Dual writes frequently cause issues in distributed, event-driven applications. A dual write occurs when an application has to change data in two different systems, such as when an application needs to persist data in the database and send a Kafka message to notify other systems. If one of these two operations fails, you might end up with inconsistent data. Dual writes can be hard to detect and fix.
In this article, you will learn how to use the outbox pattern with Red Hat OpenShift Streams for Apache Kafka and Debezium to avoid the dual write problem in event-driven applications. I will show you how to:
- Provision a Kafka cluster on OpenShift Streams for Apache Kafka.
- Deploy and configure Debezium to use OpenShift Streams for Apache Kafka.
- Run an application that uses Debezium and OpenShift Streams for Apache Kafka to implement the outbox pattern.
OpenShift Streams for Apache Kafka is an Apache Kafka service that is fully hosted and managed by Red Hat. The service is useful for developers who want to incorporate streaming data and scalable messaging in their applications without the burden of setting up and maintaining a Kafka cluster infrastructure.
Debezium is an open source, distributed platform for change data capture. Built on top of Apache Kafka, Debezium allows applications to react to inserts, updates, and deletes in your databases.
Demo: Dual writes in an event-driven system
The demo application we'll use in this article is part of a distributed, event-driven order management system. The application suffers from the dual write issue: When a new order comes in through a REST interface, the order is persisted in the database—in this case PostgreSQL—and an OrderCreated event is sent to a Kafka topic. From there, it can be consumed by other parts of the system.
You will find the code for the order service application in this Github repository. The application was developed using Quarkus. The structure of the OrderCreated events follows the CloudEvents specification, which defines a common way to describe event data.
Solving dual writes with the outbox pattern
Figure 1 shows the architecture of the outbox pattern implemented with Debezium and OpenShift Streams for Apache Kafka. For this example, you will also use Docker to spin up the different application components on your local system.
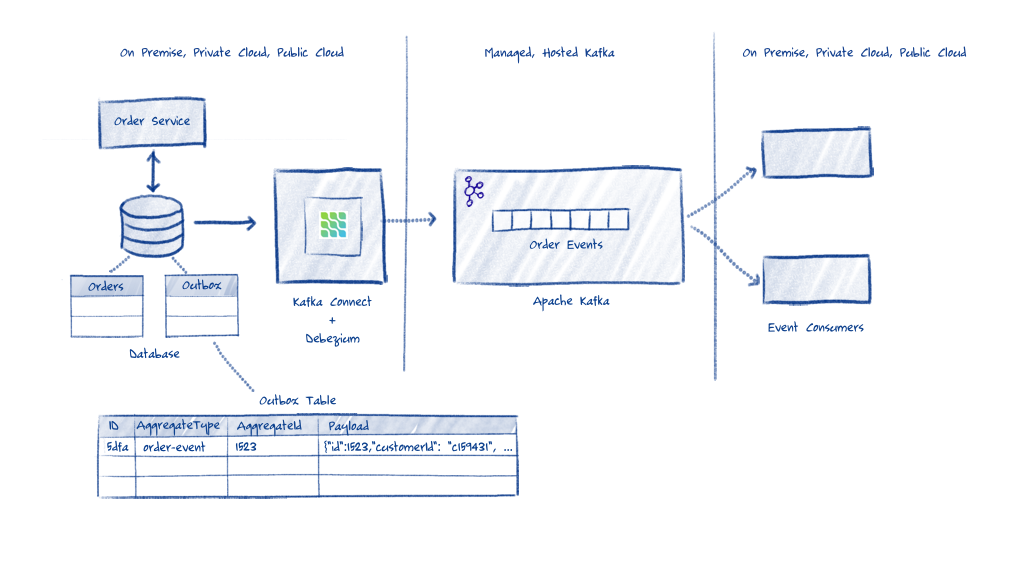
Note: For a thorough discussion of Debezium and the outbox pattern see Reliable Microservices Data Exchange With the Outbox Pattern.
Prerequisites for the demonstration
This article assumes that you already have an OpenShift Streams for Apache Kafka instance in your development environment. Visit the Red Hat OpenShift Streams for Apache Kafka page to create a Kafka instance. See the article Getting started with Red Hat OpenShift Streams for Apache Kafka for the basics of creating Kafka instances, topics, and service accounts.
I also assume that you have Docker installed on your local system.
Provision a Kafka cluster with OpenShift Streams for Apache Kafka
After you set up an OpenShift Streams for Apache Kafka instance, you will create environment variables for the Kafka bootstrap server endpoint and the service account credentials. Use the following environment variables when configuring the application:
$ export KAFKA_BOOTSTRAP_SERVER=<value of the Bootstrap server endpoint>
$ export CLIENT_ID=<value of the service account Client ID>
$ export CLIENT_SECRET=<value of the service account Client Secret>
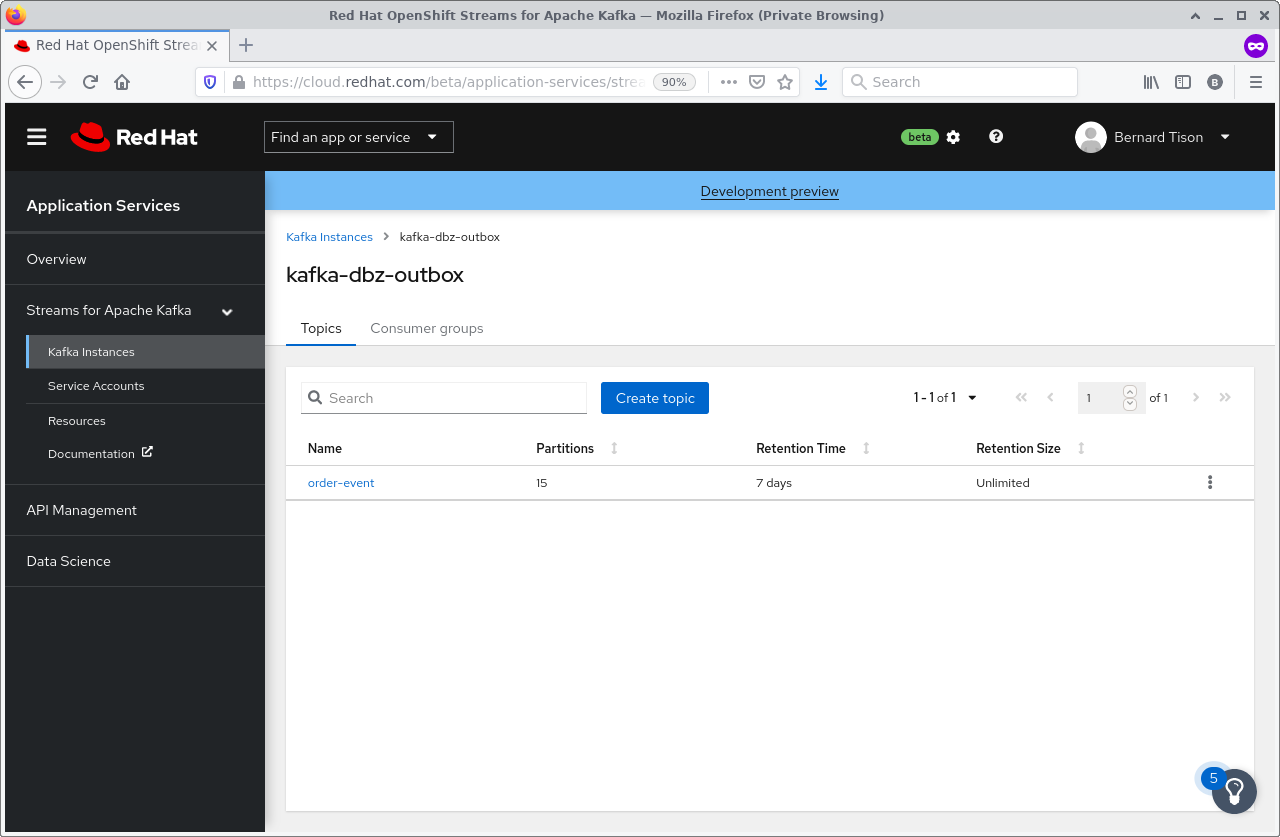
Create a topic named order-event on your Kafka instance for the user service application, as shown in Figure 2. The number of partitions is not critical for this example. I generally use 15 partitions for Kafka topics as a default. You can leave the message retention time at seven days.
Persisting the order service
The order service application exposes a REST endpoint for new orders. When a new order is received, the order is persisted using JPA in the orders table of the PostgreSQL database. In the same transaction, the outbox event for the OrderCreated message is written to the orders_outbox table. See this Github repo for the application source code. The OrderService class contains the code for persisting the order entity and the OrderCreated message:
@ApplicationScoped
public class OrderService {
@Inject
EntityManager entityManager;
@ConfigProperty(name = "order-event.aggregate.type", defaultValue = "order-event")
String aggregateType;
@Transactional
public Long create(Order order) {
order.setStatus(OrderStatus.CREATED);
entityManager.persist(order);
OutboxEvent outboxEvent = buildOutBoxEvent(order);
entityManager.persist(outboxEvent);
entityManager.remove(outboxEvent);
return order.getId();
}
OutboxEvent buildOutBoxEvent(Order order) {
OutboxEvent outboxEvent = new OutboxEvent();
outboxEvent.setAggregateType(aggregateType);
outboxEvent.setAggregateId(Long.toString(order.getId()));
outboxEvent.setContentType("application/cloudevents+json; charset=UTF-8");
outboxEvent.setPayload(toCloudEvent(order));
return outboxEvent;
}
String toCloudEvent(Order order) {
CloudEvent event = CloudEventBuilder.v1().withType("OrderCreatedEvent")
.withTime(OffsetDateTime.now())
.withSource(URI.create("ecommerce/order-service"))
.withDataContentType("application/json")
.withId(UUID.randomUUID().toString())
.withData(order.toJson().encode().getBytes())
.build();
EventFormat format = EventFormatProvider.getInstance()
.resolveFormat(JsonFormat.CONTENT_TYPE);
return new String(format.serialize(event));
}
}
Notice the following:
- The structure of the
OrderCreatedmessage follows the CloudEvents specification. The code uses the Java SDK for CloudEvents API to build the CloudEvent and serialize it to JSON format. - The
ContentTypefield of theOutboxEvententity is set toapplication/cloudevents+json. When processed by a Debezium single message transformation (SMT), this value is set as thecontent-typeheader on the Kafka message, as mandated by the CloudEvents specification.
I'll discuss the structure of the Outbox Event table shortly. The OutboxEvent entity is persisted to the database and then removed right away. Debezium, being log-based, does not examine the contents of the database table; it just tails the append-only transaction log. The code will generate an INSERT and a DELETE entry in the log when the transaction commits. Debezium processes both events, and produces a Kafka message for any INSERT. However, DELETE events are ignored.
The net result is that Debezium is able to capture the event added to the outbox table, but the table itself remains empty. No additional disk space is needed for the table and no separate housekeeping process is required to stop it from growing indefinitely.
Running the PostgreSQL database
Run the PostgreSQL database as a Docker container. The database and the orders and orders_outbox tables are created when the container starts up:
$ docker run -d --name postgresql \
-e POSTGRESQL_USER=orders -e POSTGRESQL_PASSWORD=orders \
-e POSTGRESQL_ADMIN_PASSWORD=admin -e POSTGRESQL_DATABASE=orders \
quay.io/btison_rhosak/postgresql-order-service
Then, spin up the container for the order service:
$ docker run -d --name order-service -p 8080:8080 \
--link postgresql -e DATABASE_USER=orders \
-e DATABASE_PASSWORD=orders -e DATABASE_NAME=orders \
-e DATABASE_HOST=postgresql -e ORDER_EVENT_AGGREGATE_TYPE=order-event \
quay.io/btison_rhosak/order-service-outbox
Configure and run Debezium
Debezium is implemented as a Kafka Connect connector, so the first thing to do is to spin up a Kafka Connect container, pointing to the managed Kafka instance.
The Kafka Connect image we use here is derived from the Kafka Connect image provided by the Strimzi project. The Debezium libraries and the Debezium PostgreSQL connector are already installed on this image.
Kafka Connect is configured using a properties file, which specifies among other things how Kafka Connect should connect to the Kafka broker.
To connect to the managed Kafka instance, this application employs SASL/PLAIN authentication over TLS, using the client ID and secret from the service account you created earlier as credentials.
Creating a configuration file
Create a configuration file on your local file system. The file refers to environment variables for the Kafka bootstrap address and the service account credentials:
$ cat << EOF > /tmp/kafka-connect.properties
# Bootstrap servers
bootstrap.servers=$KAFKA_BOOTSTRAP_SERVER
# REST Listeners
rest.port=8083
# Plugins
plugin.path=/opt/kafka/plugins
# Provided configuration
offset.storage.topic=kafka-connect-offsets
value.converter=org.apache.kafka.connect.json.JsonConverter
config.storage.topic=kafka-connect-configs
key.converter=org.apache.kafka.connect.json.JsonConverter
group.id=kafka-connect
status.storage.topic=kafka-connect-status
config.storage.replication.factor=3
key.converter.schemas.enable=false
offset.storage.replication.factor=3
status.storage.replication.factor=3
value.converter.schemas.enable=false
security.protocol=SASL_SSL
producer.security.protocol=SASL_SSL
consumer.security.protocol=SASL_SSL
admin.security.protocol=SASL_SSL
sasl.mechanism=PLAIN
producer.sasl.mechanism=PLAIN
consumer.sasl.mechanism=PLAIN
admin.sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$CLIENT_ID" \
password="$CLIENT_SECRET" ;
producer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$CLIENT_ID" \
password="$CLIENT_SECRET" ;
consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$CLIENT_ID" \
password="$CLIENT_SECRET" ;
admin.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$CLIENT_ID" \
password="$CLIENT_SECRET" ;
EOF
Launching the Kafka Connect container
Next, you will launch the Kafka Connect container. The properties file you just created is mounted into the container. The container is also linked to the PostgreSQL container, so that the Debezium connector can connect to PostgreSQL to access the transaction logs:
$ docker run -d --name kafka-connect --link postgresql -p 8083:8083 \
--mount type=bind,source=/tmp/kafka-connect.properties,destination=/config/kafka-connect.properties \
quay.io/btison_rhosak/kafka-connect-dbz-pgsql:1.7.0-1.5.0.Final
Now check the Kafka Connect container logs. Kafka Connect logs are quite verbose, so if you don’t see any stack traces, you can assume Kafka Connect is running fine and successfully connected to the Kafka cluster.
Configuring the Debezium connector
Kafka Connect exposes a REST endpoint through which you can deploy and manage Kafka Connect connectors, such as the Debezium connector. Create a file on your local file system for the Debezium connector configuration:
$ cat << EOF > /tmp/debezium-connector.json
{
"name": "debezium-postgres-orders",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "postgresql",
"database.port": "5432",
"database.user": "postgres",
"database.password": "admin",
"database.dbname": "orders",
"database.server.name": "orders1",
"schema.whitelist": "public",
"table.whitelist": "public.orders_outbox",
"tombstones.on.delete" : "false",
"transforms": "router",
"transforms.router.type": "io.debezium.transforms.outbox.EventRouter",
"transforms.router.table.fields.additional.placement": "content_type:header:content-type",
"transforms.router.route.topic.replacement": "\${routedByValue}"
}
}
EOF
Let's look more closely at some of the fields in this configuration:
- plugin-name: The Debezium connector uses a PostgreSQL output plug-in to extract changes committed to the transaction log. In this case, we use the
pgoutputplug-in, which is included in PostgreSQL since version 10. See the Debezium documentation for information about output plug-ins. - database.*: These settings allow Debezium to connect to the PostgreSQL database. This example specifies the
postgressystem user, which has superuser privileges. In a production system, you should probably create a dedicated Debezium user with the necessary privileges. - table.whitelist: This specifies the list of tables that are monitored for changes by the Debezium Connector.
- tombstones.on.delete: This indicates whether a deletion marker ("tombstones") should be emitted by the connector when a record is deleted from the outbox table. By setting
tombstones.on.deleteto false, you tell Debezium to effectively ignore deletes. - transforms.*: These settings describe how Debezium should process database change events. Debezium applies a single message transform (SMT) to every captured change event. For the outbox pattern, Debezium uses the built-in
EventRouterSMT, which extracts the new state of the change event, transforms it into a Kafka message, and sends it to the appropriate topic.
More about the EventRouter
The EventRouter by default makes certain assumptions about the structure of the outbox table:
Column | Type | Modifiers
--------------+------------------------+-----------
id | uuid | not null
aggregatetype | character varying(255) | not null
aggregateid | character varying(255) | not null
payload | text | not null
content_type | character varying(255) | not null
The EventRouter calculates the value of the destination topic from the aggregatetype column and the value of the route.topic.replacement configuration (where ${routedBy} represents the value in the aggregatetype column). The key of the Kafka message is the value of the aggregateid column, and the payload is whatever is in the payload column. The table.fields.additional.placement parameter defines how additional columns should be handled. In our case, we specify that the value of the content_type column should be added to the Kafka message as a header with key content-type.
Deploying the Debezium connector
Deploy the Debezium connector by calling the Kafka Connect REST endpoint:
$ curl -X POST -H "Accept: application/json" -H "Content-type: application/json" \
-d @/tmp/debezium-connector.json 'http://localhost:8083/connectors'
You can check the logs of the kafka-connect container to verify that the Debezium connector was installed successfully. If you were successful, you’ll see something like the following toward the end of the logs:
2021-06-09 21:09:46,944 INFO user 'postgres' connected to database 'orders' on PostgreSQL 12.5 on x86_64-redhat-linux-gnu, compiled
by gcc (GCC) 8.3.1 20191121 (Red Hat 8.3.1-5), 64-bit with roles:
role 'pg_read_all_settings' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can log in: false]
role 'pg_stat_scan_tables' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can log in: false]
role 'pg_write_server_files' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can log in: false]
role 'pg_monitor' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can log in: false]
role 'pg_read_server_files' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can log in: false]
role 'orders' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can log in: true]
role 'pg_execute_server_program' [superuser: false, replication: false, inherit: true, create role: false, create db: false,can log in: false]
role 'pg_read_all_stats' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can login: false]
role 'pg_signal_backend' [superuser: false, replication: false, inherit: true, create role: false, create db: false, can login: false]
role 'postgres' [superuser: true, replication: true, inherit: true, create role: true, create db: true, can log in: true] (io.debezium.connector.postgresql.PostgresConnectorTask) [task-thread-debezium-postgres-orders-0]
Consume the Kafka messages
Next, you want to view the Kafka messages produced by Debezium and sent to the order-event topic. You can use a tool such as kafkacat to process the messages. The following docker command launches a container hosting the kafkacat utility and consumes all the messages in the order-event topic from the beginning:
$ docker run -it --rm edenhill/kafkacat:1.6.0 kafkacat \
-b $KAFKA_BOOTSTRAP_SERVER -t order-event \
-X security.protocol=SASL_SSL -X sasl.mechanisms=PLAIN \
-X sasl.username="$CLIENT_ID" -X sasl.password="$CLIENT_SECRET" \
-f 'Partition: %p\n Key: %k\n Headers: %h\n Payload: %s\n' -C
Test the application
All components are in place to test the order service application. To use the REST interface to create an order, issue the following cURL command:
$ curl -v -X POST -H "Content-type: application/json" \
-d '{"customerId": "customer123", "productCode": "XXX-YYY", "quantity": 3, "price": 159.99}' \
http://localhost:8080/order
Verify with kafkacat that a Kafka message has been produced to the order-event topic. When you issue the kafkacat command mentioned earlier, the output should look like this:
Partition: 3
Key: "992"
Headers: id=743e3736-f9e3-4c2f-bce7-eaa35afe8876,content-type=application/cloudevents+json; charset=UTF-8
Payload: "{\"specversion\":\"1.0\",\"id\":\"843d8770-f23d-41e2-a697-a64367f1d387\",\"source\":\"ecommerce/order-service\",\"type\":\"OrderCreatedEvent\",\"datacontenttype\":\"application/json\",\"time\":\"2021-06-10T07:40:52.282602Z\",\"data\":{\"id\":992,\"customerId\":\"customer123\",\"productCode\":\"XXX-YYY\",\"quantity\":3,\"price\":159.99,\"status\":\"CREATED\"}}"
% Reached end of topic order-event [3] at offset 1
Note that the ID of the outbox event is added as a header to the message. This information can be exploited by consumers for duplicate detection. The content-type header is added by the Debezium EventRouter.
Conclusion
Great job! If you’ve followed along, you have successfully:
- Provisioned a managed Kafka instance on cloud.redhat.com.
- Used Kafka Connect and Debezium to connect to the managed Kafka instance.
- Implemented and tested the outbox pattern with Debezium.
Setting up and maintaining a Kafka cluster can be tedious and complex. OpenShift Streams for Apache Kafka takes away that burden, allowing you to focus on implementing services and business logic.
Applications can connect to the managed Kafka instance from everywhere, so it doesn’t really matter where these applications run, whether it's on a private or public cloud, or even in Docker containers on your local workstation.
Stay tuned for more articles on interesting use cases and demos with OpenShift Streams for Apache Kafka.
Last updated: March 18, 2024