If you've been experimenting with a large language model (LLM), then you've probably felt that they have a lot of potential, except that they can't use the same services we do as developers and engineers. For example, try asking a model this:
Can you diagnose issues in my blackjack-ai-demo Kubernetes namespace?A typical response from a foundation model would result in a generic, helpful response such as "You need to run kubectl get pods” but it can't actually do anything about it. That's why the Model Context Protocol (MCP) has gained popularity as a standardized way for letting your AI model gather information from resources and use tools, including your cluster, your browser, and much more. This is also known as agentic AI. You can use an MCP client (like VS Code, Claude Desktop, or your own application with Llama Stack) to interact with your favorite services in natural language using MCP servers (such as Playwright, GitHub, and more).
An MCP client invokes tools, queries for resources, and interpolates prompts, while an MCP server exposes tools, resources, and prompts:
- Tools: Model-controlled functions invoked by a model
- Retrieve and search
- Send a message
- Update database records
- Resources: Application-controlled data exposed to the application
- Files
- Database records
- API responses (for example, HTTP GET/POST)
- Prompts: User-controlled pre-defined templates for AI interactions
- Document questions and answers
- Transcript summaries
- Output as JSON
With great power comes great responsibility (and a surprisingly high token bill). Each MCP server you add compounds a model's context window with thousands of tokens of tool metadata before your prompt even starts. More importantly, connecting an LLM to your live system must be done with care.
So let's look at the three most useful MCP servers you can plug into your workflow today, along with the non-negotiable guardrails needed to deploy them safely, especially on a platform like Red Hat OpenShift AI.
What you should know about MCP and safety
Before we install anything, let’s briefly talk about confirming that your private data isn’t leaked through prompt injection. This can happen when there's a "lethal trifecta" of capabilities in an AI agent:
- Private data: Access to your internal wikis, codebases, or databases
- Untrusted content: The ability to read data from the "outside world" (like a new GitHub issue or a public webpage)
- External communication: The ability to send data out (by posting a comment, calling a webhook, or running a
curlcommand)
Any agent that combines all three is a data exfiltration risk. An attacker could craft a malicious GitHub issue (untrusted content) that tricks your agent (which has access to your private code) into sending that code to an external server. The fix? Treat "human-in-the-loop" as a must, not a suggestion. By default, every tool must be set to read-only, and require explicit user approval for any write action. It's best practice to avoid giving a model write access to anything you wouldn’t want deleted or read access to anything you wouldn’t want publicly leaked.
With that out of the way, let's get started!
Pick #1: Kubernetes MCP server
I absolutely love this one. It's the most powerful, day-one tool for any platform or SRE team. The Kubernetes MCP server (Figure 1) lets your AI assistant directly communicate with your cluster, letting it perform any CRUD (create or update, get, list, delete) operation on resources, even interact and install Helm charts. Wonder why your pod is failing? Just ask your model: get the logs and recent events for pod xyz and tell me why it's crash-looping.
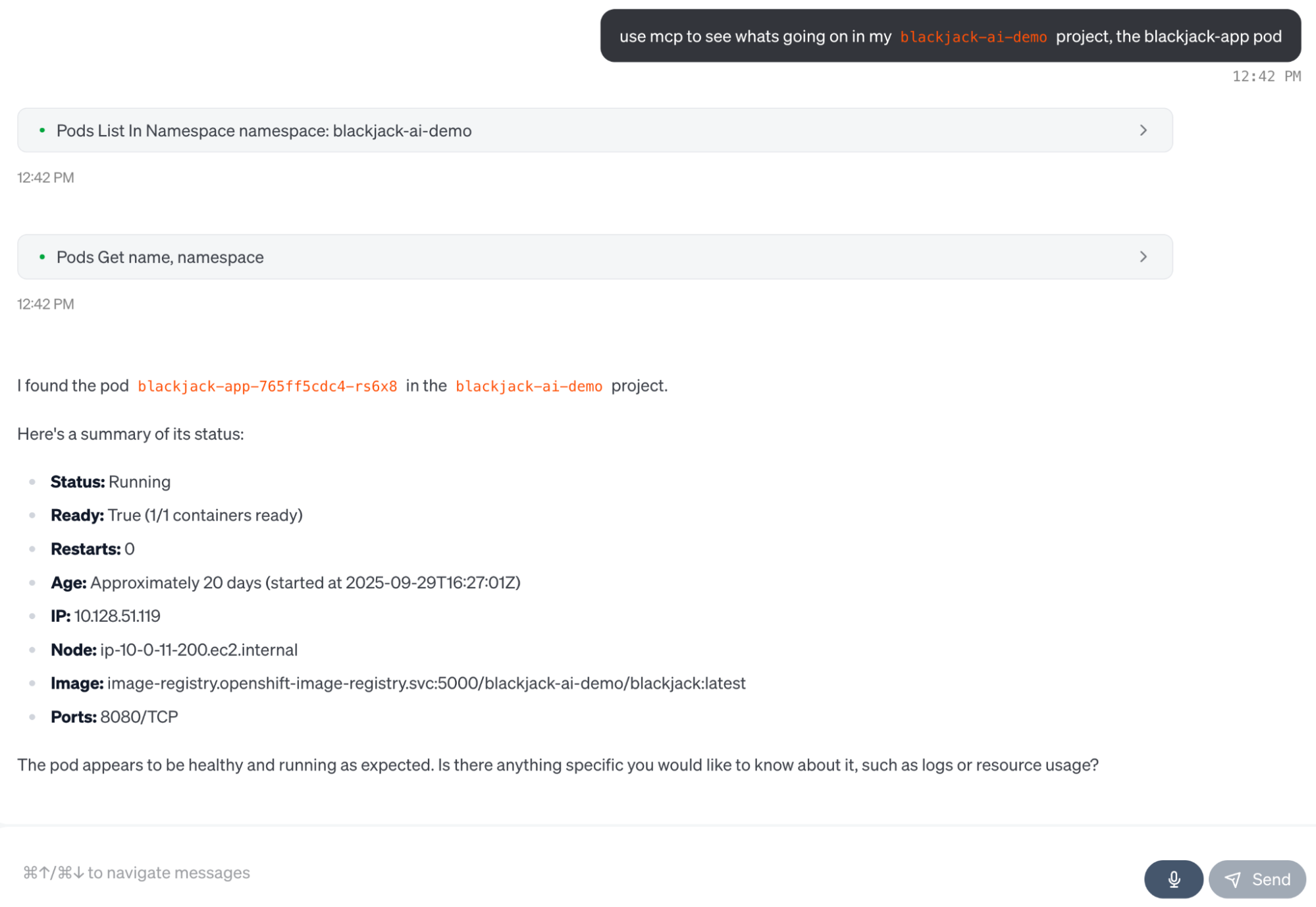
Install the Kubernetes MCP server
Check out this Red Hat Developer guide on setting up the Kubernetes MCP server with least-privileged ServiceAccounts, which allows it to more safely query your cluster. In your AI assistant (like Goose or Claude Desktop), here’s the MCP server configuration:
{
"mcpServers": {
"kubernetes-mcp-server": {
"command": "npx",
"args": ["-y", "kubernetes-mcp-server@latest", "--read-only"]
}
}
}Now you'll be able to diagnose issues ("Why is my deployment not scaling?") by safely inspecting resources, all while adhering to your existing RBAC policies.
Pick #2: Context7 MCP server
The biggest problem with LLMs is that their knowledge is frozen in time. They confidently hallucinate APIs that don't exist and write code for deprecated library versions. For developers, this can be frustrating when using a code assistant, but the Context7 MCP server (Figure 2) solves this by giving your agent access to up-to-date technical documentation on demand.
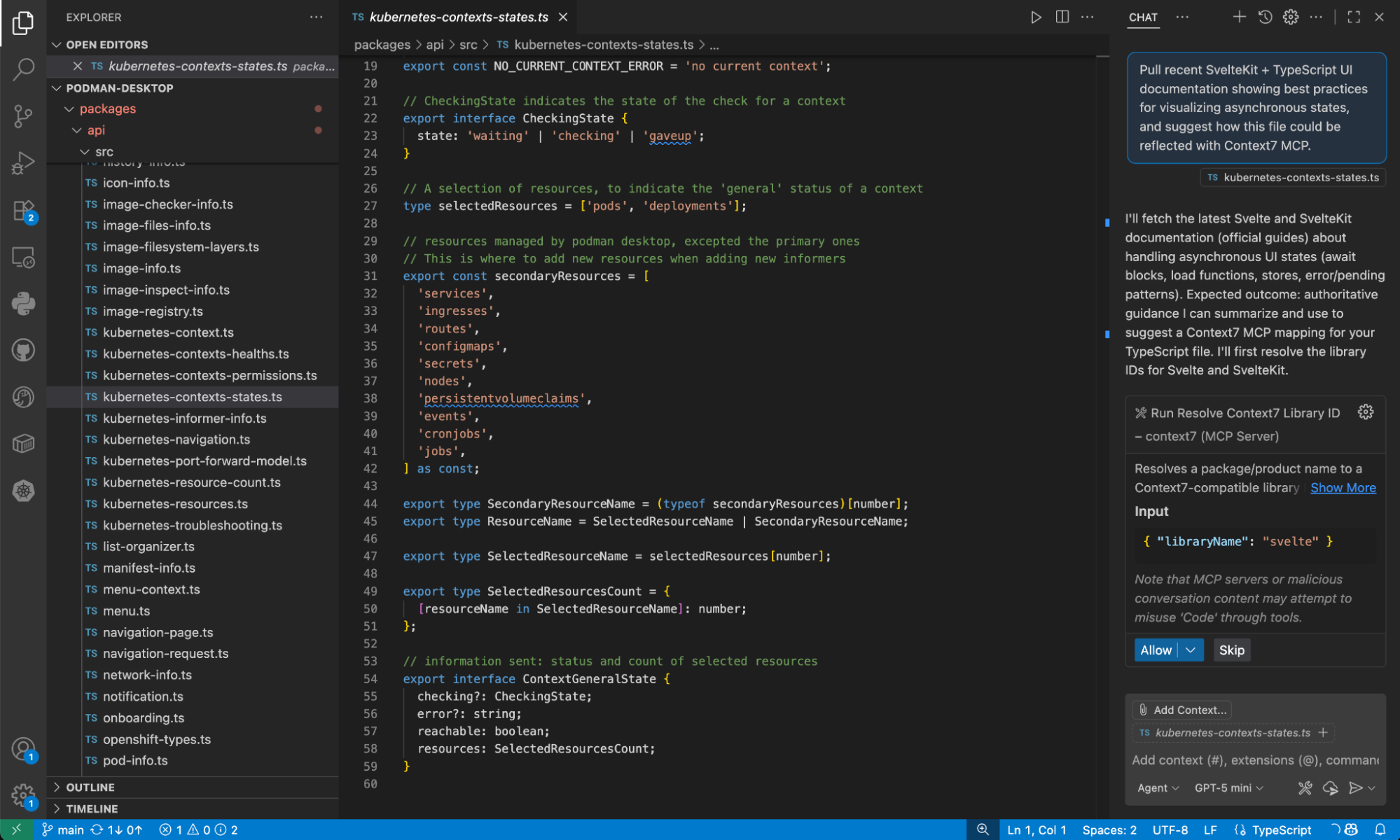
Install the Context7 MCP server
To pull in fresh documentation for your projects (for example, I asked “pull recent SvelteKit + TypeScript UI documentation showing best practices for visualizing asynchronous states”), add this MCP server configuration directly to your IDE (such as VS Code or Cursor):
{
"mcpServers": {
"context7": {
"command": "npx",
"args": ["-y", "@upstash/context7-mcp@latest"]
}
}
}Because it's read-only by design, there's less risk on its own, but be careful when combining this server with a write-capable one (like the GitHub MCP) as Context7 can also support API keys to access private repository docs.
Pick #3: GitHub MCP server
As developers, only a small portion of our work is strictly coding, the rest is PR triage, issue grooming, searching for code, and so on. That's why the official GitHub MCP server makes it easy to interact with your repositories (but I’ve even been using it for CI/CD, to understand why my GitHub Actions are failing).
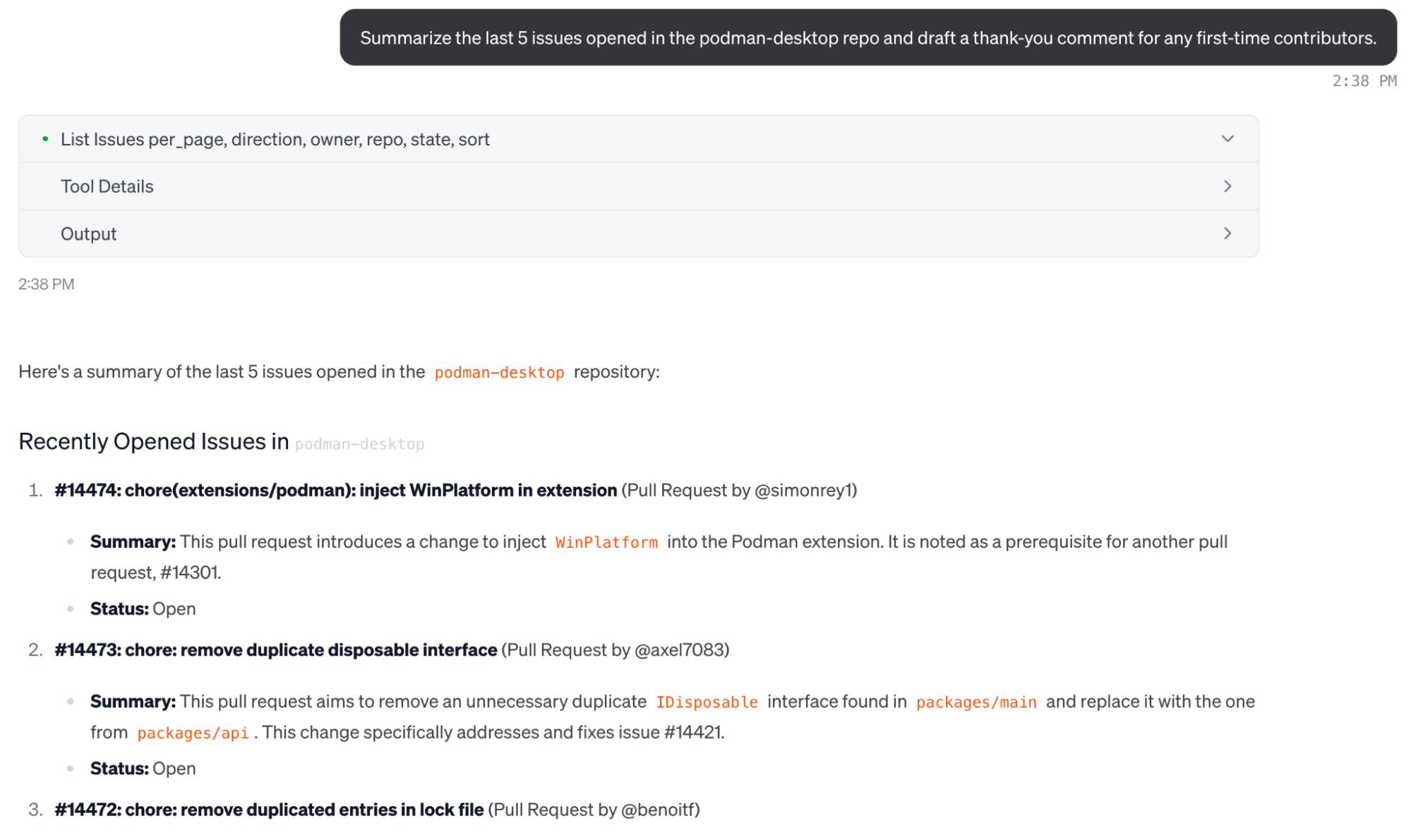
Install the GitHub MCP server
With this specific MCP Server, it's recommended to use a specific personal access token with minimum scopes. Start with repo:read and read:org, and ensure that you have human approval for any write action.
{
"mcpServers": {
"github": {
"url": "https://api.githubcopilot.com/mcp/",
"headers": {
"Authorization": "Bearer YOUR_GITHUB_PAT"
}
}
}
}Now you can query GitHub (and your unique projects) using natural language, like "summarize the last 5 issues opened in the podman-desktop repo and draft a thank-you comment for any first-time contributors".
Conclusion
By using a single MCP server, or multiple MCP servers, in your agentic AI workflow, you may see faster troubleshooting, smarter code assistants, and fewer manual interactions with your commonly used services. Be cautious with the control your agentic application has, there have been instances where AI-powered tools have deleted an entire database. Start small, then scale up, with approval workflows and sensible guardrails.
By deploying these tools with care on a trusted, hybrid platform like Red Hat OpenShift AI, you can build powerful and cost-efficient agentic AI systems in production, thanks to open standards like MCP and the broader open source ecosystem.