Apache Camel is used widely for message queue integration and notification. Its lightweight and simple coding structure makes it a good choice for developers. Camel is well suited for application modernization and integrates very well with Kubernetes and Red Hat OpenShift. You can use these technologies together for a continuous integration and continuous delivery (CI/CD) pipeline and deployment.
In this article, we'll introduce the elements of application modernization, give an overview of Camel's components and architecture, and demonstrate how to use Camel with JavaScript to deploy your applications to OpenShift. We'll go through a few application modernization examples and look at the performance gains from using Camel with OpenShift and JavaScript. We'll also introduce Camel K, a lightweight integration framework built from Apache Camel that is specifically designed for serverless and microservices architectures.
Modernizing legacy applications
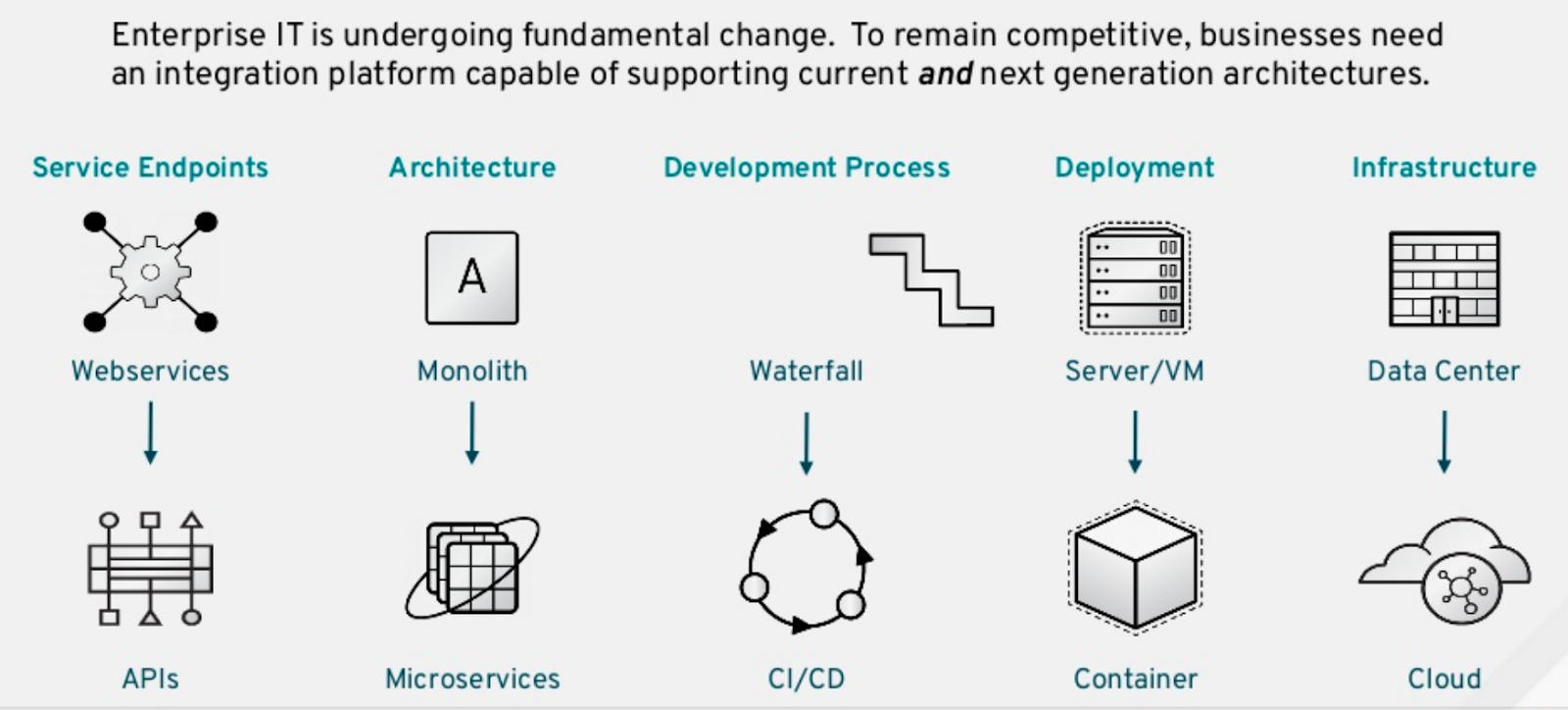
Application modernization usually consists of five parts, as shown in Figure 1:
- Service endpoint modernization involves migrating web services to a web API so that you can use tools like Red Hat 3scale API Management to manage API usage, subscriptions, pricing, and availability.
- Architecture modernization requires breaking down legacy monolithic systems into multiple standalone microservices. Each microservice should be a standalone CRUD (create, read, update, and delete) operation that follows the SOLID principles.
- Development modernization involves changing from a waterfall delivery model to a CI/CD delivery model. As soon as code is committed to the Git repository, the CI/CD pipeline kicks off the build and deployment process. New code changes are deployed to production as soon as they pass the validation tests and checkpoints.
- Deployment modernization requires moving from on-premise physical servers or virtual machines to a containerized architecture in the cloud.
- Infrastructure modernization involves moving infrastructure from physical data centers to the cloud.
Often, it is hard to carve out a piece of the application to modernize because you need to identify the external and internal dependencies that must be modernized at the same time. Everything in a legacy system is a big dependency tree, as illustrated in Figure 2.
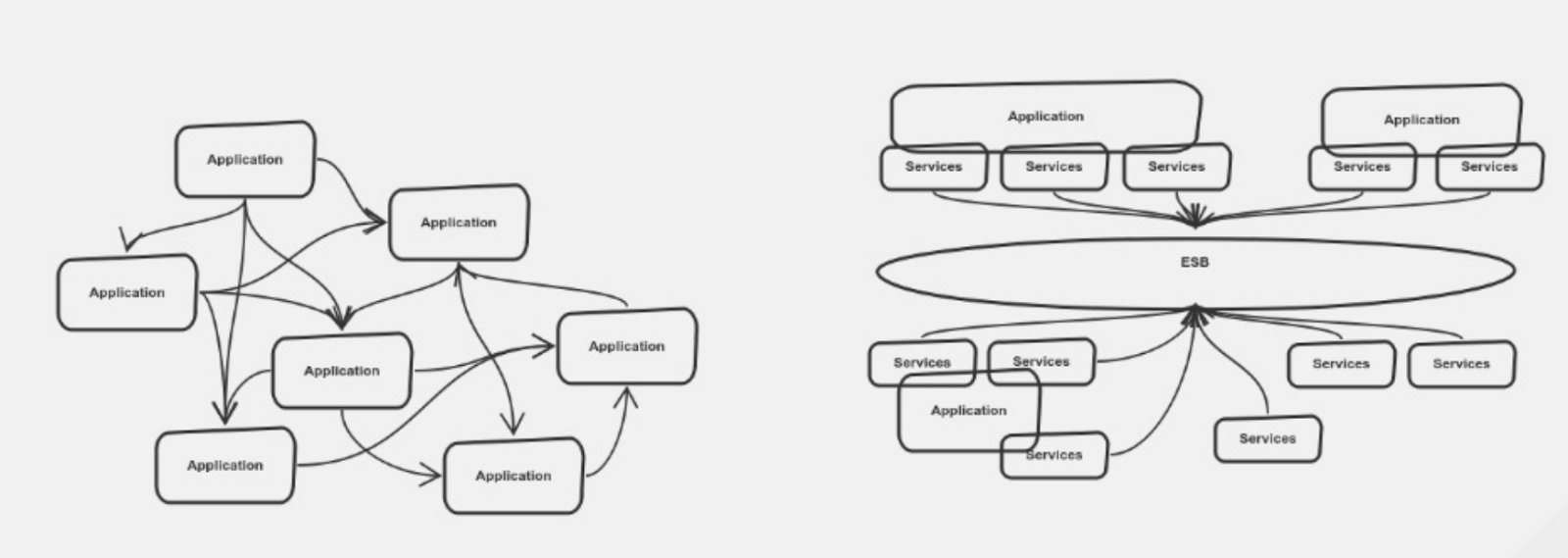
It helps to break down the dependencies into multiple smaller clusters, instead of managing one giant cluster. This lets you modernize while maintaining low risk.
Application modernization with Apache Camel
Apache Camel is an upstream project that we use for integration technology at Red Hat. It is an open source Java framework that started as an implementation of the book Enterprise Integration Patterns. Camel comes with 300 components that you can use out of the box. Integrations range from simple timer-to-log dummy examples to complex processing workflows that connect several external systems.
The Camel framework provides the following benefits:
- Enterprise integration patterns that build integrations using enterprise best practices.
- 300 components for batch, messaging, web services, cloud, and APIs.
- Built-in data transformation for JSON, XML, YAML, SOAP, Java, and CSV.
- Intuitive routing to develop integrations quickly in Java and XML.
- Native REST support to create, connect, and compose APIs.
As developers, we know that the more applications are deconstructed into smaller pieces, the more we need communication patterns to manage the inherent complexity. Camel has been shaped around enterprise integration patterns (EIPs) since its inception, and it uses a domain-specific language (DSL) to map patterns in a one-to-one relationship. Let's look at Camel's components more closely.
Integration patterns
Camel integration patterns are agnostic of programming language, platform, and architecture. They provide a universal language, notation, and fundamental messaging as well as integration. Camel continues to evolve and add new patterns from the service-oriented architecture, microservices, cloud-native, and serverless paradigms. It has become a general pattern-based integration framework suitable for multiple architectures.
It's not an exaggeration to say that the Camel DSL is now the language of EIPs. It is the language that best expresses the patterns that were present in the original “book of integration.” Additionally, the community continues to add new patterns and components with every release.
Figure 3 shows various enterprise integration patterns, including the Content-Based Router, Message Filter, Dynamic Router, Recipient List, Splitter, Aggregator, Resequencer, Content Enricher, Content Filter, and Pipes and Filters.

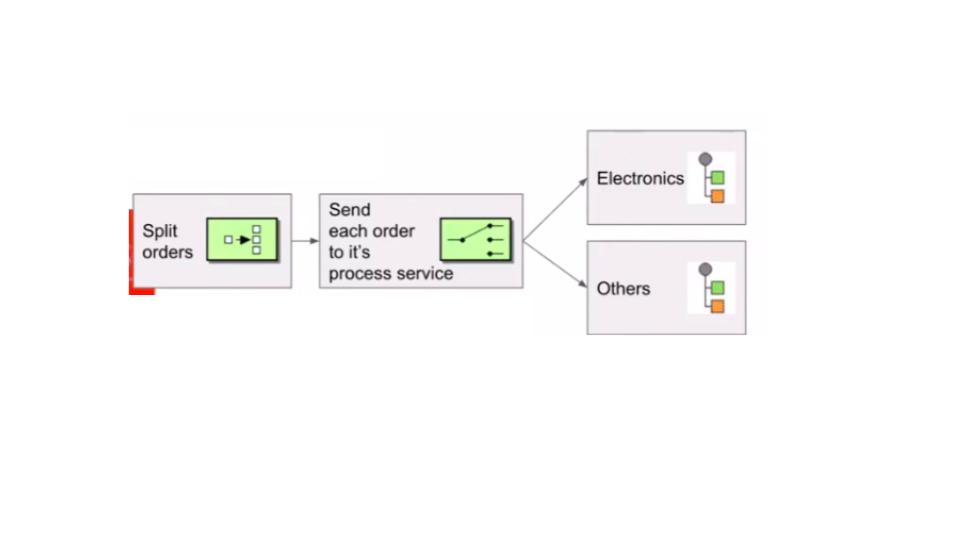
In the example shown in Figure 4, the pattern splits the order from a larger order and sends each item to electronics or other areas to be fulfilled.
Domain-specific languages
Camel has multiple DSLs. It supports XML, Java, Groovy, Kotlin, and other Java components. There are good reasons to use both Java and XML-based DSLs. A Camel route expresses the EIPs. It gets developers thinking in terms of pipes and filters. The DSL that you use is a technicality that will not impact the success of the project. You can even mix and match DSLs.
Connectors
In addition to implementing enterprise integration patterns with DSLs, Apache Camel is a powerful integration library that provides many integration connectors. Hundreds of Java libraries can use Camel connectors with the Camel endpoint notation. These uniform resource identifiers (URIs) are universal. For a list of supported components, see the Camel documentation.
A sample JMS integration
Integrations are great for connecting systems and transforming data, as well as creating new microservices. Let's look at a simple one-to-one integration between a file and a Java Message Service (JMS) queue. At runtime, the DSL does not matter for Camel.
The following is an example of a Java DSL Camel route:
from("file:data/inbox")
.to("jms:queue:order");
Here is an XML DSL Camel route for the same integration:
<route>
<from uri="file:data/inbox"/>
<to uri="jms:queue:order"/>
</route>
Figure 5 shows a Camel program that picks up a file from a location, splits the file by line, converts the line content into an XML definition, and puts the XML objects into an active messaging queue.
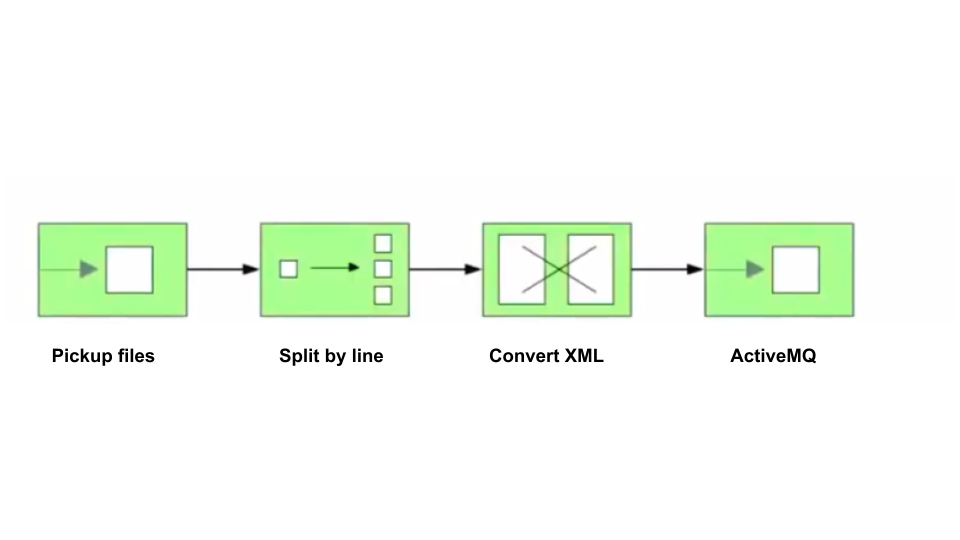
Here is the corresponding JavaScript code for the program in Figure 5:
from("file:inbox")
.split(body().tokenize("\n"))
.marshal(customToXml)
.to("activemq:queue:line");
Apache Camel offers a REST-style DSL that you can use with Java or XML. This lets users define services using REST verbs such as GET, POST, DELETE, and so on. The REST DSL supports the XML DSL using either Spring or Blueprint.
To define a path, you can set the base path in REST and then provide the URI template with the verbs, as shown in the following example. The REST DSL also accepts a data format setting:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<rest path="/say">
<get uri="/hello">
<to uri="direct:hello"/>
</get>
<get uri="/bye" consumes="application/json">
<to uri="direct:bye"/>
</get>
<post uri="/bye">
<to uri="mock:update"/>
</post>
</rest>
<route>
<from uri="direct:hello"/>
</route>
<route>
<from uri="direct:bye"/>
</route>
</camelContext>
This Camel DSL example contains the following attributes:
- Base path: The service path (
/say). - Verb: The defining HTTP method.
consumes: The acceptable data format setting- URI template: The service method and parameters for the HTTP calls.
A JavaScript integration example
In the following example, we create a predicate in a message filter using the JavaScript function. The message filter is an EIP that allows you to filter the messages. For example, if the predicate is true, the message will be routed from queue A to queue B. This path routes exchanges from admin users to a special queue. We could also write the path using a Spring DSL:
from("direct:start")
.choice()
.when().javaScript("request.headers.get('user') == 'admin'")
.to("seda:adminQueue")
.otherwise()
.to("seda:regularQueue")
Here is the same content in the XML DSL:
<route>
<from uri="direct:start"/>
<choice>
<when>
<javaScript>request.headers.get('user') == 'admin'</javaScript>
<to uri="seda:adminQueue"/>
</when>
<otherwise>
<to uri="sdea:regularQueue"/>
</otherwise>
</choice>
</route>
An integration written in JavaScript is very similar to one written in Java. The Camel program listens to the system timer, where each second is displayed as a timer tick. For each second, the Camel program will process the function that prints Hello Camel K! and log the results to the log info section. (We'll talk more about Camel K later in this article.)
const Processor = Java.extend(Java.type("org.apache.camel.Processor"));
function proc(e) {
e.getIn().setBody('Hello Camel K!');
}
from('timer:tick')
.process(new Processor(proc))
.to('log:info')
To run it, execute kamel run followed by the file name:
$ kamel run hello.js
Global bound objects
The Camel K framework does not yet provide an enhanced DSL for JavaScript integrations, but you can access global bound objects such as a writable registry. In the following example, we've taken the context.getComponent from the previous log component that printed Hello Camel K! and used the exchangeFormatter property to modify the log format:
1 = context.getComponent('log', true, false)
1.exchangeFormatter = function(e) {
return "log = body=" + e.in.body + ", headers=" + e.in.headers
}
Using scripting languages with Camel
The Java specification request JSR-223 lets you use scripting languages like Ruby, Groovy, and Python on the Java platform. Camel supports many scripting languages that are used to create an expression or predicate via JSR-223, which is a standard part of Java. This is useful when you need to invoke logic that is in another language, such as JavaScript or Groovy.
JSR-223's ScriptContext is preconfigured with the attributes listed in Table 1.
| Attribute | Type | Value |
context |
org.apache.camel.CamelContext |
The Camel context. |
exchange |
org.apache.camel.Exchange |
The current exchange. |
request |
org.apache.camel.Message |
The message (IN message). |
response |
org.apache.camel.Message |
The OUT message; if null, use IN message instead. |
properties |
org.apache.camel.builder.script |
Function with a resolve method to make it easier to use Camel properties from scripts. |
You can use the properties component from a script to look up property placeholders. In the following example, we set a header name, myHeader, with a value from a property placeholder; the property key is provided in the header named foo.
.setHeader("myHeader").groovy("properties.resolve(request.headers.get('foo'))")
You can also refer to an external script file by having Camel load it from a resource such as classpath:, file:, or http:. We use the resource:schema:location syntax, which takes a file on the classpath. To load a Groovy script from the classpath, you need to prefix the value with a resource, as shown here:
.setHeader("myHeader").groovy("resource:classpath:mygroovy.groovy")
To use scripting languages in your Camel routes, you need to add a dependency on camel-script to integrate the JSR-223 scripting engine. If you use Maven, you can simply add the following to your pom.xml, substituting the version number for the latest release (see the Maven download page):
<dependency>
<groupId>org.apache.camel.</groupId>
<artifactId>camel-script</artifactId>
<version>x.x.x</version>
</dependency>
Apache Camel K
So, with the introduction of Camel and how Camel supports JavaScript, let’s talk about Camel K. Camel K is a deep Kubernetes integration for Camel that runs natively in the cloud on Red Hat OpenShift. It is designed for serverless and microservice architectures. Camel K lets you build a lightweight runtime for running integration code directly on cloud platforms like Kubernetes and OpenShift.
Camel K is serverless Camel for Kubernetes and Knative. It runs on top of Quarkus and enables developers to write small, fast Java applications.
To run Camel K, you will need access to a Kubernetes or OpenShift environment. Before creating any applications, log into the cluster, create a project, and install the Camel K Operator. Camel K works best when it is run natively on Knative. It is a simple prebuilt component to pub/sub from the event mesh.
The Camel K runtime provides significant performance optimizations without using Knative and serverless technologies. Compared to binary Source-to-Image, Camel K has lower deploy and redeploy time. If the binary runs remotely, it is even slower. By contrast, the redeploy with the Camel K is almost instantaneous.
How to deploy Camel K integrations with Red Hat OpenShift
So, how does Camel K work? Developers just want to deal with business logic and not worry about runtimes. We want to use Camel K to integrate with different systems and leverage the serverless architecture. What we can do is to write Camel routes in a single file. In the next example, we use a Camel route written in XML. At this point, with Camel K, you only have an integration file. This is a Camel integration file that looks up every second from the Google domain and logs the output:
from('timer:dns?period=1s')
.routeId('dns')
.setHeader('dns.domain')
.constant('www.google.com')
.to('dns:ip')
.log('log:dns');
Camel K comes with a command-line tool, kamel, that we can use to automate tasks such as observing code changes, streaming them to the Kubernetes cluster, and printing the logos from the running pods. Once you've prepared the cluster and installed the operator in the current namespace, you can use the kamel run command as shown here:
$ kamel run integration.groovy
Then, check the pods running in the cluster on the OpenShift console. (You can do this with the OpenShift CLI tool, as well.) Once it's logged with the OpenShift cluster, kamel will use it to run the integration on the OpenShift cluster in this project and deploy it from there. The process is shown in Figure 6.
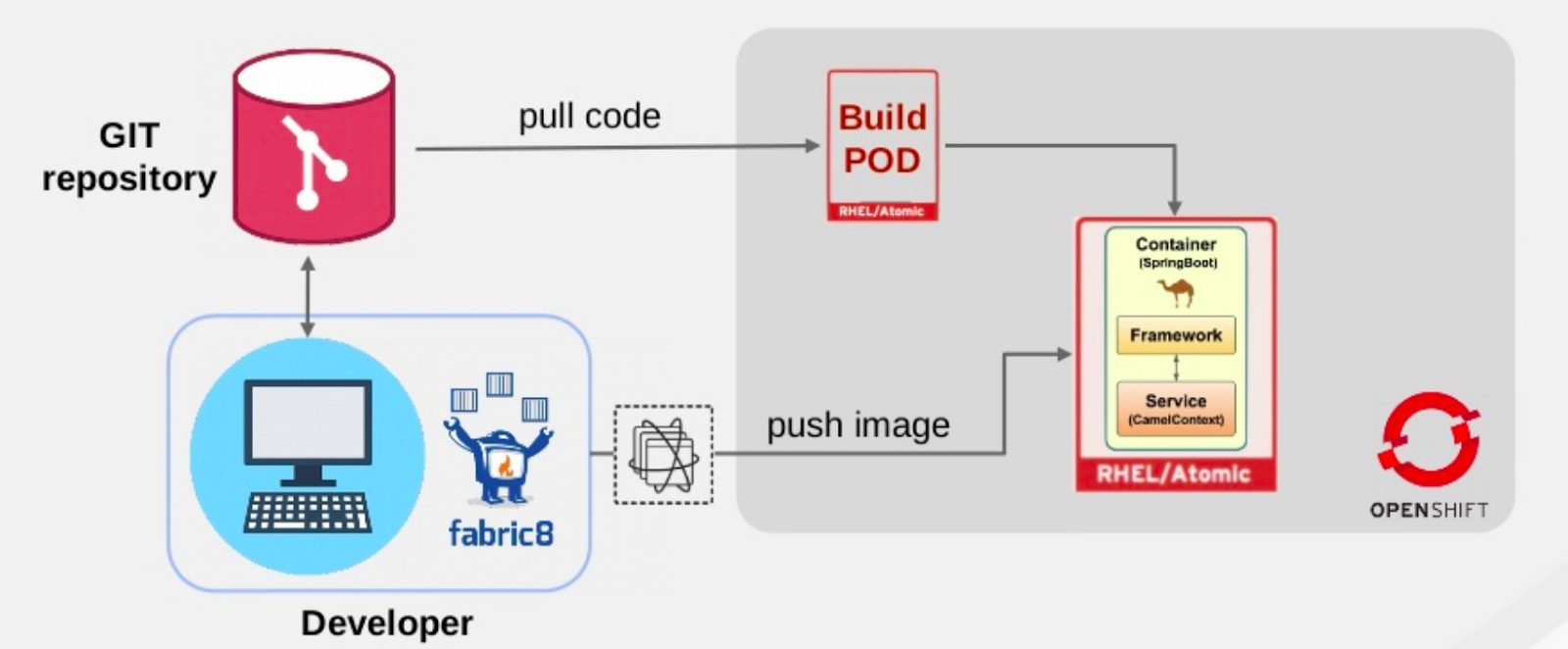
In OpenShift, the ConfigMap object injects application properties into the Camel application. Each Camel application is deployed in a different pod, as shown in Figure 7. You can manage multiple Camel applications across different pods using the same ConfigMap.
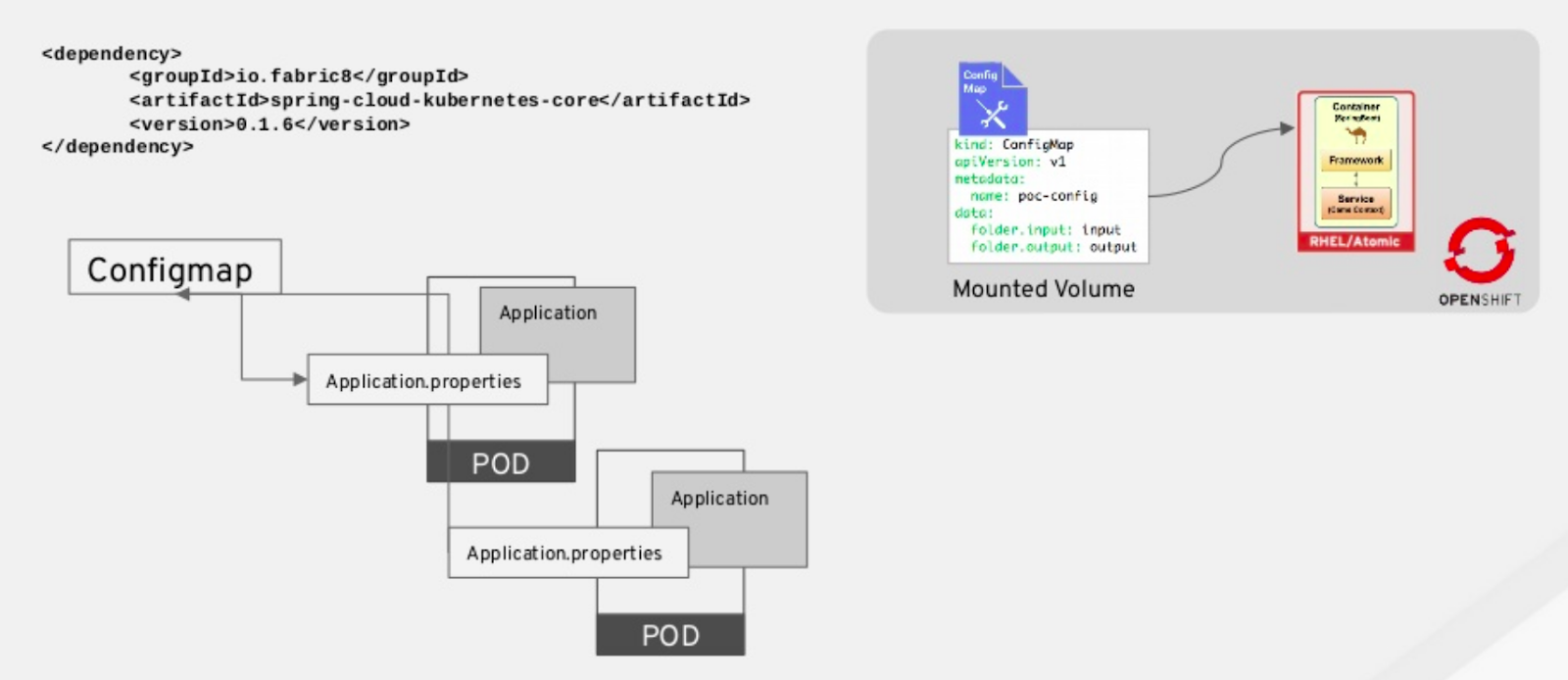
ConfigMap.Conclusion
We started this article by reviewing the elements of application modernization, then discussed how using Camel and JavaScript solves some of the challenges of modernization. We also discussed integrating Camel with OpenShift.
We then looked at Camel K and its kamel CLI command tool. Camel K adds components for deploying, running, and managing serverless, cloud-native applications to Red Hat OpenShift. The serverless cloud computing model leads to increased developer productivity, reliable cloud deployments, and reduced operational costs. Together, OpenShift and Camel K provide a fast and scalable solution for application modernization, which integrates with different technologies to provide reliable results.