Nodes in Red Hat OpenShift can be updated automatically through OpenShift's Machine Config Operator (MCO). A machine config is a custom resource that helps a cluster manage the complete life cycle of its nodes. When a machine config resource is created or updated in a cluster, the MCO picks up the update, performs the necessary changes to the selected nodes, and restarts the nodes gracefully by cordoning, draining, and rebooting them. The MCO handles everything ranging from the kernel to the kubelet.
However, interactions between the MCO and the GitOps workflow can introduce major performance issues and other undesired behavior. This article shows how to make the MCO and the Argo CD GitOps orchestration tool work well together.
Machine configs and Argo CD: Performance challenges
When using machine configs as part of a GitOps workflow, the following sequence can produce suboptimal performance:
- Argo CD starts a sync job after a commit to the Git repository containing application resources.
- If Argo CD notices a new or changed machine config while the sync operation is ongoing, MCO picks up the change to the machine config and starts rebooting the nodes to apply it.
- If any of the nodes that are rebooting contain the Argo CD application controller, the application controller terminates and the application sync is aborted.
Because the MCO reboots the nodes in sequential order, and the Argo CD workloads can be rescheduled on each reboot, it could take some time for the sync to be completed. This could also result in undefined behavior until the MCO has rebooted all nodes affected by the machine configs within the sync.
Extend the application's manifest in Git
The solution to the interactions in the previous section requires you to extend the application's manifest in Git by adding PreSync and PostSync hooks to Argo CD. Argo CD provides these hooks so that you can ensure that operations of your choice are performed before and after each sync (Figure 1). As the name suggests, a PreSync hook is a job that Argo CD executes right before the sync starts. Similarly, the PostSync hook executes after a sync.

We will use kam-blog as the sample application for this demo. We have generated this application following directions in the article Bootstrap GitOps with Red Hat OpenShift Pipelines and kam CLI.
Add sync hooks to Argo CD
Our PreSync job pauses the Machine Config Pool (MCP) so it does not reboot the nodes in order to apply the machine config changes. We ensure this pause by setting the flag .spec.paused to true.
To insert the PreSync job, create a file named pre-sync-job.yaml and add it to the same directory as the application. The content of the file is:
apiVersion: batch/v1
kind: Job
metadata:
annotations:
argocd.argoproj.io/hook: PreSync
argocd.argoproj.io/hook-delete-policy: HookSucceeded
name: mcp-worker-pause-job
namespace: openshift-gitops
spec:
template:
spec:
containers:
- image: registry.redhat.io/openshift4/ose-cli:v4.4
command:
- /bin/bash
- -c
- |
echo -n "Waiting for the MCP $MCP to converge."
echo $(oc patch --type=merge --patch='{"spec":{"paused":true}}' machineconfigpool/$MCP)
sleep $SLEEP
echo "DONE"
imagePullPolicy: IfNotPresent
name: mcp-worker-pause-job
env:
- name: SLEEP
value: "10"
- name: MCP
value: worker
restartPolicy: Never
serviceAccount: sync-job-sa
The PostSync hook resumes the MCP so that it reboots the nodes, applying the queued or incoming machine config changes. Enable this behavior by setting the flag .spec.paused to false. To insert the PostSync job, create a file named post-sync-job.yaml and add it to the same directory as the application. The content of the file is:
apiVersion: batch/v1
kind: Job
metadata:
annotations:
argocd.argoproj.io/hook: PostSync
argocd.argoproj.io/hook-delete-policy: HookSucceeded
name: mcp-worker-resume-job
namespace: openshift-gitops
spec:
template:
spec:
containers:
- image: registry.redhat.io/openshift4/ose-cli:v4.4
command:
- /bin/bash
- -c
- |
echo -n "Waiting for the MCP $MCP to converge."
sleep $SLEEP
echo $(oc patch --type=merge --patch='{"spec":{"paused":false}}' machineconfigpool/$MCP)
echo "DONE"
imagePullPolicy: Always
name: mcp-worker-resume-job
env:
- name: SLEEP
value: "5"
- name: MCP
value: worker
dnsPolicy: ClusterFirst
restartPolicy: OnFailure
serviceAccount: sync-job-sa
serviceAccountName: sync-job-sa
terminationGracePeriodSeconds: 30
Add permissions for Sync Hooks
In order for these jobs to execute successfully, they need permissions to manipulate machine config resources in the cluster. These permissions need to be granted using a ServiceAccount and appropriate ClusterRole and ClusterRoleBinding properties.
To add the ServiceAccount, ClusterRole, and ClusterRoleBinding properties, create a file named sync-job-cluster-rbac.yaml and add it to the same directory as the application. The content is:
apiVersion: v1
kind: ServiceAccount
metadata:
annotations: {}
name: sync-job-sa
namespace: openshift-gitops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: sync-job-sa-role
rules:
- apiGroups:
- apiextensions.k8s.io
- machineconfiguration.openshift.io
resources:
- machineconfigpools
verbs:
- get
- list
- patch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: sync-job-sa-rolebinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: sync-job-sa-role
subjects:
- kind: ServiceAccount
name: sync-job-sa
namespace: openshift-gitops
You can now apply the configuration to the cluster using the following command:
$ kubectl apply -k config/argocd
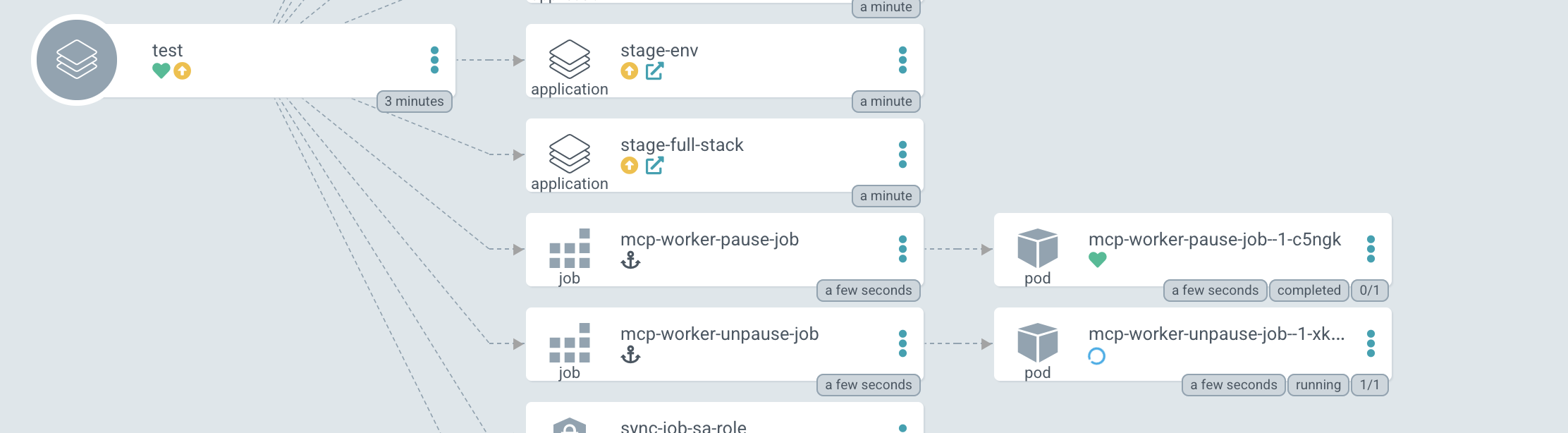
After you have applied the configuration, try manually syncing the application. You should see that the PreSync and PostSync jobs have paused and unpaused the MCP as shown in Figure 2.
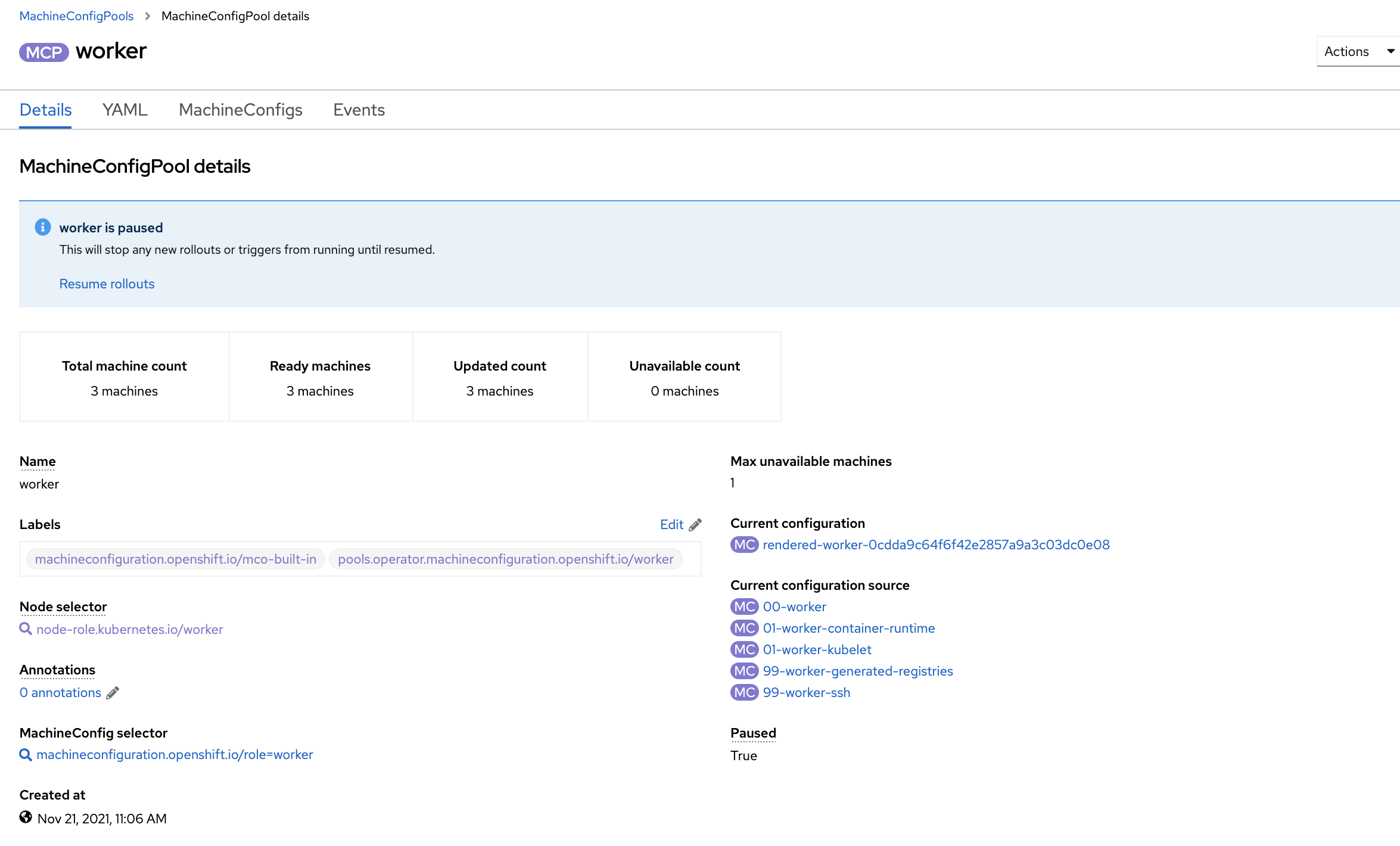
You can also see that the MCP paused by examining its details (Figure 3).
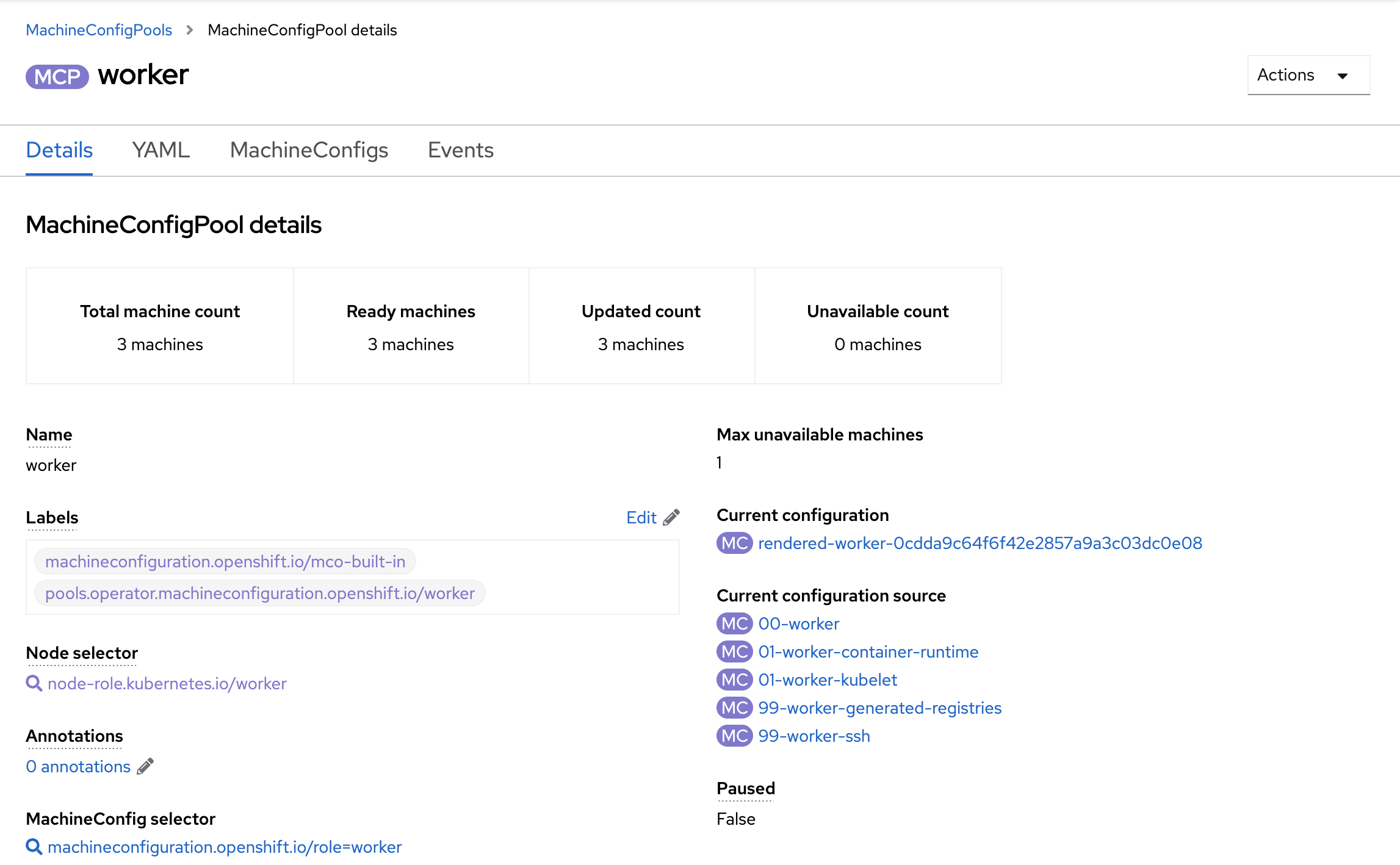
Once the sync job finishes, the PostSync job unpauses the MCP and resumes all the updates to the nodes in the cluster. The MCP details show this change as well (Figure 4).
If the sync fails for any reason, the MCP will stay paused and won't update the nodes. To resume MCP updates, you have to manually update the MCP and set the flag .spec.paused to false. You can set the flag using the following command:
$ oc patch --type=merge --patch='{"spec":{"paused":false}}' machineconfigpool/worker
Conclusion
Updates to machine configs can lead to uncontrolled node reboots, termination of the sync process, and unanticipated issues in the application. The workaround in this article helps to prevent nodes from rebooting while the critical Argo CD sync operations are in progress.
Last updated: September 20, 2023