In Red Hat OpenShift 4, the Operator framework became a fundamental part of the daily cluster operations. We previously explained the Data Grid Operator in the blog post How to install and upgrade Data Grid 8 Operator. You can also deploy via a Helm chart, as discussed in How to use Helm charts to deploy Data Grid on OpenShift.
This article describes a few Java Virtual Machine (JVM) tuning considerations for Red Hat Data Grid deployments. Note that some of this advice also applies to Red Hat JBoss Enterprise Application Platform (EAP) and other middleware products. This post builds on the article How to Use Java Container Awareness in OpenShift 4, which discusses several of those topics.
Fundamentals of JVM tuning for Red Hat Data Grid
While containers make it simple to deploy an application, the JVM is bound by the container, which can make tuning difficult.
Beyond application performance and garbage collection (GC) impact, you should consider additional factors for the container and the OpenShift node itself. Application deployment involves several considerations; the GC collector is just one of many.
These tuning considerations for Data Grid deployments focus on 3 key aspects:
- The container deployment and how this impacts the JVM.
- The Kubernetes/OpenShift deployment and its impacts, such as Quality of Service (QoS) of the pods.
- The GC and JVM performance in general. While the GC collector is a big factor here, it doesn't entirely control the Java container performance.
5 core tuning considerations
Here are some key points to keep in mind for tuning:
- JVM container awareness: The JVM is container-aware, automatically detecting and adhering to the container's boundaries. This is a valuable feature for resource management.
- JVM Inelasticity: For main Data Grid operations, the JVM is inelastic, meaning it primarily uses
resources.limitsfor CPU calculations (including GC threads, blocking threads, and non-blocking threads). - Allocate adequate CPU resources: Provide sufficient CPU resources for the container. Avoid allocating minimal CPU resources; this might not cause immediate restarts or out-of-memory errors, but it could lead to unresponsive probes and trigger a
SIGTERMfrom the kubelet. Set appropriate quality of service (QoS): In OpenShift Container Platform 4, resource limits and requests enable sharing and potential overcommitment of cluster node resources. Because this overcommitment can be problematic, set an adequate QoS to avoid performance issues.
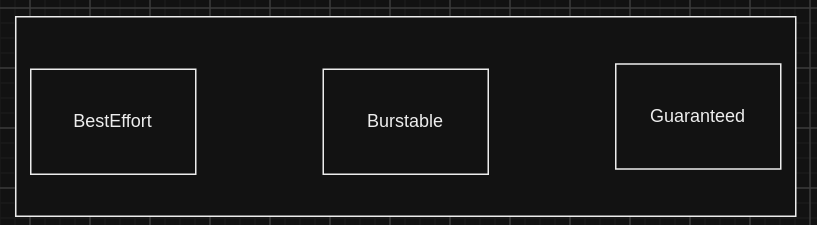
Specifically, setting pod resource requests the same value as the pod limits provides the pod with Guaranteed Quality of Service (QoS). For production-critical deployments, this approach is recommended. It prevents overcommitment by users and ensures applications do not interfere with critical deployments. See Figure 1.
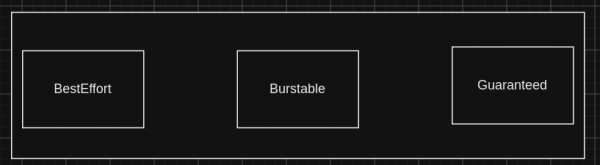
Figure 1: Diagram of Quality of Service (QoS). However, this does not mean that one should always use this setting. Red Hat's recommendation is to deploy critical workloads with
GuaranteedQuality of Service. Most applications do not need to use a high number of CPUs throughout the day, as they might spike sporadically and not simultaneously. Therefore, having different values withBurstableQoS can be adequate, or in some cases,BestEffortQoS. The use ofGuaranteedQoS might be excessive (and even counterproductive) for all circumstances. For more information on overcommitting resources, refer to the OpenShift documentation. This has other implications, such as CPU throttling—see below.- Finally, adjust the deployment method. Select the adequate deployment method in OpenShift Container Platform 4, either Operator or Helm charts. In most cases, the Data Grid Operator should be adequate.
| Core fact | Purpose | Recommended |
| JVM is container-aware | JVM boundaries are associated with the container resources via cgroups. | Setting the adequate container memory size will also set the JVM size (heap and off-heap). |
| JVM is inelastic | The JVM will not dynamically change its heap and number of threads (more on this in a moment). | Set adequate resources on the container for the JVM to start with. |
| Allocate reasonable resources | Avoid allocating scarce resources for the JVM. | Avoid extremely small container sizes for Data Grid in terms of CPU and memory. |
| Runtime versus build time | Runtime allows better adaptability. | Avoid setting Java parameters at build time; instead, prefer runtime (e.g., extraJvmOpts). |
| Quality of Service (QoS) | The usage of Guaranteed QoS provides more security in case of resource scarcity. | Deploy critical applications with Guaranteed QoS. |
About the number of threads: For all intents and purposes, Red Hat build of OpenJDK considers the CPU/memory values at the start of the container. Thread and memory calculations are derived from those values, affecting heap size and thread pools. If the value changes with an update to the cgroups file, the JVM will see it, but its behavior is undefined if it's no longer the same as the usage at startup. See more information here.
Most importantly, benchmark your application so that memory and CPU usage are clearly understood. This will help identify resource requirements and breakpoints in terms of usage and allocation. It also helps understand how the application will behave under non-optimal OpenShift Container Platform scenarios.
Considerations for Data Grid Operator versus Data Grid via Helm charts
When using the Data Grid Operator, you must take additional considerations into account for each of the pods:
- Data Grid Operator pod: If many clusters are being deployed by the Data Grid Operator, more resources might be needed if there are a large number of Infinispan CR and Cache CRs.
- Router pod: This is useful for cross-site configuration.
- Config Listener pod (also known as the tattletale pod, as it provides the configuration the user creates in the Data Grid cluster): You might need to increase its resources if there are many cache Custom Resources for bidirectional reconciliation.
The following table summarizes these considerations:
| Pod | Purpose | Why tune it? |
| Data Grid Operator | Listens for API changes and creates resources like caches and Infinispan clusters. | To handle more Infinispan resources. More caches/clusters require more resources. |
| Router pod | Enables cross-site communication. | For scaling up cross-site communication. |
| ConfigListener | Listen to adjustments on the YAML files. | More caches/clusters require more resources to listen for changes. |
When using Data Grid Helm charts, be sure to consider container resource scalability. For instance, in cases where there are many memcached listeners, the Infinispan pod container must increase resources accordingly. The more socket listeners, for example, the more container resources you need to allocate.
Benchmark
The main recommendation in any tuning setting is to have a benchmarking methodology that allows comparing a certain baseline versus a certain alternate scenario. The difference can then be pinpointed specifically for a certain task or series of tasks.
Steps:
- Set a baseline for comparison.
- Set a comparative scenario.
- Conclude by comparing the baseline versus comparative scenarios.
In terms of comparison metrics, comparing specific scenarios in terms of latency versus footprint versus throughput is always the simplest approach. More often than not, we sacrifice footprint for a better throughput or latency.
GC log collection and GC collectors
GC log collection is highly recommended in any scenario. It has very low overhead and provides extensive, detailed information about the specific operation of the Data Grid Java process.
Example configuration:
Xlog:gc*=info:file=/tmp/gc.log:time,level,tags,uptimemillis:filecount=10,filesize=1mJVM garbage collectors offer numerous configuration options. G1GC, for instance, simplifies JVM deployment by prioritizing latency targets over generational memory sizing using the MaxGCPauseMillis argument, streamlining the process compared to CMS with its many settings.
Furthermore, it's important to note that the non-generational Shenandoah collector is generally unsuitable for workloads involving extensive random memory allocation and deallocation. Therefore, combining it with Data Grid is not recommended unless the application features consistent, ongoing data allocation and deallocation, which is uncommon in Data Grid use cases.
| GC collector | Usage |
| Non-generational (e.g., Shenandoah or ZGC) | Avoid using high-performance Data Grid (e.g., cross-site scenarios and random/high allocation/deallocation). |
| G1GC | Generational collector focused on latency (usually has the best performance for high performance Data Grid, including cross-site scenarios). |
| ParallelGC | Generational collector focused on throughput rather than latency. |
For generational workloads, generational collectors will have better performance than non-generational, even concurrent ones.
JVM tuning
JVM tuning for Data Grid Operator and Data Grid Helm charts can be configured as described below..
Data Grid Operator:
spec:
container:
cpu: '2'
extraJvmOpts: '-Xlog:gc*=info:file=/tmp/gc.log:time,level,tags,uptimemillis:filecount=10,filesize=1m'Data Grid Helm chart:
deploy:
container
extraJvmOpts: '-Xlog:gc*=info:file=/tmp/gc.log:time,level,tags,uptimemillis:filecount=10,filesize=1m'For more information on Helm chart releases, see the Red Hat Data Grid 8.3 Documentation.
CPU throttling
When discussing tuning, including the number of threads and Garbage Collector, CPU throttling is an important topic. CPU throttling occurs when a container's runtime CPU utilization reaches, approaches, or surpasses the set CPU limits, triggering a kernel reaction to cap its utilization.
This is a consequence of the container being just a process in the OpenShift Container Platform host, as explained on this solution. The kernel has the ability and prerogative to preempt the processes to run; this is a feature. Below are some additional points to consider, depending on the situation:
The throttling should occur when the application's threads have used up its quota (limit), given the CPU quota the process is preempted. Depending on the kernel version this plays less of a role.
OCP host might use Completely Fair Schedule's (CFS) quota mechanism to implement process limits, and therefore impose a limit on the threads as a consequence, regardless of CPU and memory settings.
CPU throttling process is a kernel feature. Setting a different Quality of Service (QoS), which is a Kubelet feature, does not prevent the kernel from throttling. For example, this occurs in a scenario where the application maxes out a single CPU on the thread where a single-threaded Lightweight Process (LWP) executes on one CPU. The following table summarizes these scenarios.
| Option | Cons | Pros |
| Leave the container without any limits | The QoS will be BestEffort. | Not having limits means the kernel will not throttle the application. However, if eviction occurs, this container will be the first. Additionally, Data Grid will use the full OpenShift node as the CPU (or memory) limit. |
| Leave the container with limits | The QoS will be can be Guaranteed or Burstable | Having limits means the kernel will throttle the application at some point. However, if eviction occurs, this container will not be the first. |
Although Kubelet's Guaranteed or Burstable QoS does not prevent CPU throttling from happening, avoiding setting limits will prevent the kernel from performing CPU throttling. Nonetheless, this has two critical implications:
- First and most importantly: Data Grid and any Red Hat build of OpenJDK application use the deployment CPU limits for CPU thread calculation. This means leaving no limits on the deployment has consequences.
- Second: Not setting limits (and requests), which means not setting Guaranteed or Burstable QoS, results in a Best Effort QoS. If the cluster comes under pressure, Best Effort QoS pods will be evicted first, followed by Burstable QoS pods.
Therefore, if the user sets limits and requests (thereby setting pods as Guaranteed or Burstable QoS), CPU throttling can occur. Avoiding CPU limits on the deployment would prevent this.
To compromise between eviction and CPU throttling, you can set a larger request-to-limit ratio on the deployment so the pod will have Burstable QoS. This compromise will:
- Reduce (but not completely avoid) CPU throttling.
- Ensure that if eviction occurs, this pod will not be the first to be evicted.
- Prevent Data Grid (or any OpenJDK application) from using the full OpenShift node as a limit for memory and/or CPU, which would lead to an excessive number of threads.
Other factors to consider
Below are some additional points to consider, depending on the situation:
- Complementary to the above, do not set
Xmxfor more than 80% of the heap (leaving less than off-heap space). Always leave space for off-heap, even if the cache is not explicitly configured for off-heap. - Do not set off-heap for 80%+ of the total memory, even if all caches are off-heap. This is because state transfers temporarily require a significant chunk of heap memory. After the actual cache data, state transfers are the second biggest memory consumer in Data Grid (in short bursts).
- One should not deploy anything critical in production with less than 2 or 3 CPUs. A lack of CPU will cause timeouts on the execution of CLI commands. If you have more resources, this is the time to use them.
- Using 2+ CPUs also allows for much better utilization of multi-thread collectors such as ParallelGC and G1GC, taking advantage of multiple CPUs.
- Avoid deprecated service caches, such as those described in Red Hat Solution 6972352.
- Avoid deprecated flags, like using JDK 17 with
UseParallelOldGC. This will return:Unrecognized VM option 'UseParallelOldGC'or--illegal-access=debug.
For specific Data Grid recommendations, see this Red Hat article.
Conclusion
This article covered JVM tuning, core tuning settings, and benchmarking topics, focusing on Data Grid specificities in OpenShift Container Platform 4. It also raised some aspects of Data Grid installation and customization that can be done via the Data Grid Operator (preferable) or Data Grid Helm charts.
Regarding tuning and settings, a considerable number of JVM settings can be changed, including—but not limited to—GC and container settings. For GC collectors, G1GC has shown great performance for generational workloads, specifically focusing on latency targets rather than generational memory size.
This article briefly describes some tuning possibilities for Java applications deployed in OpenShift Container Platform 4. None of the points described here are mandatory rules; everything should be taken with a grain of salt depending on the specific use case. Therefore, benchmarking and comparing performance with a baseline and expectations should be the primary lessons learned.
For critical deployments, the recommendation is to set Guaranteed or Burstable QoS and avoid Best Effort QoS. This prevents critical pods from being evicted if the OpenShift cluster resources are under pressure or over-provisioned. However, the trade-off will be the effect of CPU throttling by the kernel, as these containers will have limits. A compromise to both problems, preemption and eviction, was proposed above: Burstable QoS with a larger ratio of requests to limits. This will prevent pods from being the first to be evicted if resources run out and will avoid significant throttling effects.
Finally, this article builds on the main article How to Use Java Container Awareness in OpenShift 4, which details how changes in JDK 8u191+ enabled container awareness. This is undoubtedly the largest feature and causes a significant shift in Java application development and deployment inside OpenShift Container Platform 4. The application no longer needs to be explicitly "deployed for container settings" but rather, the deployment will detect the container settings and adapt from the detected cgroups (version 1 and version 2).
Additional resources
To learn more, read Java 17: What’s new in OpenJDK's container awareness.
To learn more about the DG Operator, see the Data Grid Operator Guide.
To learn more about the Data Grid Helm chart deployment, see here.
For any other specific inquiries, please open a case with Red Hat support. Our global team of experts can help you with any issues.
Special thanks to Will Russell and Alexander Barbosa for the review of this article. Finally, thank you to Vladislav Walek for his inputs and lessons on OpenShift those last 5 years working together.