A sparse summary
- Sparse foundation model: The first sparse, highly accurate foundation model built on top of Meta’s Llama 3.1 8B with 98% recovery on Open LLM Leaderboard v1 and full recovery across fine-tuning tasks, including math, coding, and chat.
- Hardware-accelerated sparsity: Features a 2:4 sparsity pattern designed for NVIDIA Ampere GPUs and newer, delivering up to 30% higher throughput and 20% lower latency from sparsity alone with vLLM.
- Quantization Compatible: Fully integrates with advanced 4-bit quantization methods like GPTQ and efficient Sparse-Marlin inference kernels, enabling faster inference anywhere from 1.2x to 3.0x depending on the hardware and scenario.
Large language models (LLMs) are approaching their limits in terms of traditional scaling, with billions of parameters added for relatively small accuracy gains and advanced quantization techniques squeezing out the last possible bits before accuracy plummets. These dense architectures remain large, costly, and resource-intensive, making it challenging and expensive to scale AI.
Neural Magic is doubling down on this challenge with sparse LLMs—reducing the model size by removing unneeded connections while retaining accuracy. Sparse models, though underexplored in the LLM space due to the high compute demands of pretraining, offer an increasingly promising dimension in model compression and efficiency.
Sparse-Llama-3.1-8B-2of4 is our next step in this commitment—a 50% pruned version of Meta's open-source Llama 3.1 8B. Built with a GPU-friendly 2:4 sparsity structure, it removes two of every four parameters while preserving accuracy. Designed as a versatile foundation model for fine-tuning and instruction alignment, Sparse Llama is optimized for both speed and efficiency. Its quantization-friendly architecture enables faster, cheaper inference with roughly half the connections of its dense counterpart.
Research background
Sparse Llama 3.1 originates from years of prior research, building on previous breakthroughs with SparseGPT, SquareHead Knowledge Distillation, and Sparse Llama 2. These contributions laid the groundwork for our state-of-the-art sparse training approach, tailored to the latest generation of LLMs. Leveraging SparseGPT developed in collaboration with ISTA, we efficiently removed redundant connections, while SquareHead’s layerwise knowledge distillation and Sparse Llama 2’s foundational training recipes provided the basis for sparsity optimization.
Working with the latest LLMs requires more than applying existing techniques. These models, pushed to the edge of training scaling laws, are highly sensitive to sparsity. We iteratively refined our methods to overcome this, starting with meticulously curating publicly available datasets. By sourcing and filtering only the highest-quality and most representative data for LLM use cases, we reduced the pretraining set to just 13 billion tokens—drastically cutting the environmental impact of further training while preserving performance.
This curated dataset and advancements in our pruning and sparse training recipes allowed training to converge in just 26 hours on 32 H100 GPUs, demonstrating the efficiency and scalability of our approach while delivering a model optimized for real-world deployments.
Performance snapshot
Sparse Llama 3.1 demonstrates exceptional performance across few-shot benchmarks, fine-tuning tasks, and inference scenarios, showcasing the versatility and efficiency of 2:4 sparsity.
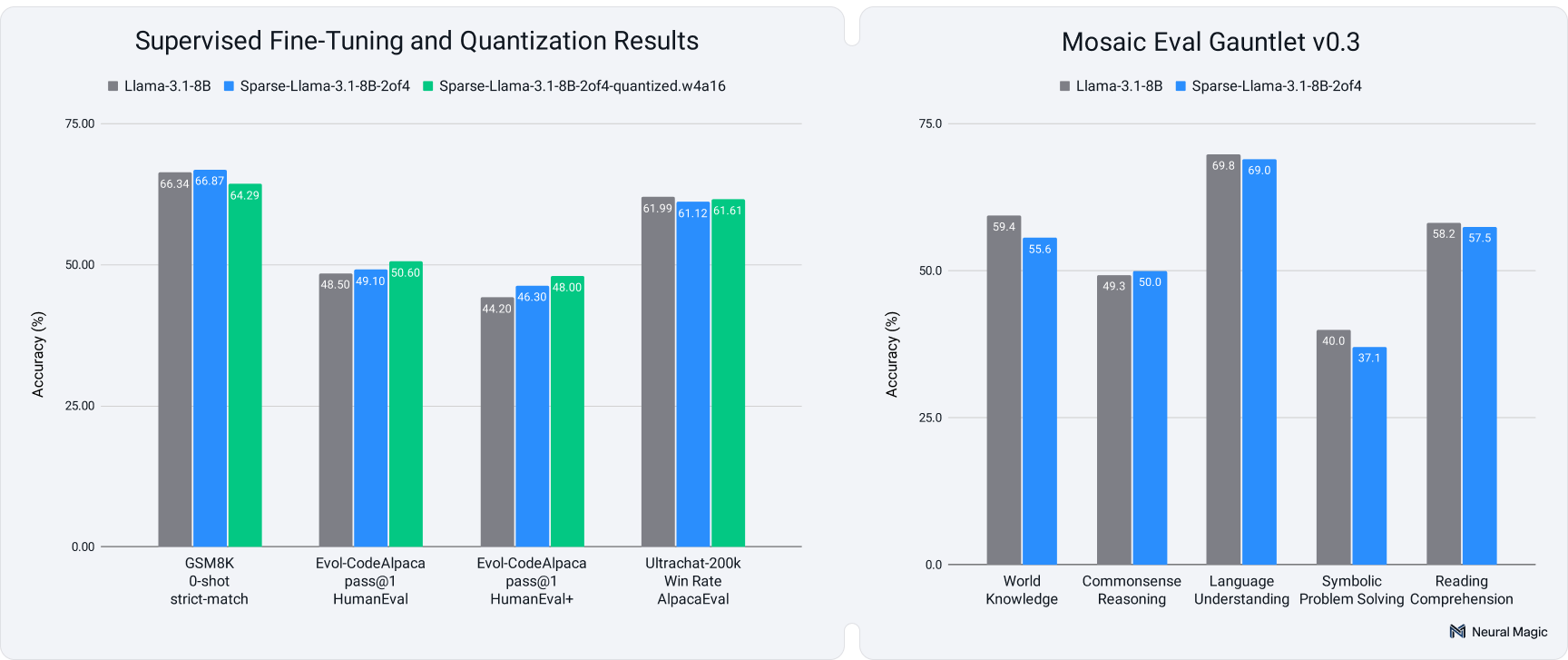
- Few-shot benchmarks: It achieved 98.4% accuracy recovery on the Open LLM Leaderboard V1 and 97.3% recovery on the more challenging Mosaic Eval Gauntlet (Figure 1, right), maintaining competitive performance with dense models.
- Fine-tuning results (Figure 1, left): The most exciting results emerged during fine-tuning across math (GSM8K), code (Evol-CodeAlpaca), and conversational AI (Ultrachat-200K) tasks. Despite minimal regression in the few-shot benchmarks, it achieved full accuracy recovery and, in some cases, outperformed its dense counterparts. These results underscore Sparse Llama's robustness and adaptability across domains. As a proof of concept, these fine-tuned models are additionally publicly available.
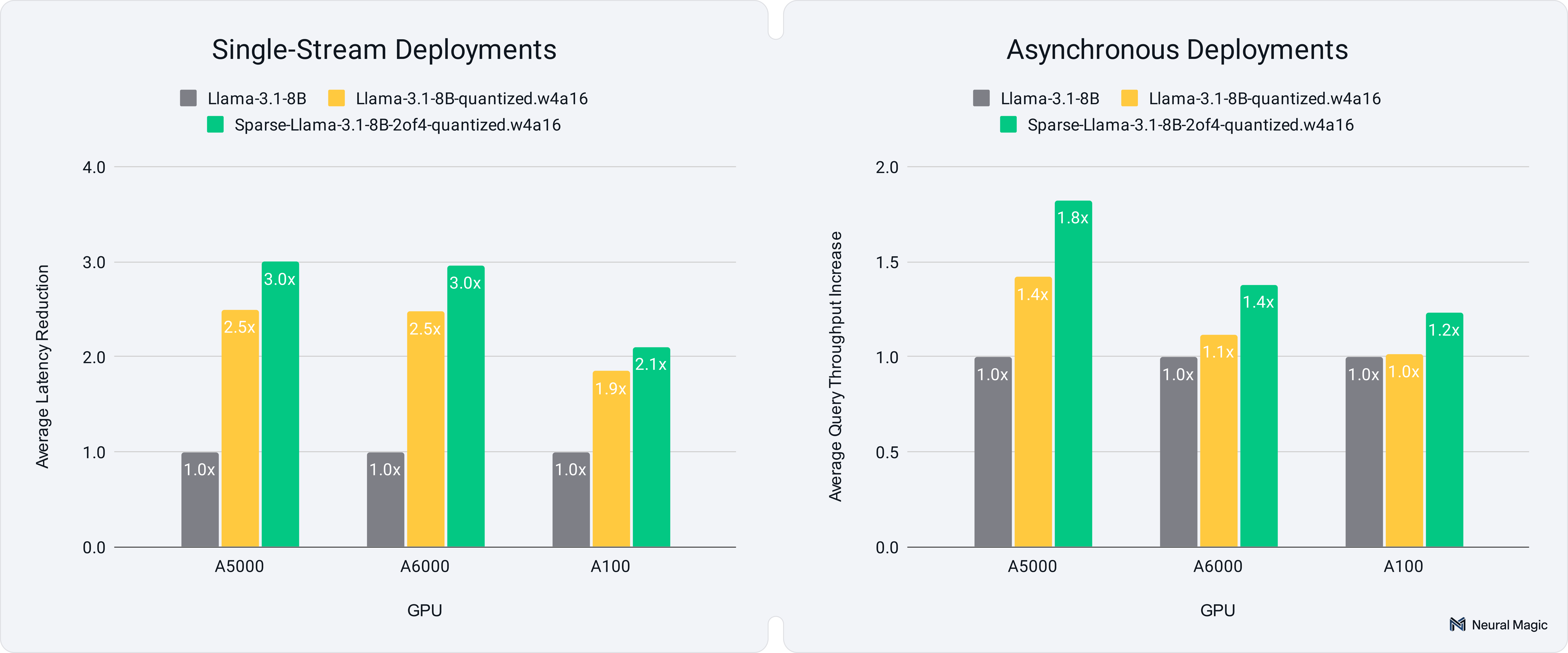
- Sparse-quantized Inference (Figure 2): Using 4-bit post-training quantization combined with 2:4 sparsity delivered impressive inference speedups with vLLM 0.6.4.post1 and minimal effects on accuracy for most cases. The sparse-quantized models achieved 3.0x speedup on A5000 and A6000 GPUs, and 2.1x on A100 GPUs in single-stream latency, with 1.1x to 1.2x of the gains attributed to sparsity alone. Throughput scenarios showed 1.2x to 1.8x improvement, even when quantization alone had minimal impact.
For a detailed breakdown of metrics and benchmarks, refer to the Full performance details section.
Get started
Explore the Sparse Llama base model and our fine-tuned versions today on Neural Magic’s Hugging Face organization. With open-sourced weights, evaluations, and benchmarks, we intend to empower the community to experiment and build on our foundation.
Stay tuned for more. The future of LLMs is open source, and with sparsity, we're excited to continue pushing the boundaries of what's possible for efficient, scalable, and performant AI.
Full performance details
This section breaks down the metrics and benchmarks.
Base model evaluations
We evaluated Sparse Llama on two widely used benchmarks to establish its baseline performance:
Open LLM Leaderboard v1: This benchmark measures capabilities across domains such as grade school mathematics (GSM8K), world knowledge (MMLU, ARC-Challenge), and language understanding (WinoGrande, HellaSwag). Sparse Llama achieved 98.4% accuracy recovery, performing nearly on par with its dense counterpart, as shown in Table 1.
| Open LLM Leaderboard V1 | ARC C 25-shot | MMLU 5-shot | HellaSwag 10-shot | WinoGrande 5-shot | GSM8K 5-shot | TruthfulQA 0-shot |
| Llama-3.1-8B | 58.2 | 65.4 | 82.3 | 78.3 | 50.7 | 44.2 |
| Sparse-Llama-3.1-8B-2of4 | 59.4 | 60.6 | 79.8 | 75.9 | 56.3 | 40.9 |
Mosaic Eval Gauntlet v0.3: A comprehensive benchmark covering reasoning, problem-solving, and reading comprehension tasks. Sparse Llama demonstrated robust performance, achieving 97.3% accuracy recovery, even on more challenging datasets, as reported in Table 2.
| Mosaic Eval Gauntlet v0.3 | World knowledge | Commonsense reasoning | Language understanding | Symbolic problem solving | Reading comprehension |
| Llama-3.1-8B | 59.4 | 49.3 | 69.8 | 40.0 | 58.2 |
| Sparse-Llama-3.1-8B-2of4 | 55.6 | 50.0 | 69.0 | 37.1 | 57.5 |
Sparse fine-tuning evaluations
To evaluate Sparse Llama’s adaptability, we fine-tuned both sparse and dense versions across three domains using the same amount of hyperparameter tuning:
- Mathematical reasoning (GSM8K): Strict-match accuracy in 0-shot setting via lm-evaluation-harness.
- Coding (Evol-CodeAlpaca): Pass@1 on HumanEval and HumanEval+ via EvalPlus.
- Conversational AI (Ultrachat-200K): Win rate on AlpacaEval, following the setup of Sparse Llama 2.
Sparse Llama consistently achieved full accuracy recovery during fine-tuning and even outperformed the dense baseline on some tasks, demonstrating its versatility. The results are detailed in Table 3.
| Model | Recovery (%) | Average | GSM8K (0-shot strict-match) | HumanEval (Evol-CodeAlpaca pass@1) | HumanEval+ (Evol-CodeAlpaca pass@1) | AlpacaEval (Ultrachat-200k Win Rate) |
|---|---|---|---|---|---|---|
| Llama-3.1-8B | 100.1 | 55.3 | 66.3 | 48.5 | 44.1 | 62.0 |
| Sparse-Llama-3.1-8B-2of4 | 101.1 | 55.8 | 66.9 | 49.1 | 46.3 | 61.1 |
Quantization and sparsity
To further optimize Sparse Llama, we applied 4-bit post-training quantization using the W4A16 scheme. This approach preserves the 2:4 sparsity pattern, where weights are quantized to 4-bit integers, and activations remain at 16-bit precision.
Sparse quantized versions maintained accuracy with minimal degradation compared to unquantized models while enabling significant compression and inference performance gains. See Table 4 for detailed accuracy comparisons across tasks.
| Model | GSM8K (0-shot strict-match) | HumanEval (Evol-CodeAlpaca pass@1) | HumanEval+ (Evol-CodeAlpaca pass@1) | AlpacaEval (Ultrachat-200k Win Rate) |
|---|---|---|---|---|
| Llama-3.1-8B | 66.34 | 48.50 | 44.20 | 61.99 |
| Sparse-Llama-3.1-8B-2of4 | 66.87 | 49.10 | 46.30 | 61.12 |
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 64.29 | 50.60 | 48.00 | 61.61 |
Inference
Sparse Llama’s inference performance was benchmarked using vLLM, the high-performance inference engine, and compared to dense variants across several real-world use cases—ranging from code completion to large summarization—using version 0.6.4.post1, as detailed in Table 5.
| Use case | Prefill tokens | Decode tokens |
|---|---|---|
| Code completion | 256 | 1024 |
| Docstring generation | 768 | 128 |
| Code fixing | 1024 | 1024 |
| RAG | 1024 | 128 |
| Instruction following | 256 | 128 |
| Multi-turn chat | 512 | 256 |
| Large summarization | 4096 | 512 |
Single-stream deployments
In single-stream scenarios, combining sparsity and quantization resulted in significant latency reductions ranging from 2.1x to 3.0x faster inference than dense, 16-bit models, with 1.1x to 1.2x speedups from sparsity alone. Table 6 provides full results across the various use cases.
| GPU class | Model | Average Speedup | Latency (s) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Code Completion | Docstring Generation | Code Fixing | RAG | Instruction Following | Multi-Turn Chat | Large Summarization | ||||
| A5000 | Llama-3.1-8B | 25.3 | 3.3 | 25.7 | 3.4 | 3.2 | 6.5 | 13.9 | ||
| Llama-3.1-8B-quantized.w4a16 | 2.5 | 9.6 | 1.4 | 10.0 | 1.4 | 1.3 | 2.5 | 6.1 | ||
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 3.0 | 8.3 | 1.1 | 8.4 | 1.2 | 1.1 | 2.1 | 5.0 | ||
| A6000 | Llama-3.1-8B | 24.6 | 3.2 | 24.9 | 3.2 | 3.1 | 6.2 | 13.4 | ||
| Llama-3.1-8B-quantized.w4a16 | 2.5 | 9.5 | 1.3 | 9.8 | 1.4 | 1.2 | 2.5 | 5.9 | ||
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 3.0 | 8.0 | 1.1 | 8.2 | 1.1 | 1.0 | 2.1 | 4.9 | ||
| A100 | Llama-3.1-8B | 12.3 | 1.6 | 12.4 | 1.6 | 2.0 | 3.0 | 7.0 | ||
| Llama-3.1-8B-quantized.w4a16 | 1.9 | 6.4 | 0.9 | 6.6 | 0.9 | 1.0 | 2.0 | 4.0 | ||
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 2.1 | 5.7 | 0.8 | 5.8 | 0.8 | 1.0 | 1.0 | 3.0 | ||
Asynchronous deployments
In multi-query scenarios, we highlight the gains focusing on maximum throughput for the various scenarios to compare Sparse Llama with its dense counterparts. Sparse Llama achieved 1.2x to 1.8x speedup in maximum query rates compared to the dense, 16-bit model, while quantization alone offered only minimal improvements and, in some cases, performed worse. Table 7 provides full results across the various use cases.
Maximum queries per second | |||||||||
| GPU class | Model | Average speedup | Code completion | Docstring generation | Code fixing | RAG | Instruction following | Multi-turn chat | Large summarization |
| A5000 | Llama-3.1-8B |
| 0.9 | 4.2 | 0.5 | 3.2 | 7.9 | 24.4 | 0.4 |
| Llama-3.1-8B-quantized.w4a16 | 1.4 | 1.6 | 4.9 | 1.0 | 3.8 | 11.6 | 22.5 | 0.6 | |
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 1.8 | 2.0 | 7.2 | 1.3 | 5.6 | 15.6 | 16.4 | 0.8 | |
| A6000 | Llama-3.1-8B |
| 1.5 | 5.6 | 1.1 | 4.5 | 12.5 | 11.8 | 0.8 |
| Llama-3.1-8B-quantized.w4a16 | 1.1 | 2.4 | 5.8 | 1.3 | 4.5 | 13.7 | 12,7 | 0.7 | |
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 1.4 | 2.7 | 7.4 | 1.5 | 5.9 | 17.3 | 16.6 | 0.8 | |
| A100 | Llama-3.1-8B |
| 3.5 | 11.2 | 2.4 | 8.7 | 23.0 | 22.5 | 1.6 |
| Llama-3.1-8B-quantized.w4a16 | 1.0 | 3.9 | 10.7 | 2.6 | 8.4 | 23.7 | 22.8 | 1.5 | |
| Sparse-Llama-3.1-8B-2of4-quantized.w4a16 | 1.2 | 4.4 | 14.0 | 3.0 | 10.8 | 25.5 | 28.2 | 1.8 | |
Empowering AI efficiency
Sparse Llama 3.1 represents a new step for scalable and efficient LLMs through SOTA sparsity and quantization techniques. From few-shot evaluations to fine-tuning performance and real-world inference benchmarks, Sparse Llama delivers substantial improvements in inference performance, making advanced AI more accessible.
We are excited to see how the community builds on this foundation. Whether you’re optimizing deployments, exploring model compression, or scaling AI to new heights, Sparse Llama offers a compelling path forward. Together, let’s shape the future of efficient AI.
This blog was updated on 12/23/24 with corrections to inference performance numbers.
Last updated: March 25, 2025