As a maintainer of the GCC register allocator (RA), I naturally have a keen interest in the register allocators used in various industrial compilers. For some compilers, like LLVM and Cranelift, there is sufficient documentation, including papers and presentations, to gain a deep understanding of their register allocators (RAs).
Unfortunately, this is not the case for the Go compiler. To gather information about the RA in the Go compiler, I had to delve into its source code. This article outlines my findings.
Go's register allocator: A high-level view
In summary, the current Go register allocator operates on SSA (Static Single Assignment). The entire Go compiler optimization pipeline operates on SSA.
Taking a broader view, the current Go register allocator comprises the following components (passes), shown in Figure 1 and described below.

Critical edge elimination in the control flow graph (CFG) is a prerequisite for Go's register allocator. During its operation, the Go RA needs to insert various instructions on CFG edges. In the final program, there are no CFG edges, so the instructions must be placed at the start of the basic block (BB) that is the edge destination or at the end of the BB that is the edge source.
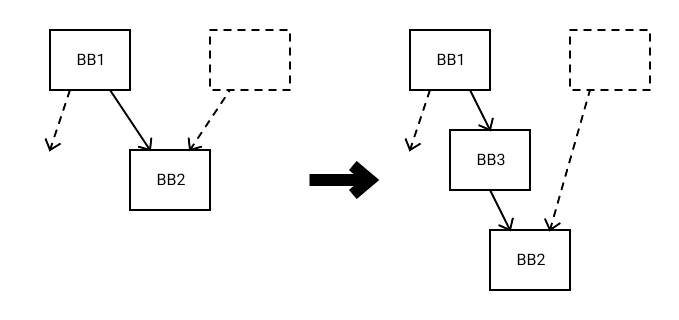
To ensure the correctness of the result code, we need to split a critical edge, creating a BB with one input and one output edge, as shown in Figure 2.
Flagalloc deals with conditional code value allocation, which is not crucial for performance.
Live analysis generates data for Go garbage collection based on register allocation result.
Here, our focus is on regalloc and stackalloc.
Regalloc
This is the biggest and most complicated part of Go RA.
The minimal allocation unit is the SSA value, which has one definition and several uses. SSA Phi semantics dictate that all Phi operands and results must receive the same location, whether a register or a stack memory slot. The register allocator is a local register allocator with some global scope optimizations.
The RA in Go processes basic blocks (BBs) in CFG preorder. To be more precise, BBs are processed in the Go BB layout, which is created to minimize branch instructions. An important aspect is that at least one predecessor of a BB in CFG is processed by RA first (Figure 3).
The RA keeps track of where currently living values are located, which can be in several different registers or in memory.
To choose a better register for SSA value Go RA keeps up to 4 desired registers for the value. Some of them are defined by used instructions (e.g., x86 shift requires keeping shift value in CX), others are defined by 2-op instruction constraints or by copying to/from hard registers (e.g., call argument hard registers).
The start allocation of SSA values at a BB is taken from a predecessor already processed. When there is more than one such predecessor, the predecessor with fewer spill values is used.
Value spills
When the instruction corresponding to the current SSA value requires a register for the operand or result, and there are no free registers available, the register allocator can spill values that are live at the current program point.
This is done using a heuristic based on the longest distance to the next use, which works particularly well for linear code.
To apply this heuristic, the distances to the next value uses must be known. The basic block (BB) layout influences these distances. Distances are measured in instructions, and for distances between BBs, Go's RA uses likelyDistance (1), unlikelyDistance (100), and normalDistance (10).
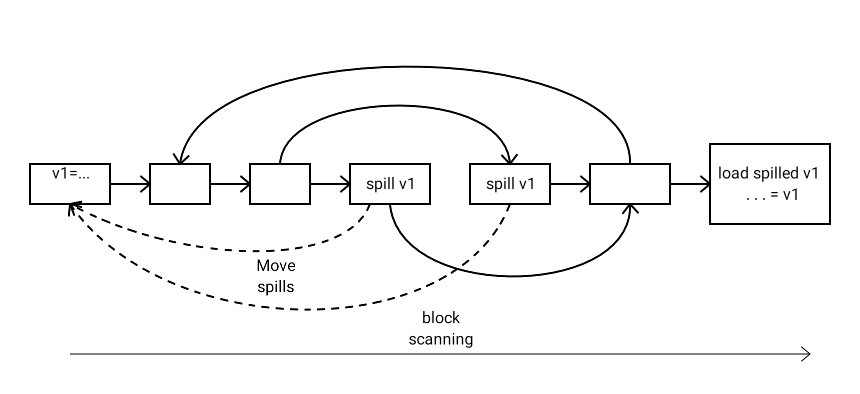
The spill operation creates a new SSA value and effectively implements live range splitting.
Value spills are not placed where they are generated; instead, they are placed in the uppermost BB in the dominator tree where the value is in a register, the BB is in the least nested loop, and the BB dominates all the value restores (see the figure above). The value restores are placed right before their use.
The RA can also perform simple value rematerialization when the value is a constant or a reference to a fixed register (such as a stack or frame pointer register).
Instead of spilling, the Go RA can move a value from one hard register to another. For example, this can occur when a specific value needs to be in a particular hard register (e.g., CX for an x86 shift instruction).
Dealing with Phis
A significant portion of the register allocation code is dedicated to processing SSA Phis, ensuring that registers are correctly allocated to Phi values and their arguments according to Phi semantics (a process referred to as a shuffle in the RA code comments). Since the same argument value can be used in different Phis within a basic block, the Go register allocator may create copies of argument values at this stage.
At control flow graph merge points, the RA can generate instructions to ensure that the live value (or its new representative) is placed in the same location from each path leading to the merge point. See Figure 4.
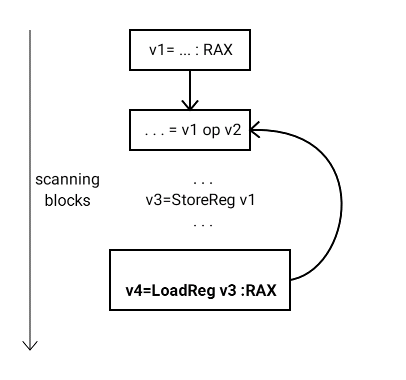
By the end of the RA process, Phi value and all its operand values should occupy the same hard register or the same stack location. To achieve this, Go RA adds copies to ensure consistent value allocation at the merge points. In a sense, this can be considered an out-of-SSA pass. The same issue of cycles in copied values can arise, and these cycles are broken by using a temporary register and performing copies to/from it. The use of a temporary register may lead to temporary spilling of values involved in the cycle.
Stack slot allocation
Values that did not obtain registers are assigned to stack slots. Efficient stack slot utilization is crucial for Go programs, as goroutines use their own stacks. Therefore, stack slot allocation is a process with global scope view. It is implemented in the stackalloc.go file. Stack slot allocation is not a separate pass in the Go compiler; rather, it is integrated into regalloc pass.
The same stack slot can be shared by different SSA values if their lifetimes do not overlap. To optimize stack allocation, the Go compiler even constructs a conflict graph. The nodes of the graph represent values that require a stack slot, and an edge between nodes indicates that the corresponding values can live simultaneously.
Unlike other compilers, which typically rely on live analysis based on data-flow equations to build the conflict graph, the Go compiler benefits from SSA properties that eliminate the need for such analysis.
Values that did not receive a register are processed in a specific order, and the conflict graph is used to find stack slots already allocated to values that live simultaneously with the given value. In some ways, this algorithm is analogous to Priority-Based Coloring (Fred Chow et al., "Register Allocation by Priority-Based Coloring", ACM SIGPLAN Notices, Vol. 39, Issue 4).
Go RA data
Like any register allocator, Go's RA utilizes a significant amount of data, such as instruction register requirements, allocatable registers, and the location information of SSA values at the end of a basic block. These are initialized and represented using efficient data structures. The Go compiler generates and optimizes functions in parallel, which makes it challenging to reuse allocated data structures, some of which can be quite large. Go developers have addressed this issue generally by allocating a cache for parallel workers, allowing the cache to be reused by functions processed by the same worker. A portion of this cache is used by the RA for its data.
Each SSA value has an instruction description that outlines instruction inputs, outputs, and clobbers. The order of these inputs and outputs can differ from the corresponding SSA value operand order because Go's RA assumes that inputs or outputs with more constrained register requirements are placed first.
Instruction clobbers identify registers whose values are overwritten by the instruction and should not be used for the instruction outputs. This differs from GCC, where clobbers are early clobbers and cannot be used for inputs. Early clobbers in the Go compiler can be described by excluding the early clobbered registers from permissible input registers. Early clobbered GCC pseudos can be represented in Go by using the Go instruction attribute resultNotInArgs.
GCC scratch registers can be described in the Go compiler using another Go instruction attribute, needIntTemp. In my opinion, these instruction descriptions in the Go compiler are suitable for the current register allocator but may be inconvenient for other register allocator algorithms.
Go's RA uses 64-bit masks for registers, which means it assumes that the target has at most 64 registers.
Dealing with SSA in Go's register allocator
As previously mentioned, all optimization passes, including regalloc, operate on SSA form.
However, maintaining SSA after register allocation is challenging because the one-definition rule of SSA cannot be upheld with a limited number of hard registers.
Additionally, two-operand machine instructions (which require the output and one input to be the same) further complicate preserving the one-definition rule.
To address these challenges, Go's RA employs several techniques to preserve SSA. Instead of using explicit hard registers in the intermediate representation (IR), it maintains SSA values and maps them to registers.
To represent value spills and restores, Go uses special operations StoreReg and LoadReg:
s=StoreReg v1
...
v2 = LoadReg sTo handle two-operand instructions, the RA creates a copy instruction. This allows the original value to be preserved in at least one location. In the following example, c and a share the same register, and the location for the value d can be reused in subsequent instructions. If the value of the copy is not used, it is removed afterward.
d = a
c = a op bStill, SSA after register allocation is not pure SSA. It requires retaining some dead values; otherwise, the semantics of the function code would be invalid. The following example (taken from RA code comments but modified for better understanding) illustrates this:
b1: x = ... : AX
x2 = StoreReg x
... AX gets reused for something else ...
if ... goto b3 else b4
b3: x3 = LoadReg x2 : BX b4: x4 = LoadReg x2 : CX
... use x3 ... ... use x4 ...
x5 = copy x4 : BX
b2: ... use x3 ...Firstly, x3 in b2 is not dominated by the definition. The second issue is that x5 is dead, but it is necessary to have the x value at b2 in the same hard register (BX). Therefore, dead code elimination is never run after RA.
RA output
The result of regalloc pass is an SSA IR where values are bound to registers or stack slots, with special instructions (or SSA values) like LoadReg, StoreReg, and Copy added. However, the SSA IR after regalloc is not in a valid SSA form, rendering classical optimizations like dead code elimination impossible.
The output of the Go register allocator is modified SSA code accompanied by a RegAlloc slice that maps SSA value IDs (unique value numbers) to their respective locations, either registers or stack slots.
Regalloc algorithm
To summarize the above, the Go register allocator employs the following algorithm:
initialize data;
foreach BB in CFG pre-order do // moving from function entry to exit
calculate next value use distance;
if BB has one predecessor then
copy allocation state from it;
else
choose the best predecessor and use its state as the starting point;
allocate registers to Phi values and their arguments;
fi
propagate desired registers for values from processed successor BBs;
foreach BB instruction in reverse order do
update desired registers based on the instruction;
done
determine desired registers for BB values;
foreach BB instruction do
reserve required registers for instruction operands,
spilling or shuffling live values with the most distant use if there are no free registers;
load, shuffle, or rematerialize input values into the corresponding registers;
make a copy of an input value if the input must be the same as the output (2-op instructions);
done
if there is only one successor and it’s in the loop then
move live SSA values without register into a register (preferably the desired one) if possible;
fi
save end block allocation state, including spilled values;
done
place generated spills;
allocate stack slots to SSA values without register;
fix all merge edges;
remove unused generated copies;Most of the RA code is machine-independent, driven by machine-dependent data such as instruction requirements. However, the RA code also includes explicit machine-dependent code, such as initialization code or handling specific operations during RA, like treating OpAMD64ADDQconst as a 2-op instruction to generate the preferred x86-64 add instead of lea. Additionally, a considerable amount of code is dedicated to the WebAssembly(WASM) target, identifying which values reside on the WebAssembly stack.
Comments in the source code suggest that Go's RA uses a version of linear scan. I believe this is not accurate. Linear scan typically operates with live ranges described using program points. In my view, the RA algorithm most closely related to Go's RA is the second-chance bin-packing method [2]. Although second-chance bin-packing also operates on live ranges expressed as program points, it shares similarities with Go's RA in its focus on resolving allocation states at CFG merge points, spill placement, and register shuffling (moving values from one hard register to another).
[2] Omri Traub et al., "Quality and Speed in Linear-Scan Register Allocation," ACM SIGPLAN 1998 Conference on PLDI.
Call ABI
Go's RA assumes that all registers are clobbered by calls. In other words, if an SSA value is assigned to a register and lives through a call, it must be saved before the call and restored afterward, resulting in inefficient generated code.
To generate more performant code, most call ABIs have both call-saved and call-clobbered registers, allowing the RA to assign call-saved registers to pseudos that live through calls. The following example illustrates how using such a call ABI can produce better code:
func example
loop
p1 = ...
...
call
...
... = p1
end loopIf we assign p1 to a call-saved register r, and r is not used in the called function, we only need to save and restore r in the prologue and epilogue of the function example. However, if we use a call-clobbered register r, we would need to save and restore r around the call somewhere in the loop. This could result in millions of additional instructions being executed.
Using a call ABI with call-saved registers complicates the implementation of finding root pointers for Go's precise Garbage Collector, but in my opinion, the benefit of better-generated code is worth it.
While changing the call ABI might seem challenging, the Go compiler's ABI has already been modified once: instead of passing all call arguments on the stack, some arguments can now be passed through registers. This is not a significant issue since Go programs are statically linked.
Conclusion
In general, I consider the current Go RA to be a local scope RA with some global optimizations. As with any approach to register allocation, there are pros and cons. Here are the advantages and drawbacks of the current RA as I see them:
Advantages of Go RA:
- Small codebase (3K LOC in
regalloc.go+ 500 LOC instackalloc.go). RA is a complex part of any compiler, so a smaller size generally means fewer bugs in the code. - Very fast. Go developers highly value the incredible speed of the Go compiler, and the speed of the RA is an important contributor to the overall compiler performance, as it is still the most expensive pass, sometimes taking up to 20% of the entire optimization pipeline's time.
- Decent stack slot sharing.
Drawbacks of Go RA:
- Lack of a global view: The RA performs well with mostly linear code (e.g., a single basic block). However, for a more complex Control Flow Graph (CFG), which is common in Go programs, it can result in excessive shuffles on CFG edges and spills, leading to larger and slower code.
- Spills/restores can easily end up inside loops, which a more sophisticated RA would avoid.
- Complex Phi handling: Although the RA code is not large, it is overly complicated in keeping Phi values and operands in the same location. In some ways, the RA implicitly implements an out-of-SSA pass.
- Fine-grained allocation unit (SSA value): This granularity can lead to excessive value shuffling.
- Invalid SSA after RA: Even disregarding locations, the SSA is invalid, which prevents useful checks like verifying RA correctness.
In summary, the current Go RA is a well-designed and creative RA. I enjoyed the time I spent studying it.