Red Hat OpenShift Connectors is a new cloud service offering from Red Hat. The service provides prebuilt connectors to enable quick and reliable connectivity across data, services, and systems. Each connector is a fully managed service, tightly integrated with Red Hat OpenShift Streams for Apache Kafka, Red Hat's managed cloud service for Apache Kafka.
Change data capture (CDC) is a software process that detects changes (inserts, updates, deletes) to data in a database and transforms these changes into event streams that can be consumed by other systems or applications to react to these changes.
Typical use cases for change data capture include:
- Data replication
- Streaming analytics
- Event-driven distributed applications
Red Hat OpenShift Connectors offers several source connectors for change data capture, based on the popular Debezium open source project. OpenShift Connectors support the following databases:
- PostgreSQL
- MySQL
- SQL Server
- MongoDB
This article demonstrates how to configure a source connector to capture data change events from MongoDB Atlas, a fully managed cloud database provided by MongoDB.
Prerequisites
This article assumes that you have created an instance of OpenShift Streams for Apache Kafka and that the instance is in the Ready state. Please refer to Getting started with Red Hat OpenShift Streams for Apache Kafka for step-by-step instructions on creating your Kafka instance.
Create a service account and configure the access rules for it. The service account requires privileges to read and write topics and to create new topics. The Get started with Red Hat OpenShift Connectors article has detailed instructions on creating and configuring the service account and the access rules.
Set up a MongoDB Atlas instance
The following instructions will guide you through the process of setting up a MongoDB Atlas instance:
- Sign up to provision a MongoDB Atlas instance. You can create an Atlas account or sign up with your Google account.
- After registration, you are taken to a page where you can choose the type of cloud database you want to provision. MongoDB Atlas offers different tiers, including a free tier for an easy getting-started experience. The free tier is sufficient to follow this demonstration.
- When creating your MongoDB Atlas instance, you have to specify the security settings. Choose a username and password and create a user to connect to your MongoDB instance.
- Add an IP address to the IP Access List. Enter
0.0.0.0/0because you don't know the IP address where the managed OpenShift Connector is running. This effectively allows connections to your MongoDB instance from anywhere. You can make the IP Access List more restrictive later on. - Add databases and collections once the MongoDB Atlas instance is up and running.
MongoDB Atlas provides a sample dataset described in the documentation. We will use the sample_mflix database from the sample dataset. This dataset contains data about movies.
10 steps to create an instance for change data capture
Now that you have provisioned and configured a MongoDB Atlas instance and loaded the sample dataset, you can create an OpenShift Connectors source connector to capture change events from the sample_mflix database. From your Red Hat console, complete the following 10 steps:
- Select Application and Data Services.
- On the Application and Data Services page, select Connectors and click Create Connectors instance.
- To find the Debezium MongoDB connector, enter
mongoin the search field. Click the Debezium MongoDB Connector card, then click Next. - Select the Streams for Apache Kafka instance for the connector. (This is the instance you created in the prerequisites step.) Then click Next.
- On the Namespace page, click Create preview namespace to provision a namespace for hosting the connector instances that you create (or select your existing namespace if you created one earlier). This evaluation namespace will remain available for 48 hours. You can create up to four connector instances per namespace. Once the namespace is available, select it and click Next.
- Provide the core configuration for your connector by entering the following values:
- A unique name for the connector.
- The Client ID and Client Secret of the service account that you created for your connectors.
- Click Next.
Provide the connection configuration for your connector. For the Debezium MongoDB connector, enter the following information:
Hosts: The set of the replicaset public addresses for your MongoDB instance. You can find these on the web console for your MongoDB instance. Click the Overview tab shown in Figure 1.
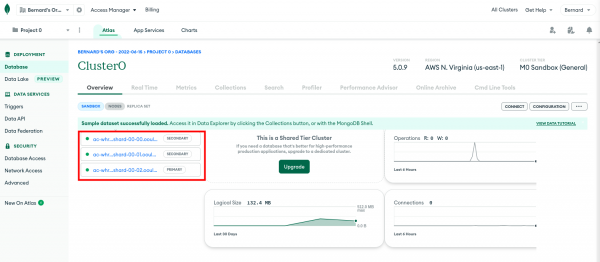
Figure 1: The Overview tab on the web console of the MongoDB Atlas instance shows the public addresses of the MongoDB replicaset. - Click the first link to get to the status page of the replica. The address of the replica is shown at the top of the page in
host:portformat. Copy the address to a text editor. - Repeat the procedure for the other replicas.
Go back to the OpenShift Connectors configuration page and enter the addresses of the three replicas separated by commas in the Hosts field. The entry should look like the following list (your values will be different):
ac-whrxxxx-shard-00-00.ooulprt.mongodb.net:27017, ac-whrxxxx-shard-00-01.ooulprt.mongodb.net:27017, ac-whrxxxx-shard-00-02.ooulprt.mongodb.net:27017- Namespace: A unique name that identifies this MongoDB instance. For example, enter
mongo-mflix. - Password: The password of the database user you created previously. Note that this is not the same user with which you logged into MongoDB Atlas.
- User: The user name of the database user you created.
- Make sure the Enable SSL connection to MongoDB is checked.
Figure 2 shows what a filled-out form looks like.
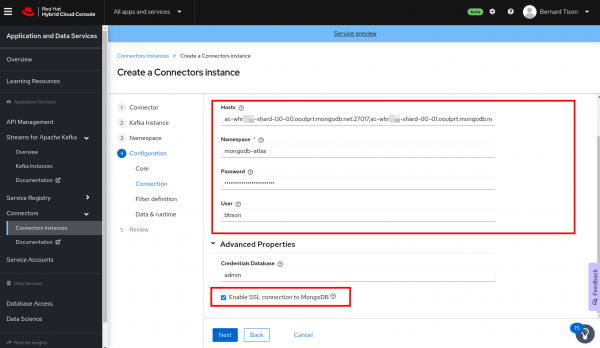
Figure 2: Enter configuration properties for the MongoDB Debezium connector. - On the next page of the wizard, set the Database filter to
sample_mflixand the Collection filter tosample_mflix.movies.This will ensure you capture change events only from themoviescollection. - Make sure that the Include box is selected for both entries. Click Apply to apply the filter. [Do not change the values on the Data & runtime page of the wizard. These are advanced values that you rarely need to change.]
- Review the summary of the configuration properties. Pay particular attention to the MongoDB Hosts field. Click Create Connector to create the connector.

Your connector instance will be added to the table of connectors. After a couple of seconds, the status of your connector instance should change to Ready. If your connector ends up in an Error state, you can click the options icon (the three vertical dots) next to the connector. Then edit the configuration and restart the connector.
Capture data change events from MongoDB
Once the Debezium MongoDB connector is ready, it connects to the MongoDB database, creates a snapshot of the collections it monitors, and creates data change events for every record present in the collection.
To verify, use the message viewer in the OpenShift Streams for Apache Kafka web console.
Head over to the Application and Data Services page of the Red Hat console and select Streams for Apache Kafka→Kafka Instances. Click the name of the Streams for the Apache Kafka instance that you created for connectors. Select the Topics tab.
You should see four new topics. Debezium connectors run on top of Kafka Connect (in contrast to the other OpenShift Connectors instances, which are based on Camel-K). Kafka Connect creates three topics to maintain its internal state. These are the topics ending with -config, -offset, and -status shown in Figure 3.
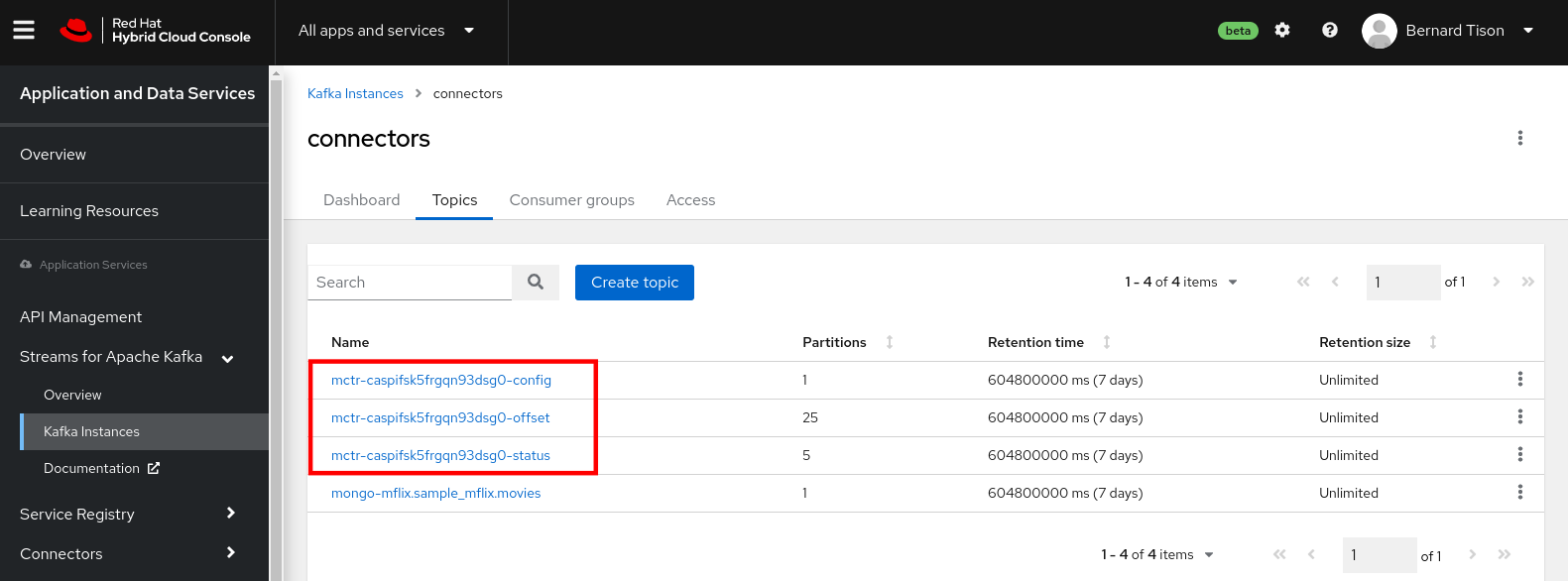
The other topic, named mongo-mflix.sample_mflix.movies, holds the data change events from the movies collection. Click the topic name and select the Messages tab. You should see the most recent ten messages in the topic, as shown in Figure 4.
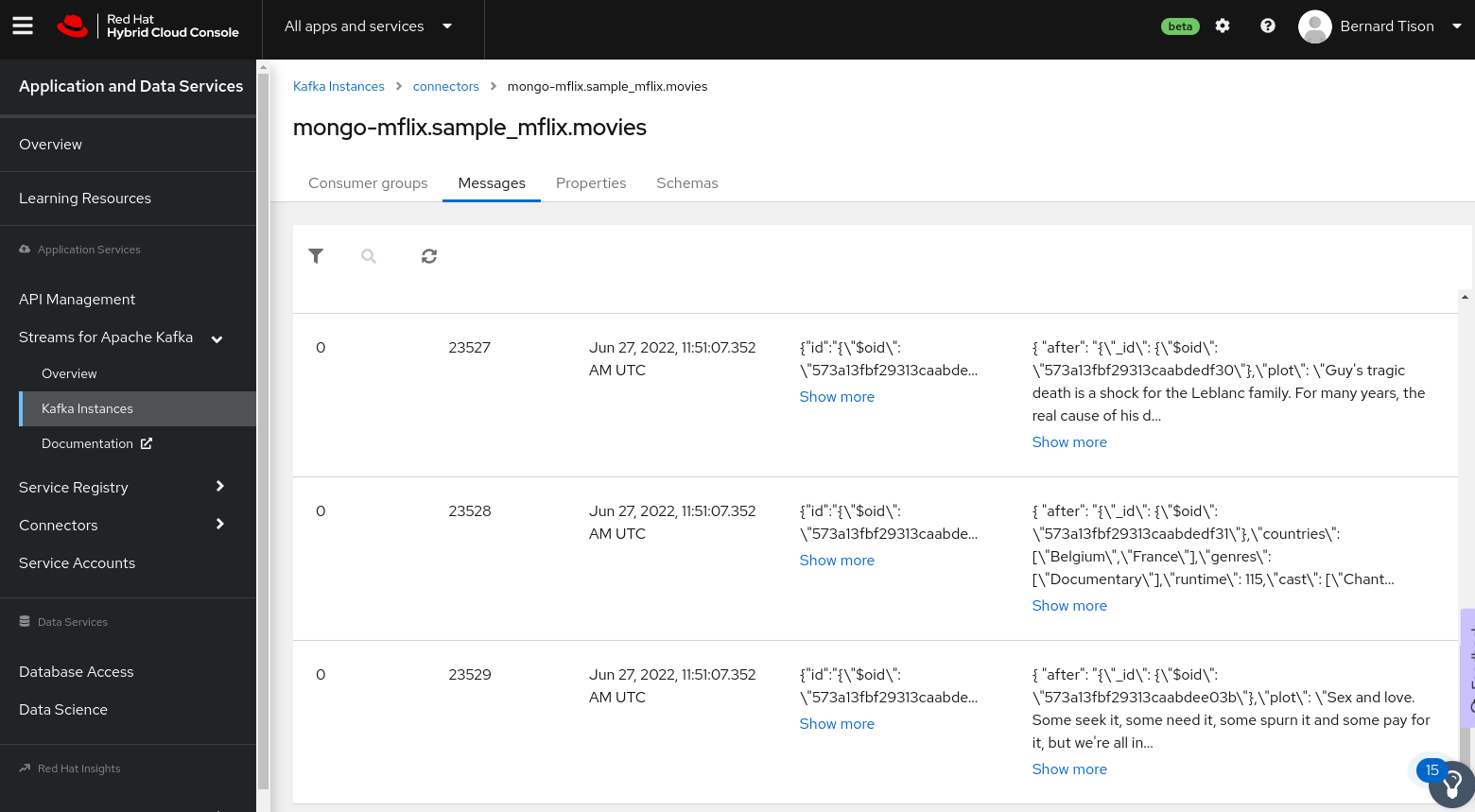
The offset of the last message in Figure 4 is 23529, which indicates that there are 23530 events in the topic. This corresponds to the number of records in the movies collection.
Each data change message has a JSON payload with the following structure:
- after: Contains the latest state of the document.
- source: Contains metadata about the connector and the MongoDB instance.
- op: Specifies the operation that created this change. In this case, the operation is
r, which stands forread.
Please refer to the Debezium documentation for more information on Debezium and the structure of the data change events it produces.
At this point, you can add new records to the MongoDB collection or modify existing records. The easiest way to do so is through the MongoDB Atlas web console:
- On the Database page, select the Collections tab
- Then select the
sample_mflix.moviescollection. - From here you can add new records to the collection or modify existing ones. Every time you make a change, a data change event is produced with the latest state of the document and an operation equal to
cfor creates andufor updates. - You can verify that change events are generated by checking the message viewer of the data change event topic in the Red Hat console.
An end-to-end data pipeline example
Capturing data change events from a database with an OpenShift Connector instance is just the first step in using the data. Typically, the data change events are consumed by other services or applications to, for instance, replicate the data or build a local view of the data.
The following video contains a demo of what an end-to-end data pipeline could look like. The demo uses OpenShift Connectors to stream the data change events to AWS Kinesis. The events trigger an AWS Lambda function that extracts the state of the document from the event and updates an AWS OpenSearch index. Figure 5 shows the pipeline.

Watch this quick CDC pipeline demo:
OpenShift Connectors speed up data collection applications
We hope you found this demonstration informative and easy to follow. Try Red Hat OpenShift Connectors for yourself and see how they speed up data collection applications. Feel free to reach out to us. We welcome your feedback.
Last updated: August 15, 2025