In the era of cloud-based applications that divide tasks among multiple dedicated microservices, it is crucial to be able to dispatch events and messaging to multiple clients. This article presents an efficient architecture for broadcasting from a service using a Kubernetes headless service.
Why broadcasting is difficult
Many cloud-native patterns rely on messaging to deliver data to multiple receivers. Examples of these patterns include:
- Queue-based load leveling: Sets up a message queue as a buffer between a task and a service it invokes. The queue smooths out intermittent heavy loads that can cause the service to fail or the task to time out. Multiple services can subscribe to the queue to process data faster by doing it in parallel.
- Asynchronous request-reply: Executes client requests asynchronously so that the clients can proceed to other tasks while waiting for a slow server to respond. This pattern often uses queue-based load leveling to process the requests.
Chats, DNS servers, and publication/subscription (pub/sub) applications are common examples where servers need to send messages to multiple consumers.
When high performance and low latency are critical, one might seek a messaging solution based on the User Datagram Protocol (UDP). One advantage of UDP is that it is much faster than Transmission Control Protocol (TCP), because UDP skips all the handshakes and doesn't establish a connection before sending data. The trade-off is that transfers are not guaranteed to succeed, and packets can arrive out of order.
A second advantage of UDP is that, while TCP by itself offers only unicast, other delivery options are built into UDP that allow delivery to a large number of clients on the same network (Figure 1):
- Multicast: Transmission to a defined group of hosts.
- Broadcast: Transmission to all of the hosts on a network or subnet.
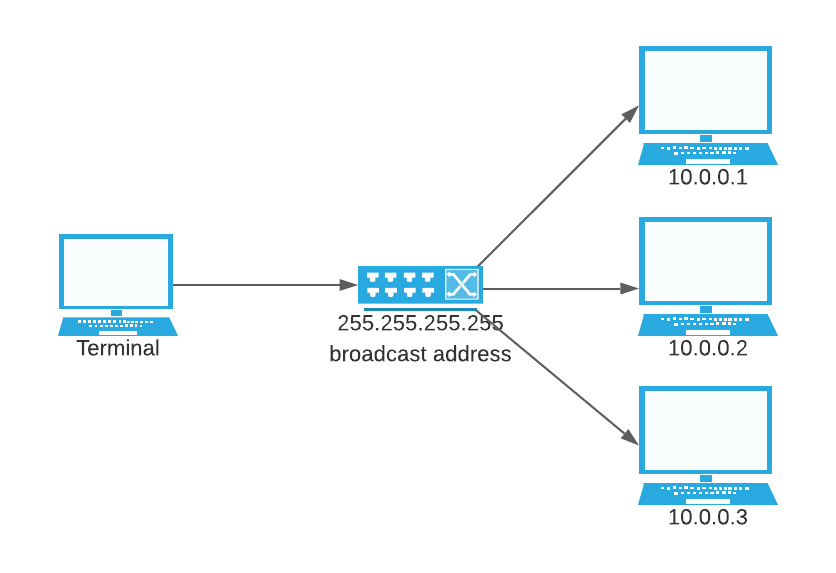
We could easily create a Python client service that listens to the broadcast address using the socket library:
from socket import *
PORT = 36000
serverSocket = socket(AF_INET, SOCK_DGRAM,IPPROTO_UDP) # UDP
serverSocket.setsockopt(SOL_SOCKET, SO_REUSEPORT, 1)
# Enable broadcasting
serverSocket.setsockopt(SOL_SOCKET,SO_BROADCAST,1)
serverSocket.bind(('', PORT))
while True:
data, addr = serverSocket.recvfrom(1024)
print("received message:{}".format(data) )
However, allowing UDP broadcasting poses major network security risks, such as UDP flooding and Smurf attacks. Therefore, administrators often block broadcast addresses.
When UDP broadcasting is prohibited or you need to shift the responsibility to the sending application for another reason, this article offers another option.
Headless services in Kubernetes
Kubernetes offers a service component called headless services. When using a headless service, Kubernetes doesn’t allocate a dedicated cluster IP address or perform load balancing. Instead, all the pods that are assigned to the service are connected to the service. The pods' IP addresses are recorded in DNS as the service's A records. An nslookup on the headless service returns all the pods' IP addresses with the corresponding selector.
Creating a headless service is pretty straightforward:
apiVersion: v1
kind: Service
metadata:
name: headless-udp
spec:
selector:
deployment: statefulset-udp-server
clusterIP: None #headless service definition
clusterIPs:
- None
type: ClusterIP
ports:
- protocol: UDP
port: 12000
targetPort: 12000
The following example executes an nslookup on the headless service from a pod on the same cluster, returning the bounded pod's IP address:
$ nslookup headless-udp
Server: 172.30.0.10
Address: 172.30.0.10#53
Name: headless-udp.ilpinto.svc.cluster.local
Address: 10.128.5.80
Name: headless-udp.ilpinto.svc.cluster.local
Address: 10.128.5.81
Although the headless service does not explicitly implement load balancing, it effectively performs a simple round-robin load balancing. In the example just shown, every message sent to headless-udp hostname is routed to the first IP address (10.128.5.80) unless its pod is down, in which case the message is sent to the second IP address (10.128.5.81).
Broadcasting from the application
Going back to our initial problem, we would like to broadcast a message in our Kubernetes or Red Hat OpenShift cluster, but the broadcast address is blocked for security reasons. There is no option of turning on UDP broadcasting.
The solution presented here is to move the broadcasting responsibility from the network component to the application component: In our case, the service that is sending the data. Broadcasting can be simulated by providing the sending service with the IP addresses of the relevant pods that use the headless service.
The solution looks like this:
- In the Kubernetes/OpenShift cluster, you set up a headless service with a selector pointing to all the subscribed services.
- Before sending the message, the sending service queries the headless service to get the pods' IP addresses.
- The service sends the message to all the IP addresses. The broadcast uses UDP protocol-based messaging, so no response or acknowledgment is returned to the server.
- Optionally, subscribed services can send their responses to a third service that writes the messages to a database (Figure 2). This step is important for stateful services. Using the third service prevents multiple database writes for the same state.

When to use this solution
The solution in this article should be used only when the following conditions are true:
- The application can send out the same message multiple times, to improve chances of delivery in case the UDP-based messaging service drops a message. Messages are probably assigned numbers or other markers so that receivers can recognize and discard duplicates.
- The microservices architecture is idempotent. All the pods processing the message at any given time should return the same result.
Resources
Try out this broadcast solution using demo apps and YAML resources for deployment that I have put in my GitHub repository.
Last updated: September 20, 2023