In this part of our ongoing introduction to the Node.js reference architecture, we dig into some of the discussions the team had when developing the GraphQL section of the reference architecture. Learn about the principles we considered and gain additional insight into how we developed the current recommendations for using GraphQL in your Node.js applications.
Read the whole series:
- Part 1: Overview of the Node.js reference architecture
- Part 2: Logging in Node.js
- Part 3: Code consistency in Node.js
- Part 4: GraphQL in Node.js
- Part 5: Building good containers
- Part 6: Choosing web frameworks
- Part 7: Code coverage
- Part 8: Typescript
- Part 9: Securing Node.js applications
- Part 10: Accessibility
- Part 11: Typical development workflows
- Part 12: npm development
- Part 13: Problem determination
- Part 14: Testing
- Part 15: Transaction handling
- Part 16: Load balancing, threading, and scaling
- Part 17: CI/CD best practices in Node.js
- Part 18: Wrapping up
GraphQL in the Node.js ecosystem
GraphQL is a query language specification that includes specific semantics for interaction between the client and server. Implementing a GraphQL server and client typically requires more effort than building REST applications, due to the extensive nature of the language and additional requirements for client-side and server-side developers. To start, let's consider a few of the elements of developing a Node.js application with GraphQL (Figure 1).

Developing a GraphQL schema
When building a GraphQL API, client- and server-side teams must define strong contracts in the form of a GraphQL schema. The two teams must also change the way they have been communicating and developing their software. GraphQL internally requires server-side developers to build data-handling methods, called resolvers, that match the GraphQL schema, which is an internal graph that both teams must build and agree on. Client-side developers typically need to use specialized clients to send GraphQL queries to the back-end server.
Choosing your tools
The GraphQL ecosystem consists of thousands of libraries and solutions that you can find on GitHub, at conferences, and in various forums that offer to resolve all your GraphQL problems. On top of frameworks and libraries (Figure 2) the GraphQL ecosystem offers many out-of-the-box, self-hosted, or even service-based (SaaS) CRUD engines. Create, read, update, and delete (CRUD) engines offer to minimize the amount of server-side development by providing a direct link to the database. We'll come back to this topic later.
Implementing a GraphQL API
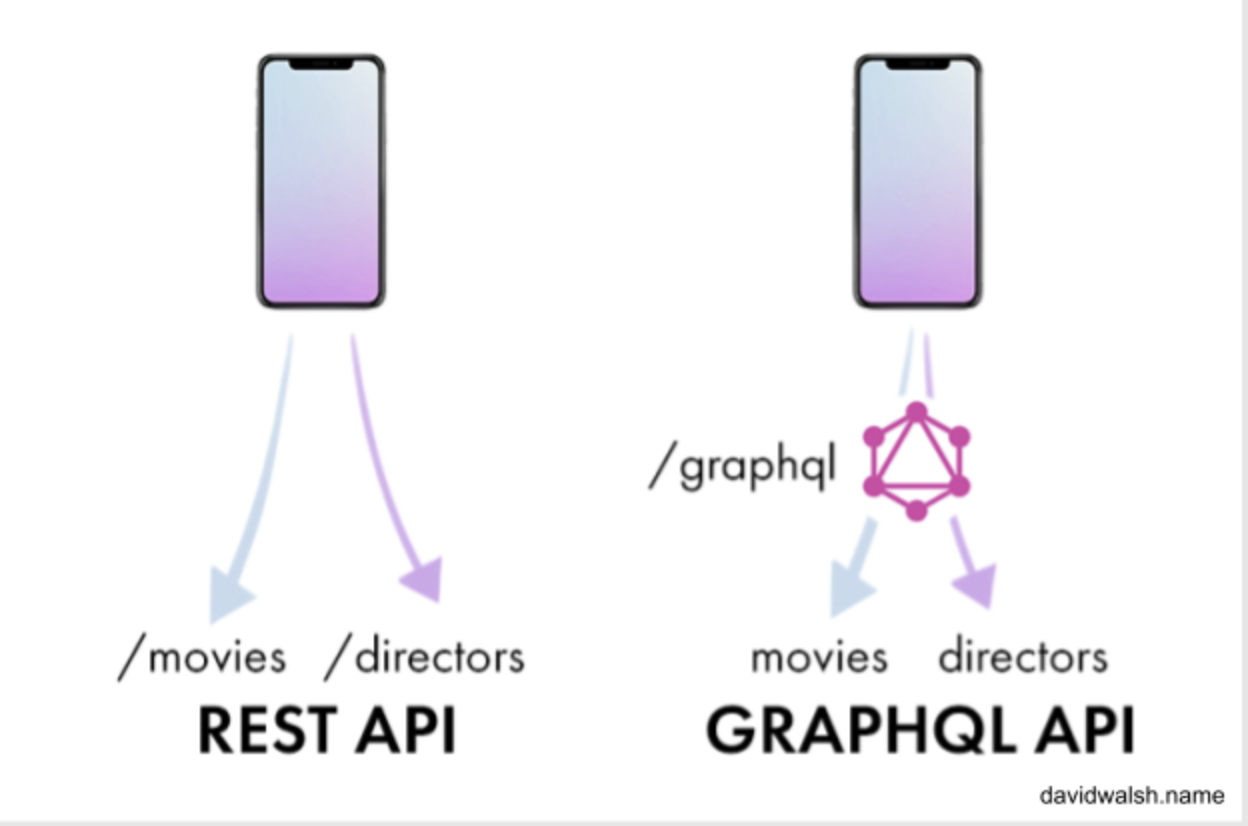
When implementing a GraphQL API, we often see a number of side-effects on other elements of our back-end infrastructure. A GraphQL API is typically exposed as a single endpoint by our back end, as illustrated in Figure 3.
Adopting the GraphQL API means that we will not only need to change the API but will often have to rethink our entire infrastructure (Figure 4), from API management and security to caching, developing a federation of queries on gateways, and much more.

Schema first or code first?
There are multiple ways to develop GraphQL solutions. The two most common approaches are schema first, where developers write GraphQL schema first and later build client-side queries and data resolvers on the back end, and code first (also known as resolvers first), where developers write the resolvers first and then generate the GraphQL schema for them.
Both approaches come with advantages and disadvantages based on your specific use case.
Implementing GraphQL for Node.js
Making all of the decisions about how to implement GraphQL can be daunting, as illustrated by Figure 5.

Many developers become overwhelmed by the amount of work required and look for libraries or tools that offer comprehensive support instead. As we've previously mentioned, in a GraphQL ecosystem, developers often look to one of the available CRUD engines for support (Figure 6).

CRUD engines try to address the major shortcomings and complexity of GraphQL by offering unified and low-code data access. However, in the long run, they can fail to deliver the capabilities we want, especially integration with other services.
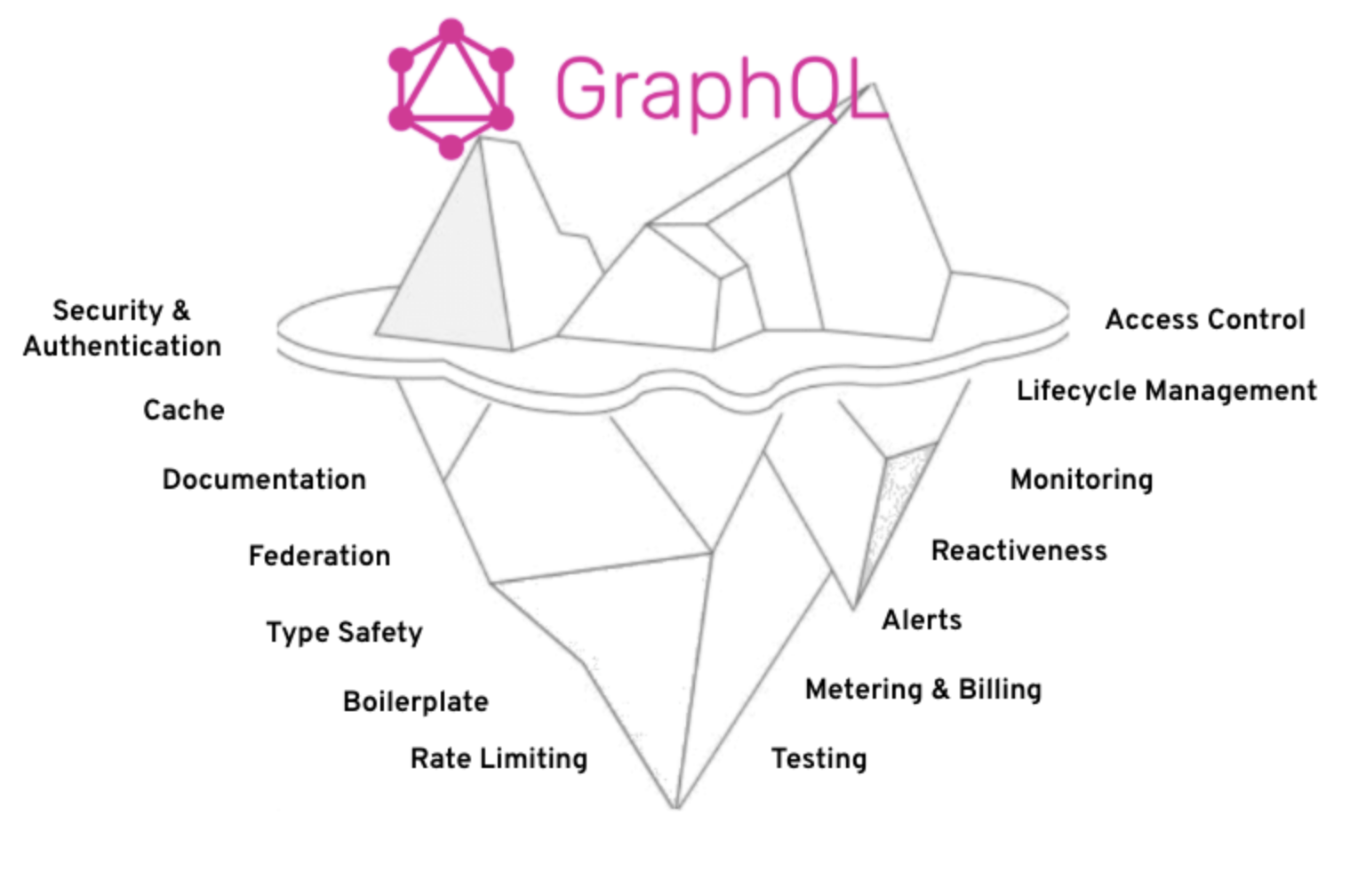
Moreover, the initial results associated with using productivity tooling are often the tip of the iceberg for what you will face when deploying your code to production (see Figure 7).
Red Hat team members have been using GraphQL for many years, working with the community and customers to address different challenges encountered when using GraphQL, including those we've discussed in the preceding sections. Next, we'll introduce the GraphQL section of the Node.js Reference architecture, which is based on our experience as well as that of teams within IBM.
GraphQL recommendations and guidance
When working on the GraphQL section of the reference architecture, we discussed a number of principles and values that influenced the documented recommendations and guidance. Here, we'll offer a brief overview.
Schema first development
In order to support collaboration across different languages, microservices, and tools we recommend using the GraphQL schema as a form of API definition rather than generating a schema from the code. Code-first solutions typically are limited to a single language and can create compatibility issues between the front end and other useful GraphQL tools.
Separate concerns
When our back- and front-end codebase is minimal we can use tools to generate code, analyze our schemas, and so on. Those tools typically do not run in production but provide a number of features missing in the reference architecture. All elements should work outside your application and can be replaced if needed.
Use the GraphQL reference implementation
Using the GraphQL reference implementation facilitates supportability and it is vendor agnostic. GraphQL is a Linux Foundation project with a number of reference libraries maintained under its umbrella. Choosing these libraries over single vendor and product-focused open source libraries reduces the risk of providing support and maximizes the stability of our solutions over extended periods of time.
Minimalism
Developers often look for libraries that offer an improved API and increase productivity. In our experience, picking a high-level tool that focuses only on the essential elements needed to build a successful GraphQL API leads to the best outcome. As a result, we've chosen to include a very short list of packages and recommendations that are useful for developers.
Exclude opinionated solutions
The GraphQL section of the Node.js reference architecture does not include CRUD engines or tools that affect developer flexibility and introduce proprietary APIs.
Based on our discussion of these principles and values, along with our prior experience, we developed the recommendations and guidance captured in the reference architecture. We hope this article has given you some insight into the background and considerations the team covered in building that section. For more information, check out the GraphQL section of the Node.js reference architecture.

What’s next?
We plan to cover new topics regularly as part of the Node.js reference architecture series. In the next installment, we discuss building good containers.
We invite you to visit the Node.js reference architecture repository on GitHub, where you'll see the work we’ve already done and the kinds of topics you can look forward to in the future.
To learn more about what Red Hat is up to on the Node.js front, check out our GraphQL or Node.js landing page.
Last updated: January 9, 2024