In Red Hat OpenShift 4.x, the Operator framework became a fundamental part of the daily cluster operations, and we explain the Data Grid Operator in this Data Grid Operator installation article.
The Data Grid Operator provides an easy and straightforward method for deploying a Red Hat Data Grid server. Once the Data Grid is deployed it can include features such as cross-site and JVM settings, which are set via the Custom Resources (CRs) consumed by the Data Grid Operator to build the Data Grid server.
[ Learning path: Cross site and cross applications with Red Hat OpenShift and Red Hat Data Grid ]
Another supported approach for deploying Data Grid in Red Hat OpenShift Container Platform (RHOCP) 4 is via the use of Helm charts, where the user installs the charts and passes a value YAML file to be deployed as a StatefulSet (sts).
These are the only two supported approaches to deploy Data Grid in OpenShift Container Platform 4 given the absence of template/direct deployment in Data Grid, unlike Red Hat JBoss Data Grid 7. To cover this deployment method, which complements the Data Grid Operator, we will explain how to install a Data Grid server using the Data Grid Helm charts. We'll also discuss the use and limitations of this approach.
Introduction
Data Grid is Red Hat's supported solution for in-memory cache storage.
A Helm chart is a popular approach to install resources using pre-made charts, which helps the development and provides a standardized way to customize the deployment (usually via a custom YAML file passed to the RHOCP cluster—comprised of values to be consumed by the Helm).
The Red Hat Data Grid Helm charts are the official files we provide to deploy Data Grid directly on the RHOCP 4 environment and provide several embedded features ready for use. The Helm charts has two components: Helm and the charts.
- Helm: the command-line process that processes the values YAMLs together with the chart itself.
- Charts: a collection of files in a specific structure already pre-made.
To use the Helm charts, the user needs to add the Helm charts and then create a file that will be consumed by the Helm parser, called the value file. The value YAML passes the information for the Helm charts on the Helm installation. Finally, Helm uses its CLI tool helm to select the specific details for installation: namespace, specific Helm chart, resource name, and the value YAML to be consumed.
Data Grid installation using Helm charts
CLI installation
Below is an example of a minimalistic custom value YAML file—to be passed on the Helm installation and consumed to create the Data Grid resources:
$ cat jdg-values.yaml
images:
server: quay.io/infinispan/server:14.0
initContainer: registry.access.redhat.com/ubi8-micro
deploy:
replicas: 1
container:
extraJvmOpts: ""
storage:
size: 1Gi
resources:
limits:
cpu: 1200m
memory: 5Gi
requests:
cpu: 1000m
memory: 3Gi
security:
batch: "user create admin -p changeme"
To install Data Grid via Helm charts, use the helm command CLI as below.
helm install --values jdg-values.yaml infinispan openshift-helm-charts/redhat-data-grid
Another example is shown below.
helm install infinispan openshift-helm-charts/redhat-data-grid --values jdg-values.yml
Explanation: The example above creates a StatefulSet (STS) called Infinispan passing the values file above (called jdg-values.yml) and the official Helms will be openshift-helm-charts/redhat-data-grid.
OpenShift web console installation
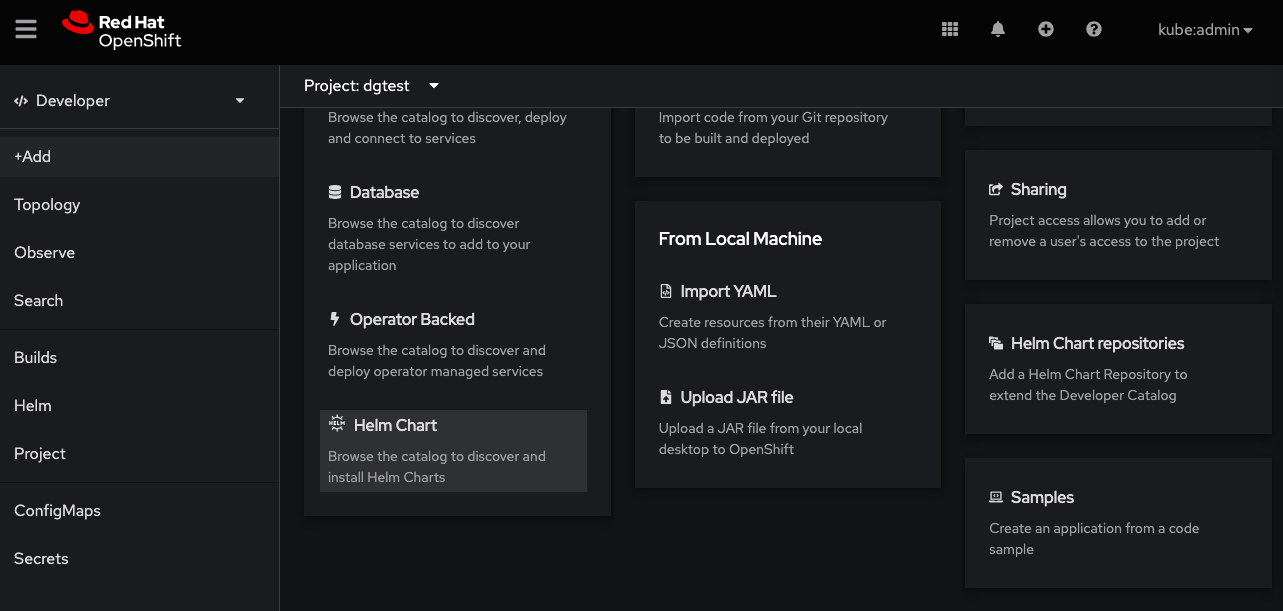
Besides the CLI installation detailed above, it’s also possible to install the Helm chart via OpenShift web console by switching to the Developer perspective, then selecting the +Add option in the left panel and scrolling down to the Helm Chart option, as shown in Figure 1.
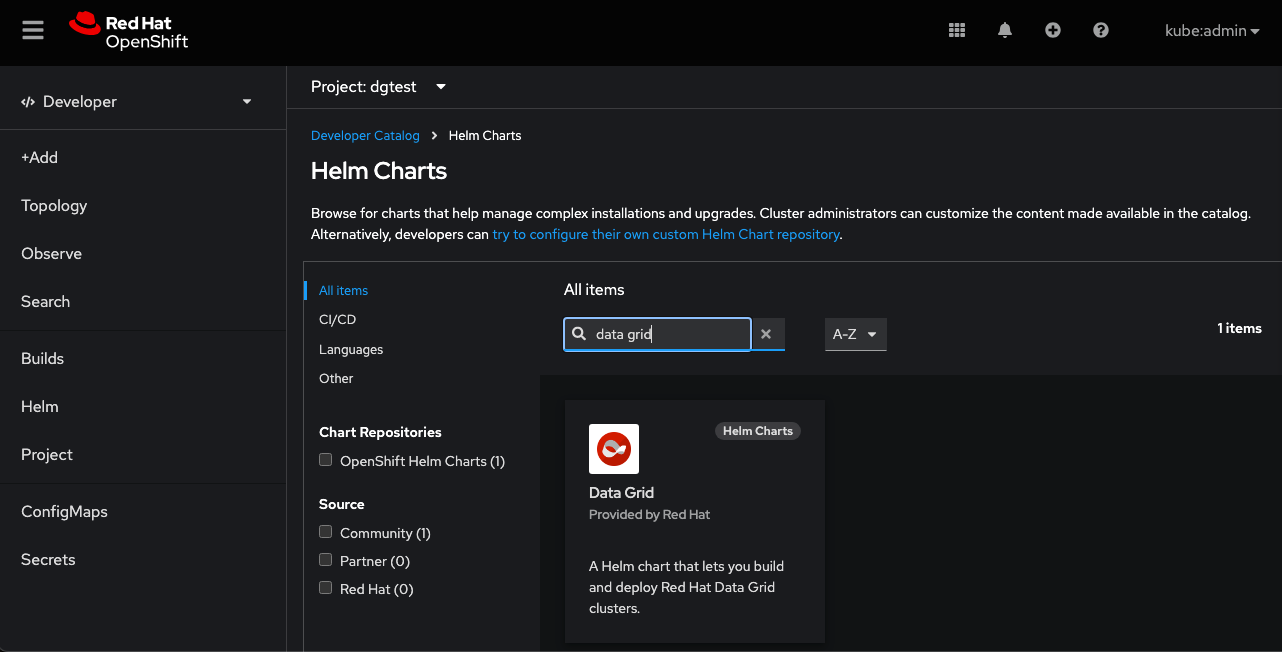
Then search the Data Grid Helm chart and create the project (Figure 2).
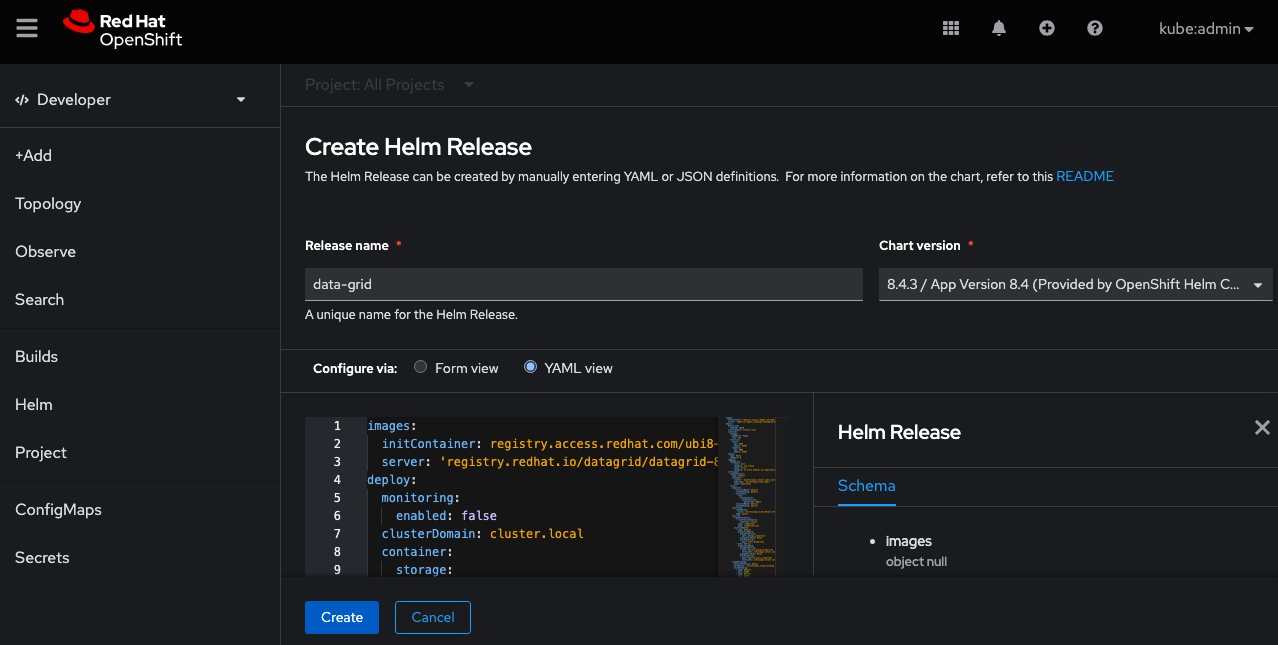
Once selected, there is an option to add the custom value YAML with the required deployment options, as shown in Figure 3.
Data Grid Operator versus Data Grid via Helm charts
First and foremost, Data Grid Operator already covers most use cases, and Red Hat's official recommendation is to use the Data Grid Operator we ship for its deployment. The Operator relies on Custom Resources (CRs), which are finely tuned and easy to manage covering the vast majority of use cases.
However, for very specific use cases that involve certain customizations like using Memcached listener, Helm charts can be a better approach. For most of the other use cases, Data Grid Operator is the most useful, direct, and simple approach for deployment.
Data Grid Operators and Helm chart deployment strategies differ in the different resources they create and how they manage these resources to achieve the same goal.
Table 1 summarizes some of the main differences.
|
Resource/Verb |
Data Grid Operator |
Data Grid Helm charts |
|---|---|---|
|
Pod deployments |
Data Grid manager deployment |
Data Grid server pods StatefulSet |
|
Services |
Created and managed by the Operator, by creating an STS |
Deployed together with the StatefulSet |
|
Route |
Created and managed by the Operator |
Deployed together with the StatefulSet |
|
User interacts |
Using CRs |
Directly on the STS |
Helm CLI commands
Table 2 shows the command list for Helm CLI.
| Command | Purpose |
|
|
Installs a certain chart passing some values—to provide a release. |
|
|
Lists the releases. |
|
|
Lists all definitions; very useful for troubleshooting. |
Getting support
For support and assistance, we encourage you to open a case with Red Hat and include some of the following details that may help to understand the issues you may encounter, including the value file and the namespace's inspect. See below.
logging:
- catalog: org.infinispan.SERVER
level: debug
We also collect the YAML value file that the user provides, also known as the values file.
Finally, we can collect the manifest file with everything that is deployed:
$ helm get manifest infinispan
- For troubleshooting, we follow similar steps as the Operator, collecting the resources on that namespace like the pod YAML/pod logs/services/routes/StatefulSet, which comes in the inspect bundle:
$ oc adm inspect namespace $NAME_PROJECT - Before running the
inspectcommand above, it is very useful to collect the server logs with debug level so we can see the actual configuration being set—so the Data Grid pod logs/inspect will bring it.
For more information, see the solution Troubleshooting Data Grid 8 deployed via Helm charts. Sometimes the problem might be as trivial as a value file parsing error, others can be more advanced, such as JVM settings misconfiguration.
Conclusion
Data Grid provides two methods of deployment and both are very straightforward: Data Grid Operator and Data Grid Helm charts.
As Table 2 shows, using Data Grid Operator is much simpler and streamlined, given the Operator is the one that creates but also manages those resources. This means that changes in those resources are handled by the Data Grid Operator. On the one hand, the Data Grid Helm charts provide more flexibility in terms of deployment and especially management of resources, where the user uses the value file to create the resource. On the other hand, Data Grid Helm charts provide fewer embedded features than the Data Grid Operator.
We recommend using the Data Grid Operator in most of the use cases for these reasons—ease of deployment, simpler troubleshooting, and embedded features—but also for managing resources, given the Data Grid Grid Operator deploys CRs and controls resources. Red Hat considers the Operator Framework to be considerably streamlined and a mature technology with vast applications and suitable for most of the use cases, but Red Hat's Data Grid Helm charts deployment is still supported.
Additional resources
To learn more about the DG Operator, see the Data Grid Operator Guide.
For any other specific inquiries, please open a case with Red Hat support. Our global team of experts can help you with any issues.
Special thanks to Will Russell for the review of this article.