdk-testpmd --in-memory --single-file-segment --no-pci --vdev \
'net_virtio_user0,mac=00:01:02:03:04:05,path=/tmp/vhost0,server=1,queues=4' \
-- -i --noisy-tx-sw-buffer-size=128 --noisy-tx-sw-buffer-flushtime=20 \
--noisy-lkup-memory=200 --noisy-lkup-num-writes=8 --noisy-lkup-num-reads=32 \
--noisy-forward-mode=5tswap --rxq 4 --forward-mode=noisy# OVS configurations
34a5a4cc-69e2-46e5-abed-8a73e5b08dd7
Bridge noisytest
datapath_type: netdev
Port dpdk0
Interface dpdk0
type: dpdkvhostuserclient
options: {n_rxq="4", vhost-server-path="/tmp/vhost0"}
Port noisytest
Interface noisytest
type: internal
Port dpdk1
Interface dpdk1
type: dpdk
options: {dpdk-devargs="0000:03:00.1", n_rxq="4", n_rxq_desc="4096", n_txq_desc="4096"}
ovs_version: "3.0.90"The client application used for this test is available on GitHub.
Results
The table below shows performance results in packets per second and microsecond round trip time while only changing the testpmd invocation.
5tswap test
Packet source and destination addresses swapped.
- Packets per second: 145,000
- Round-trip time: 134
noisy_vnf 1 test
Source and destination swapped; 220 memory operations over 400 MB of memory per batch.
- Packets per second: 40,000
- Round-trip time: 235
noisy_vnf 2 test
Source and destination swapped; 40 memory operations over 200 MB of memory per batch; and 128 packets queued in a FIFO buffer.
- Packets per second: 992
- Round-trip time: 20,225
Conclusion
These results demonstrate how substantially a packet buffer or a lot of random memory access can impact packet throughput. Merely inserting a few hundred memory operations with each packet saw a near doubling of round trip time. Using a FIFO packet buffer had a 40x reduction in packets per second throughput. These results make it clear that a network speed test that doesn't involve any per packet processing will not give a complete picture of the performance capabilities of the network setup.
Last updated: July 30, 2026